최근 vLLM을 언급한 여러 논문을 보면서, vLLM이 오픈소스로써 가지는 장점에도 불구하고 LLM의 발전으로 인해 모델 포팅에 있어서 여러 제약 사항이 발생하는 것을 보았다. 이전에 vAttention이 언급한 PagedAttention의 메모리 할당 방식이 가지는 문제점이라던가, Mamba 같은 모델의 특수성 등이 언급되면서 vLLM을 개선하기 위한 노력들이 학회 페이퍼로 올라오고 있다.
이번 논문도 그러한 종류 중에 하나로, vLLM의 1저자인 권우석씨가 저자 중에 한 명으로 들어가 있어서 내용이 궁금했다. (이 논문의 1저자는 칭화대 사람들이지만, UC berkeley의 SKY lab이 도움을 준 것으로 보인다.)
Heterogeneous LLM Architecture
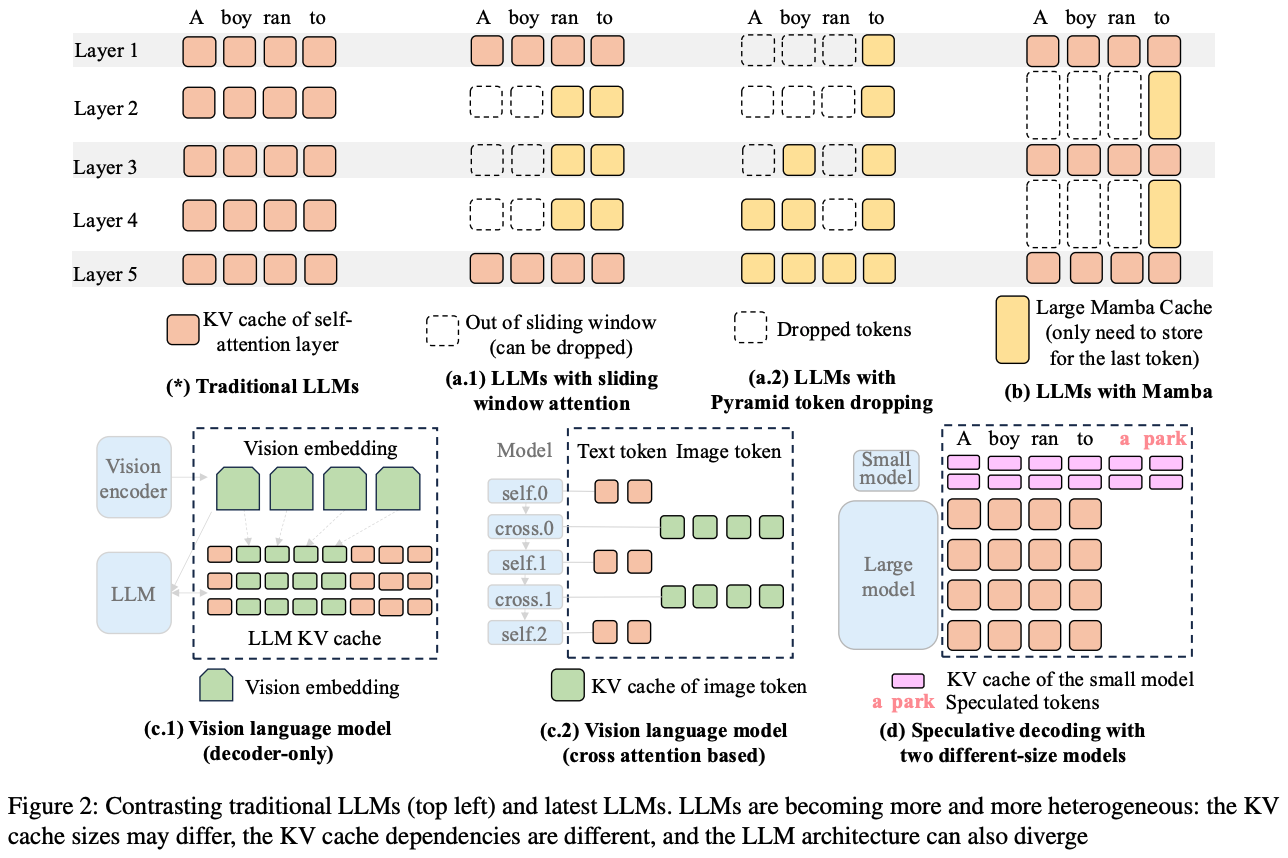
이전의 LLM들은 동일한 self-attention 레이어를 단순하게 쌓는 방식으로 모델을 구성해왔다. 하지만 최근 들어서 Google의 Gemma-2나 Mamba, Hymba 같은 특수한 아키텍쳐들은 기존의 고정적인 크기의 임베딩을 사용하는 Transformer 레이어를 쌓지 않고 heterogeneous하게 사용하고 있다.
위 그림은 이에 대한 주된 heterogeneous LLM 구조를 보여준다.
1. Sparse Attention
(a.1) 그림의 경우, prefix 토큰의 일부분만 참조하여 KV cache 크기를 줄이는 방식을 사용한다. 가장 많이 쓰이는 방법이 sliding-window attention 방식으로, 각 토큰이 고정된 수 만큼의 인접한 토큰 attention으로 사용한다. 거기에 decoding 과정에서 동적으로 일부 토큰을 제거하는 방식도 있다. (그림 a.2) 참고로 sparse attention의 경우에는 이전에 작성했던 MagicDec의 KV cache 압축과도 연관이 있다.
2. State Space Models
State space model은 sparse attention을 확장한 형태이다. 각 토큰마다 이전 토큰들의 context 정보를 가져오기 위한 텐서를 추가로 사용한다. 그림 (b)의 Mamba 같은 경우가 그 예시인데, 이런 레이어들은 self-attention 레이어와 섞어서 사용 된다. 그렇기 때문에 메모리를 할당 할 때, state 기록을 위한 소수의 커다란 고정 크기의 텐서와 다수의 소형 KV cache 블록을 동시에 관리해야 한다.
3. Multi-Modal LLM
입력 모달리티가 여러개인 경우이다. (c.1)은 전형적인 VLM의 예시인데, 이미지 토큰 형태의 비전 임베딩이 존재하기 때문에 이미지와 기존의 텍스트 형태를 모두 포함하는 KV cache가 필요하다. 거기에 텍스트 KV cache는 GQA 같은 KV cache 압축 알고리즘이 사용 된다면, 크기가 서로 크게 차이 나게 된다.
4. Serving Multiple Concurrent Models
(d) 그림과 같이 speculative decoding은 단일 LLM 여러개를 동시에 서빙해야 하는 경우도 있다. 이 경우, 작은 모델과 큰 모델 사이에는 토큰 하나 당 KV cache 크기가 크게 차이가 나게 된다.
Heterogeneous KV Cache의 Memory Fragmentation
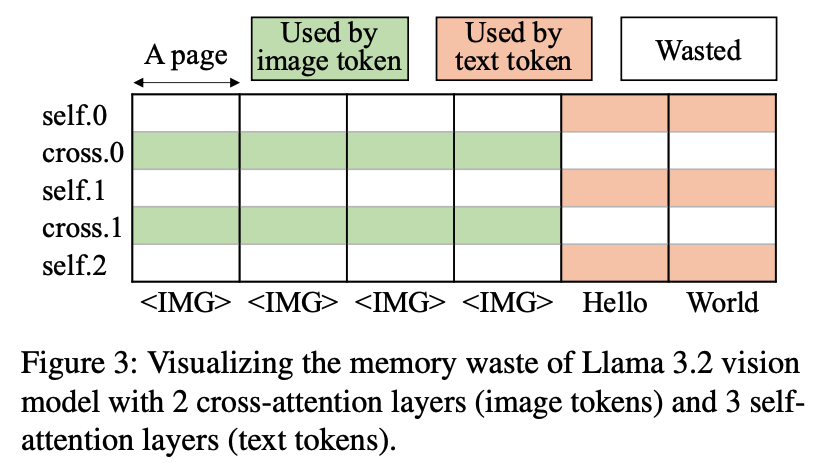
결국 레이어를 고정 된 임베딩 크기의 Transformer가 아닌 것을 사용하기 때문에 KV cache의 크기가 달라지는 것이 문제라고 언급되고 있다. Jenga는 여기에 LLaMA-3.2 11B 비전 모델을 이용하여 기존의 Paged Attention에서 발생 할 수 있는 fragmentation 문제를 추가로 설명해준다.
위 그림과 같이, 기존의 Paged Attention의 동작 방식대로라면, 모든 레이어에서 텍스트 토큰과 이미지 토큰은 동일한 크기를 가진다. 하지만 이상적인 방식으로는 self-attention 레이어에서는 텍스트 토큰의 KV cache만 발생하고, cross-attention 레이어에서 이미지 토큰 KV cache가 발생하기 때문에, 더 적은 양의 메모리로도 충분히 할당을 할 수 있어야 한다.
LLaMA-3.2 11B 비전 모델의 경우, Paged attention 대비 이상적인 메모리 할당 방식을 비교 했을 때, 낭비율이 79.6%까지 도달 할 만큼 fragmentation이 심하다는 것을 발견했다고 한다.
Heterogeneous Dependency로 인한 Prefix Caching 문제
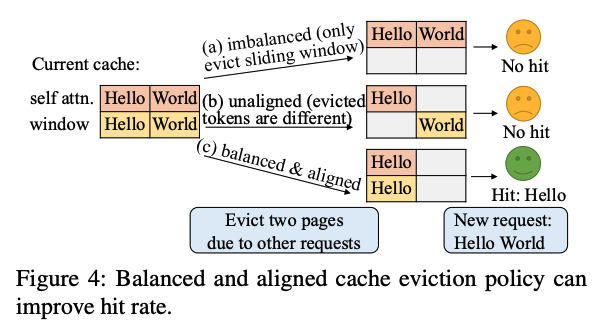
메모리 문제 외에도 prefix caching에서도 3가지 문제가 발생하게 된다.
1. Cache hit & eviction rule
self-attention 레이어는 특정 토큰이 이전에 모든 prefix attention과 토큰을 계산하기 때문에, cache hit를 위해서는 모든 prefix token이 남아있어야 한다. 그러나 sliding window 같은 방식은 새로운 토큰을 생성 할 때, prefix 중 일부분만 참조하기 때문에 모든 prefix가 없더라고 cache hit가 발생한다.
2. Balanced eviction (그림 a)
서로 다른 레이어 간에 제거되는 토큰 수도 균형 있게 유지해야 한다. 모델 전체에서 prefix cache가 hit 하려면 당연하게도 모든 레이어에서 prefix 토큰이 존재해야 한다. 그런데 만약 sliding window처럼 특정 레이어에서 너무 많은 토큰을 제거하는 경우, 다른 레이어에서 prefix가 남아있더라도 hit가 되지 않는 상황이 생긴다.
3. Aligned eviction (그림 b)
레이어마다 prefix를 제거 할 때, 비슷한 토큰 집합이 함께 제거 되어야 한다. 만약 서로 다른 토큰 집합을 제거 하게 되면, 레이어의 합집합에 속하는 토큰들은 cache miss가 발생하는 상황이 생긴다. 그렇기 때문에 레이어마다 prefix cache를 제거하는 정책을 align 시켜서, 유사한 토큰 집합이 동시에 제거 되어야 한다.
Two-level Memory Allocation
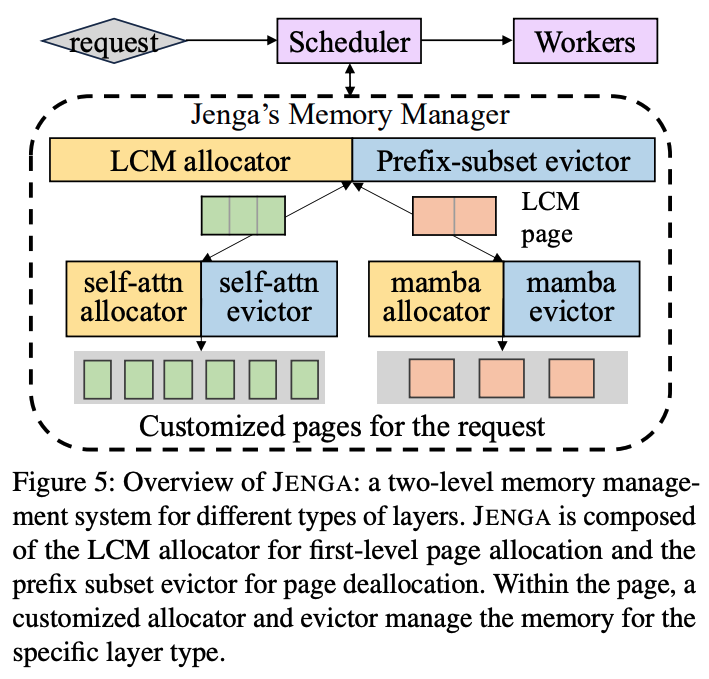
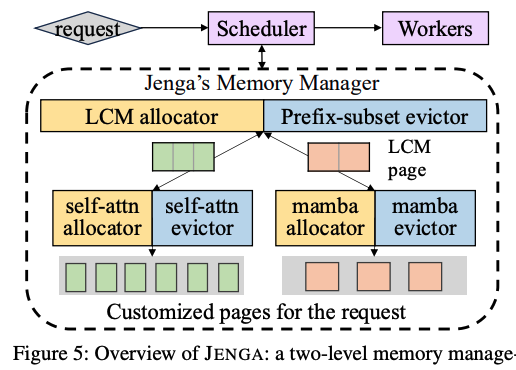
Jenga는 LLM의 heterogeneous 레이어 사용을 위해 메모리를 효율적으로 할당하기 위한 compatibility layer, 그리고 cusomization layer를 도입하였다. 이러한 방식으로 two-level로 메모리 관리 시스템을 위 그림과 같이 구성하였다.
Jenga는 모든 레이어 타입에 호환되는 크기의 page를 할당해야 했는데, 이를 위해 LCM(최소공배수) allocator를 만들었다. 그리고 각 레이어 타입에 특화 된 사용자 정의형 allocator를 두었다. 이 사용자 정의형 allocator는 LCM allocator로부터 호환되는 페이지를 가져오고, 해당 유형에 맞는 전용 page size로 만들어 메모리를 관리한다.
그리고 prefix cache를 관리하려면 서로 다른 레이어 타입 사이에 eviction을 조정해야 한다. 이를 위해 prefix-subset evictor를 도입하였고, 각 레이어 타입마다 사용자 정의형 evictor를 통해 타입에 맞는 eviction 전략을 사용한다.
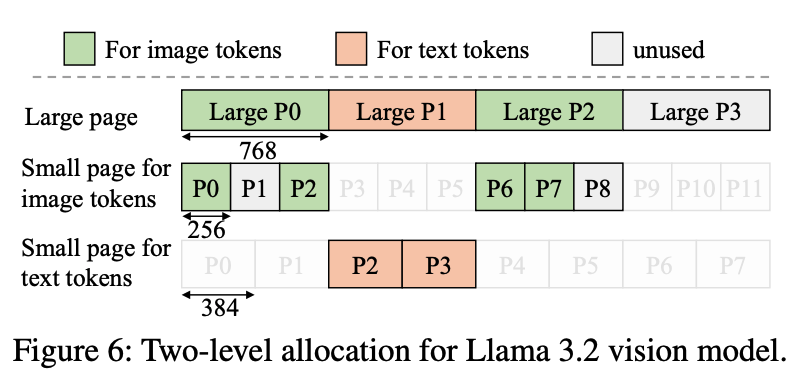
위 그림은 LLaMA 3.2 비전 모델을 예시로 한 Jenga의 메모리 구조이다. 이 모델은 페이지의 크기로 이미지 토큰은 256 바이트, 텍스트는 384 바이트를 사용한다. 이 경우, 값으로, 이를 compatible page size로 사용하게 된다. 위 그림의 large page처럼, Jenga는 전체 KV cache 메모리를 768바이트의 대형 page로 나누고, 이를 LCM allocator로 관리한다.
하위에 사용자 정의형 allocator는 LCM allocator로부터 일부 대형 page를 요청한다. 그리고 각 대형 page를 레이어마다 타입에 맞는 작은 page로 분할하여 사용하게 된다. 위 그림에서 image 토큰 KV cache는 대형 page 0번과 2번을 할당 받았고, 각 페이지는 256 바이트씩 3개의 작은 page로 쪼개서 사용하고 있다. 텍스트 토큰 KV cache의 경우, 1번 대형 page를 할당 받아서 384 바이트씩 2개의 작은 page로 할당 시킨다.
작은 page의 경우, 만약 모든 작은 page가 사용중이라면 새 대형 page를 LCM allocator에 추가로 요청하게 된다. 그리고 대형 page 내에 쪼개진 모든 page가 사용되지 않는 상태가 되면 그 대형 page는 할당이 해제 된다.
New Memory Layout
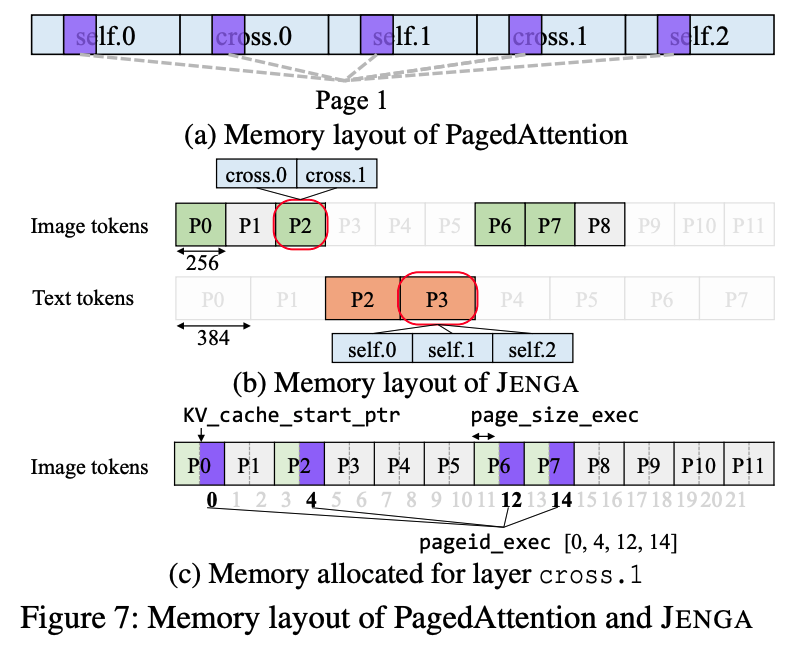
Jenga는 two-level로 디자인 된 메모리 레이아웃을 사용하긴 하지만, 기존 Paged Attention의 worker를 거의 변경하지 않고 호환하여 재사용 할 수 있다.
위 그림 (a)에서, 기존 paged attention은 각 logical page가 physical memory 상에서 여러개로 나누어져 있다. 이 구조에서는 서로 다른 레이어 타입끼리 KV cache를 공유하기 어렵다. 이를 layer-page partition 방식으로 부르는데, 메모리를 레이어 단위로 나누고, 이걸 다시 page 단위로 나눈다는 얘기다.
Jenga는 이를 뒤집어서 page-layer partition 방식을 사용한다. 먼저 메모리를 page 단위로 나눠 놓고, 각 page 내부를 다시 레이어 단위로 분할한다. 그런 경우, 그림 (b)와 같이 작은 page들은 연속적인 메모리 블록 형태로 배치가 된다.
그림 (c)에서처럼 cross-attention 같은 특정 레이어는 사용자가 정의한 포인터 메타데이터 형태로 표현이 될 수 있다. 이 값을 전달하면 attention 연산을 그대로 수행 하는 것이 가능하기 때문에 기존 paged attention 커널과 호환이 가능하다.
Request-aware Allocation
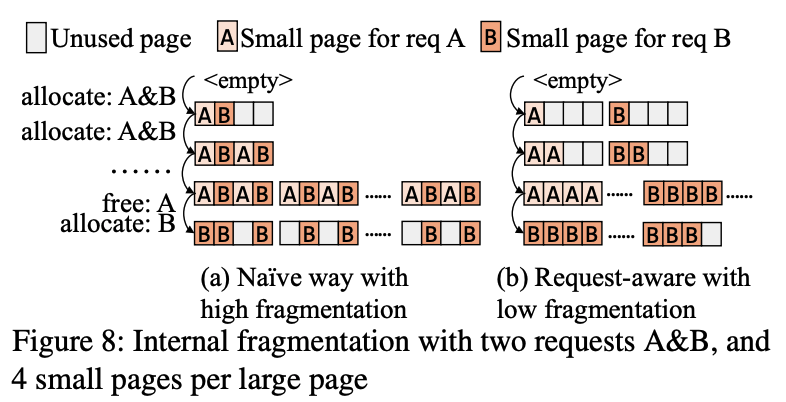
메모리를 단순하게 할당하는 경우, 대형 page에 internal fragmentation을 발생 시킬 수 있다. 위 그림의 (a)가 그러한 케이스인데, 요청에 대한 메모리 할당은 다른 요청들의 할당과 함께 이루어진다. 하지만 메모리 해제는 경우가 다른데, 보통 한 요청이 완전히 끝나면 일괄적으로 수행이 된다. 이렇게 되면 대형 page 전체를 다시 allocator로 반환하게 되는 횟수가 줄어들면서 fragmentation이 발생하게 된다.
Jenga의 경우, 각 요청 단위로 할당과 해제를 (b)와 같이 조정하게 된다. 가능한 경우에 하나의 대형 page 내의 작은 page들을 동일한 요청에 할당을 하는 방식으로, 이렇게 조정을 하는 경우 일부 page가 해제 되더라도 대부분 인접한 작은 page들이 연속적으로 해제 되기 때문에 대형 page를 allocator에게 반환 시킬 수 있다.
결론적으로 Jenga의 request-aware allocation 방식을 정리하면 다음과 같다.
- 현재 요청에 연결 된 작은 page 중에 미사용 된 것을 할당한다.
- 실패한 경우, 대형 page를 allocator로부터 요청한다. 그리고 그 대형 page의 모든 작은 page와 요청을 연결 한다.
- 1번과 2번이 모두 실패한 경우, 다른 요청과 연결 된 작은 page 중에 미사용 된 것을 할당한다.
Allocator Options
Jenga의 저자들은 일단 대형 page의 크기를 추정하기 위해서 LCM을 사용하긴 한다. 그렇지만 그 외에도 몇가지 옵션으로 다른 크기를 고려 할 수 있다고 한다.
GCD (최대공약수) 방식
임베딩 크기를 최대공약수로 산정하는 방식으로, 이 방식은 internal fragmentation이 없다는 장점이 있다. 하지만 LLM의 inference 속도가 감소한다는 큰 문제가 있다. 그 이유는 GPU 메모리 내부에서 KV cache는 특정 텐서의 차원 방향으로 연속적으로 할당 되는 것이 좋다. 하지만 GCD를 사용하게 되면 텐서를 여러 조각으로 나눠야 하고, 이로 인해 GCD에 맞춘 GPU 커널을 새로 만들어야 하는 부담이 있다. 그렇게 만들더라도 성능이 기존에 비해 많이 떨어지는 경우가 많았다고 한다.
Max (최대 크기) 방식
임베딩 크기 중 제일 최대값을 page size로 사용하는 방식이다. 이 방식은 작은 page 크기를 사용하는 레이어에서 internal fragmentation가 발생한다는 문제가 있다. 작은 레이어의 page 당 토큰 수를 늘리면 어느 정도 완화가 가능하지만, 이로 인해 메모리 할당과 cache hit에 대한 단위 크기가 커지는 문제가 있다.
LCM (최소공배수) 방식
LCM 방식은 새로운 GPU 커널을 작성하거나, 각 페이지에 비정상적으로 많은 토큰을 추가로 할당할 필요가 없다. 다만 request-aware allocation이 병행 되지 않은 대형 page에서 사용되지 않는 작은 page들로 인해 internal fragmentation이 발생 할 수는 있다. 또한 LCM이 지나치게 큰 경우도 발생할 수 있는데, 대부분의 모델로 실험을 했을 때, 작은 page 대비 84배 수준까지 발생했었고, 이는 성능 저하를 미칠 정도는 아니였다고 한다.
Customizable Prefix Caching
Jenga는 prefix caching 관련 작업을 지원하기 위해서 캐싱 제거와 캐싱 히트를 지원해야 한다. 하지만 이 두 기능 역시 layer 타입에 따라 다르게 동작해야 하기 때문에 이에 대해 prefix-subset evictor를 이용하여 다양한 layer 타입을 관리한다.
Customizable cache eviction
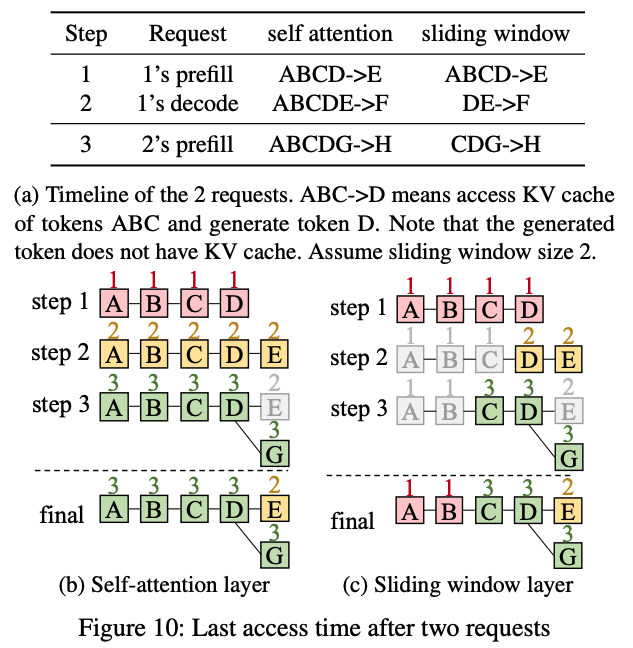
서로 다른 레이어 타입으로 LLM을 구성했을 때, prefix cache에서 제거되는 토큰 수는 균형 있게 유지하면서 비슷한 토큰 집합이 함께 제거 되어야 한다. Jenga는 이를 LRU 알고리즘으로 구현하였는데, 가장 오래 전에 접근 된 페이지가 제거 대상이 되는 방식이다.
위 예시 그림에서, 모델이 2개의 요청을 처리하려고 한다.
- 요청 1 : [A, B, C, D]를 입력으로 가지고, [E, F] 토큰을 출력
- 요청 2 : [A, B, C, D, G]를 입력으로 가지고, [H] 토큰을 출력
모든 레이어 타입의 페이지 크기가 동일하다고 가정 했을 때, self-attention은 모든 실행중인 step에서 현재 처리 중인 모든 토큰의 접근 시간이 갱신이 된다. 즉, step 1에서는 [A, B, C, D], step 2에서는 [A, B, C, D, E], step 3에서는 [A, B, C, D, G]가 업데이트 된다.
반면, sliding-window를 사용하는 layer는 오로지 sliding-window 내 토큰만 접근 시간이 갱신 된다. 그래서 step 2에서 토큰 [F]를 생성 할 때, [D, E]만 갱신이 되고 [A, B, C]는 갱신이 되지 않는다.
또한 Jenga는 동일한 접근 시간을 가진 페이지 사이에서 제거 순서를 조정 할 수 있는데, 이는 같은 토큰 그룹을 제거하기 위함이다. 각 레이어에는 대응 되는 토큰에 동일한 prefix length 값을 부여하여 높은 prefix length부터 제거 시킨다.
Customizable cache hit
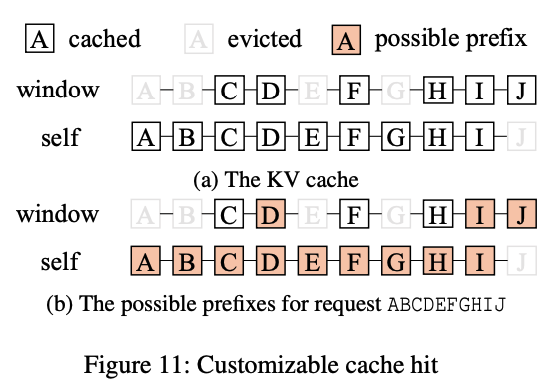
각 레이어 마다 prefix cache가 히트 되는 조건은 보통 다음과 같다.
- self-attention layer는 모든 토큰이 cache에서 제거 되지 않고 prefix 전부 유지 되어야 한다.
- sliding-attention layer는 마지막 sliding window 크기만큼의 토큰만 캐시에 남아 있으면 된다.
예를 들어, 위 그림과 같이 요청이 [A, B, C, D, E, F, G, H, I, J] 일 때, self-attention의 경우에 유효한 prefix cache는 [A], [A, B], ... , [A, B, C, D, E, F, G, H, I]일 것이다. 반면, sliding-window layer는 [A, B, C, D], [A, B, C, D, E, F, G, H, I]. [A, B, C, D, E, F, G, H, I, J] 이런 방식일 것이다.
Jenga는 새로운 요청이 들어오면 compatibility 레이어에서 각 레이어 타입에 맞는 유효한 prefix를 식별한다. 그리고 그 중에서 모든 레이어에서 동시에 유효한 가장 긴 prefix를 최종 히트로 선택한다.
다양한 레이어에 대한 예시
1) Sliding-window layer
Jenga는 window 내부의 토큰에 대해서만 최근 접근한 시간을 갱신한다. 또한 prefix cache의 히트를 위해 이 window 내부 토큰들만 cache에 남아 있으면 된다.
2) Mamba layer
Mamba는 각 토큰들이 가지는 state가 기존 attention 기반보다 훨씬 크다. 모든 토큰을 캐싱하면 메모리 사용량이 매우 크기 때문에 Jenga는 512개 토큰마다 하나의 state만 캐싱한다. 따라서 512의 배수 길이를 가진 prefix만 히트로 인식 된다. 그래서 접근 시간의 갱신은 마지막으로 캐싱 된 토큰 하나만 갱신 된다.
3) Vision embedding cache와 Vision cross attention cache
이미지 토큰 중 하나라도 제거가 되면 전체 vision encoder를 다시 계산해야 한다. 그렇기 때문에 재계산 해야 하는 이미지의 수를 최소화 해야 하며, 하나의 이미지 전체를 제거 하는 것이 여러 이미지에서 일부 토큰을 조금씩 제거 하는 것보다 효율적이다. Jenga는 각 이미지에 대해 랜덤으로 prefix length를 할당 한다. 그리고 해당 이미지의 모든 토큰에 랜덤으로 부여 된 값을 적용하고, 이 값이 가장 큰 이미지에 속한 토큰들부터 우선적으로 제거 된다.
LCM page table의 cache eviction
Jenga는 two-level 메모리 관리에서 prefix caching의 효율을 높이기 위해 작은 페이지의 캐시 히트와 대형 페이지의 교환을 조정한다. Jenga의 페이지의 상태는 다음과 같은 분류를 따른다.
-
small page
1) empty page : 유효한 KV cache가 없고, 어떤 요청에서도 사용 되지 않음
2) evictable page : 유효한 KV cache는 있지만, 어떤 요청에서도 사용 되지 않음
3) used page : 실행 중인 요청에서 사용중 -> 제거 불가 -
large page
1) empty large page : 내부에 모든 페이지가 empty page일 때
2) evictable large page : 내부에 모든 페이지가 evictable page일 때
위 상태 분류를 기반으로, Jenga는 메모리 할당 알고리즘을 실행 할 때 2가지 원칙을 따른다.
1) 우선적으로 사용되지 않는 페이지는 재사용하고, 필요할 때만 캐시 제거를 수행한다.
2) 하나의 대형 페이지 내부에 작은 페이지들이 동일한 상태를 유지하도록 하여 internal fragmentation을 방지한다.
그리고 Jenga는 특정한 요청에 대해 새로운 작은 페이지를 할당 할 때 아래와 같은 절차를 따른다.
1) 요청과 연관 된 unused small page를 할당한다.
2) 적절한 small page가 없으면 빈 large page를 할당하고, 내부의 모든 small page를 요청과 연관 시킨다.
3) large page가 없는 경우, LRU로 제거 가능한 large page를 제거하고 재사용한다.
4) 1번부터 4번까지 전부 실패한 경우, 요청과 직접 연관 되지 않은 unused small page를 임시로 할당한다.
5) 최후의 수단으로 LRU로 evictable small page를 제거하고 해당 공간을 재사용한다.
실험 결과
Jenga는 vLLM v0.6.4 위에 구현하여 실험을 했고, CUDA 커널을 수정하진 않았다고 한다. 그리고 해당 vLLM 버전에 포팅 된 모델 90여종이 모두 호환이 되었다고 한다. 실험을 위한 환경은 H100과 L4 GPU를 사용하였고, vLLM, SGLang, TGI 프레임워크를 베이스라인으로 사용하였다. 사용한 모델과, 각 모델에 따른 layer 구성은 다음과 같다.
| 모델명 | Layer |
|---|---|
| LLaMA-3.2 Vision | cross-attention layer |
| Gemma-2 | sliding-window layer |
| Ministral | sliding-window layer |
| Jamba | Mamba layer |
| Character.ai | sliding-window + KV cache sharing |
| PyramidKV | sparse attention + layer마다 서로 다른 토큰 수 유지 |
그리고 데이터셋은 MMLU-pro와 MMMU-pro를 사용하였다.
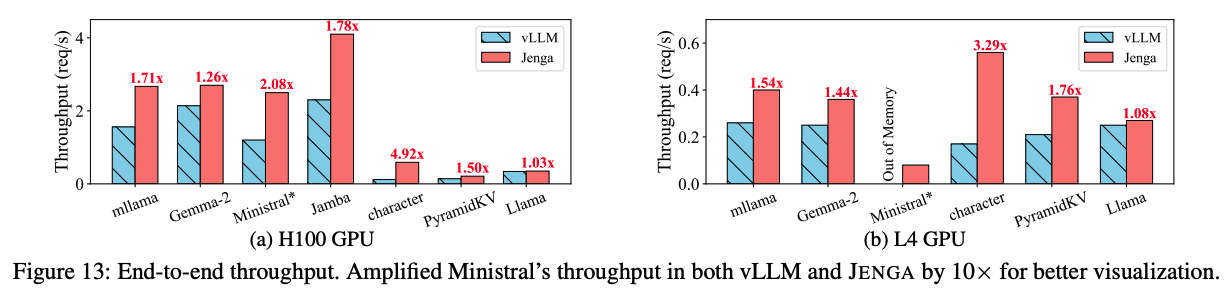
위 그래프는 vLLM 대비 Jenga의 각 GPU 클러스터에서 end-to-end 처리량을 보여준다. Jenga는 메모리 낭비 감소와 prefix caching의 효율화로 인해 H100 기준 최대 4.92배까지 성능 향상을 보여준다고 한다.
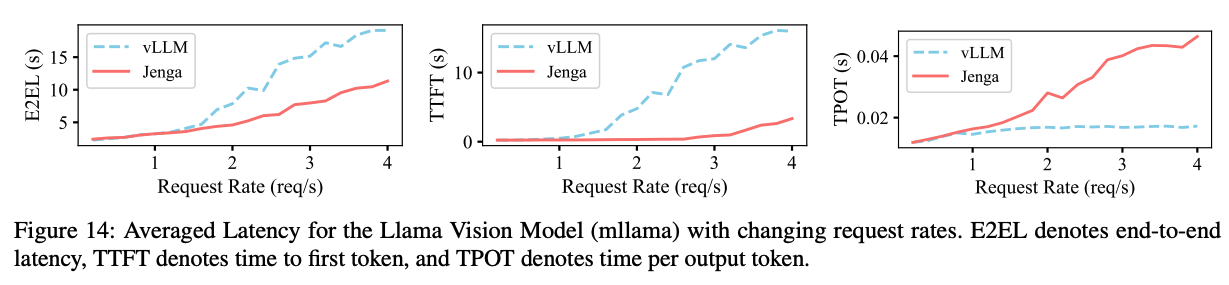
위 그래프는 LLaMA-3.2 Vision 모델을 요청률별 지연 시간으로 나타낸 그래프이다. 요청률이 1.2보다 낮은 구간에서는 vLLM과 Jenga의 지연 시간 차이는 크지 않다. 하지만 요청률이 높아질수록 Jenga의 TTFT가 월등히 높아지는데, 이는 메모리 낭비가 줄어서 더 큰 batch를 처리 할 수 있게 되기 때문이다. 그래서 TPOT은 상대적으로 높게 나오지만 이는 동일 요청수로 batch를 구성하여 vLLM과 동일 수준으로 맞출 수 있다.
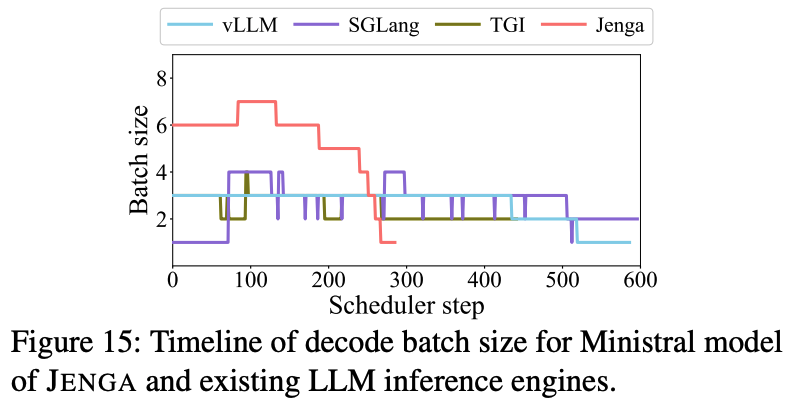
위 그림은 Jenga와 다른 프레임워크에서 decoding 과정에서 발생하는 batch size 크기를 분석한 결과이다. 동시에 20개의 요청이 들어오는 동시에, 장문의 RAG QA 워크로드를 사용하였다. Jenga는 효율적인 메모리 사용을 통해 평균적으로 5.39 batch size로 처리하였고, 이로 인해 300 스텝 이내에서 모든 추론을 완료하였다. 그에 비해 다른 프레임워크들은 약 600 스텝에서 처리를 하였다.
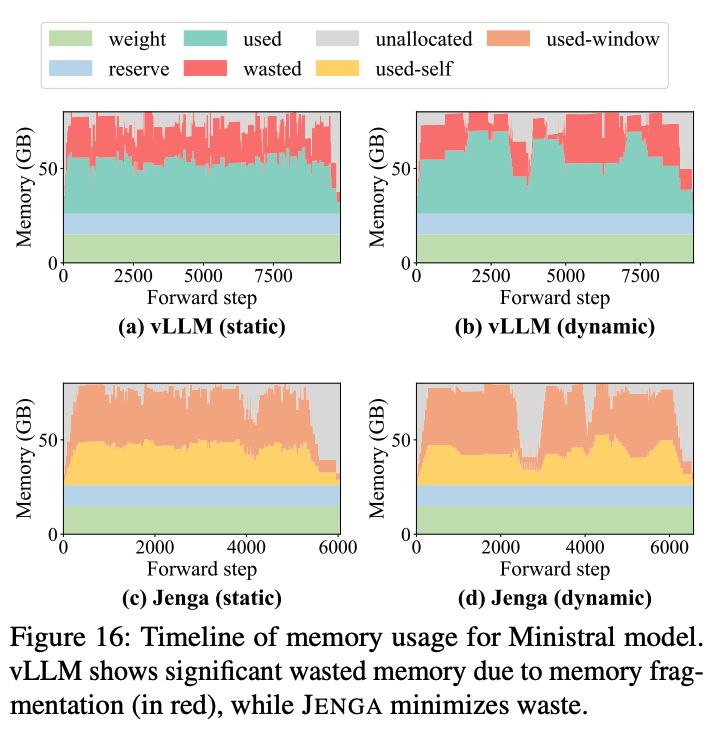
Ministral 모델의 추론 중 메모리 사용량의 경우에도 Jenga는 낮은 fragmentation으로 인해 0.04% 만큼의 메모리 낭비만 발생했다. 그에 비해 vLLM은 평균적으로 38.2%의 KV cache 메모리를 낭비했다.
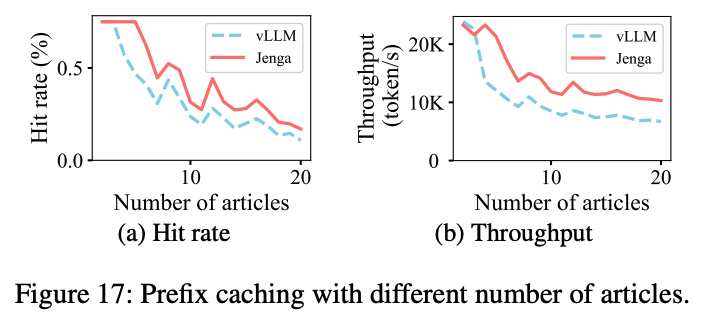
Prefix caching의 경우, 데이터의 수가 작을 때 Jenga가 약간 느린 경향을 보이는데, 이는 self-attention용 메모리와 sliding-window용 메모리 2개를 할당하기 때문이다. 그에 비해 vLLM은 1번만 레이어를 할당한다. 그러나 데이터 수가 많아질수록 Jenga의 cache hit가 더 높고 처리량도 최대 1.77배 상승하였다.
결론 및 고찰
Jenga는 결론적으로 메모리 할당을 two-level로 확장하여, fragmentation과 서로 다른 embedding에 따른 caching 정책을 정의하여, heterogeneous한 레이어 구조를 갖는 LLM에서 더 효율적으로 메모리를 할당 시킬 수 있는 논문이였다. 이 논문의 경우, SOSP 현장에 가서 직접 듣고 싶었는데 슬프게도 회사 이슈로 인해 직관을 하지 못해서 조금 아쉬웠다. 회사에서 사실 heterogeneous한 형태의 LLM을 내가 언급한 적이 있었는데, 시니어 분들은 이러한 구조에 대해 조금 회의적이신 것 같았다. Mamba와 같은 아키텍쳐가 앞으로 얼마나 사용 될지는 모르겠지만, 당분간 대세는 아마 MoE로 좀 더 흘러가지 않을까 싶다.
