오늘은 간만에 시스템쪽 논문을 가지고 왔다. 한번쯤 speculative decoding 기능을 속도 향상 여부에 따라 on/off를 한다거나, speculative length 파라미터를 동적으로 조정하는 아이디어를 생각해본 적이 있을 것이다. 이 논문은 speculative decoding을 좀 더 시스템 관점에서 쓴 논문으로, 그러한 아이디어를 MoE 모델을 타겟으로 구현한 Cascade라는 프레임워크를 소개한다. 아직 어디에도 붙은 논문은 아니지만, 조만간 어딘가에 나올만한 논문인 것 같아서 가져왔다.
Speculative Decoding과 MoE

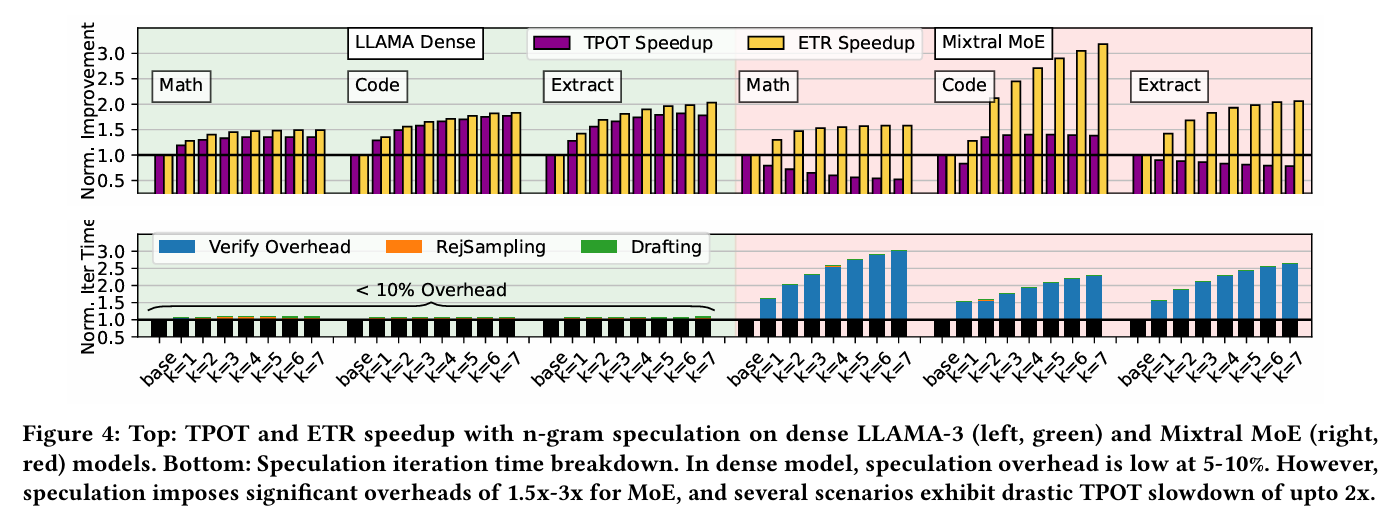
이전에 MoESD 논문에서 언급하였듯이, MoE는 speculative decoding과 어울리지 않는 워크로드이다. 보통 speculative decoding이 빠른 이유는, draft 토큰을 검증하는 target 모델의 시간은 하나의 토큰을 decoding 하는 시간과 거의 동일하기 때문이다. 하지만 MoE를 target으로 사용하게 되면, 발생한 토큰들은 각각 독립적으로 expert들을 활성화 시키기 때문에 통신 오버헤드가 발생하게 된다. 여기에 speculative decoding으로 인해 draft 모델에서 토큰을 전달하는 통신까지 추가하기 때문에 MoE에서는 speculative decoding의 성능 이득을 보기 어렵다. (b) 그림이 이러한 문제를 Mixtral 8x7B를 이용하여 보여주는 사례이다.
그림 (c)는 다양한 데이터셋에서 Mixtral에 speculative length 값을 바꿔가면서 성능을 측정한 결과이다. 모든 데이터셋에서 적어도 하나의 값 세팅에서 성능 저하가 발생하는 것을 볼 수 있다. 다른 데이터셋에서 이득을 볼 수 있는 값이라 할지라도, 어떤 데이터셋에서는 그 설정값이 속도 저하를 일으키기도 한다. 또한 보수적으로 값을 사용해도 성능 저하가 발생하는 데이터셋도 있다.
위와 같은 이유로, 동적으로 speculative decoding을 조절 할 수 있는 방법이 필요한데, 보통 speculative decoding은 현재 vLLM에서 설정 시, 항상 on 된 상태로 작동을 한다. 이전에 dense 모델의 값을 동적으로 바꾸는 논문도 있었지만, speculative decoding을 아예 꺼버리는 기능이 있는 논문도 없었다.
Speculative decoding의 오버헤드 구성
ETR (Effective Token Rate) = accept 된 토큰 수 / decoding step 수
Speculative decoding이 실제로 유효하게 확정된 출력 토큰 수를 시간 대비 얼마나 많이 생성했는가를 의미한다.
Speculative decoding은 ETR을 개선하면 할수록 LLM inference에서 decoding에 할당 되는 시간이 많이 줄어들게 된다. speculative decoding에는 3가지 주요 오버헤드가 존재하며, 이 오버헤드들을 개선 할수록 전체적인 시스템의 latency가 줄어들게 된다.
- draft overhead : draft 모델이 후보 토큰을 생성하는 오버헤드
- verification overhead : target 모델이 후보 토큰을 검증 하는 오버헤드
- reject sampling overhead : reject 발생 시, 토큰을 재계산 하는 오버헤드
위 그림 중 하단에 있는 그림은 각각 dense 모델인 LLaMA와 MoE 모델인 Mixtral에서 각 오버헤드가 발생하는 비율을 나타낸 그래프이다. 일반적으로 검증에 소요 되는 오버헤드는 굉장히 작은편이다. 그렇기 때문에 draft 모델의 후보 토큰 생성 오버헤드와 rejection 발생 시, 토큰을 재계산하는 오버헤드가 대부분을 차지한다. 그래서 ETR 값이 조금만 향상 되어도, 시스템의 latency는 대폭 감소하는 효과를 볼 수 있다.
하지만 정말 모든 모델에서 ETR 증가가 speed-up rate의 개선으로 이루어질까? dense 모델인 LLaMA의 경우, 위 그래프에서 ETR의 개선이 곧 TPOT의 speed-up rate 증가로 이루어졌다. 그에 비해 MoE인 Mixtral은 ETR이 개선이 되어도 TPOT의 speed-up rate는 전혀 개선이 되지 않고, 오히려 떨어지는 문제가 발생했다.
아래 그래프에서 MoE에 speculative decoding을 적용한 것을 분석했을 때, draft 모델의 생성이나 reject sampling으로 인한 오버헤드는 그대로지만, 검증으로 인한 오버헤드가 크게 증가했다. 이는 결국 MoE는 검증 단계에서 expert 사이에 통신 오버헤드가 증가하기 때문임을 알 수 있다.
모델과 워크로드에 따른 speculative decoding의 성능 변화
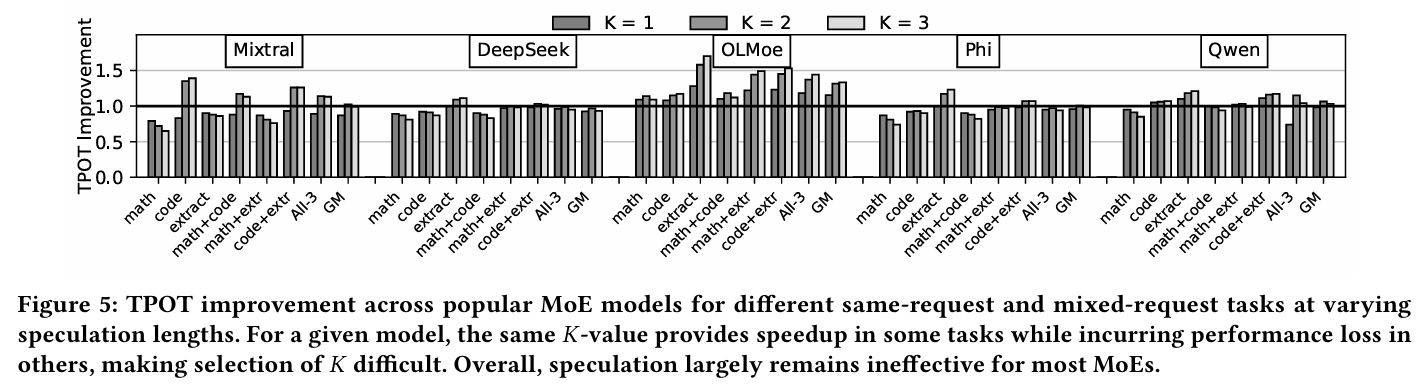
위 그래프는 MoE 모델과 사용한 데이터셋, 그리고 speculation length인 값에 따른 TPOT의 개선 정도를 나타낸 그래프이다. 위 그래프를 통해 알 수 있는 것은, 모델마다, 그리고 사용되는 input으로 들어오는 데이터에 따라 speculative decoding의 성능이 다를 수 있다는 점, 그리고 성능 향상을 보장하는 값이 없다는 점이다. 또한 Phi-MoE 같은 모델은 오히려 speculative decoding을 사용하지 않는 것이 좋은 성능을 보여줄 때도 있다는 점이다.
기존의 K값 조정 방식을 사용 할 수 없다
이전에 dense 모델들을 타겟으로 값을 동적으로 변경하는 방식은 주로 draft 모델의 출력 확률 분포를 이용하여 조정을 했다. 하지만 이러한 방식은 n-gram 기반의 draft 모델의 경우에는 확률 분포를 제공하지 않는다는 문제점이 있다. 또한 ETR을 최대로 향상 시키는 것에 초점이 맞춰져 있기 때문에 MoE처럼 ETR 개선이 TPOT speed-up rate 증가를 보장하지 않는 경우에는 사용하기 어렵다.
Speculation Utility
이 논문에서는 draft의 확률 분포를 이용하는 대신, speculation utility를 정의하여 speculative decoding의 on/off 여부와 값의 조정을 관리한다. 정의는 다음과 같다.
Speculation utility를 ETR 대신 사용하게 되면 다음과 같은 3가지 이점이 있다.
- ETR과 달리, speculation utility는 비용과 이득을 모두 고려한다. 그래서 speculative decoding의 실제 성능을 더 정확하게 예측한다.
- speculation utility가 1 이하로 떨어지면, speculative decoding은 더 이상 성능 향상이 되지 않는다. 따라서 런타임에서 동적으로 비활성화할 수 있는 유효한 기준이 된다.
- speculation utility를 최대화하는 것은 TPOT 속도를 직접적으로 최대화한다.
위 3가지에 대한 증명은 다음과 같이 할 수 있다. 우선, speculative decoding을 사용하지 않는 설정일 때, speculative decoding이 가지는 TPOT을 라고 정의한다. 그리고, speculation utility를 이라 표기하고, 이로 인해 개선 된 TPOT은 으로 표기한다.
우선 TPOT을 생각해봤을 때, TPOT은 초당 발생하는 토큰 수인 TPS의 역수로 정의 된다.
TPS는 그리고, ETR을 1번의 iteration에 걸리는 시간으로 나눈 값으로 환산이 가능하다.
speculative decoding을 사용하지 않는 방식의 ETR을 의미하는 값을 가진다. 이에 따라, 사용 할 때의 발생하는 오버헤드와 이득을 다음과 같이 계산을 한다.
speculation utility는 오버헤드 대비 이득값으로 정의를 한다고 앞서 언급하였다. 그렇기 때문에 다음과 같이 수식을 결합 할 수 있다.
위 수식을 정리하면, 최종적으로 수식은 아래와 같이 바뀐다.
보통 speculative decoding을 적용함으로써 이 감소해야한다. target 모델의 decoding 속도는 고정이 되어 있으므로, 결국 speculation utility를 증가 시키면 성능의 개선이 발생함을 알 수 있다.
하지만 MoE를 사용 할 때, 이를 개선 시키는 것이 어렵다는걸 앞서 그래프에서 확인했다. 이는 모델마다, 그리고 워크로드마다 다르기 때문에 일반화를 시키는 것은 어렵다. 결국 이 값을 정적 프로파일링만을 이용해서 적절한 값을 결정하는 것이 불가능하기 때문에, request 레벨이나 iteration 레벨에서 런타임으로 계산해야 한다.
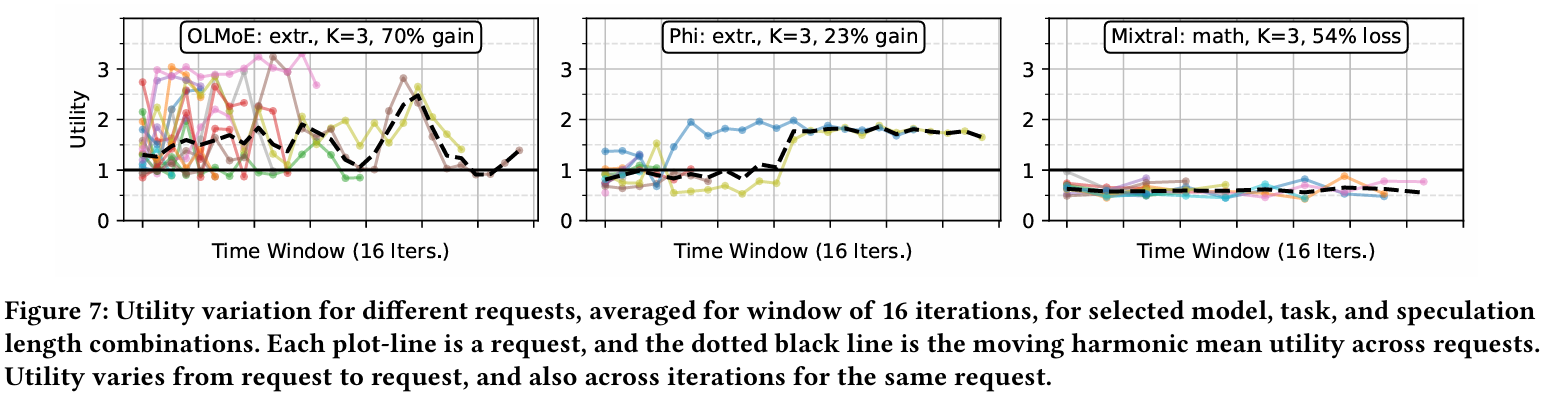
위 그래프는 동일한 데이터셋을 이용해도 요청마다 utility가 크게 변하는 것을 보여준다. Phi + extraction 조합은 iteration이 계속 될수록 utility가 증가하는 반면, Mixtral + math 조합은 되려 낮아진다. OLMoE + extraction 경우에는 아예 불규칙하게 요동치기도 한다. 다만, 이렇게 utility가 요동치는 워크로드라도, 짧은 구간에서는 temporal locality를 관측 할 수 있다. 그래서 만약 어떤 시점에 speculation utility가 증가하는 경향을 보인다면, 다음 몇 번의 iteration에서도 그러한 구간이 유지 될 가능성이 높다.
결론적으로, utility가 낮다면 일반적으로 값을 줄이면 해결이 될 수 있다. 반대로 초기의 utility가 낮더라도 시간이 지나면 개선이 될 여지도 있다. 그렇기 때문에 저자들은 iteration 단위에서 utility 모니터링을 수행해야 한다고 주장한다.
Cascade Design
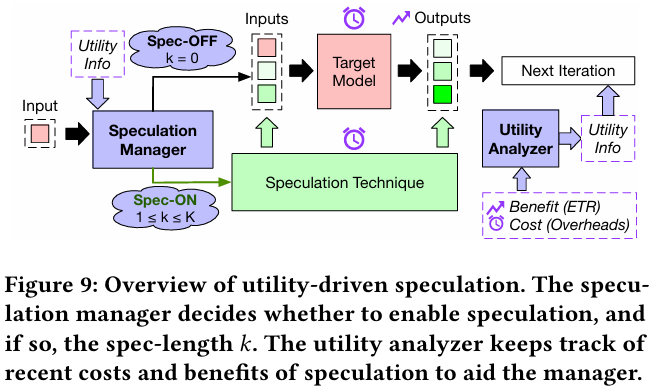
Cascade는 MoE를 워크로드로 사용 할 때, speculative decoding의 trade-off를 관리하기 위해 고안이 되었다. 현재의 speculation utility를 기반으로 speculation length 값을 동적으로 조정한다. 위 그림이 Cascade의 구조를 나타낸 그림으로, speculation을 켜고 끄거나 값을 조정하는 manager와 런타임에서 utility를 분석하는 analyzer 2가지로 구성이 되어 있다.
모든 의사결정은 speculation utility를 기반으로 이루어진다. 만약 값이 1 미만이 되는 경우, speculative decoding을 비활성화 한다. 그리고 1을 넘는 값이라면, utility를 최대화 시키는 값을 선택한다. 이에 따라 Cascade는 몇가지 중요한 점을 해결해야 했다.
1. Test-and-Set policy: 얼마나 값을 자주 조정해야 하는가?
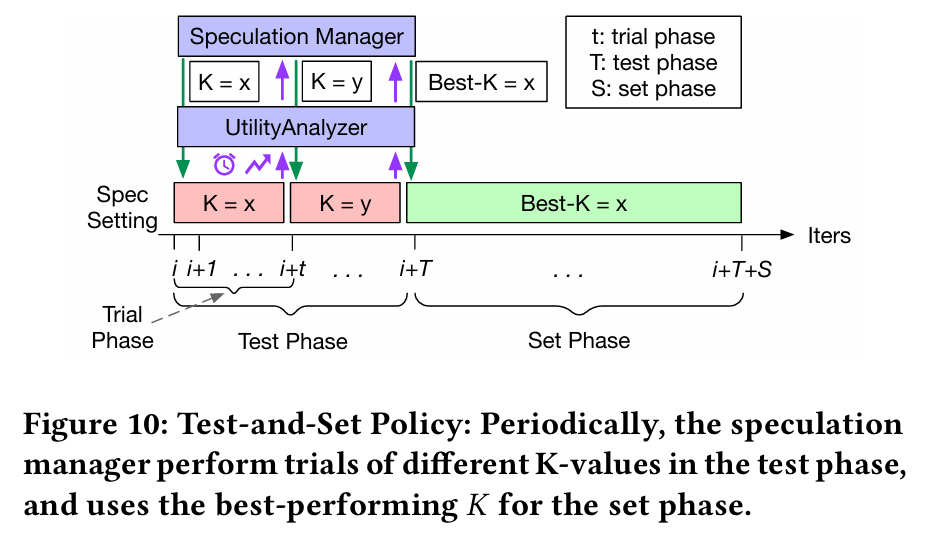
앞서 발견한 바에 따르면, utility는 수시로 변하기도 하지만 짧은 iteration에서는 어느정도 일정한 경향성을 보이기도 했다. 그렇기 때문에 Cascade는 매 iteration마다 값을 변경하지 않고, 주기적으로 결정하는 방식을 적용하였다. 각 interval의 끝에서, 최근 iteration들의 utility를 계산하고, 그 값을 기반으로 다음 interval에서 사용할 를 결정하는 방식인데, 문제는 utility 예측이 정확하지 않다면 잘못된 값을 사용하게 된다. 이런 경우에 오버헤드가 크게 발생하게 된다.
위와 같은 문제로 인해서 Cascade는 test-and-set이라는 방식을 사용했다. Speculation manager가 여러 값을 짧게 테스트를 하면서 각각의 값의 utility를 측정한다. 그리고나서 가장 높은 utility를 가지는 를 적용하는 방식이다. 초기 값은 manager가 최근 히스토리를 스캔하여 과거에 높은 utility를 보인 값을 선택해서 사용한다.
2. Slowdown 방지: Speculative decoding을 언제 비활성화 하는가?
MoE 모델 중에 일부는 speculative decoding를 붙이는 것 자체가 오버헤드를 발생 시키는 경우가 있었다. 이를 피하기 위해서 각 테스트 단계의 끝자락에서 utility를 계산하여 1 미만의 값이 나오는 경우에 다음 iteration에서 speculative decoding을 비활성화 시킨다.
만약 현재 값이 1인데 다음 utility가 1 미만 값으로 예측이 된다면, 이는 더 테스트 해봤자 오버헤드만 발생되기 때문에 테스트를 조기종료 시킨다. 그리고 speculative decoding이 비활성화 된 상태라도 utility는 지속적으로 모니터링 시킨다. 그리고 특정 iteration에 도달할 때 다시 테스트를 로 다시 시행하면서 utility가 다시 좋아졌는지 확인한다.
3. 테스트 오버헤드 최소화: Adaptive Back-off
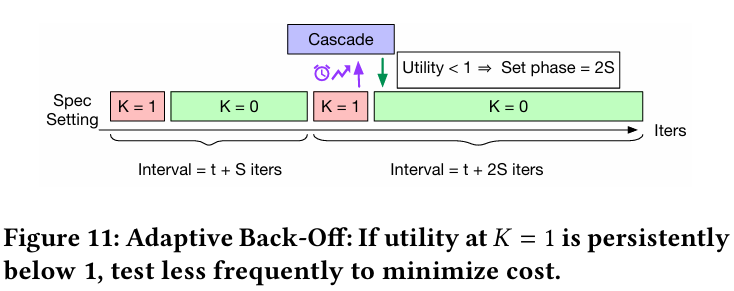
Cascade는 speculative decoding이 성능의 이득을 주지 않는다고 판단 할 때도 최소한의 오버헤드만 발생시키면서 테스트를 해야 한다. 그렇게 때문에 adaptive back-off라는 방식을 사용한다.
처음 시작하는 값은 항상 1 이상의 값을 사용한다. 그래서 sequence를 진행하다가 어떤 지점이든 가 0으로 떨어지는 순간을 테스트의 빈도를 낮춰야 하는 신호로 받아들이게 된다. 이 경우, set 단계의 길이를 2배로 늘려서 반복 테스트를 수행하는 빈도를 낮춘다. 즉, 위 그림처럼 이 되는 지점에서부터 테스트 빈도를 exponential하게 줄여서 반복 테스트를 최소화 시키는 전략이다.
4. Hill-Climbing Search를 통한 Utility 극대화 지점 찾기

Cascade는 utility가 일정 구간 동안 경향성을 보이기 때문에 이를 hill-climbing search를 이용하여 테스트 단계에서 이를 탐색한다. 위 그림은 이에 대한 방법을 보여준다. 검색에 사용 되는 입력값은 다음과 같이 3가지가 있다.
- 현재 trial에서 사용하고 있는 값
- 이전 trial에서 사용한 값
- 각 에 대해서 측정 된 utility 값
위 3가지 값을 비교해가면서 speculation manager는 utility가 증가하는 방향을 추론하고, 다음 값을 결정한다. manager는 총 번의 tral 동안 탐색을 하고, utility가 최대가 되는 로 수렴시킨다. 이 방식은 를 증가 시키면 처음에는 utility가 좋아지지만 어느 시점부터는 검증하는 비용이 이득이 되는 지점을 초과하기 때문에 utility가 감소한다는 점에서 시작한다.
예시를 들자면, 다음과 같다.
- 이전 < 현재 인데 utility가 증가한다면, 더 큰 가 좋을 가능성이 크다.
- 를 키웠는데, utility가 감소한다면, 더 작은 로 되돌아가는 것이 좋다.
또한 불필요한 테스트를 줄이기 위해서, 아래 조건 중 하나라도 만좆ㄱ하는 순간 테스트 단계를 조기에 종료시킨다.
- utility가 계속 감소해서 local maximum을 지난 것이 명확할 때
- 현재 이 되어서 speculative decoding을 비활성화 해야 할 때
- 연속된 사이에 utility 변화가 10% 이내로 수렴 할 때
Evaluation
실험 세팅

Cascade는 vLLM v0.6.6 버전에서 구현이 되었다. 실험에는 5가지 MoE 모델 (Mixtral, DeepSeek-v1, Qwen-1.5, Phi-3.5, OLMoE)가 사용 되었다. 각 MoE에 대한 expert의 수와 같은 정보는 위 표와 같다. 데이터셋은 GSM8K, HumanEval, MT-Bench 3가지를 사용했고, 이들은 모두 decoding의 비중이 높은 워크로드다.
Mixtral의 경우에는 EAGLE이 적용된 방식을 사용했지만, 나머지 MoE들은 EAGLE draft가 없기 때문에 n-gram 기반 speculative decoding을 적용하였다. 이 MoE들은 RTX 6000에서 사용이 되었다.
실험 결과
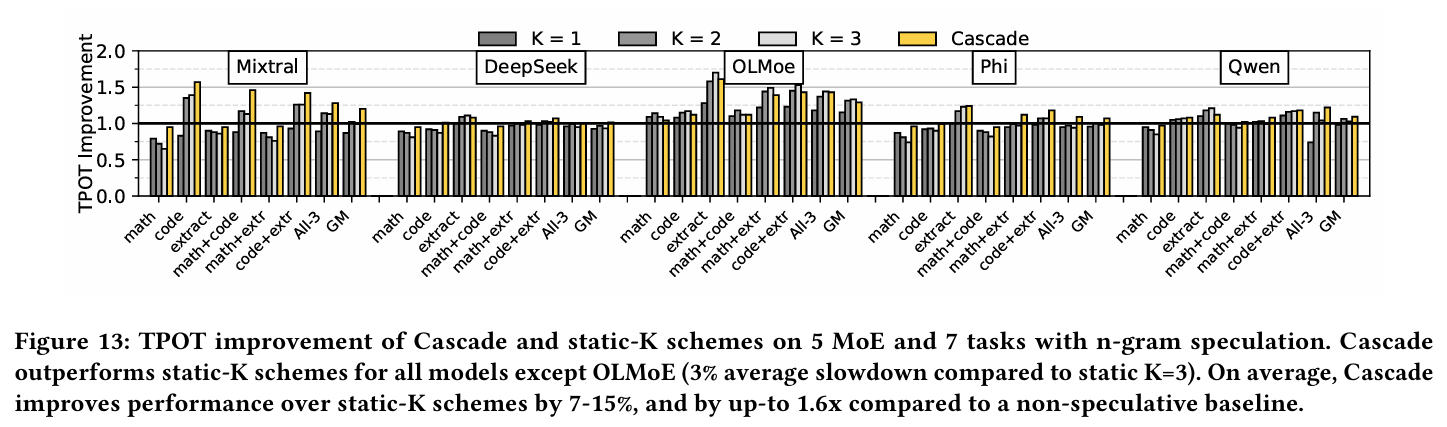
위 그래프는 으로 고정하여 사용한 speculative decoding과 Cascade를 비교한 결과이다. Cascade는 최악의 경우 5%까지 성능이 기준선보다 하락하지만, 고정적인 를 사용하는 경우, 최대 54%까지 성능이 하락한다. 일부 모델과 데이터셋에서 Cascade의 성능이 살짝 밀리는 경향이 있는데, 이는 Cascade가 값을 탐색하면서 일시적으로 성능이 낮은 값을 사용하는 경우가 발생하기 때문이다.
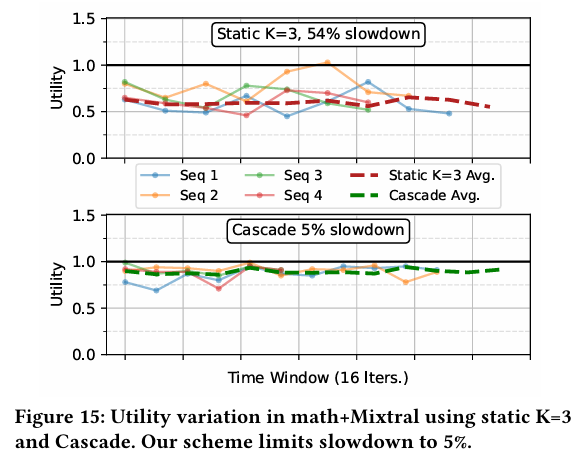
위 그래프는 임의로 선택 된 4개의 요청에 대해 iteration 단위에서의 utility 변화를 보여준다. 를 고정한 경우에는 utility의 변화가 큰 폭으로 나타나면서 최대 54%까지 성능이 저하되지만, 이에 비해 Cascade는 5%만 성능이 저하 되어서 안정적이라고 주장한다.
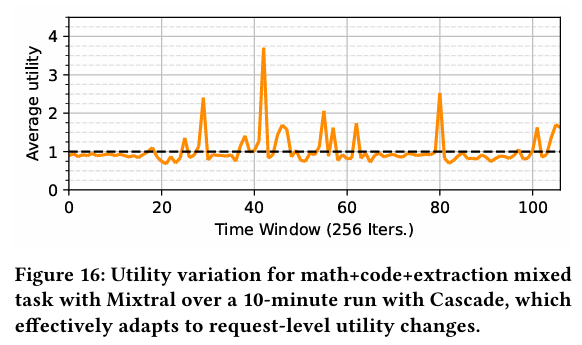
위 그래프는 Mixtral에서 각각의 데이터셋을 1/3씩 섞어서 수행 했을 때, 런타임에서 utility 변화를 측정한 결과이다. speculative decoding이 유리할 때는 Cascade의 utility를 1 언저리로 유지하면서 성능 저하를 최소화 시킨다. 반면 유리해지는 경우, 동적으로 를 조절하면서 성능을 극대화 시킨다. 결과적으로 데이터셋에 상관 없이 Cascade는 지속적으로 utility를 최대화 시킨다.

위 그래프는 EAGLE과 Cascade의 호환 여부를 확인하기 위한 실험 결과이다. 각 값은 EAGLE에 적용된 값들로, EAGLE은 feature 레벨에서 다음 토큰을 예측하기 때문에 비교적 성능 저하가 적은 편이다. 하지만 값이 증가함에 따라 오버헤드가 증가하는데, Cascade와 겸용하여 사용하는 경우에 이를 피할 수 있다.
- EAGLE에 대한 자세한 설명은 아래 링크에서 확인 할 수 있다.
https://velog.io/@with1015/ICLM24-EAGLE-Speculative-Sampling-Requires-Rethinking-Feature-Uncertainty
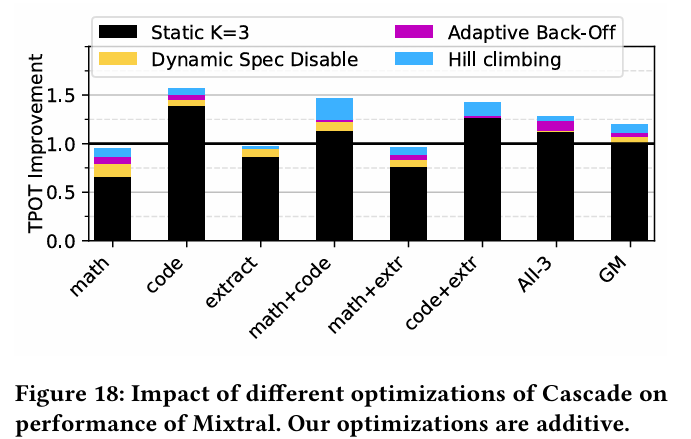
마지막으로 Cascade에 사용 된 최적화 기법에 대해 실험한 결과이다. 동적으로 speculative decoding을 on/off하는 기능과 adaptive back-off, 그리고 hill-climbing search를 각각 분리하여 보여준다. 최적화를 하나도 사용하지 않은 경우에 대해서는 값을 사용한다.
- hill-climbing의 경우, 전반적으로 최대 utility를 보여주는 값을 찾아내기 때문에 성능 향상에 전부 기여를 한다.
- 동적으로 on/off 하는 기능은 일반적으로 성능 저하가 발생할 때, 이를 완화 시켜주는 역할에 기여한다.
- adaptive back-off는 일부 speculation에 잘 반응하지 않는 작업에 대한 오버헤드를 추가로 줄여준다.
결론 및 고찰
Cascade 논문은 결론적으로 MoE를 target 모델로 사용을 할 때, speculative decoding의 기능을 동적으로 켜고 끄거나 speculation length를 조절함으로써 성능을 극대화하려는 것이 결론이다. 이 방식의 가장 큰 장점은 draft 모델이나 target에 새로운 head를 추가하여 학습을 시키는 방법이 필요 없고, 시스템적으로 문제를 풀려고 했기 때문에 적용이 쉽다는 것이 장점으로 보인다. 다만, 여전히 MoE에 speculative decoding을 붙이면 성능 개선이 되지 않는 워크로드가 존재한다는 점에서 단점이라고 할 수 있을 것 같다. (물론 이를 완화시키려고는 했지만.)
그리고 batch size를 조절해가면서 실험을 했으면 어떨까 하는 생각도 들었다. batch size가 커지는 경우도 speculative decoding처럼 활성화 되는 expert가 많아지는 상태가 되기 때문에 아마 실험 결과가 달라질 것이라고 생각한다. 일반적으로 사용자들이 MoE를 사용하는 환경은 continuous batching이 적용된 상태이기 때문에 이에 대한 아쉬움이 남았다. 거기에 이 논문보다 나중에 나온 논문이긴 하지만, MoESD처럼 특정 batch 구간에서 MoE에 적용 된 speculative decoding이 성능을 향상시킨 사례도 있기 때문에, 이에 대해서 궁금하긴 하다.
