[SOSP'23] Efficient Memory Management for Large Language Model Serving with PagedAttention
ML System
vLLM은 industry/academy를 막론하고 거의 LLM inference의 표준 프레임워크로 자리 잡았다.
사내에 만드는 모든 LLM inference engine으로 vLLM을 사용하고 있고, 내부 코드까지 확인하고 오픈소스 기여까지 시도 할만큼 많은 관심을 갖고 보고 있는 만큼 이 논문을 한 번쯤 리뷰하고 싶었다.
Batch inference 문제
어느 ML 모델들이 그렇듯 LLM 또한 inference 단계에서 배치로 요청을 묶어서 처리하는 방식이 GPU의 활용률을 높이는 방법일 것이다. 특히 LLM의 경우, Transformer 아키텍쳐에 의존하는 만큼 decoding 단계에서 발생하는 token을 하나씩 생성하는 auto-regressive 방식이 대부분의 처리 시간에 소모 된다.
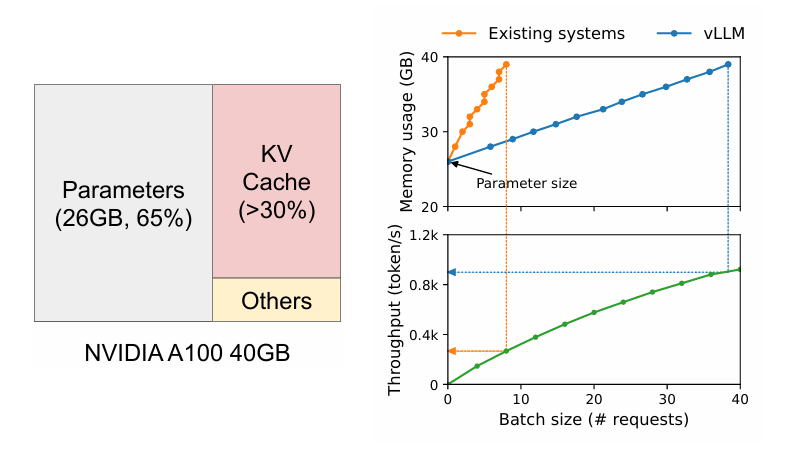
위 그림은 A100에서 13B 크기의 LLM 추론 시 할당 되는 메모리를 어떻게 사용 되고 있는지 그 비율을 나타낸 그림(왼쪽)과, batch size에 따른 thoroughput 및 메모리 사용량을 나타낸 그림(오른쪽)이다.
우선 왼쪽 그림을 보면, 대부분 모델 파라미터에 메모리를 할당을 하고, 남은 메모리를 KV Cache, 그리고 activation과 같은 기타 파라미터에 사용을 한다. 정적으로 할당되는 모델 파라미터와는 달리, KV Cache는 동적으로 할당 되는 파라미터인 것에 비해 GPU의 많은 부분을 차지하고 있음을 알 수 있다.
오른쪽 그림의 경우, batch size 증가에 따른 vLLM과 다른 system (NVIDIA의 FastTrasnforemer, FrendliAI의 Orca) 사이의 비교이다. vLLM의 경우, batch size나 parameter의 증가에도 GPU memory 사용량이 급증하는 구간이 없기 때문에 큰 batch size에서도 높은 성능이 나온다.
그러나 LLM의 경우, 단순히 batch inference를 하는 것에 몇가지 문제가 존재한다.
- 요청이 언제 도착할지 알 수 없다. 먼저 도착한 요청이 batch 대기 시간으로 인해 나중에 오는 요청을 기다린다거나, 새로운 요청이 이전 요청이 끝날 때까지 기다려야 한다.
- batch에 속한 각 요청들마다 길이가 다르다. 그렇기 때문에 일반적인 batching 기법들은 padding을 통해 입/출력의 길이를 맞춰줘야 하고, 이는 메모리 낭비가 된다.
LLM inference의 메모리 문제
두 번째로 LLM inference의 문제는 GPU 메모리 관리에 있다. 아무리 batching 기법을 잘 활용하더라도 결국 GPU 메모리는 한계가 존재하기 때문에 이를 잘 활용하는 것이 중요하다. LLM은 특히 KV Cache를 활용해야 하기 때문에, LLM을 serving하는 시스템은 memory-bound의 성격을 가지게 된다.
KV Cache 크기와 decoding 알고리즘에 따른 메모리 관리 문제
단순히 모델의 Attention 크기에 비례하여 KV Cache가 증가하기 때문도 있지만, decoding 알고리즘에 따른 복잡성도 고려해야 한다. 예를 들어, 사용자가 하나의 input prompt에서 무작위 샘플을 요청하는 작업이나, beam search 같은 방식은 KV Cache의 많은 부분을 공유 할 수 있지만, auto-regressive로 인한 생성 작업은 샘플별 결과가 context와 token position이 달라지기 때문에 공유 하기 어렵다.
Scheduling에서 알 수 없는 입출력 길이
앞서 언급하였듯, input으로 들어오는 요청이 어느 시점에 얼마만큼의 길이가 들어올지, 요청들로 batch size를 얼마만큼 받을 수 있는지 알 수 없다. 또한 요청이 스케줄링이 될 당시에는 LLM inference로 인해 얼마만큼의 decoding token이 발생할지 알 수 없다. 그렇기 때문에 새로운 요청이 들어왔을 때, KV Cache를 얼마만큼 재할당을 하고 스왑을 할 지 결정하기 어려운 문제가 있다.
기존 시스템의 메모리 관리 문제

기존 시스템들은 메모리를 연속적으로 사용한다. 그렇기 때문에 KV Cache 또한 요청에 대해 연속적으로 메모리를 할당하게 된다. 하지만 LLM의 경우, output의 길이를 예측 할 수 없기 때문에 출력 할 수 있는 최대 sequence 길이에 맞추어 고정적인 chunk 단위로 할당을 하게 된다.
위 그림의 경우, 요청 A는 최대 sequence 길이가 2048인 요청이고, B는 512인 예시를 들어 발생 할 수 있는 문제를 보여준다. 요청 A는 LLM이 생성하는 output의 길이를 알 수 없기 때문에, 2048 크기의 메모리를 사전에 미리 잡아 놓았다. 하지만 실제로 요청은 10개의 토큰만 생성했고, 이로 인해 2038개의 internal fragmentation이 발생했다. 요청 B의 경우도 동일한 이유로 507개의 메모리 슬롯이 낭비가 되었다. 또한 두 요청 사이에 buddy allocator로 인한 external fragmentation도 발생한다.
vLLM과 Paged Attention
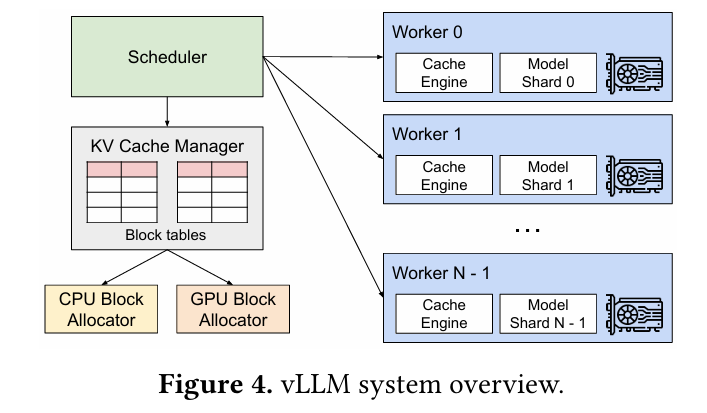
결국 위에서 발생하는 메모리 할당 문제와 batch 스케줄링의 문제를 해결하기 위해서, vLLM이라는 serving engine과 함께 기존에 Operating System에서 사용하는 Paging에 영감을 받아 Paged Attention이라는 KV Cache 메모리 관리 기법을 고안해냈다.
vLLM은 중앙화 된 스케줄러가 하나 있고, 이 스케줄러가 각 GPU worker들의 실행을 관리한다. 그리고 KV Cache Manager는 스케줄러의 명령을 받아서 Paged Attention 방식을 이용하여 물리적인 GPU 블록을 할당하고 관리하게 된다.
Paged Attention
Paged Attention의 핵심은 OS의 virtual memory를 physical memory에 매핑 시키는 paging처럼, KV Cache도 paging 방식으로 연속적인 공간이 아닌 비연속적인 공간에 할당하자는 것이 아이디어이다.
우선 Paged Attention은 각 sequence를 특정한 블록 단위로 분할한다. 만약 블록 크기가 라면, key 값들을 모아 놓은 블록과 value 값을 모아 놓은 블록을 다음과 같이 정의 할 수 있다.
그리고 이전에 Transformer 리뷰에서 사용하였던 Attention 연산 수식에 이 블록들을 대입 할 수 있게 되는데, 그렇게 대입을 해보면 다음과 같이 작성 할 수 있다.
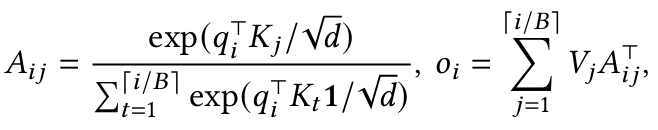
결국 이렇게 되면 Attention 또한 블록 단위로 정리 할 수 있게 된다.
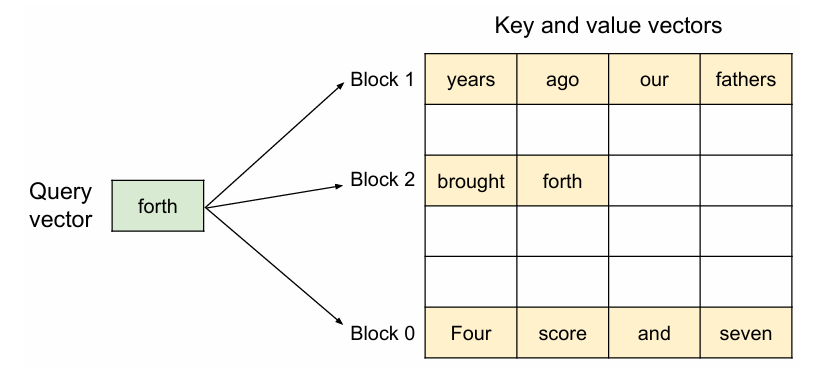
vLLM은 이러한 블록 단위의 KV 연산을 PagedAttention 커널로 구현하였고, 이 커널은 서로 다른 KV 블록을 개별적으로 식별하여 위 그림처럼 가져오게 된다. 쿼리에 대한 key와 value 벡터는 3개의 블록으로 나누어져 있다. 물리적인 메모리 상에서 PagedAttention에 의해 각 블록은 연속적으로 할당되어 있지 않다.
위 그림을 예시로 들면, 쿼리 벡터인 forth 는 KV block 중에서 0번 key 블록인 "Four", "score", "and", "seven" 과 결합하여 0번 Attention block을 만들어 낼 수 있다. 그리고, 0번 Attention block은 0번 value block과 결합하여 결과값을 만들어내게 된다.
결론적으로, KV를 블록 단위로 관리하면서 비연속적인 할당으로 메모리 관리를 하여도, Attention 또한 블록 단위로 계산을 독립적으로 하는 것이 가능하기 때문에, Page 방식으로 Attention 계산을 수행하는 것에는 지장이 없게 된다.
KV Cache Manager
앞서 언급하였듯이 vLLM의 KV Cache 메모리 관리 기법은 OS의 virtual memory와 동일하게 paging 방식을 사용한다. KV Cache는 고정 된 크기의 블록으로 나눠지는데, 이것을 OS의 page와 유사하게 바라본다.
request 하나가 들어오면, KV Cache는 logical KV 블록을 연속적으로 할당한다. 그리고 새로운 토큰에 대해서 그에 대응 되는 KV Cache가 왼쪽부터 채워지게 된다. 그리고 채워지지 않은 공간들은 나중에 토큰 생성을 위해서 남겨두게 된다.
이러한 동작들은 GPU worker의 block engine에서 이루어지는데, block engine은 block table을 가지고 있고, 이를 이용하여 physical KV block과 logical KV block을 매핑하는 역할도 수행한다.
vLLM Decoding with Paged Attention
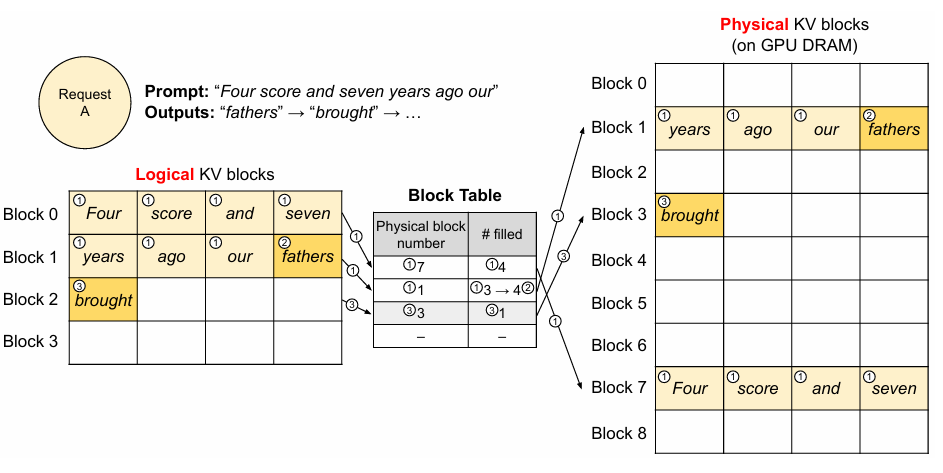
위 예시는 vLLM에서 paged attention이 decoding 단계에서 어떻게 활용되는지 보여주는 예시이다. vLLM은 처음부터 최대 생성 길이 만큼의 메모리를 할당하지 않고, 프롬프트 계산 도중 생성 된 KV cache를 담는데 필요한 최소한의 KV 블록만 할당한다. 위 예시에서, 초기 프롬프트는 7개의 토큰을 가지고 있고, prefill 단계가 완료 된 후, logical block 0번부터 1번까지 7개의 공간을 할당시킨다.
이 후, decoding 단계에 진입하면, Prefill 결과에 따라 첫번째 토큰이 생성 될 것이다. logical block 1번과 physical 블록의 1번 마지막 공간이 남아있었기 때문에, 이를 채우고, block size가 한계에 이르면 다음 블록을 할당하게 된다.
위 예시의 "fathers" 토큰은 블록 공간이 남아있었기 때문에 1번 블록에 할당이 가능했지만, 이 후에 생성 된 "brought"는 새로운 블록이 할당되었다. 그리고 새로 할당 된 블록의 매핑 정보는 block table에 기록이 되었다.
요청의 처리가 완료 되고 나면, 블록 공간은 할당을 해제하고 다음에 들어오는 요청에게 재할당 하게 된다. 이러한 방식으로 GPU 메모리를 동적으로 블록 단위로 할당하기 때문에 KV Cache 공간을 좀 더 압축하여 사용 할 수 있고, 이로 인해 기존보다 더 많은 요청을 batch로 받아들여 처리량을 증가 시킬 수 있다.
Parallel Sampling
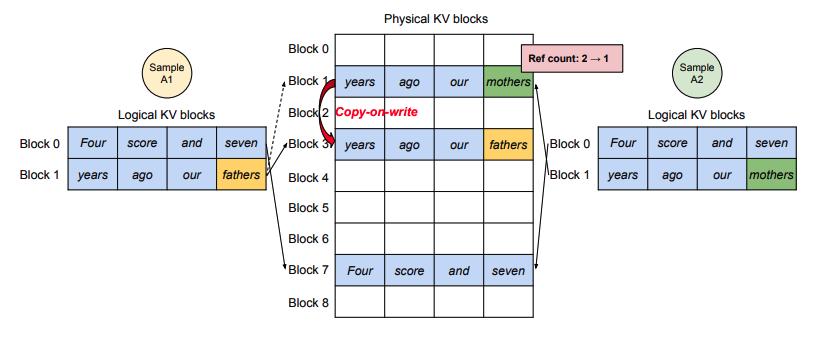
앞서 언급한 decoding 단계에서 paged attention의 활용 방식은 greedy sampling에 의한 방식이였다. Paged attention 방식은 greedy sampling 외에도 parallel sampling에서도 사용 할 수 있다. 하나의 요청이 다수의 sequence를 생성하는 경우는 바꿔 말하면 다수의 출력이 동일한 프롬프트를 공유한다는 말이 된다. Paged attention은 이러한 경우 physical block에 Copy-on-Write 방식을 구현하여 사용한다.
위 그림의 예시처럼, 각 logical KV block에는 독립적으로 KV cache 블록이 존재 하는 것처럼 보이지만, physical KV block에서는 이미 블록이 모두 할당이 되어 더이상 토큰을 할당 할 수 없는 7번 블록을 하나로 공유하고, 1번과 3번 블록에서 각각 발생한 토큰을 할당하게 된다.
이러한 방식은 공유 하는 입력 프롬프트가 클수록 더 효율이 좋다는 장점이 있다.
Beam Search
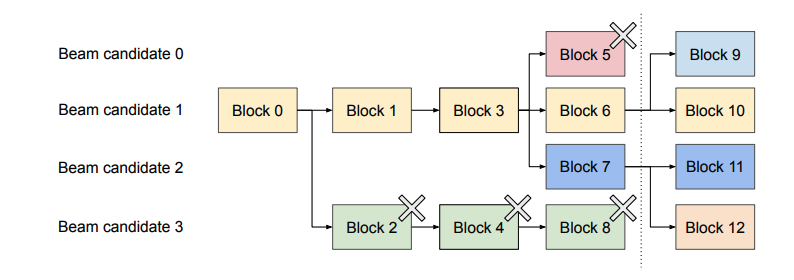
빔 서치의 경우, KV Cache 블록 관점에서 보면 후속으로 생성 되는 블록들이 여러 후보들 사이에서 공유 될 수 있다는 점이 있다. OS에서 fork를 사용 할 때 발생하는 process tree와 유사한데, 이를 위 예시 그림을 통해 살펴보면 다음과 같다.
우선 빔 서치의 너비 ()인 상황을 가정한다. 왼쪽에서 오른쪽으로 빔 서치 후보가 생성이 되는데, 모든 후보들은 0번 블록을 공유 하고 있다. iteration이 점점 진행 되면서 유망하지 않다고 결정 되는 토큰이 포함 된 KV block들은 제거가 될 것이고, 점선 이후에 마지막 iteration이 끝나고 나서 생성 된 블록들은 모두 3번 블록까지 공유하게 된다. Parallel sampling과 동일하게 vLLM은 Copy-on-Write를 사용하기 때문에 빔 서치에서 공유 되는 KV Cache도 paged attention에서 동일하게 사용 할 수 있다.
Shared Prefix
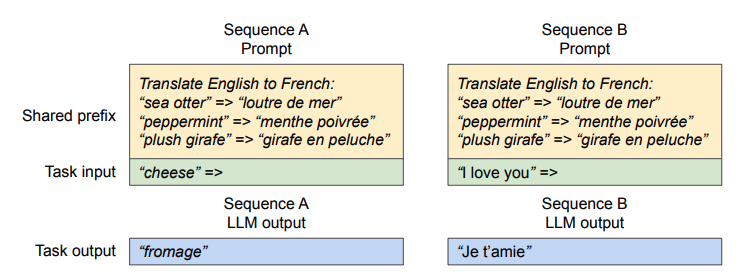
흔히 우리가 ChatGPT 같은 LLM 서비스나 그 외에 모델을 사용 할 때, 보통 system prompt를 넣어서 지시사항이나 input, output의 포맷을 제한하곤 한다. vLLM에서는 이를 Shared Prefix라고 지칭하는데, 결국에는 자주 사용되는 systemp prompt도 prefix cache라는 이름으로 vLLM에서 KV Cache를 저장하여 사용 할 수 있다.
앞서 언급한 parallel sampling의 Copy-on-Write를 이용하여 system prompt를 공유하는 요청들 사이에는 physical block에서 공통인 부분을 매핑 시키고, 그 외에 사용자 입력에 해당 되는 부분을 추가로 블록을 할당 시킬 수 있다.
Mixed Decoding Methods
결론적으로 vLLM은 KV Cache를 블록 단위로 관리하면서 요청 사이에 공유 할 수 있는 부분은 block을 physical block으로 공유하고, 나머지 공유 되지 않는 부분은 추가로 블록을 할당하여 관리한다. 이 모든 방식을 page table처럼 관리하기 때문에 sampling 요구 사항이 다른 것을 사용하더라도 기존 방식에 비해 효과적으로 메모리를 관리 할 수 있다.
vLLM Schduling & Preemption
vLLM의 메모리 관리 방식은 앞서 언급한 paged attention을 이용한다. 그렇다면 다음에 살펴볼 것은 스케줄러를 어떻게 사용하는지에 대한 내용이다. vLLM은 기본적으로 FCFS 방식을 사용하기 때문에 먼저 들어오는 요청을 먼저 처리한다. 이를 통해 fairness에 대한 점은 크게 걱정하지 않아도 되지만, 문제는 메모리 관리 방식에서 오는 어떤 block을 eviction 할 것인가이다. 그리고 eviction이 된 경우, 만약 그 블록이 다시 필요해지면 어떻게 복구 할 것인가도 고려해야 한다.
보통 cache eviction은 적절한 휴리스틱을 기준으로 자주 사용되는 블록이나 곧 접근 될 블록을 예측하곤 한다. 하지만 vLLM의 경우, all-or-noting 방식을 이용하는데, 이는 동일한 sequence에 속한다면 거기에 속한 블록이 모두 항상 함께 접근이 된다는 LLM의 특성에 기인하기 때문이다. 즉, 한 sequence의 모든 블록은 제거되거나 제거 되지 않는다.
만약 빔 서치처럼 하나의 요청에 여러 seqeunce가 존재하는 경우, 이들을 모두 sequence 그룹으로 묶어서 gang-scheduling 방식으로 사용 할 수 있다. 이는 seqeunce 그룹끼리는 일정 부분 KV cache 블록을 공유하기 때문이다.
제거 된 블록을 다시 복구하는 방식은 Swapping과 Recomputation 두 가지 방식을 고려 해볼 수 있다.
-
Swapping은 기존에 OS에서도 virtual memory에서도 사용 되는 기법으로, vLLM에서는 CPU allocator에서 이 기능을 담당하고 있다. vLLM에서 새로운 토큰 할당을 위한 공간이 모자라면, 일부 sequence의 KV cache를 CPU 메모리로 이동 시킨다. 그리고 새로운 토큰을 할당하고, 해당 sequece가 완료 되어 GPU memory가 해제되고 났을 때 CPU로 잠시 옮겼던 KV Cache를 불러들인다.
-
Recomputaiton은 말 그대로 sequence가 다시 스케줄링 될 때, KV Cache를 다시 계산하는 방법이다. 재계산이 될 경우, 초기 계산보다 latency가 더 작을 수 있는데, 그 이유는 decoding 단계에서 이미 생성 된 토큰들을 원래의 사용자 프롬프트와 결합하여 새로운 프롬프트로 만들어 사용하면 초기보다 계산량이 작아지기 때문이다.
Distributed Execution
LLM의 경우, 요새는 H100으로도 버티기 어려울 만큼의 파라미터를 가지고 있는 것들이 많다. vLLM은 이런 모델들을 위해서 Pipeline parallelism이나 Tensor parallelism 또한 지원한다. 내부적으로 all-reduce를 이용하고, 하나의 KV Cache를 다수의 GPU worker가 공유하면서 각 GPU worker는 각자가 독립적인 attention 헤드를 갖고 있기 때문에, 실제로는 KV Cache를 테이블에서 독립적으로 매핑하여 사용하게 된다.
실험 결과
vLLM은 실험에서 Orca와 FastTranformer를 비교군으로 사용했다. Orca는 FrendliAI에서 만든 논문인데, 이는 오픈소스가 아니기 때문에 직접 구현했다고 한다. (이에 대한 재밌는 일화도 있다고 전해들었다.) 그리고 모델은 OPT를 사용하였다. 데이터셋은 Alpaca, ShareGPT를 사용하였고, GPU는 GCP를 통해 A100을 사용하였다.
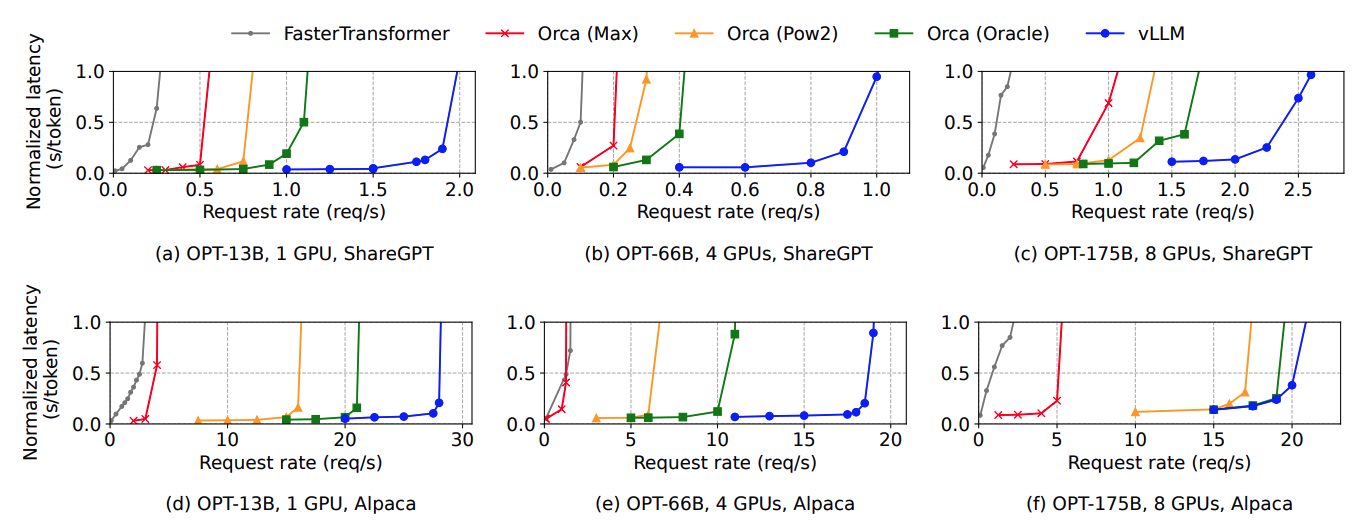
우선 기본적인 greedy sampling을 사용하는 경우의 그래프를 보자. 그래프를 보면 요청이 서서히 증가하다가 갑자기 latency가 급격하게 치솟는 구간이 있다. 이는 요청률이 serving system의 처리 용량을 초과하게 되면 queue의 길이가 무한하게 증가하게 되는데, 이로 인해 응답 시간 또한 계속 늘어나는 것이 원인이다.
vLLM의 경우, 요청률이 치솟는 구간이 비교군들에 비해 상대적으로 더 큰 값으로 잡혀 있다. 이는 vLLM이 메모리를 효율적으로 관리하기 때문에 더 많은 요청을 batch로 묶어서 처리 할 수 있기 때문이다.
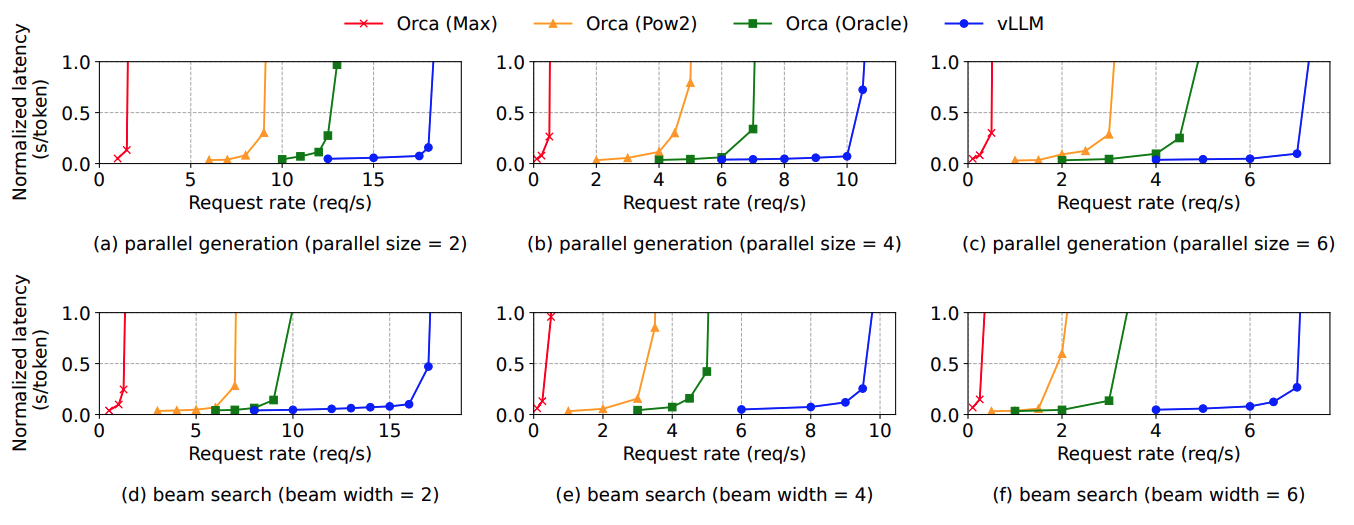
이러한 경향은 다른 sampling 방식을 사용해도 동일하게 나타난다. Parallel sampling이나 beam search의 경우에도 vLLM이 Copy-on-Write 방식으로 효율적인 메모리 관리를 하기 때문에 vLLM이 더 많은 요청을 처리 할 수 있다는 결과를 얻게 된다.
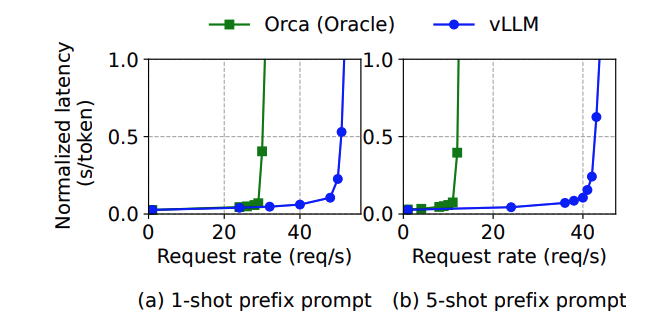
Shared prefix 실험에서는 LLaMA 13B 모델에 WMT16 (en-de) 데이터를 사용하였다. 그리고 1-shot과 5-shot으로 나누어 실험하였다. 위 그래프와 같이 Orca 대비 1.67배 더 높은 처리량을 보여주었고, 이 역시 vLLM의 메모리 관리 방식이 system prompt 처리에도 효과적이라는 것을 보여준다.
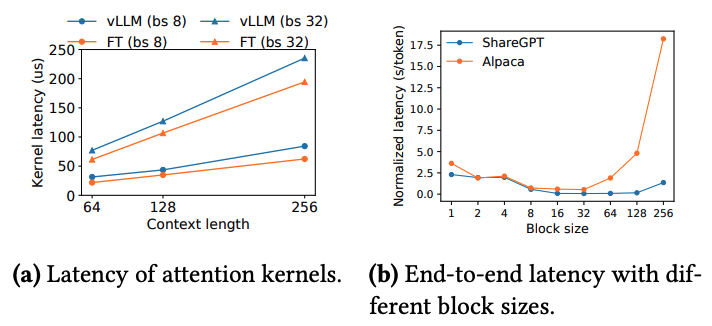
위 그래프 중 (a)는 attention kernel 연산에서 발생하는 오버헤드를 관측한 결과이다. vLLM의 경우 attention 연산을 할 때 블록 테이블을 접근하거나 추가적인 분기문을 실행하는 것으로 인해 FastTransformer에 비해 커널 연산에 오버헤드가 존재한다. 하지만 이러한 연산은 attention 커널에만 존재하고 다른 연산에는 영향을 주지 않기 때문에 end-to-end 성능에서 vLLM이 더 좋은 성능을 보인다.
(b) 그래프는 vLLM에서 사용하는 KV Cache 블록의 크기 설정에 따른 latency 변화이다. OS와 마찬가지로 page의 크기는 무조건 크다고 좋은 것도 아니고, 작다고 좋은 것이 아니다. 적절한 크기를 찾아야 하는데, 대체로 16 값이 적절한 기본값으로 사용되고 있다. 만약 블록 크기가 크다면 internal fragmentation이 크게 발생하고 블록 공유가 잘 이뤄지지 않을 것이고, 너무 작다면 KV Cache를 읽고 처리하는 과정에서 GPU의 병렬적인 특성을 활용하지 못할 것이다.
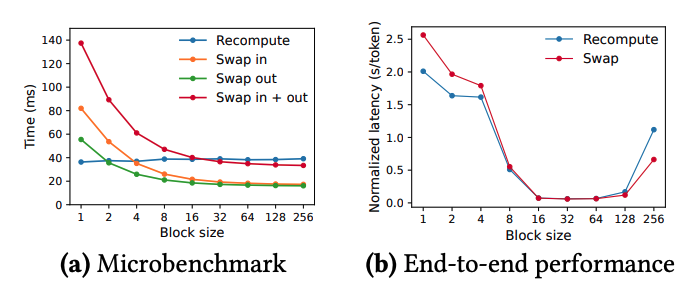
마지막으로 recomputation과 swapping으로 인한 오버헤드를 관찰한 그래프이다.
우선 microbenchmark를 보면, recomputation은 블록 크기에 영향을 받지 않는 편이다. 이는 recomputation이 KV Cache 블록을 사용하지 않기 때문이다. 반면에 Swapping은 블록 크기가 작을 때 오버헤드가 크게 나타났다. 블록 크기가 작을 수록 swapping이 자주 일어나야 하고, 그로 인해 CPU와 GPU 사이에서 PCIe 대역폭 활용 문제가 발생하기 때문이다.
결론적으로 블록 크기가 작다면 recomputation을, 크다면 swapping을 사용하는 것이 좋다. 다만 중간 크기에서는 어느것을 사용해도 성능이 비슷하다.
결론 및 고찰
최근 다른 serving framework에 관련 된 논문들을 보면 많은 부분을 vLLM 위에서 고치고 있을 정도로 vLLM은 거의 serving의 국룰처럼 되었다. 최근에는 V0에서 V1으로 넘어가면서 많은 코드들이 고쳐졌고, 그 외에도 추가적인 기능들이 덧붙여져 가면서 작년과 비교하면 더 거대해진 생태계가 되어갔다. 그러나 한편으로는 코드가 거대해지면서 일부 기능들이 서로 호환이 안되는 사례들도 많고, 모델이 새로 나오면 그에 맞는 인터페이스도 다시 맞춰야 하는 문제들이 생겼다. 물론 이런 것들이 오픈소스의 숙명이겠지만...
나도 vLLM 내부 코드를 보면서 (vLLM 내부에 알 수 없는 asynchronous exception과 싸우며) 사내 서비스에 적용하기 위해 많은 고생을 했었는데, 이런 점들이 좀 더 개선이 되면 좋겠다.
