최근 speculative decoding에 주력해서 논문을 읽다보니까 시스템 관련한 논문을 많이 읽지 못한 것 같다. 그래서 오늘은 SOSP에서 context caching 관련하여 논문을 가져왔다. 요새 회사에서 LLM을 클러스터 단위로 서빙해야 할 일이 많다. 그래서 이 논문이 조금 도움이 될 것 같았다. IC-Cache의 경우 구글 내부자들도 많이 참여한 논문이기 때문에, GCP에서 운영되는 Gemini가 어떤 식으로 serving이 되는지 조금이나마 단서가 될 수도 있을 것 같다.
Accuracy-Cost-Latency Tensions in LLM Serving

대부분 잘 알다시피, ChatGPT 같은 서비스에 필요한 LLM serving에는 수백 대의 GPU가 필요하다. 이러한 주요 원인은 LLM의 파라미터 수가 점점 커지는데에 있는데, 이러한 추세는 모델의 품질과 효율성 사이에서 문제가 발생하게 된다. 보통 사용자들은 사용하는 LLM이 높은 품질을 가지면서 낮은 latency 안에 응답이 돌아오길 기대한다.
위 그래프를 보면 LLM serving의 비용, latency 그리고 정확도에 대한 trade-off를 분석했다. 일반적으로 더 큰 모델일수록 더 높은 품질의 응답을 만들어냈지만, ITL (Inter-Token Latency)가 크고 훨씬 더 많은 자원을 사용해야 했다.
이 세 가지 요소의 균형을 맞추는 것은 거기에 3가지 요소로 인해서 더 어렵다.
- 엄격한 SLO (Service Level Objectives)
- 증가하는 request 수
- 매우 동적으로 변화하는 request 패턴
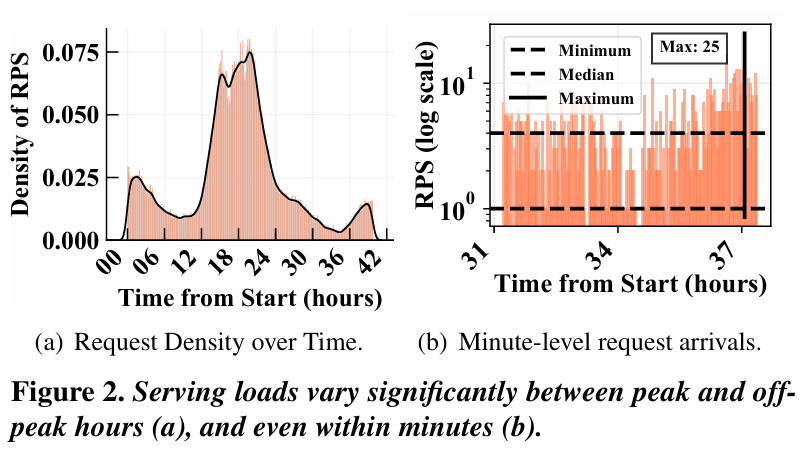
위 그래프는 Azure의 LLM serving trace를 분석한 것인데, 이에 따르면 매일 발생하는 특정 패턴 외에도 몇분 동안 부하가 급격하게 증가하는 것을 볼 수 있다. 이러한 피크 타임은 아닐 때에 비해서 최대 25배까지 부하가 치솟는다. 이 상황에서 SLO를 맞추기 위해서는 클러스터의 운영이 복잡해지고 과다한 resource provisioning이 필요하다. 심지어, 최적화가 많이 이루어진 LLM 플랫폼조차 사용자 요청은 심각한 latency 변동을 자주 겪는다.
과거의 요청을 재활용 하기
최근에는 개별 요청과 개별 LLM에 대해서 disaggregated 방식으로 리소스를 할당하거나, 사용자가 체감하는 latency 최적화를 중점적으로 연구가 되었다. 하지만 IC-Cache의 경우는 이러한 방식보다는 주로 과거의 요청-응답을 in-context example로 활용하여 실시간 LLM 능력을 향상시키는 방식을 채택했다. 이 방식은 작은 LLM을 더 큰 모델의 동작 방식을 모방시켜서 더 고품질의 응답을 생성하는 방식이다. 그래서 큰 LLM의 트래픽을 작은 LLM으로 적절하게 오프로딩 시킬 수 있다. 이는 다음 그래프에 대한 관찰 결과에 기반한다.
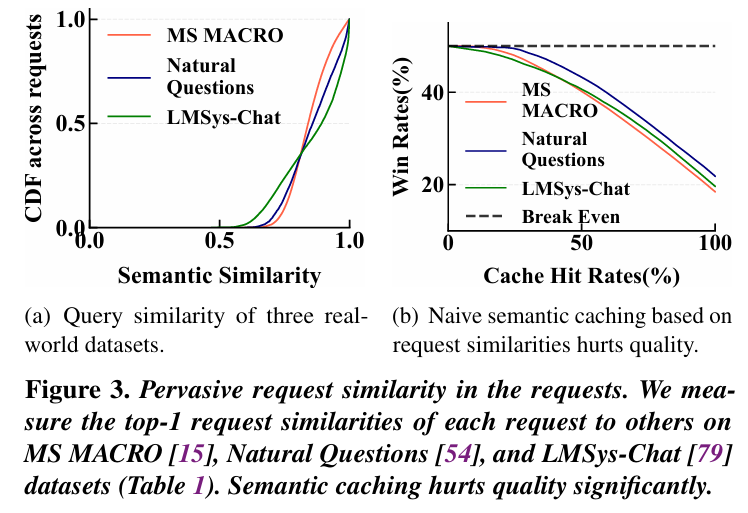
1. 많은 request는 범위가 큰 의미적인 유사성을 만들어낸다.
LLM의 일일 요청량이 폭발적으로 증가하더라도, 요청 사이의 의미적인 유사성이 존재한다. 이에 대해서 실제 데이터 (Bing 검색 요청 건)를 이용하여, 각 요청의 dense embedding을 T5 모델로 추출하고, consine similarity를 적용 했을 때, 위 그래프 (a)와 같은 결과가 발생했다.
70% 이상의 요청이 유사도 0.8 이상인 다른 요청을 최소 1개 이상으로 가진다. 보통 cosine similarity에서 0.8 정도면 강한 의미적인 유사성을 가진 것으로 본다. 또한 무작위로 요청-응답 쌍을 만들더라도, 평균 유사도는 0.5 정도를 가진다.
2. Semantic caching은 효율성과 품질에 한계가 존재한다.
Google이나 OpenAI, 그리고 DeepSeek의 경우, prefix caching을 지원하는 기능이 이미 구현이 되어 있다. 이를 기반으로 GPTCache나 Databricks 같은 semantic caching을 도입했다. 이는 새 요청이 과거 요청과 의미적으로 비슷하면 그 응답을 그대로 재사용하는 방식이다.
하지만 (b) 그래프를 보면, 가장 유사한 요청을 찾아 캐싱 된 응답을 그대로 반환 시켰을 때, 모델이 직접 생성한 응답 대비 승률이 50%에서 18%까지 감소했다. 이는 간단한 sematic 기반 캐싱도 위험하고 품질도 낮다는 것인데, 이는 2가지 문제에서 비롯된다.
- 같은 요청도 표현이 다양하기 때문에 매칭이 잘 안된다. 그래서 정확한 일치율이 낮아진다.
- 두 요청이 완전히 동일한 의미인가에 대한 판단이 주관적이다.
3. 과거의 기록은 실시간 LLM 능력 향상에 도움이 된다.
IC-Cache 저자들은 단순한 응답을 재사용하는 것 대신에, 과거의 요청-응답 context를 새로운 요청 앞에 in-context example로 붙여서 작은 LLM의 능력을 확장시킬 수 있음을 발견했다. 이는 in-context learning에 기반한다. 최근의 LLM은 고품질의 학습 데이터를 사용하기 때문에 즉석 지식 이전 (on-the-fly knowledge trasfer)이나 추론 패턴을 모방하는 것이 가능하다.
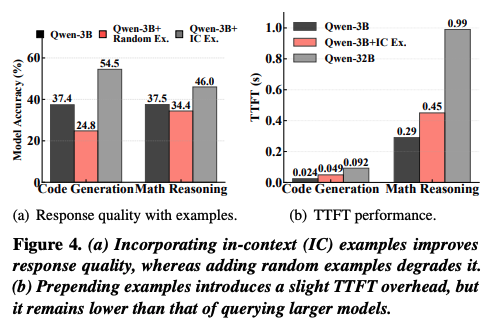
위 그래프는 Qwen-2.5 3B 모델에 32B에서 생성한 예제 5개를 붙여서 정확도를 측정한 결과이다. (a) 그래프의 경우, 잘 선택된 예제를 붙이면 LLM의 성능이 크게 향상함을 보이지만, 반대로 무작위로 선택 된 잘못된 예제를 붙이면 오히려 성능이 떨어진다. (b) 그래프의 경우, 예제를 추가하면 prefill에 걸리는 시간이 늘어나는 것을 보여준다. 하지만 decoding 시간은 그대로이고, prefill이 늘어난다고 하더라도 여전히 작은 LLM의 latency는 큰 LLM보다 작아서 상관 없다.
IC-Cache
IC-Cache는 정확도와 효율성 측면에서 온라인으로 쏟아지는 수많은 context 속에서 단순한 관련도 이상의 판단 기준을 정하고, 이를 효과적으로 캐시를 관리하는 방법을 고민해야 했다. 그래서 아래 그림과 같이 IC-Cache 프레임워크를 구성하였다.
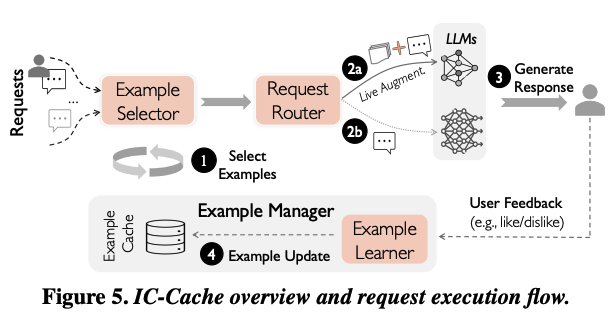
IC-Cache는 과거의 요청을 활용하여 실시간으로 LLM의 능력을 증강시키고, 요청을 동적으로 offloading하여 latency와 비용을 줄이면서 응답 품질을 유지시킨다. 이에 따라서 3가지 구성 요소로 구성이 되어 있다.
- Example selector : 과거 기록에서 높은 efficiency를 가진 요청-응답을 선택하여 LLM의 in-context로 사용한다.
- Request router : 새로운 요청의 복잡도와 현재 시스템의 부하를 기반으로 in-context가 추가 된 요청을 작은 모델이나 큰 모델 중 가장 적합한 곳으로 보낸다.
- Example manager : 요청-응답 context를 관리하면서 in-context의 품질을 개선시키거나, 오래되거나 품질이 낮은 항목을 제거한다.

IC-Cache는 위와 같이 최소한의 코드로만 동작한다. 5번 그림을 기준으로 봤을 때, 새로운 요청이 들어오면 다음과 같은 순서로 IC-Cache가 동작하게 된다.
- example selector가 캐시에서 가장 도움이 되는 요청-응답 쌍을 찾아서 in-context 예시로 선택한다.
- 새로운 요청은 이 예시들이 포함된 형태로 request router로 간다. router는 어떤 LLM이 요청을 처리할지 결정한다.
- 선택 된 모델이 요청을 처리하여 응답을 생성하고, 사용자에게 전달한다.
- example manager가 필요에 따라서 요청-응답을 캐시에 저장하거나, 비용을 고려하여 replay를 통해 예시 품질을 향상 시키거나, 오래되거나 품질이 낮은 예시를 캐시에서 제거한다.
Example Selector
IC-Cache의 example selector는 캐시에서 utility가 높은 이전의 요청-응답 예시를 찾는 역할을 수행한다. 이에 따라 찾아주는 예시의 utility에 따라서 생성되는 응답 품질 향상이 얼마나 되는지가 결정된다. 가장 단순한 방법은 각 예시를 넣어서 실제 모델의 결과랑 비교하는 것인데, 이러한 방식은 시간과 비용 측면에서 비현실적이다.
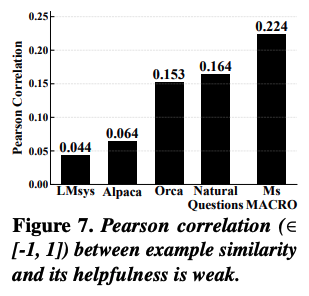
대안할만한 방법으로는 RAG 같은 곳에서 사용되는 embedding cosine similarity를 이용하는 것이다. 하지만 위 그래프를 보면, semantic relevance는 실제 예시에서 도움의 정도와 상관 관계가 약하기 때문에 utility를 근사하기에는 신뢰성이 떨어지는 문제가 있다. 이러한 경향이 나타나는 이유는, 관련도를 기반하여 선택하는 것이 모델의 능력 차이나 예시의 품질을 반영하지 못하기 때문에 편향적인 utility가 추정 되기 때문이다. 또한 similarity는 세부 정보 확장은 가능하지만, 정확성이나 깊이, 창의성 같은 더 넓은 차원의 품질 요소들은 반영하지 못한다.
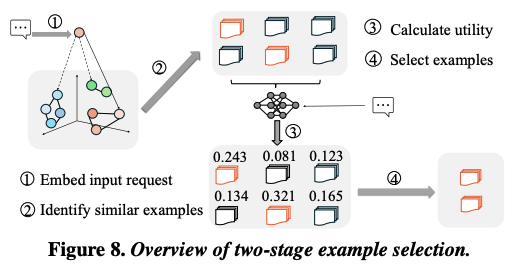
이에 따라서 IC-Cache의 example selector는 two-stage 기반으로 동작하는 선택 메커니즘을 도입하였다. 핵심 아이디어는 1단계로 semantic relevance를 이용하여 후보군을 좁히고, 2단계에서 proxy model을 이용하여 utility를 추정한다.
1. semantic relevance 기반 후보 필터링
새로운 요청이 도착하는 경우, 요청 embedding과 캐싱 된 example embedding 사이의 cosine similarity를 계산한다. 그리고 높은 similarity를 가지는 예시를 우선순위로 두고 후보군을 만든다. 여기에 scale을 확장시키기 위해서 캐싱 된 예시들을 오프라인에서 k-means를 이용하여 K개의 클러스터로 나누고, 온라인에서는 해당 요청과 가장 가까운 클러스터만 탐색한다.
K개의 클러스터에는 한 가지 trade-off가 있는데, K가 너무 크면 최근접 중심점을 탐색하는데에 비용이 많이 들고, 반대로 너무 작으면 클러스터 내부를 탐색하는 비용이 증가한다. 따라서 요청 당 매칭 비용인 를 최소화하는 을 선택하여 utility를 최적화 한다.
2. proxy 모델을 이용하여 예시별 utility를 정밀하게 추정한다.
1단계에서 필터링 된 후보군으로부터 작은 proxy 모델을 사용하여 각 예시가 응답 품질 향상에 얼마나 기여 할 수 있는지를 추정한다. 보통 proxy 모델을 가벼운 것을 사용해야 하는데, IC-Cache의 경우, TinyBERT를 사용했고, 이는 Qwen-2.5 7B의 0.2% 미만의 크기를 사용했다고 한다. 추가적으로 proxy 모델은 피드백 기반 학습으로 오프라인에서 지속적으로 업데이트를 시킨다. 실제 대형 서비스는 하루에 수백만의 요청이 들어오는데, 이 중 1%만 샘플링해도 매우 큰 사이즈의 데이터셋이 발생하기 때문에, 사용자 피드백을 지속적으로 수집함으로써 proxy 모델의 성능 향상이 가능하다.
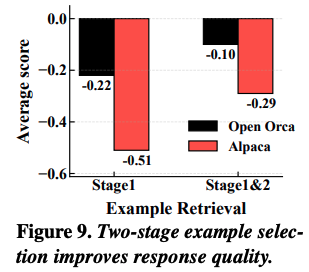
위 그래프는 two-stage 기반의 example selector를 사용하였을 때, 1% 미만의 오버헤드만 발생시키면서 응답 품질을 크게 향상 시켰다고 한다.
Selecting Example Combination
two-stage 방식은 높은 utility를 가진 이전 context를 잘 찾아내지만, 너무 많은 예시를 포함하면 오히려 품질 향상 효과가 줄어든다. 또한 입력 길이가 길어지면 prefill에서도 추론 비용이 증가하기 때문에 요청마다 포함 할 예시의 수를 동적으로 조절해야 한다.
LLM serving은 오랜 시간동안 떠있는 서비스이므로, IC-Cache는 다양한 수의 예시를 포함했을 때 발생하는 영향도를 지속적으로 탐색을 수행한다. 이에 따라서 two-stage selection 이후, 동적으로 utility의 threshold를 적용하여 utility가 threshold 값보다 낮은 예시들을 제외시킨다. 실제 배포 도중에, IC-Cache는 주기적으로 일부 요청 샘플을 뽑는다. 그리고 서로 다른 utility threshold에서 평균 utility 개선 정도를 평가하고, 그 중에서 전체 성능을 최대화 시키는 threshold를 선택하여 전역으로 적용시킨다. 샘플링 된 요청들의 품질은 request router가 적절하게 보장이 가능하기 때문에, 이 방식은 안정적으로 동작 할 수 있다.
Request Router
Example selector에서 선택 된 예시들을 활용하면 작은 LLM들도 실시간으로 추론 능력을 확장하여 고품질의 응답을 생성 할 수 있다. 하지만, 과도하게 작은 LLM에 offloading을 하면, example-based 확장의 한계로 인해 응답의 품질이 떨어질 수 있거나, 반대로 지나치게 보수적으로 routing하면 utility 향상 폭이 줄어든다.
일부 연구에서는 요청을 routing 하는 것을 분류 문제로 다루는 접근도 가능하지만, 실제 시스템에서는 다음 3가지 요건을 충족해야 하기 때문에 비효율적이다.
- 동적인 serving 부하와 품질과 throughput 사이의 trade-off 변화에 실시간으로 대응해야 한다.
- 데이터와 모델 특성 변화에 따라 달라질 수 있다.
- 모든 모델에 대한 응답의 생성과 labeling이 필요할 정도로 무거운 비용이 소모되어서는 안된다.
위와 같은 제약 사항으로 인해 무거운 classifier 기반의 router는 적합하지 않다. 그래서 이를 해결하기 위해, IC-Cache는 request routing 문제를 MAB (contextual multi-armed bandit) 문제로 모델링하였다.
MAB 문제는 여러 개의 선택지 중 어떤 것을 선택해야 총 보상이 커지는지를 "탐색"과 "활용"을 통해 찾아내는 문제를 의미한다.
MAB 문제로 변환 시, 사용되는 입력은 요청 질문과 선택 된 예시들이고, 각 arm은 후보가 되는 LLM(예시로 보강 된 작은 LLM, 또는 예시 없이 큰 LLM)이 된다. MAB는 여러 요청을 통해 arm을 탐색/활용 하여 누적 보상인 응답 품질 최대화를 만드는 방향으로 학습이 된다. 이러한 MAB 방식은 온라인 피드백에 대한 요구량이 적고, LLM 대비 경량이기 때문에 online serving 환경에 적합하다.
Load/Quality-aware Offloading
품질을 우선시 하면 큰 LLM을 많이 사용하게 되고, 이로 인해 비용과 latency가 증가한다. 반대로 효율을 우선시 한다면 작은 LLM을 많이 사용하게 되는데, 이는 품질에 대한 위험이 증가한다. 이를 해결하기 위해서, request router는 들어오는 요청 부하의 변화에 대응하기 위해서 load-aware biasing 방식을 사용한다. 시스템으로 들어오는 부하에 대해서 Exponential Moving Average (EMA)를 추적한다. EMA는 정해진 특정한 threshold 값에 따라서 현재 시스템의 상태가 요청이 많이 들어오는 부하 상태인지 아닌지를 판단한다.
- EMA < threshold인 경우, 시스템의 부하가 낮기 때문에 품질을 우선시하는 전략을 사용 할 수 있다. 큰 LLM을 많이 사용하거나, 작은 LLM을 쓰더라도 좀 더 좋은 선택지를 탐색하여 사용한다.
- EMA > threshold인 경우, 시스템의 부하가 높은 상태이다. 이 상태에서는 기반의 bias를 만들어서 큰 모델이 선택 될 확률을 낮추고, 작은 모델 선택 확률을 올려준다.
기반의 bias를 사용하는 이유는, bias 값이 발산하지 않기 때문에 급격하게 튀지 않고 부드럽고 안정적인 offload 비율을 조절 할 수 있기 때문이다.
Efficient Router Adaptation under Dynamics
실제 배포 환경에서는 요청 분포의 변화나 모델 업데이트로 인해 router가 지속적으로 개선이 되어야 한다. router는 0.5M 정도의 파라미터만 가지는 매우 작은 모델을 사용하기 때문에 training 비용 자체는 작지만, 이를 수행하기 위한 데이터 수집이 병목이 될 수 있다.
따라서 불확실한 요청에 대해서만 피드백을 요구하는 전략을 사용한다. 우선 router가 LLM 후보들에 대한 confidence 분포를 사용해서 불확실성을 측정한다. 만약 후보 모델 점수의 표준편차가 낮은 경우가 있다면 이는 모델 간의 구분이 어려운 상황이 되고, 피드백 요청 대상이 된다. 이런 요청에 대해서 항상 1순위 모델을 포함해야 하고, 2순위 모델은 확률적으로 선택하여 적절한 탐색을 보장시킨다.
Example Manager
IC-Cache의 example manger는 end-to-end 효율을 극대화 시키기 위해서 각 예시 context의 utility를 높여 request 단위의 offloading 효과를 개선하고, 서비스의 규모나 privacy 제약이 주어졌을 때, 다양한 request 처리를 위해 높은 utility를 가진 context pool을 유지시키는 역할을 한다. 즉, example을 지속적으로 관리하고, 최적화 하는 역할을 수행한다.
Cost-aware Example Replay
최근 LLM 연구에 따르면 토큰 샘플링과 같은 생성에서 발생하는 확률적인 특성으로 인해 모델의 응답 품질에는 여러 변동성이 존재한다. IC-Cache의 example replay는 이 변동성을 활용한다. 동일한 요청을 여러번 모델에 입력하여 여러 다양한 응답을 얻고, 이 중에서 가장 최적이라 여겨지는 응답을 선택하여 example로 저장하는 방식이다. 이러한 replay 방식은 트래픽이 몰리지 않는 비혼잡 시간대에 수행이 되어야 하고, 잘 생성 된 example의 경우, 수백번 재사용 될 수 있기 때문에 replay에 필요한 비용은 전체적으로 보면 1% 미만으로 작게 분산 된다.
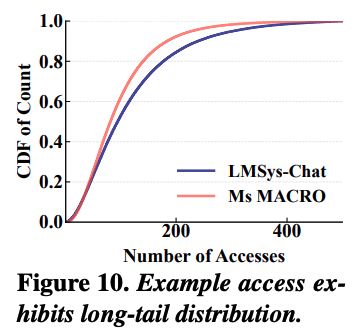
위 그래프는 실제 운영에서 example의 재사용 빈도와 효과가 long-tail 경향을 보여주면서 불균형하게 분포되는 것을 증명해준다. 이에 따라 실제 서비스 규모에서는 새로운 응답을 생성하는 비용을 여전히 관리를 해야 한다. 그래서 IC-Cache의 example manager는 utility 향상 가능성이 가장 높은 example만 선택적으로 replay하는 cost-aware 방식을 사용한다.
그래서 관건은 어떻게 utility 향상이 가능한 example인지 정량적으로 계산해야 하는 것인데, 이에 대해서 다시 example이 활용되는 것을 생각해본다면, 해당 example이 붙은 요청이 이미 작은 모델에서 충분한 품질을 내는 경우거나, example을 사용해도 여전히 품질이 낮은 경우이다. 그래서 IC-Cache는 다음과 같이 어떤 예제 가 주어졌을 때, 얻을 수 있는 잠재적인 향상을 다음 수식과 같이 정의한다.
response quality의 경우, example을 이용해 생성된 응답에 대해서 사용자의 피드백을 기반으로 측정이 된다. model cost는 요청을 처리하기 위해 사용된 모델의 상대적인 비용 (API 단가와 같은 비용) 등을 이용하여 측정이 된다. example 가 활용이 될 때마다 가 누적이 되고, 시간에 따른 변화에 대응하기 위해 EMA를 유지시킨다. 결론적으로 자주 재사용이 되거나, 여전히 큰 모델에 의존되는 example, 또는 품질이 낮은 응답을 만들어내는 example등이 replay 우선 순위가 높다.
IC-Cache의 example manager는 example을 순으로 정렬하여 replay 비용보다 기대 할 수 있는 이득이 큰 example만 사용한다. 즉, 잠재적인 향상 cut-off를 기준으로 이득보다 replay 비용이 커지는 순간 replay가 중단 된다.

위 그래프는 이러한 replay 방식 덕분에 Gemini-Flash가 Gemini-Pro보다 더 높은 품질을 달성하도록 돕는다는 것을 보여준다.
Example Cache Size 제한
IC-Cache의 example manager는 Databricks나 Gemini, DeepSeek, GPTCache와 같이 상용 시스템에서 사용하는 semantic caching 방식을 사용한다. 그래서 다음과 같은 특성으로 인해 IC-Cache는 작은 메모리 footprint만으로 동작이 가능한다.
- example을 plaintext 그대로 캐싱한다.
- 메모리 사용량이 매우 적다. 100만개의 LMSys-Chat example이 보통 1GB 정도만 차지한다.
- 여러 모델에서 재사용하기 쉽다.
- 실제 요청은 중복도가 높고, long-tail 분포가 나타난다.
만약 메모리가 제한이 되는 환경이라면, example manager는 online 캐시 관리 방식을 적용한다. 이 방식은 1-dimension knapsack 문제와 유사하기 때문에, weight을 example 텍스트 길이와 같은 저장 크기로 두고, value를 example이 만든 offloding 성공 횟수로 정의하면 결과를 example을 남길지 버릴지 결정하는 binary 선택으로 변환 할 수 있다. 또한 여기에 최근 사용 패턴을 더 강조하여 더 큰 가중치를 주고, 오래된 패턴을 점진적으로 제거할 수 있다.
이 방식은 메모리가 부족하거나, 백그라운드에서 정기적으로 실행하게 된다. 이에 따라 메모리가 매우 작은 환경에서도 일관적인 성능 향상을 IC-Cache가 제공 할 수 있도록 한다.
IC-Cache의 Privacy 정책
내가 IC-Cache를 팀 리더분한테 알려드렸을 때 나왔던 질문이기도 했는데, IC-Cache가 이전 요청을 재활용하기 때문에 privacy 문제가 있을 수 있다는 것이였다. 저자들은 IC-Cache가 사용하는 대부분의 use-case들 중 상당수가 non-private 데이터 기반임을 주장한다. (솔직히 그닥 설득력이 있진 않다.)
IC-Cache는 순위를 정하여 개인정보를 보호하는 DP 기반 synthetic cache를 사용하기 때문에, 원본 데이터 없이도 synthetic으로 example을 생성하여 캐시를 구성 할 수 있다고 한다. 이는 synthetic example을 보더라도 원본의 존재나 값을 추론 할 수 없도록 보장이 되어 있다고 한다.
Implementation
IC-Cache는 vLLM, HuggingFace runtime, LangChain을 지원하며, 백엔드는 위에서 소개한 3가지 컴포넌트가 각각 독립적인 프로세스로 여러 머신에 걸쳐서 분산 배포가 된다고 한다. 또한 각 프로세스는 구글이 만든 시스템답게 gRPC로 통신을 한다. Example retriever는 GPU 가속이 가능한 FAISS로 구현이 되었고, Request Router는 JAX로 구현이 되어 있다.
Faulit tolerance 또한 지원을 하는데, IC-Cache의 시스템 상태와 메타데이터를 여러 replica에 분산 저장하는 방식으로 수행한다. 이를 주기적으로 상태를 체크포인트 시키고, 실패 요청이 감지 되는 경우, 시스템은 자동으로 장애가 발생한 컴포넌트를 우회하고 요청을 직접 inference 백엔드로 전달한다.
실험 결과
IC-Cache 실험을 위해서 사용한 모델은 상용과 오픈소스 모델을 통틀어 다음과 같이 사용 되었다. 상용 모델의 경우, GCP에서 제공하는 Vertex AI API가 사용이 되었다.
- 상용 모델 : Gemini-1.5-Pro, Gemini-1.5-Flash
- 오픈소스 모델 : DeepSeek-R1, Qwen-2.5, Gemma-2, Phi-3
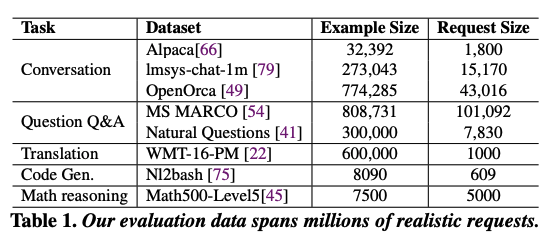
오픈소스 모델의 경우, A100으로 구성 된 GPU 클러스터가 사용되었고, 데이터셋은 다음 표와 같이 사용되었다.
IC-Cache는 과거 요청을 활용하여 실시간으로 모델의 능력을 증강하여 LLM serving을 최적화하는 시스템인데, 이러한 LLM inference framework를 보완하는 연구가 최초이기 때문에 다음 베이스라인과 비교되었다.
- w/o IC-Cache : IC-Cache를 사용하지 않은 일반적인 LLM serving system (vLLM)
- RouteLLM : 작은 모델과 큰 모델 중 하나를 binary classifier로 선택하는 모델 라우팅
- LongRAG : 외부 문서를 검색하여 추가 지식으로 활용하는 방식
- Semantic Caching : 과거 요청을 캐싱하여 embedding similarity 기반으로 캐싱 된 응답을 반환하는 방식
이에 대한 평가는 품질, latency, throughput 측면에서 평가가 되었다. 품질의 경우, LLM-as-a-judge 방식이 사용 되었는데, 상용 모델의 경우에는 DeepSeek-R1을 사용하였고, 오픈소스 모델의 경우에는 Gemini-1.5-Pro를 사용하였다.
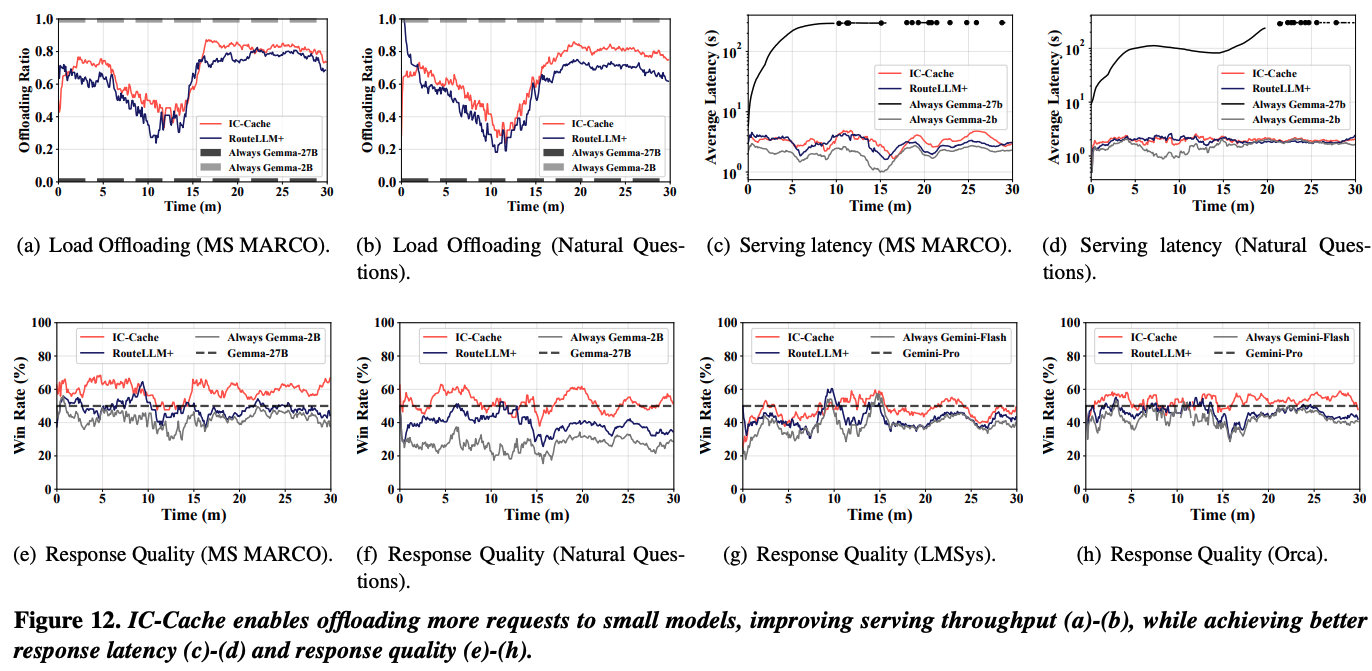
위 그래프는 online으로 부하가 발생 할 때의 offloading 비율, serving latency, 그리고 응답에 대한 품질을 보여준다. RouteLLM에 대비하여 9%까지 응답 품질이 개선이 되면서 거의 비슷한 수준의 latency와 throughput이 발생했는데, 이는 RouteLLM이 요청 난이도를 기반으로 라우팅을 하지만, 현재 시스템에 걸린 부하를 고려하지 않기 때문이다.
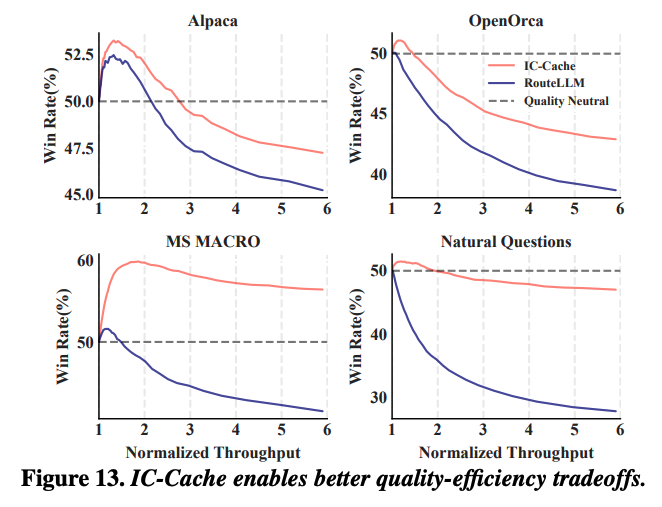
위 그래프는 IC-Cache가 현재 serving 부하를 인식하고, example을 적절하게 재활용하여 더 나은 품질과 효율성 사이의 trade-off를 제공한다는 것을 보여주기 위한 실험이다. Gemma-2-2B가 Gemma-2-27B 대비 4개의 데이터셋에서 기록한 win rate를 보여주는데, IC-Cache의 경우 동일한 품질 목표에서 RouteLLM에 비해 더 높은 throughput을 보여준다. 반대로 동일한 throughput 목표에서, IC-Cache가 더 나은 품질을 보여준다.
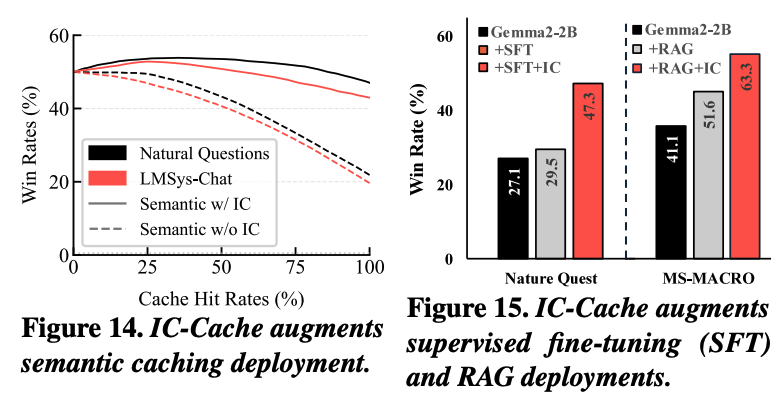
위 두 그래프 중 14번은 IC-Cache가 semantic caching과 결합 했을 때, 캐시의 hit rate가 달라지더라도 응답 품질이 일관되게 향상 되는 것을 보여준다. similarity 기준을 완화 시켜서 cache hit rate를 높였을 때, 관련성이 낮은 캐시 항목이 선택 되어 품질이 감소하는 경향이 발생한다. 이런 경우에 IC-Cache는 가져온 응답을 in-context example로 재활용하여 작은 모델의 출력을 개선시킨다. 이에 따라 최대 28%까지 품질이 향상되거나 동일 품질 기준에서 cache hit rate 기준 4.1배까지 효율이 증가한다.
15번 그래프의 경우, IC-Cache가 SFT와 RAG를 어떻게 강화하는지 보여준다. 두 방식은 기본적으로 품질을 향상시키긴 하지만, IC-Cache를 결합하여 사용 할 때 더 큰 성능 향상을 보여준다.
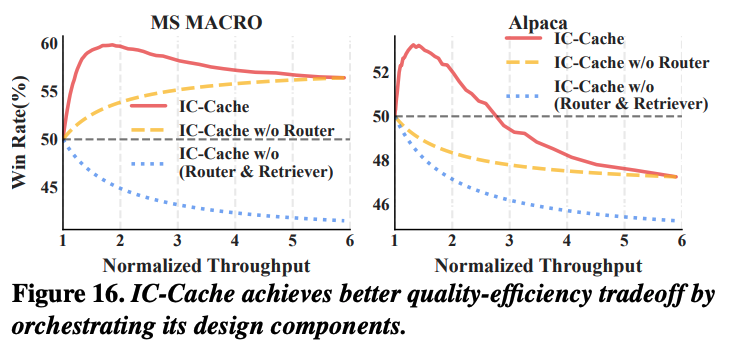
위 그래프는 IC-Cache의 performance breakdown을 측정한 그래프로, IC-Cache의 모든 컴포넌트를 조합했을 때의 성능이 제일 높게 측정이 되었다. request router가 없는 경우에서 단순히 throughput을 높이려고 하면 품질 저하가 발생했다.

위 그래프는 request router를 비활성화 하고 example replay만 활성화 했을 때의 성능을 측정한 결과이다. 다양한 모델에서 IC-Cache가 응답 품질을 크게 향상 시킨 것이 보이는데, 이는 일부 데이터셋에서는 작은 모델이 고품질의 in-context example이 들어갈 경우, 대형 모델보다 더 좋은 품질을 보여줄 수 있음을 시사한다.
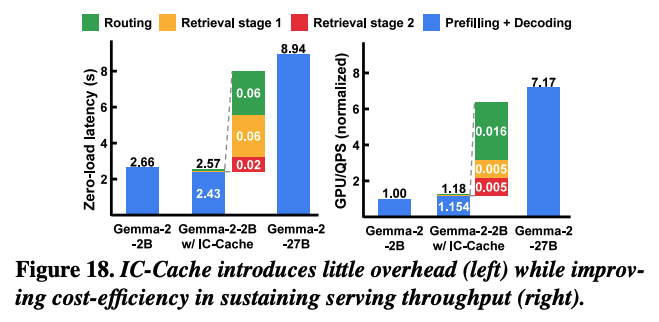
위 그래프는 Gemma 모델에 대해서 실행 단계별 세부 성능을 보여준다. 왼쪽 그래프의 경우, batching 없이 측정한 평균 contention-free latency 결과이다. IC-Cache를 같이 사용했을 때, 3%까지 감소가 되었는데, 이는 큰 모델에서 얻어온 example로 인해 평균 decoding 길이가 짧아졌기 때문이다.
우측 그래프는 비용을 분석한 그래프로, throughput 목표를 유지하는데 필요한 GPU 수가 동일한 조건에서 IC-Cache를 함께 사용한 것이 시스템 throuhgput이 5.1배 향상되었다.
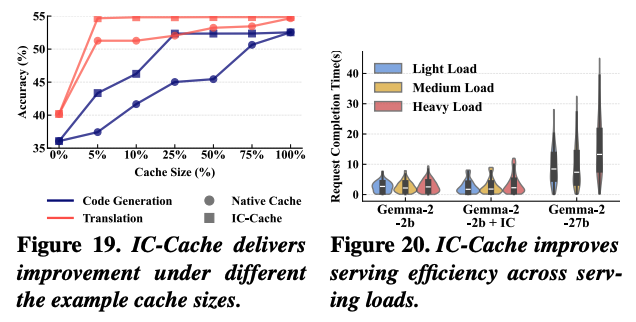
19번 그래프는 example cache의 크기로 인해 생성 품질에 미치는 영향을 평가하기 위한 그래프이다. Naive Cache는 example을 무작위로 보관하는 비교군으로, IC-Cache가 캐싱 사이즈가 아주 작을 때도 거의 포화에 가까운 성능을 보여준다.
20번 그래프는 서로 다른 QPS 조건에서 IC-Cache의 성능을 평가한 그래프이다. Light load가 QPS=1, medium이 QPS=2, 그리고 high load가 QPS=3 값이다. IC-Cache의 경우 decoding 길이의 분포 변화로 인해 전체 latency가 IC-Cache가 없는 경우와 거의 비슷하다.
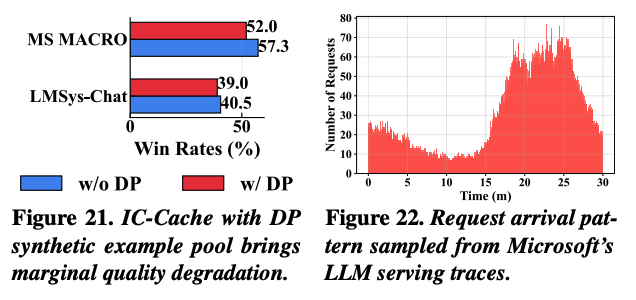
21번 그래프는 실제 사용자 질의가 포함된 데이터셋에 대해서 DP 기반의 synthetic 데이터를 사용했을 때, 폼질을 측정한 결과이다. 실제 데이터가 아닌 synthetic을 사용하는 경우 품질이 약간 감소하지만, IC-Cache가 없는 베이스라인에 비해 충분히 효과적인 품질을 보여준다.
(22번 그래프의 경우, IC-Cache 실험에 사용 된 online trace의 분포이다.)
결론 및 고찰
구글에서 나온 논문이라 그런지 실험 내용이 굉장히 많은 논문이였다. IC-Cache의 핵심은 큰 모델에서 만들어진 요청-응답을 기반으로 작은 모델의 응답 능력을 향상 시키는 것으로 보인다. 이로 인해서 전체 시스템의 부하를 줄이려는게 목적으로 보이는데, 여기에서 원리는 RAG와 비슷하지만 해결하고자 하는 문제 방향성이 다르게 느껴지는 것 같다. 다만 개인 정보 관련한 내용에 대해서는 솔직히 좀 미심쩍은 부분이 있다. LLM으로 요청을 routing 시키는 부분은 우리 팀에서도 충분히 사용할만한 내용인 것 같다.
