[ASPLOS'25] vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
ML System
올해 4월 초에 EuroSys와 ASPLOS를 다녀오면서 거기서 꽤 재밌는 논문들을 많이 소개 받았다. 이전에 리뷰 했던 CacheBlend도 재밌었지만 vAttention 역시 굉장히 흥미로운 주제로 느껴졌던 논문이였다.
최근에 vLLM의 근간이 되었던 Paged Attention을 읽고, 회사에서 직접 vLLM을 사용하면서 GPU 메모리를 페이징으로 관리하는 것이 정말 최선인가? 라는 생각을 종종 한 적이 있다. fragmentation 문제도 그렇고, 연속적이였던 메모리 할당을 비연속적으로 바꾸다보면 직면하게 되는 문제들이 생기게 된다. vAttention은 이전에 vLLM이 가지던 paging 방식의 할당 문제를 해결하고자 나온 논문으로, 어떤 문제점을 해결하였는지 알아보도록 하자.
Paged Attention(vLLM)의 문제점
1. Demand Paging 차이
우선 시작하기 전에 OS의 virtual memory는 demand paging이라는 방식을 사용하여 메모리를 할당한다. 이건 말 그대로 메모리 할당의 수요가 있을 때, 동적으로 page를 만들어서 physical memory를 할당하고 virtual memory와 매핑을 하는 방식을 의미한다. 그래서 virtual memory가 실제로 사용이 되지 않으면 physical memory는 할당이 되지 않는다.
vLLM의 경우, GPU 메모리를 할당하기 위해 cudaMalloc을 사용한다. cudaMalloc은 GPU 상의 virtual memory를 physical memory와 함께 할당을 하게 된다. 그렇기 때문에 virtual memory가 실제로 사용한 적이 없더라도, physical memory가 할당이 되어 있는 문제가 발생한다.
2. Attention Kernel
기존에 구현 된 Attention kernel들은 (또는 비교적 최근에 만들어진 것들도) key와 value의 값이 continuous하게 할당이 되어 있다는 전제 하에 구현이 되어져 있다. 하지만 vLLM의 경우, 이 값들을 비연속적으로 분리하기 때문에, 기존이나 새로운 Attention kernel들을 비연속적인 특성이 맞게 포팅을 해야 한다는 불편함이 발생한다.
3. 중복된 작업의 발생
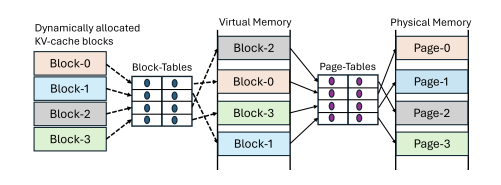
vLLM은 serving framework의 레벨에서 블록을 virtual address에서 physical address로 변환하는 작업을 사실상 2번을 하게 된다. vAttention 논문에서 나온 위 그림이 그 예시 중 하나이다. 들어온 요청에 대해서 4개의 블록이 존재한다고 가정하면, 4개의 블록은 vLLM의 블록 테이블에 따라서 실제로는 virtual memory의 블록과 매핑이 되고, 그리고 OS 레벨에서 다시 매핑이 된다. 그렇기 때문에 실제로는 중복된 작업을 한다고 주장한다.
4. Runtime Overhead
vLLM은 CPU와 GPU에서 추가적인 런타임 오버헤드가 존재한다. 이는 Paged Attention 논문에서도 언급이 된 사실인데, 우선 분기문과 블록 테이블 조회로 인한 오버헤드가 GPU 런타임에서 발생하게 된다. 그리고 블록 테이블을 준비하는 과정과 파이썬 인터페이스에서 CPU 런타임 오버헤드가 발생하게 된다.
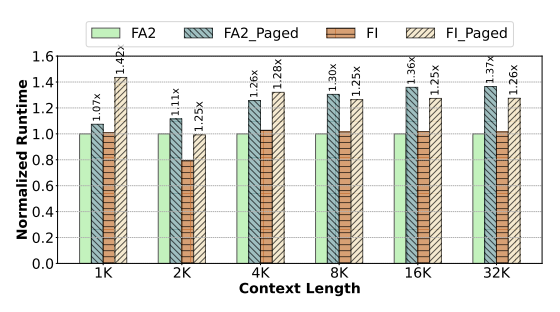
위 그래프는 FlashAttention-2와 FlashInfer 커널에 Paged Attention 여부에 따른 Prefill 단계에서의 성능 변화를 나타낸 그래프이다. 위와 같은 오버헤드로 인해 실제 Prefill 단계에서는 Paged Attention의 latency가 증가하게 된다.
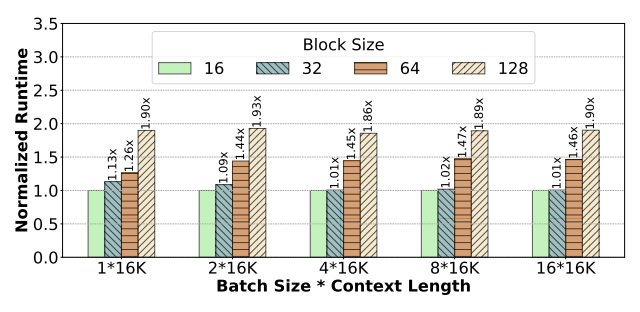
그리고 위 그래프는 블록 크기에 따른 decoding 단계에서 발생하는 오버헤드로 인한 성능 감소 그래프이다. 작은 블록일수록 L1 캐시 적중률이 높아 memory bandwidth의 활용도가 향상되는데, 블록 사이즈가 커지면서 Paged Attention은 그만큼 성능 감소가 더 크게 발생하게 된다.
LLM Serving의 특징
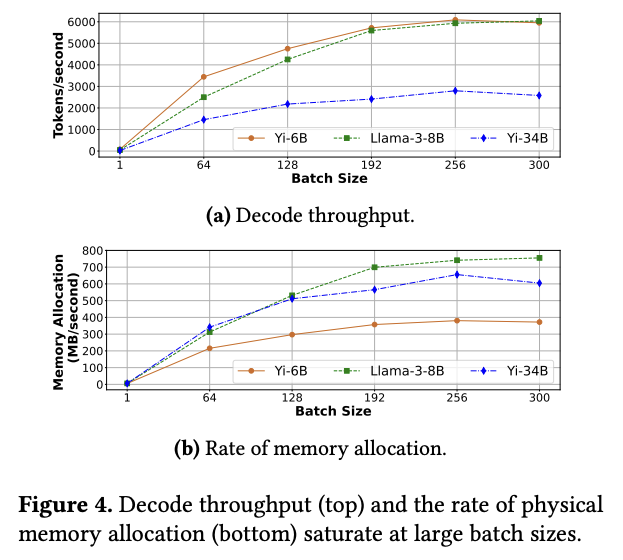
앞서 언급한 4가지 vLLM이 갖는 문제점에 대해 해결법을 제시하기 전에, vAttention 저자들은 LLM inference 워크로드를 분석하면서 몇가지 특징을 잡아내었다. Yi 6B, 34B와 LLaMA-3 8B 모델을 배치 사이즈를 증가 시키면서 decoding 단계에서 throughput과 메모리 할당에 대해 분석하였다.
- KV Cache 할당에 필요한 메모리 크기는 iteration-level에서 예측이 가능하다.
LLM의 decoding 단계는 토큰을 1개씩 반복적으로 생성하는 auto-regressive 작업이다. 그렇기 때문에 매 1 토큰 생성마다 KV Cache의 크기는 매번 1 토큰에 필요한 양만큼 증가하게 된다.
- KV Cache는 메모리 할당을 위해 bandwidth를 크게 요구하지 않는다.
LLM에 존재하는 모든 레이어를 통틀어서 1 토큰에 필요한 메모리 사용량은 KB 단위에 머물 만큼 작다. 각 모델마다 1 토큰에 필요한 메모리는 Yi-6B가 64KB, LLaMA-3 8B가 128KB, 그리고 Yi-34B가 256KB였고, 메모리 할당에는 보통 수십에서 수백 ms 만큼 시간이 소요 되었다. 그렇기 때문에 아무리 많이 쳐줘도 초당 필요한 메모리 할당은 MB 단위일 것이다.
- Batch 단위의 처리는 throughput을 개선하지만, 일정 크기를 넘어가면 TPOT이 오히려 저하된다.
이는 위 그래프 중 (a)그래프로 확인 할 수 있는데, Yi-34B 모델을 보면 256 배치 이후부터는 오히려 TPOT이 꺾이는 구간이 발생한다. 이는 배치 사이즈가 일정 이상 커지만 메모리 할당을 위한 bandwidth가 포화 상태가 되기 때문이다.
vAttention Memory Allocation
앞서 언급한 LLM serving의 특징으로 미루어 볼 때, KV Cache는 vLLM과 다르게 virtual memory의 연속성을 유지하면서 physical memory의 단편화를 방지 할 수 있다는 것을 보였다. 이를 위해서 vAttention은 virtual memory와 physical memory 할당에 대해 서로 다른 정책을 사용하였다.
- virtual memory는 KV Cache를 위해 큰 continuous buffer를 사전에 미리 할당한다.
- physical memory는 실제로 실행 되는 런타임 시점까지 지연 시킨 후 할당한다.
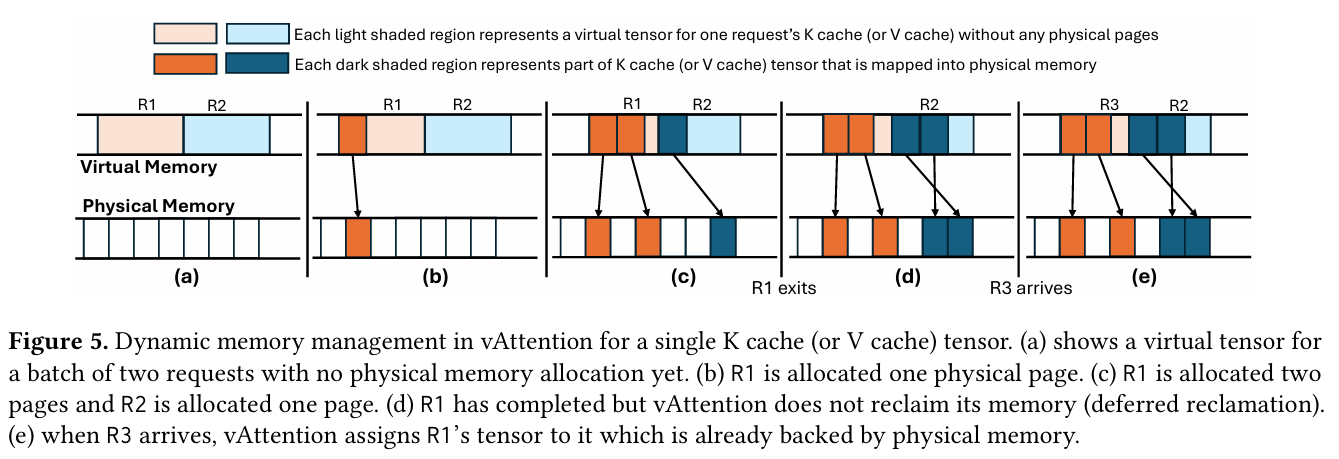
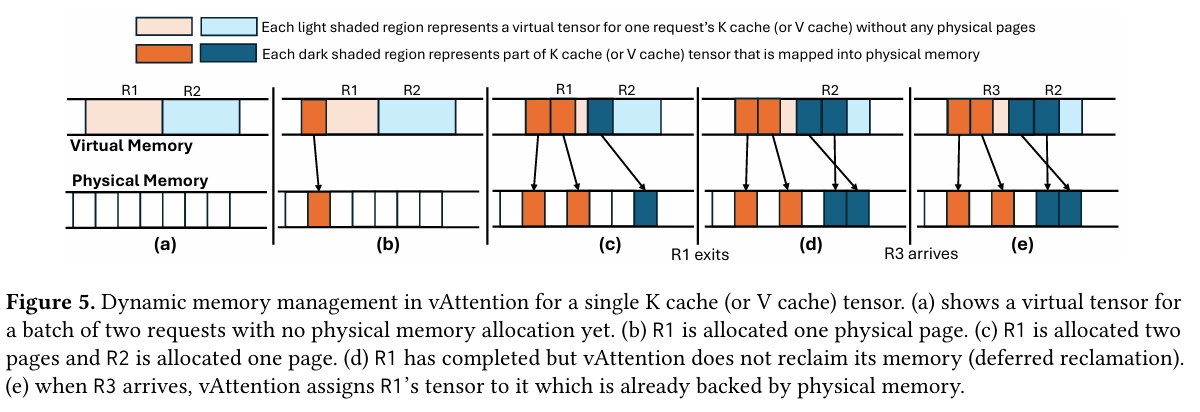
위 그림은 vAttention의 메모리 할당이 어떤 방식으로 이루어지는지에 대한 그 예시이다.
- (a) R1과 R2는 사전에 도착한 요청이고, 이들은 virutal memory에 사전에 미리 할당이 되어 있는 상태이다.
- (b) R1에서 physical page 하나를 할당한다.
- (c) R1에서 physical page 두개를 할당하고, R2에서 하나를 할당한다.
- (d) R1의 요청은 모두 완료가 되었지만, vAttention은 바로 메모리를 회수하지 않는다.
- (e) R3 요청이 들어왔을 때, R1 할당을 재활용한다.
여기서 한 가지 생각해볼만한 것은, virtual memory를 제일 큰 continuous buffer에 맞춰서 사전 할당하는 방식을 사용하면 fragmentation이 virtual memory에서 발생 할 수 있다는 점이다. vAttention은 이러한 질문에 대해서 다음과 같이 증명하였다.
우선 아래 표와 같이 수식에서 사용 되는 표기들을 정리했다.
| 표기 | 설명 |
|---|---|
| 모델 내 레이어의 개수 | |
| 최대 batch size | |
| 한 GPU에서 단일 요청의 레이어별 K cache (또는 V cache) 크기 | |
| 모델이 지원하는 최대 context 길이 | |
| GPU에서 관리하는 KV head 수 | |
| KV head 당 dimension 수 | |
| 모델의 precision에 따른 byte 크기 |
1. 각 요청의 길이
우선 vAttention의 virtual memory는 GPU가 아닌 CPU 메모리를 사용하기 때문에 상대적으로 풍부한 편이다. 그렇기 때문에 우선 각 요청의 context 길이는 LLM이 지원하는 최대 토큰 길이와 동일하다고 가정한다.
2. Virtual memory buffer의 수
그리고 대부분의 serving framework들은 LLM의 각 레이어마다 KV tensor를 관리한다. 그렇기 때문에 하나의 GPU worker에 하나의 LLM이 들어가는 경우, 개의 buffer를 사전에 예약해야 한다. 이 때, 값은 모델 레이어의 수를 의미한다.
3. 단일 Virtual memory buffer 크기
하나의 buffer가 가질 수 있는 최대 크기는 로 결정 된다. 그리고 값의 경우, 를 통해 결정이 된다.
논문에서는 위 수식을 Yi-34B 모델에 대입하여 해당 모델을 2대의 GPU에서 tensor parallelism을 이용하여 serving 할 때 얼마 만큼의 virtual memory가 필요할지 예시를 들어 계산하였다.
Yi-34B의 경우, 필요한 단일 요청 당 buffer 크기는 다음과 같다. (원래 KV head 값은 8이지만, 2 GPU가 tensor parallelism을 사용했기 때문에 값을 사용했다.)
최대 batch size를 500이라고 가정하고, 모델 레이어의 수는 60개이므로, 최종적으로 필요한 virtual memory의 양은 다음과 같다.
이는 일반적으로 하나의 GPU 노드가 128T의 CPU 메모리를 가지고 있고, tensor parallelism을 통해 2대의 워커를 사용하므로 가용 할 수 있는 총 메모리는 256T이다. 이에 비해 12T는 작은 양이므로, virtula memory 할당에 필요한 메모리는 충분하다고 보고 있다.
CUDA Memory Allocation
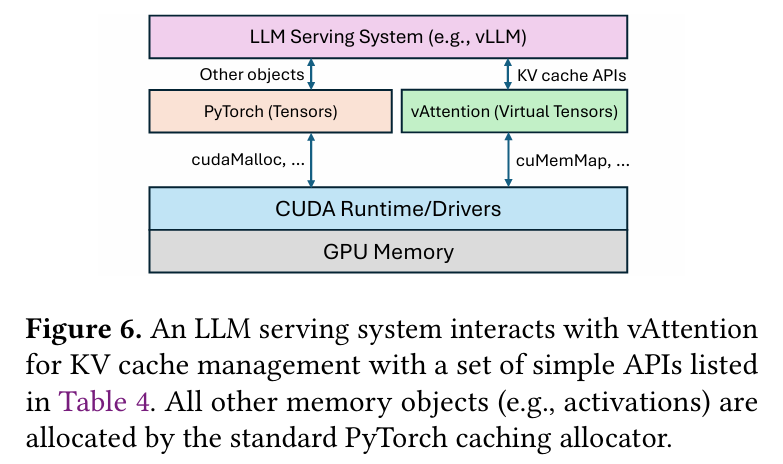
앞서 언급한 vLLM의 문제점 중 하나는, virtual memory 할당 시 cudaMalloc을 사용하면서 virtual memory와 physical memory가 동시에 매핑이 된다는 점이였다. (즉, demand paging을 지원하지 않는다.) 위 그림을 보면, PyTorch와 같은 딥러닝 프레임워크들은 tensor를 할당하는 고유 API들이 있고, 이러한 API들은 대부분 내부적으로 caching allocator가 cudaMalloc을 이용하여 메모리를 할당 시킨다.

vAttention은 이와 다르게 좀 더 low-level인 CUDA VMM API를 사용하여 PyTorch의 caching allocator를 확장 시켰다. VMM API는 CUDA 10.2 버전 이상부터 추가 된 메모리 관련 API들로, 기존의 cudaMalloc과 다르게 virtual memory 예약과 physical memory 할당이 분리 되어 있다.
vAttention은 위와 같은 CUDA VMM API를 이용해서 PyTorch를 이용하여 virtual tensor를 만들게 되는데, 이는 하나의 layer에서 K 또는 V cache를 batch size B에 대해서 나타낸다. 그리고 각각의 요청 부분을 고유한 인덱싱을 사용하여 구분한다.
vAttention Serving

vAttention을 이용하여 실제로 LLM을 서빙 할 때, 전체 과정에 대한 알고리즘은 위와 같이 이루어진다.
1. initialize (line 4)
vAttention이 실행 되면, 앞서 언급 한 모델 파라미터 5가지 () 값과 page 그룹 크기를 설정하게 된다. 만약 Parallelism을 사용하도록 설정이 된 경우에는, 값은 전체 레이어 갯수를 Parallelism 크기 만큼 나눈 값을 사용하게 된다. 그리고 이 단계에서 virtual tensor가 serving application이 끝날 때까지 전체 실행 기간 동안 예약이 된다. Physical memory 또한 각 워커에서 예약이 되는데, 다만 KV cache에 매핑이 되지는 않는다.
2. New request scheduling (line 8)
새로운 요청이 들어오게 되면 vAttention은 virtual tensor에 해당 요청 부분의 인덱싱을 할당한다. 이 후에 발생하는 모든 메모리 작업은 인덱싱 된 값을 태그로 사용하게 된다.
3. Model execution (line 13)
요청이 쌓여서 적당한 batch가 생성 되면, KV cache를 위한 virtual tensor가 physical memory에 할당이 되고 있는지 확인해야 한다. 이를 위해서 각 요청에 대해 현재 context length를 지정하게 된다. 이를 통해 physical memory가 virtual tensor 내 요청에 대해 충분한 physical memory가 매핑이 되었는지 보장할 수 있게 된다.
여기서 vAttention이 physical memory를 충분히 확보 할 수 없는 경우도 발생 할 수 있는데, 이런 경우에는 한 개 이상의 요청을 preemption 시킬 수 있다. 이는 vLLM의 동작 방식과 유사한데, 다른 점은 vAttention의 경우에는 CPU offload는 지원하지 않는다는 점이다.
요청이 처리 되는 단계에 따라 필요한 physical memory가 달라지는데, 분류는 다음과 같다.
- Prefill 단계인 경우, 스케줄링 된 프롬프트의 토큰 수에 따라 달라진다. 또한 여러 토큰을 병렬로 처리하기 때문에 decoding 단계에 비해 더 많은 page group이 필요하다.
- Decoding 단계인 경우, 하나의 요청에 대해 각 virtual tensor마다 필요한 새로운 page group 수는 최대 1개이다.
4. Request complete (line 19)
vAttention이 들어온 요청에 대한 작업이 완료 되었다는 트리거는 3가지가 있는데, 다음과 같다.
- EOS 토큰이 생성 된 경우
- 사용자가 지정한 context 길이 만큼 토큰이 생성 된 경우
- 모델의 최대 context 길이 만큼 토큰이 생성 된 경우
위와 같은 사유로 요청이 종료 되면, vAttention은 완료 된 요청이 가지고 있던 physical memory 할당을 해제하거나, 나중에 해제 하도록 deferred freeing 처리를 한다.
번외. Continuous batching
vAttention의 문제점 중 하나는, KV cache를 여러 요청에 대해 virtual tensor로 묶는 경우, 하나의 요청이 먼저 완료 처리가 되면 virtual tensor에 구멍이 생기게 된다. 이런 경우, Query와 KV cache의 크기가 불일치 되는 상황이 발생하기 때문에, 기존에 vLLM 방식의 continuous batching 방식을 적용하기 어렵다는 문제가 있다. 그래서 vAttention은 Flash Attention을 이용하여, Query와 KV cache 크기가 서로 다른 batch size를 가지는 것을 허용 할 수 있도록 하고, 임의의 순서로 재배치 할 수 있도록 지원하는 방식을 사용했다.
Optimization
저자들이 vAttention을 구현하면서, 2가지 문제에 봉착했다고 한다. 우선 CUDA의 VMM API를 런타임 단계에서 실행하는 경우, 오버헤드로 인해 serving latency에 큰 지장을 주었다는 것이 있었다. 그리고 cuMemCreate API의 경우, 2MB의 배수 단위로 현재 가장 큰 page 할당을 하는데, 이로 인해 internal fragmentation이 발생한다는 점이다.
1. Decoding computation과 memory 할당의 overlapping
VMM API 사용 시 발생하는 오버헤드를 숨기기 위해서, 이를 연산 단계에서 메모리 할당도 하자는 것이 아이디어이다. 그러기 위해서는 메모리 할당 수요를 예측해야 하는데, 이를 위해서 decoding 단계에서는 토큰이 하나씩 생성 된다는 점을 이용하였다.
vAttention은 각 요청에 대해서 현재 context 길이와 이미 매핑 된 physical memory 양을 추적한다. 이를 바탕으로 background thread를 이용하여 다음 iteration에서 필요한 메모리를 예측하고 더 할당할지 말지를 결정한다. 만약 할당이 필요하다면 현재 iteration 연산 중간에 다음 iteration에 필요 할 추가 메모리를 할당 시킨다.
2. Prefill 단계에서 메모리 지연 해제 및 사전 할당 시도
Prefill 단계에서 불필요한 메모리 할당을 메모리 지연 해제와 사전 할당을 통해 방지 할 수 있다. 예를 들자면, 요청 이 번째 iteration에서 완료 되고, 가 번째에서 batch에 합류 했다고 가정했을 때, 을 바로 해제하지 않고, 에 그대로 할당을 한다. 이를 통해 physical memory를 해제 할 필요 없이 물려줌으로써 불필요한 메모리 할당을 방지 할 수 있다.
또한 vAttention은 적은 양의 page group을 사전에 미리 할당 시켜 놓는다. 새로운 요청이 들어왔을 때, 미리 할당 된 page group을 주고, 다음에 들어올 요청에 대한 page group의 인덱스를 미리 지정해놓는다.
3. Internal fragmentation 완화 시키기
일반적으로 internal fragmetation이 발생하는 것을 방지하는 방법 중 하나는 page의 크기를 더 작게 나누는 것이다. 하지만 CUDA VMM API는 NVIDIA driver 위에 구현이 되어 있고, 이 부분은 black-box 코드라서 vAttention 저자들이 직접 수정을 할 수 없었다고 한다.
다만, NVIDIA driver의 UMM (unified memory management) 부분은 오픈소스라서 기존 CUDA API와 동일한 기능을 수행하면서, page 크기는 더 다양하게 지원 할 수 있도록 구현했다고 한다.
실험 결과
실험을 위해 vAttention은 vLLM 0.2.7 버전에 FlashInfer와 FlashAttention-2를 통합하여 베이스라인으로 비교하였다. GPU는 NVLink가 연결 된 A100 80G와 H100을 사용하였다. 모델의 경우, LLaMA-3 8B, Yi 6B와 34B를 사용하였다.
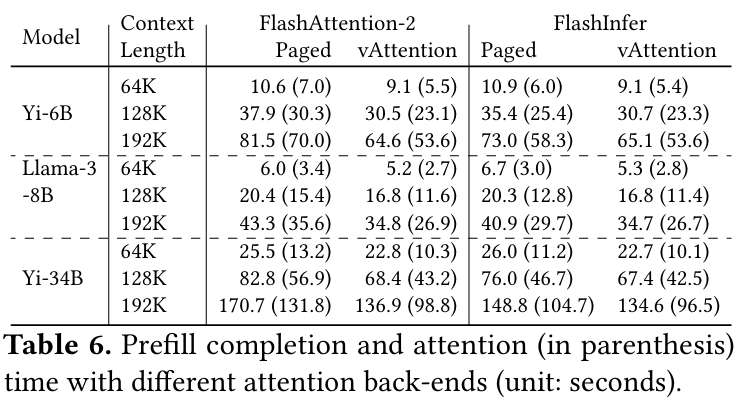
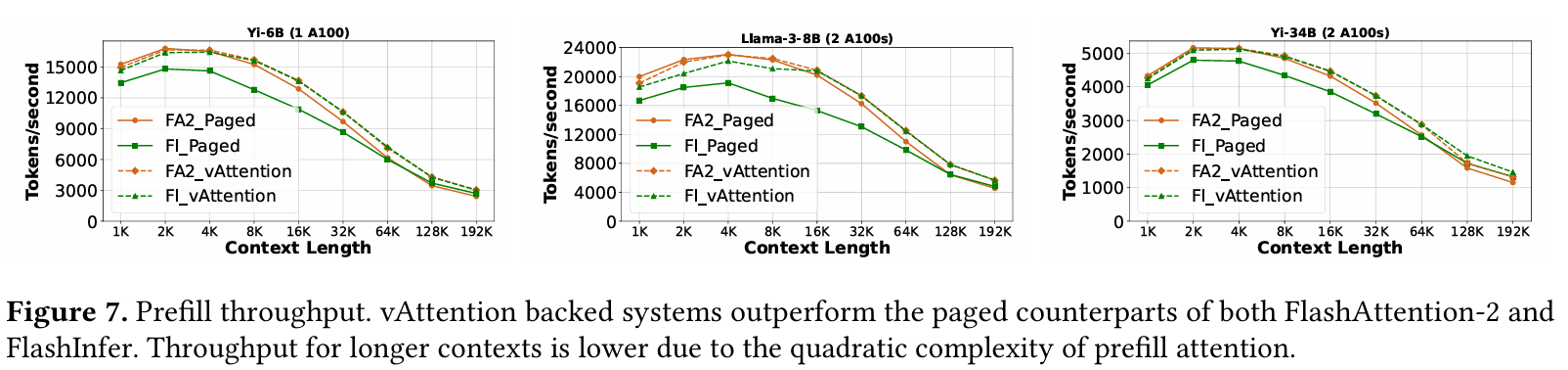
위 그래프는 Prefill에 대한 처리량을 보여준다. FA2는 FlashAttention-2 적용을, FI는 FlashInfer 적용을 의미하고, Paged는 vLLM을 이용한 Paged Attention이 사용 되었음을 의미한다.
context 길이가 짧은 경우, FlashAttention-2 커널에 대해서는 vAttention이나 vLLM이나 세 모델 모두 큰 차이를 보이지 않았다. 반면 FlashInfer에 대해서는 vAttention이 vLLM에 비해 처리량이 개선 되는 것을 보여준다. 이는 vAttention이 가지는 비연속적인 KV Cache 할당으로 인한 특성인데, FlashInfer는 매 iteration마다 block table에 수정이 발생한다. 그러나 vAttention은 연속적인 할당으로 인해 block table이 필요하지 않기 때문에 이러한 오버헤드를 피할 수 있었다.
context 길이가 16K에 이를 정도로 길어지면 커널에 상관 없이 vAttention의 prefill 처리량이 더 높다. 이에 대한 원인 역시 vAttention이 가지는 연속적인 할당 덕분인데, context 길이가 길어질수록, prefill은 attention 연산에 더 많은 시간을 사용하기 때문이다.
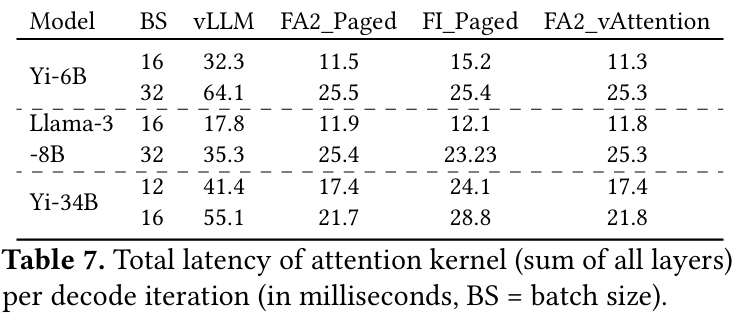
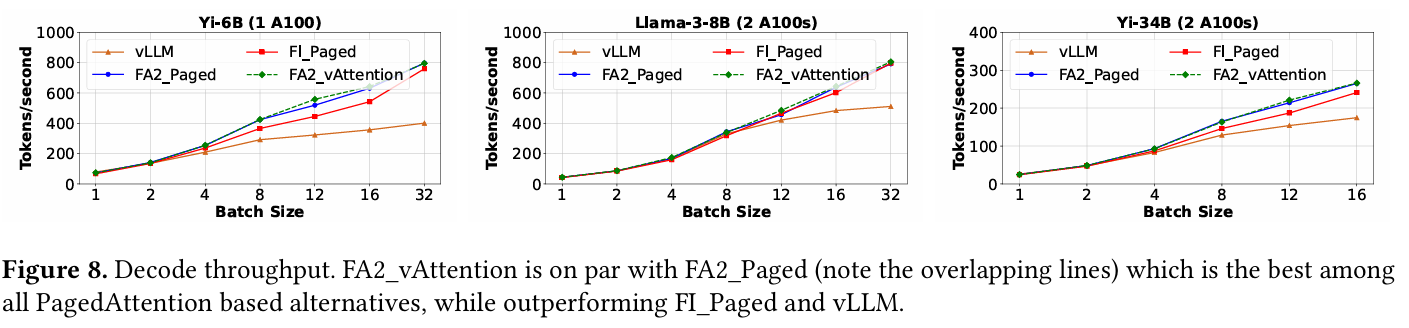
위 그래프는 decoding 단계에 대한 성능 그래프이다. 여기에는 vLLM이라 표기 된 지표가 추가되어 있는데, 이는 vLLM에서 지원하는 decode 커널을 의미한다.
decoding의 경우, 최신 버전의 paged attention과 vAttention의 성능이 거의 비슷한데, 이는 decoding이 memory bound 성격이 강하기 때문으로 보고 있다. paging을 지원하기 위해서는 block table 연산과 같은 부가적인 연산을 수행하게 되는데, memory offloading에 많은 시간을 사용하는 decoding은 이러한 연산을 overlapping을 통해 가리기 쉽다. 반면 prefill은 compute bound 성격이 강해서 이 부분에서 paged attention의 오버헤드가 가려지지 못하기 때문에 성능 격차가 발생했던 것이다.
그러나 vLLM의 decoding은 좀 다른데, 이는 vLLM이 최신 paged attention을 적절하게 최적화하지 못했기 때문으로 보고 있다.
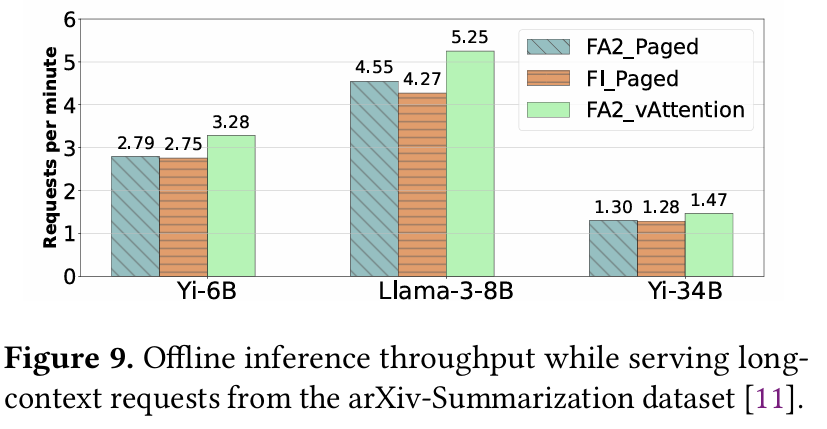
위 그래프는 prefill과 decoding을 모두 포함하여, offline inference로 end-to-end 처리량을 비교한 그래프이다. vAttention의 성능이 전체적으로 좋게 나왔다. 이를 결정 짓는 것은 context 길이과 prefill과 decoding의 비율로, 결국 prefill이 큰 작업이라면 vAttention의 성능이 좋다는 것이 결론이다.
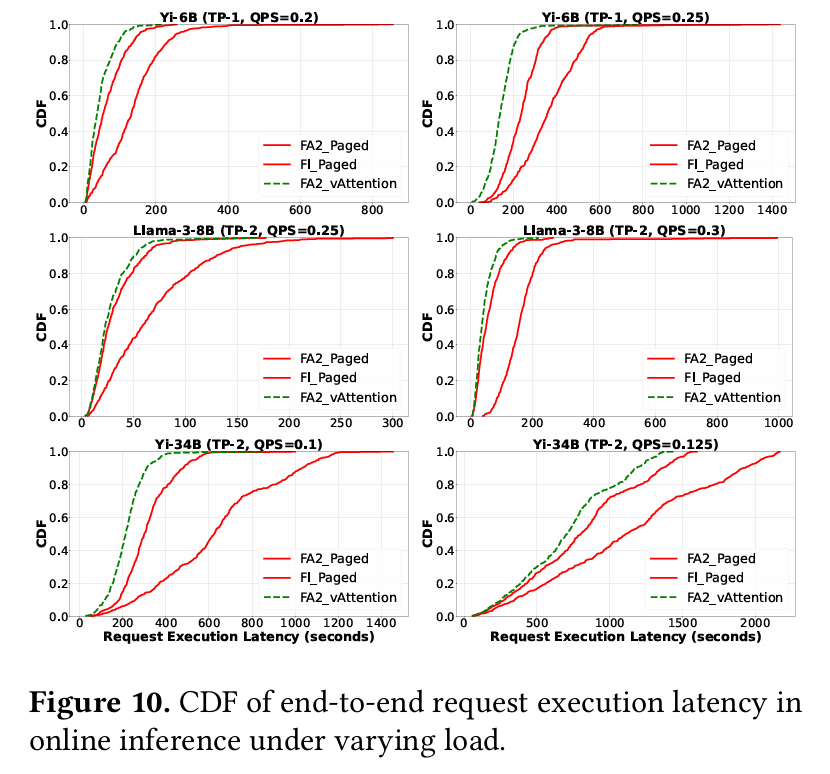
요청들을 offline에서 푸아송 분포를 따르는 online inference로 바꾸었을 때도, vAttention이 더 높은 처리량을 기록하였다. 앞서 언급한 prefill 비율이 큰 작업일수록 성능 향상도 이루어지기 때문에, 새로운 요청에 대한 prefiil을 더 빠르게 처리할 수 있다. 이로 인한 queue delay가 상대적으로 적은 것이 원인이라고 볼 수 있다.
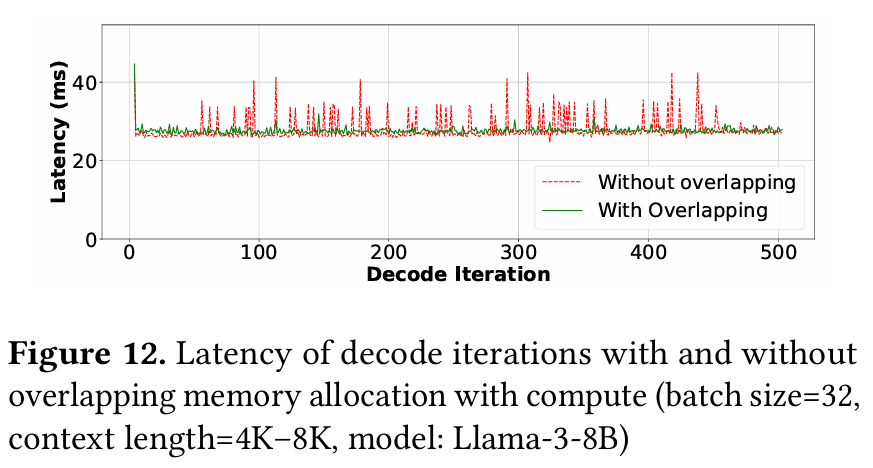
위 그래프는 decoding 단계에서 메모리 할당에 대한 overlapping 유무에 따른 latency를 기록한 그래프이다. overlapping을 사용하지 않은 경우, 메모리 할당으로 인해 spike가 발생하는 구간이 생긴다.

위 그래프는 CUDA API의 synchronous 방식과 VMM API를 이용 했을 때, 그리고 지연 할당을 사용 했을 때를 비교한 그래프이다. synchronous API를 사용하더라도, 지연 할당을 사용하면 메모리를 다시 할당하는 경우가 발생하지 않기 때문에 VMM API를 이용했을 때와 거의 동등한 성능을 달성할 수 있다고 한다.
결론 및 고찰
이 논문을 리뷰하면서, ASPLOS를 올해 4월에 가서 직관을 한 번 했음에도 잘 이해가 되지 않아서 조금 당황스럽고 시간이 오래 걸렸다. 결국 기존에 paging 방식으로 비연속적인 할당이 생각보다 비효율적인 면이 있고, vLLM도 오픈 소스가 가지는 이점에 비해 새로운 모델의 포팅이 어렵다는 점을 근거로 나온 논문이다. 이걸 보면서 CUDA VMM API의 존재를 처음 알게 되었는데, 한 번쯤 회사에서 써볼 수 있으면 좋겠다는 생각이 들었다.
vAttention의 경우, vLLM과는 메모리에 대한 철학이 다르기 때문에 vLLM 진영 측에 합류 되지 못한 것으로 보인다. (누군가 이걸 구현해서 PR을 올렸는데 거절 당했던걸 봤다.) 그 대신, MS에서 개발한 Sarathi-Serve에 통합 되어 있고, 이걸로 사용해봐도 좋을 것 같다.
