[SOSP'25] PrefillOnly: An Inference Engine for Prefill-only Workloads in Large Language Model Applications
ML System
최근에 Agentic AI에 들어가는 Safety 모델을 사내에 도입하면서, 특정 LLM의 경우 binary 결과만 내보내는 모델을 많이 보았다. 특히 카카오에서 만든 kanana safeguard가 그런 예시 중에 하나였다. kanana safeguard의 경우, 들어온 prompt에 대해 위협 여부를 Safe/Unsafe로 분류하는데, 이 경우 decoding을 통해 나오는 결과 값이 토큰 1개 밖에 되지 않는다.
이러한 종류의 LLM이 Prefill-only 모델 중 하나로, 기존에 가장 시간을 많이 잡아먹던 decoding을 최적화 하는 것이 아닌 다른 방식이 최적화가 필요할 것이다. 그래서 오늘은 Prefill-only 모델을 최적화 할 수 있는 ML System 논문을 가져왔다. 이 논문의 경우, SOSP'25에 LMPrefill이라는 이름으로 나온 것으로 보이는데 accept이 된건지는 모르겠다.
Prefill-Only workload
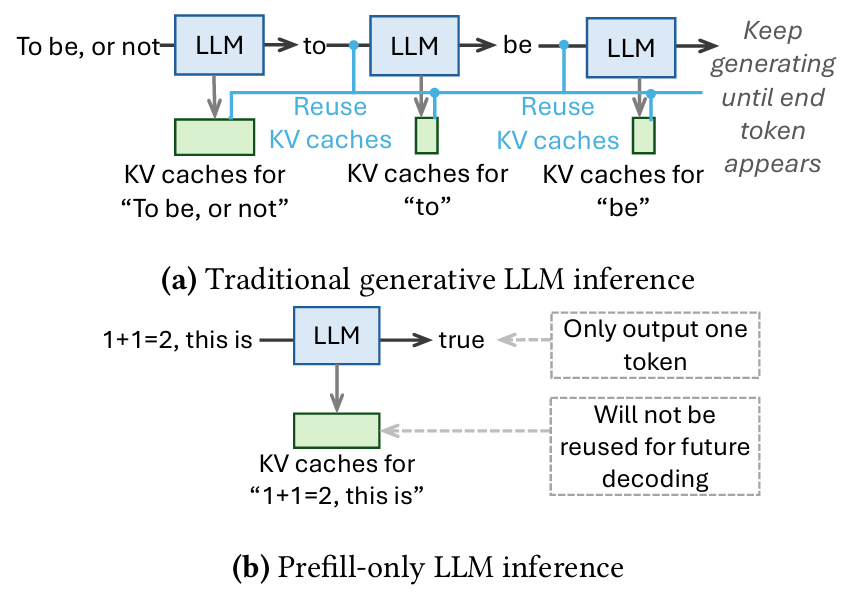
앞서 서론에서 설명하였듯, 기존 LLM의 Text generation workload와는 다르게, 최근에는 단 하나의 토큰만을 결과로 만드는 Prefill-only workload가 등장하고 있다. 언급한 kanana safeguard처럼 보통 무언가를 분류하거나, Yes or No 방식으로 의사결정을 수행하는 LLM이 이러한 형태의 workload로 분류 된다. Prefill-Only workload의 재밌는 특징으로 결과가 단 하나의 토큰으로 이루어진 것뿐만 아니라, 이로 인해 발생하는 특성들이 2가지 정도 있다.
Inference latency가 예측 가능하다.
우선 기존 LLM workload는 decoding 작업을 수행 할 때, 어느 정도의 output token을 만들어 낼지 알 수 없었다. 그렇기 때문에 동일한 input prompt를 사용하더라도 output token의 길이가 달라져서 inference latency가 매번 다른 경우가 많다. 그에 비해, Prefill-Only workload는 대부분의 latency를 decoding이 아닌 prefill에 사용하기 때문에 상대적으로 inference 소요 시간을 예측하기 쉽다.
KV cache에 사용 되는 메모리 양이 적다.
기존 LLM은 모든 레이어에서 발생하는 KV cache를 전부 저장해야 했다. 그에 비해 Prefill-Only는 output token이 1개이기 때문에 대부분의 KV cache가 사용 되지 않는다. 그렇기 때문에 상대적으로 더 적은양의 GPU 메모리를 사용하게 된다.
기존 LLM engine은 Prefill-Only workload에 적합한가?
물론 답은 No로 정해져있다. (Yes였다면 이 논문이 안나왔을 것이다.)
기존 LLM engine을 이용해서 Prefill-Only인 workload를 처리 할 경우, 2가지 문제점이 생긴다.
Sequence length가 긴 요청이 들어오는 경우 throughput에 문제가 생긴다.
일반적인 LLM engine의 경우, 요청이 들어왔을 때 sequence 길이에 따라서 KV Cache의 크기가 비례하여 증가하게 된다. 그렇게 되는 경우, batch 단위로 처리 할 수 있는 메모리의 크기가 줄어들면서 많은 양의 요청을 처리하기 어려워지는 문제가 있다.
물론 이를 처리하기 위해서 Tensor Parallelism, Pipeline Parallelism 같은 병렬 처리 테크닉을 사용하긴 하지만, NVLink와 Infiniband 같은 고속 네트워크 장치가 필요하거나 pipeline bubble을 최적화하는 추가적인 방식이 필요하다.
스케줄링 시 Job Completion Time을 구하기 어렵다.
일반적인 LLM을 상정한 engine의 경우에는 decoding 단계에서 얼마만큼의 토큰이 발생하게 되는지 알 수 없다. 그렇기 때문에 SJF (Shortest Job First) 같은 스케줄링 방식을 사용하는 것이 굉장히 어렵다. 그래서 일반적으로 JCT를 이용하지 않는 방식의 스케줄링 (FIFO나 Round-Robin) 방식을 사용한다.
PrefillOnly Engine
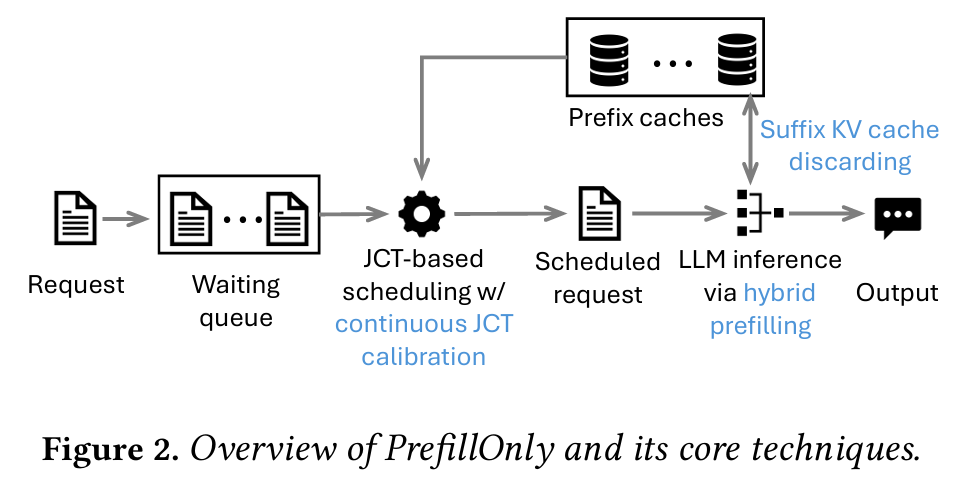
PrefillOnly는 위 그림과 같이 Profiling을 수행하는 구간과 runtime 구간으로 나누어져 있다.
1. Profiling Step
우선 Profiling 단계에서는 사용자가 LLM을 load 할 때, 모델이 처리 할 수 있는 maximum request length를 사용자로부터 받아야 한다. 이를 이용하여 PrefillOnly는 그만큼의 가짜 요청을 LLM에 던져서 처리에 걸리는 시간을 계산하면서, 이 때 필요한 최대 GPU 메모리 사용량을 계산한다. 그리고 남는 공간을 Prefix Caching에 할당한다.
2. Runtime Step
LLM engine으로 요청이 도착하면 요청을 tokenize 한 뒤 ZeroMQ 기반 RPC를 이용하여 스케줄러의 wating queue로 전달한다. 스케줄러는 wating queue에 쌓인 모든 요청을 확인하여 가장 실행 시간이 짧을 것으로 예상되는 요청을 찾아서 executor로 보낸다. 그리고 executor는 LLM inference를 수행하고, 그 결과를 사용자에게 전달한다.
위 두 step을 수행하면서 PrefillOnly에서 사용하는 추가적인 기술들로는 다음과 같이 3가지가 존재한다.
- Hybrid prefilling
- Suffix KV cache discarding
- Continuous JCT calibration
Hybrid Prefilling
PrefillOnly 저자들은 요청으로 받을 수 있는 max sequence length를 증가시키기 위해 여러가지를 시도했었다. 결국 이러한 시도들이 대부분 불필요한 KV Cache를 제거하여 GPU memory를 비우는 기술들이였는데, 그 중 하나가 활성화 된 Attention layer의 KV Cache를 주기적으로 비워주는 방식이였다. 그런데 이 방식이 생각보다 잘 되지 않았다고 한다.
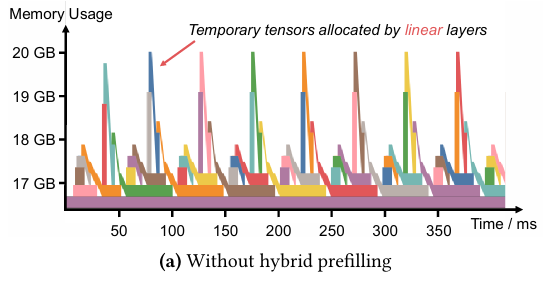
위 그래프는 Llama 3.1 8B 모델에서 32,768 토큰을 prefill 할 때, PyTorch 내부의 memory allocator에서 발생하는 메모리 사용량을 관측한 결과이다. 요청을 메모리에 할당 하는 동안 중간에 memory spike가 발생했고, 이러한 원인은 Llama 모델의 MLP에서 발생하는 입출력을 임시로 저장하기 위한 메모리 할당으로 인해 발생하는 것이였다.
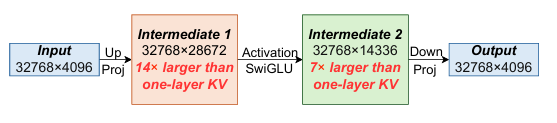
Llama 3.1 8B 모델이 32,768 토큰을 Prefill 할 때, 발생하는 tensor shape의 순서를 보면 KV cache에 비해 14배 크게 측정이 되었다. 이는 Llama 모델에서만 발생하는 경향은 아니며, 이러한 이유는 기존 LLM 모델들이 decoding 처리량을 높이기 위해 batch size를 키우고, 더 긴 LLM 요청을 처리하기 위해 KV cache의 크기를 줄이도록 설계되었기 때문이다.
결국 중간 단계에서 발생하는 tensor 크기를 줄이기 위해 고안 된 방식이 Hybrid Prfilling이다. 방법은 간단한데, Attention 레이어는 그대로 prefill을 하고, 그 외 레이어는 chunk 단위로 쪼개서 prefill 하는 방식이다. Attention의 경우, 입력 문장을 chunk로 분리하게 되면 positional encoding이 깨지거나 cross-attention을 새로 고려해야 하는 반면, 그 외 다른 레이어는 linear layer라서 chunk 단위로 분리하더라도 독립적인 계산이 가능하다. 즉, 결과에 이상이 생기지 않는다.

이를 적용 할 경우, 특정 시점에 단 하나의 chunk에 대한 중간 tensor만 저장하게 되므로, 기존 방식에 비해 GPU 메모리 사용량의 spike가 크게 감소하는 효과를 볼 수 있다.
PrefillOnly는 이 방식을 PyTorch에서 제공하는 torch.compile로 구현했다고 한다. 그 이유가 모델 inference 코드를 변경하지 않고도 model graph를 변경 할 수 있기 때문이라고 한다. 그 과정에서 아래와 같은 추가적인 최적화 방식을 사용하였다.
1. Output preallocation
chunk의 output tensor를 하나의 큰 텐서로 이어 붙일 때, output tensor의 GPU 메모리 사용량이 메모리 복사로 인해 2배가 될 수 있다. 이를 방지하기 위해, 연산 그래프에서 추론된 shape 정보를 사용해 forward 실행 전에 output tensor를 미리 할당하고, 각 chunk의 결과를 사전 할당된 tensor에 직접 기록한다.
2. In-place computation
input tensor와 output tensor의 모양이 동일한 경우, input tensor의 GPU 메모리를 재활용하여 output tensor를 저장한다. 이는 output chunk가 output tensor에서 차지하는 상대적 위치는 input tensor에서 input chunk가 차지하는 위치와 정확히 동일하기 때문이다.
Suffix KV cache discarding
PrefillOnly는 GPU 메모리 확보를 위해서 KV cache를 버리는 정책을 사용한다. 그런데 무조건 모든 KV cache를 버리게 되면 prefix cache 또한 폐기가 되기 때문에 성능에 문제가 발생 할 수 있다. 그렇게 때문에 Suffix KV cache discarding이라는 방법을 통해 prefix cache는 최대한 보존함과 동시에 suffix에 해당하는 부분의 KV cache는 버리는 정책을 사용한다.
이를 Hybrid Prefilling과 동시에 적용하는 경우, 각 요청을 단일 LLM 추론에서만 prefill을 하게 되기 때문에 prefix를 제외한 나머지 부분이 suffix로 처리되어 추론 속도를 떨어뜨리지 않으면서 KV cache의 폐기가 가능하다.
Continuous JCT Calibration
PrefillOnly는 모든 요청을 batch로 묶어서 처리하지 않는다. 이에 대한 이유로, prefill-only workload가 decoding의 처리량을 극대화 할 이유가 없는 것을 들 수 있다. 기존의 LLM workload는 decoding에서 발생하는 latency로 인해 batch size로 묶어서 요청을 처리하는 것이 성능에 큰 영향을 미쳤지만, prefill-only workload는 batch 단위로 묶어서 요청을 처리해도 성능 향상이 미미한 수준이다. 그렇기 때문에, 스케줄러로 들어오는 모든 요청은 단일 요청 그대로 처리가 된다.

위 그림은 기존의 LLM engine들이 사용하는 FIFO와 이상적으로 JCT를 유추 할 수 있다고 가정했을 때 사용 가능한 SRJF, 그리고 PrefillOnly에서 사용하는 Continuous JCT Calibration 기능을 동반한 SRJF의 전체 JCT 그래프이다.
요청의 길이 순서는 A < C < B < D 순서라고 가정하고, A와 D 그리고 B와 C가 서로 prefix cache를 공유한다고 가정할 때, 이상적으로 SRJF를 시도 했음에도 eviction 된 KV cache로 인해 SRJF의 성능이 거의 FIFO와 동일한 수준으로 전체 JCT가 떨어질 수 있다. 결국 기존의 SRJF는 단순한 JCT와 요청 도착 시간만 고려하기 때문에 이러한 문제가 발생한다. 그렇기 때문에 Continuous JCT Calibration은 두 가지를 고려하였다.
- LLM engine이 해당 요청과 관련된 prefix cache를 사용 할 수 있을 때, 우선순위를 높인다.
- 해당 요청의 prefix cache가 제거됐을 때, 우선순위를 낮춘다.
이를 반영하기 위해, PrefillOnly는 KV cache의 움직임에 따라 매번 스케줄링 직전에 대기 중인 요청의 JCT를 지속적으로 보정한다. 위 그림의 경우, A 요청 뒤에 D의 작업이 prefix cache hit가 되기 때문에 D 작업을 실행하게 된다. 그리고 B와 C는 prefix cache miss가 발생하기 때문에 둘 중 더 작은 길이를 가진 C 요청을 먼저 처리하고, prefix cache를 재활용하여 B 요청을 처리하게 된다.

세부적인 scheduling algorithm은 위와 같다.
- (5-7번 라인) PrefillOnly는 큐에 존재하는 각 요청 의 JCT를 보정하기 위해 입력 토큰 개수 과 prefix cache에 적중한 토큰 개수 를 계산한다.
- (9번 라인) 이를 기반으로 JCT를 호출하는데, 이는 최대 1000 토큰 단위까지의 다양한 과 조합에 대한 profiling 결과를 기반으로 한 작은 linear regression 모델을 이용한다.
- (10-12번 라인) JCT 값이 현재보다 작은 값이라면 이 요청을 다음 스케줄링 타겟으로 지정한다.
위 알고리즘에 9번 라인에서 값을 JCT에서 빼주는 구간이 있는데, 이는 SRJF가 가지는 starvation 문제를 해결하기 위해 어드밴티지를 주는 과정이다. 는 요청에 대한 큐에서 대기한 시간을 의미한다. 즉, 큐에서 오래 기다린 요청일수록 더 많은 어드밴티지를 얻게 되어 다음 요청으로 선정 될 가능성이 커진다. 값은 특정한 하이퍼파라미터 값으로, 이를 너무 높이게 되면 요청에 대한 지연 시간이 개선되지만 평균 지연 시간은 악화될 수 있다.
실험 결과

우선 이 논문에서 사용한 데이터셋은 2가지이다. 소셜 미디어 플랫폼에서 추출한 게시물 추천 관련 데이터셋과 은행 애플리케이션의 신용 검증 데이터셋으로, 각각 평균적으로 소셜 미디어 플랫폼은 14,000 토큰, 그리고 은행 애플리케이션의 신용 검증은 40,000에서 60,000 토큰 정도의 요청 길이를 가지고 있다고 한다.
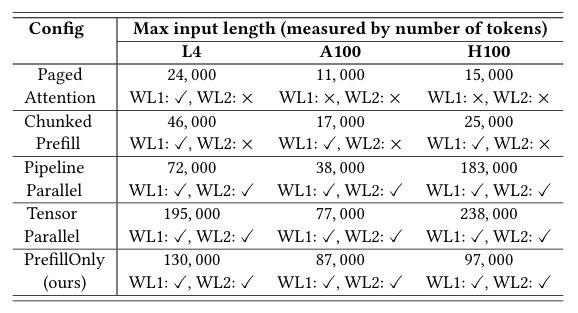
비교를 위한 GPU와 baseline은 위와 같다. Paged Attention 방식은 vLLM을 그대로 사용한 것으로 보이고, Chunked Prefill은 Sarathi-Serve라는 LLM engine을 사용한 것으로 보인다. PrefillOnly의 값은 500을 사용했다고 한다.
그리고 사용자의 요청을 GPU로 라우팅 하는 방식은 동일 사용자에 대해서는 최대한 prefix caching을 활용 할 수 있도록 ID를 기반으로 GPU를 매핑하고, prefix cache가 없어서 불가능한 경우는 Round-Robin으로 라우팅을 하였다고 한다.
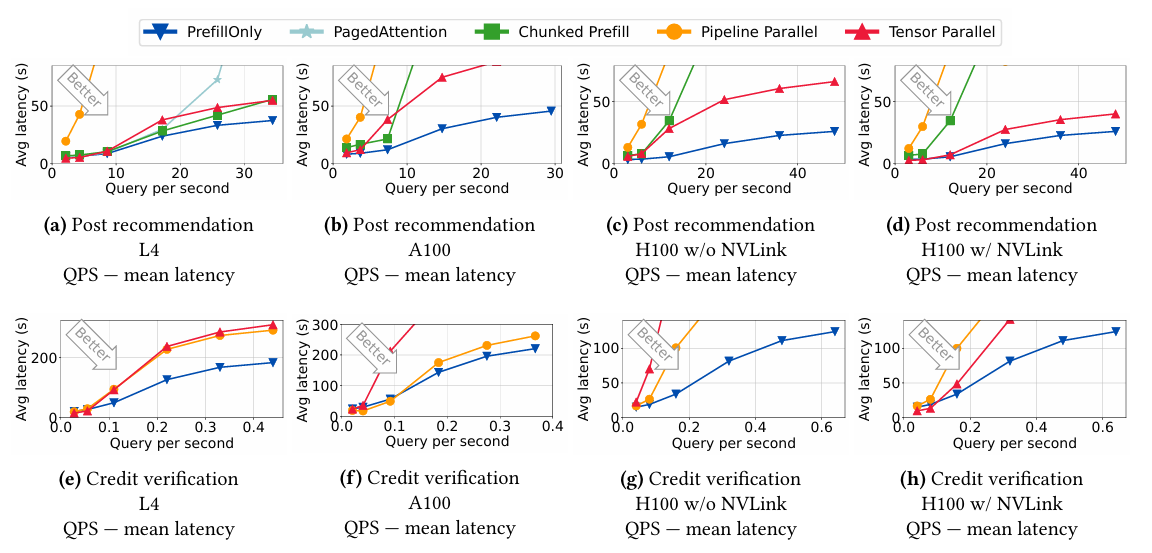
위 그래프는 초당 쿼리 수 (QPS) 증가에 따른 평균 latency에 대한 비교를 보여준다. 초당 들어오는 쿼리가 점점 많아지는 경우, PrefillOnly가 다른 LLM engine에 비해 좋은 처리 속도를 보여준다. 다만 요청량이 많지 않은 경우, Parallelism을 적용 했을때에 비해 성능이 좋지 않은데, 이는 PrefillOnly의 경우 단일 GPU에서 요청을 처리하는 반면, Parallelism 기법을 적용한 LLM engine은 2개 이상의 GPU를 사용했기 때문이라고 한다.
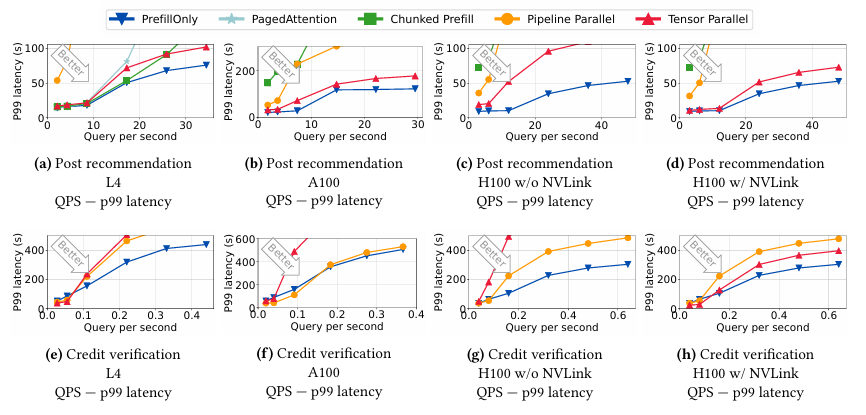
P99 latency의 경우에도 PrefillOnly의 성능이 좋은데, 이를 통해 값을 조정하는 방식을 사용하여 긴 요청에 대해 starvation이 조절됨을 의미한다.

위 그래프는 PrefillOnly의 Hybrid Prefilling으로 인해 vLLM과 Chunked Prefill 대비 얼마만큼의 input token을 더 받을 수 있는지를 나타낸 그래프이다. A100 GPU에서 FP8 Qwen-2.5-32B 모델의 최대 context length를 7.9배 향상 시켰다고 한다.
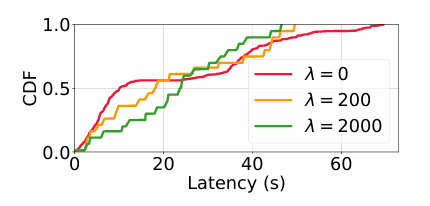
끝으로 PrefillOnly의 스케줄링에서 값을 조정하였을 때, 지연 시간 개선에 관련 된 그래프이다. 값이 높아질수록 P99 지연 시간은 감소하지만 평균 지연시간은 커지는 문제가 발생한다. 그렇기 때문에 값을 적절히 조절해야 한다.
결론 및 고찰
이 논문의 경우, 듣기로는 SOSP'25에 붙었다고 하는데 아직 올해 SOSP 페이지에 최종 버전이 업데이트가 안된 상태라 arXiv 버전을 가져와서 리뷰를 했다. 그렇기 때문에, 내용이 어딘가 부족한 부분이 많아서 방식을 이해하는데 조금 시간이 걸렸다.
논문의 끝부분에 나와있지만, 최근에 prefill과 decoding을 disaggregation 하는 방식이 유행인데 PrefillOnly를 여기에 적용 할 수 있을 것으로 본다고 되어 있다. 다만 그렇게 되면 PrefillOnly의 스케줄링을 배치 단위로 처리해야 할텐데, 이걸 해결하는 과정이 꽤 난제일 것으로 보인다. (decoding 앞단에서 배치로 모아서 하려나?)
나중에 기회가 된다면 사내 Safety에 이 방법을 적용해보고 싶다.
