이전에는 클라우드 서비스 마이크로소프트 Azure를 사용해보았었는데,
프로그래머스 데브코스에서는 AWS를 다뤄보게 되었다.
AWS는 인스턴스를 생성한 후에, 보안 key 파일을 가지고 ssh 접속을 해야 한다.
ssh 접속은 평소 자주 사용하던 mobaXterm을 사용하였다.
mobaXterm 을 사용하기전에는 권한 설정 이슈가 있었는데,
구글링을 통한 어느 해결법으로도 해결이 되질 않았고,
인스턴스를 새로 생성하고, 처음 만든 상태 그대로의 보안 key파일을 가지고
mobaXterm을 사용하자 권한 설정 없이 접근이 되었다.(여전히 윈도우 PowerShell에서는 접근되지 않는다)
프리티어 계정을 통해 생성한 기초적인 인스턴스지만
딥러닝에 필요한 기본적인 모듈들이 설치되어있었다.
conda env list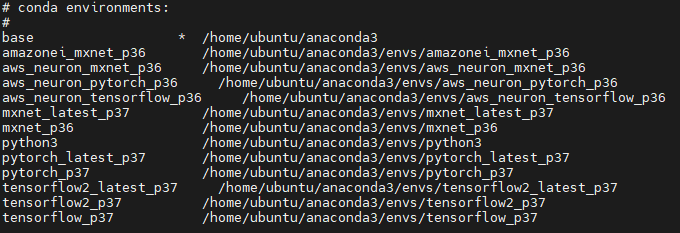
그러나 이 방법으로는 원격 인스턴스에 직접 연결은 가능하지만,
vs code 등 ide를 통한 원격 개발 환경에는 적용할 수가 없어서 결국 방법을 더 알아보았고,
wsl을 설치하여 windows 상에 linux 하위 시스템을 설치함으로써 해결하였다.
그런데, wsl을 통한 chmod 명령어의 권한 변경이 제대로 적용되지 않았다.
명령어에 오류는 발생하지 않지만 명령 변경이 적용되지 않았다.
이에 대해 찾아보니
https://github.com/microsoft/WSL/issues/81
해당 링크에서 mnt 하위 시스템에서는 권한 변경이 적용되지 않는다고 한다.
따라서 key 파일을 home 하위 시스템으로 옮기고, 권한 변경을 적용시킨 뒤에 적용한 결과 접속에 성공하였다.
변경한 파일을 mnt 하위로 옮기면 다음과 사진과 같이 변경 내용이 사라진다. 그대로 home 하위 에서 사용하였다.
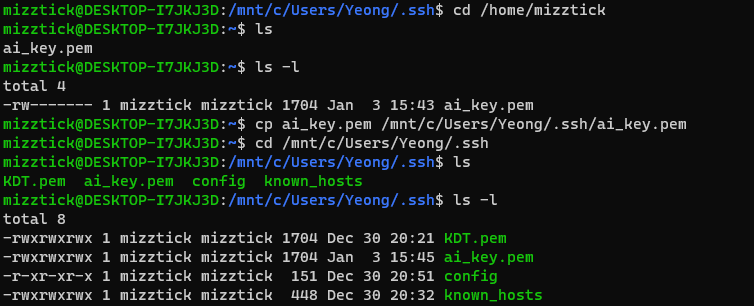
이를 vscode의 원격 ssh 개발 환경에 적용하기 위해서는
pem 파일의 경로를
\\wsl$\Ubuntu-20.04\home\mizztick로 사용한다.
여기까지 시행착오가 굉장히 많았는데, 다른 해결 방법으로 제시되는 권한 상속 해제로는 해결되지 않았던 본인은 이 방법으로 해결하였다.
api serving
serving을 위한 모델 api는 다음과 같은 큰 틀을 생각해야 한다.
(꼭 갖추어야하는 것은 아니지만 유지보수 등의 측면에서 습관을 들이자)
class ModelHandler(BaseHandelr):
def __init__(self):
def initialize(self, **kwargs):
# 데이터 처리나 모델, configuration 등 초기화
# 1. Configuration 등 초기화
# 2. (Optional) 신경망을 구성하고 초기화
# 3. 사전 학습한 모델이나 전처리기 불러오기
pass
def preprocess(self, data):
# Raw input을 전처리 및 모델 입력 가능 형태로 변환
# 1. Raw input 전처리
# 데이터 클린징의 목적과 학습된 모델의 학습 당시 Scaling이나 처리 방식과 맞춰주는 것이 필요
# 2. 모델에 입력 가능한 형태로 변환
# vectorization, converting to id 등의 작업
pass
def inference(self, data):
# 입력된 값에 대한 예측 / 추론
# 1. 각 모델의 predict 방식으로 예측 확률 분포 값 반환
pass
def postporecess(self, model_output):
# 모델의 예측값을 response에 맞게 후처리 작업
# 1. 예측된 결과에 대한 후처리 작업
# 2. 보통 모델이 반환하는 것은 확률분포와 같은 값이기 때문에 response에서 받아야하는 정보로 처리하는 역할
pass
def handle(self, data):
# 요청 정보를 받아 적절한 정보를 반환
# 1. 정의된 양식으로 데이터가 입력됐는지 확인
# 2. 입력 값에 대한 전처리 및 모델에 입력하기 위한 형태로 변환
# 3. 모델 추론
# 4. 모델 반환값의 후처리 작업
# 5. 결과 반환
pass
API 정의
Flask 기반 감성분석 api 예제를 수행할 것이다.
key:value 형태의 json 포맷으로 request를 받아서, text index 별로 key:value로 결과를 저장한 json 포맷으로 결과를 반환한다.
# [POST] /predict
json = {
"text": [review1", "review2", ..., ],
"do_fast": true or false
}# response
{ "idx0" : {
"text": "review1",
"label": "positive" or "negative",
"confidence": float
},
"idxn" : {...},
...,
}모델 핸들러의 각 부분은 다음과 같이 구성한다.
초기화
def initialize(self, ):
from transformers import AutoTokenizer, AutoModelForSequenceClassification
self.model_name_or_path = 'sackoh/bert-base-multilingual-cased-nsmc'
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name_or_path)
self.model = AutoModelForSequenceClassification.from_pretrained(self.model_name_or_path)
self.model.to('cpu')전처리
def preprocess(self, text):
model_input = self._clean_text(text)
model_input = self.tokenizer(text, return_tensors='pt', padding=True)
return model_input추론
def inference(self, model_input):
with torch.no_grad():
model_output = self.model(**model_input)[0].cpu()
model_output = 1.0 / (1.0 + torch.exp(-model_output))
model_output = model_output.numpy().astype('float')
return model_output후처리
def postprocess(self, model_output):
predicted_probabilities = model_output.max(axis=1)
predicted_ids = model_output.argmax(axis=1)
predicted_labels = [self.id2label[id_] for id_ in predicted_ids]
return predcited_labels, predicted_probabilities핸들링
def handle(self, data):
model_input = self.preprocess(data)
model_output = self.inference(model_input)
return self.postprocess(model_output)과제
예제 코드를 통해 flask 기반 post 요청을 통한 추론 모델을 실행시켜보았다.
post 혹은 get으로 학습을 요청하고 학습 수행 시간을 반환하도록 해보자.
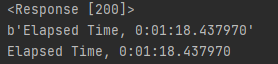
먼저 간단히 수행 시간을 반환하도록 했는데, 기본 반환이 byte 타입이다(만약 관리해야된다면 포맷을 변경하자)
import requests
url = "http://host:port//train"
response = requests.post(url)
print(response)
print(response.content)
print(response.content.decode('utf-8'))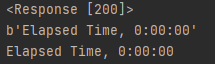
학습용 데이터 다운로드 및 학습 / 평가 / 모델 저장 후 경과 시간 반환
# train_ml.py
def download_data(mode):
base_url = f'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_{mode}.txt'
r = requests.get(base_url)
with open(f'ratings_{mode}.txt', 'wb') as w:
w.write(r.content)
logger.info("Downloaded from {}".format(base_url))
def train_and_evaluate():
train = pd.read_csv('ratings_train.txt', sep='\t').drop('id', axis=1).fillna('')
test = pd.read_csv('ratings_test.txt', sep='\t').drop('id', axis=1).fillna('')
X_train, y_train = train['document'].apply(clean_text), train['label']
X_test, y_test = test['document'].apply(clean_text), test['label']
vectorizer = CountVectorizer(max_features=100000)
vectorizer.fit(X_train)
logger.info("fitting Counter vectorizer")
X_train = vectorizer.transform(X_train)
X_test = vectorizer.transform(X_test)
logger.info("Transform raw text into vector")
model = MultinomialNB()
model.fit(X_train, y_train)
logger.info("Trained Naive Bayes model.")
evaluation_score = model.score(X_test, y_test)
logger.info(f"ML model accuracy score: {evaluation_score*100:.2f}%")
return model, vectorizer
def serialization(model, vectorizer):
import joblib
os.makedirs('model', exist_ok=True)
joblib.dump(vectorizer, 'model/ml_vectorizer.pkl')
logger.info(f'Saved vectorizer to `model/ml_vectorizer.pkl`')
joblib.dump(model, 'model/ml_model.pkl')
logger.info(f'Saved model to `model/ml_model.pkl`')
학습 요청
@app.route("/train", methods=["POST"])
def train():
start_time = datetime.now()
# Download train and test data from github
for mode in ['train', 'test']:
train_ml.download_data(mode)
# train and evaluate model
model, vectorizer = train_ml.train_and_evaluate()
# Serialization
train_ml.serialization(model, vectorizer)
return f'Elapsed Time, {datetime.now() - start_time}'결과
학습 요청 후 경과 시간