공간
공간(space)은 덧셈연산(+), 스칼라 곱(k배) 연산에 닫혀 있다.
n-벡터 집합은 공간이다.
그리고 이를 벡터 공간이라고 한다.
최소제곱법
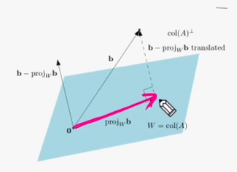
선형 시스템 Ax=b에 대한 해가 없음에도 불구하고, 달성가능한 최선의 목표(근사치) 를 구하는 것
b를 col(A)=w에 투영한 값을 구하는 것
이 때, 이 방법은 목표 b와 달성가능한 목표 의 차이를 최소화하기 때문에 최소제곱법이라고 한다.
- 주어진 선형시스템의 양변에 전치행렬 를 곱하면 최소제곱법의 해를 구할 수 있다.
이렇게 구한 해는 선형시스템을 만족하는 해는 아니고
다음을 만족하는 근사해라고 한다.
선형회귀
이를 선형회귀를 구할 때 적용할 수 있는데,
각 데이터들을 지나는 직선이 존재한다고 가정하고, 이를 만족하는 근사해를 구함으로써 선형회귀 직선을구할 수 있다.
통계학
scipy
scipy를 사용하여 각종 통계 수치를 쉽게 계산할 수 있다.
평균
평균은 파이썬 기본 패키지로 계산할 수 있다.
import statistics
statistics.mean(a)중앙값
평균은 극단값(이상치)의 영향을 많이 받는다
자료를 순서대로 나열했을 때, 가운데 있는 값
자료의 수가 n일 때,
n이 홀수라면 번째 자료값
n이 짝수라면 번째와 번째 값의 평균(실제로 존재하는 값은 아님)
중앙값 또한 파이썬 기본 패키지로 계산할 수 있다.
statistics.median(a)분산
편차의 제곱의 합을 자료의 수로 나눈 값
(편차 : 값과 평균의 차이)

# 표본분산
statistics.variance(a)
import scipy
import scipy.stats
scipy.stats.tvar(a)표준편차
분산의 양의 제곱근

#표본표준편차
statistics.stdev(a)
# 모표준편차
statistics.pstdev(a)
# 모분산
statistics.pvariance(a)import numpy
# 모분산, 모표준편차
numpy.var(a)
numpy.std(a)
# 표본분산, 표준편차
# ddof : Delta Degrees of Freedom(자유도)
numpy.var(a, ddof=1)
numpy.std(a, ddof=1)범위
자료를 정렬했을 때, 가장 큰 값과 가장 작은 값의 차이
max(a)-min(a)
numpy.max(a) - numpy.min(a)사분위수(Quartile)
전체 자료를 정렬했을 때 위치에 있는 수
numpy.quantile(a, .25)
numpy.quantile(a, .5)
numpy.quantile(a, .75)
# 다음과 같이 꼭 사분위수를 구하는데만 사용되는건 아님
numpy.quantile(a, .6)z-score
어떤 값이 평균으로부터 몇 표준편차 떨어져있는지를 의미하는 값

# 모집단의 경우
scipy.stats.zscore(a)
# 표본집단의경우
scipy.stats.zscore(a, ddof=1)
오래 공부하는 사람