추후 마지막 프로젝트를 진행할 팀을 정해야했는데,
관심 주제인 GAN을 제시했을 때 안타깝게도 이번 기수에
크게 GAN에 관심있는 사람이 없었다.
내가 선택할 수 있는 방법은 크게 3가지 였는데,
- 관심도가 떨어지는 다른 주제를 선택해서 팀에 합류한다.
- 1과 병행하고, GAN을 다루는 서브 프로젝트를 따로 준비한다.
- 혼자 프로젝트를 준비한다.
1은 취업 도메인이 바뀔 수 있는 문제라고 판단해서, 2와 3을 고려했는데 어차피 2를 할것이라면 그 노력으로(프로젝트를 2개한다는 것이니까)
3을 하기로 했다.
다른 팀의 3~4인 이상의 인력이 작업할 일을 혼자 해야하기 때문에, 조금 더 미리 준비를 해나가기로 했다.
큰 일을 준비할 때는 계획을 세워야 한다.
계획대로 모든게 이루어지지는 않겠지만,
그렇다고 계획을 하지 않은 것에 비할 것은 아니다.
지금 판단하기에 커다란 줄기들을 나열하고
단계별로 진행할 계획이다.
준비할 프로젝트의 큰 틀은
자연어 음성 생성 프로젝트이다.
서비스적인 측면에서는,
영상 + 자막 파일이 있을 때,
자막 파일의 내용을 토대로
영상의 각 자막의 위치에 자막의 내용에 맞는 음성을 생성하여 영상에 합쳐주는 프로젝트를 만들 생각이다.
음성 생성은 GAN을 기반으로 만들 예정이며,
음성을 억양 + 목소리톤 으로 구분했을 때,
억양의 경우에는 좀 더 많은 데이터가 필요하겠지만,
적어도 아주 적은 데이터를 입력받아
그 데이터와 유사한 목소리톤을 구현해주는 것을 목표로 한다.
현재 기초적인 내용부터 시작해서 공부를 시작했다.
세부적인 중간 목표들은 다음과 같다.
웹 서버가 존재해야 한다.
-
웹 서버는 영상파일, 자막파일을 입력 받을 수 있다.
-
몇 가지 sample 목소리를 기본으로 제공한다.
-
(제일 중요) 임의의 음성 파일을 제공함으로써(녹음 or 음성파일) 해당 음성 파일을 기반으로 목소리를 만들어줄 수 있어야 한다.
- 단순 목소리톤의 유사성은 기본 전제
- 제공된 음성의 억양 정보는 데이터가 적을 경우에도 유의미하게 구현이 될 것인지? 이건 서브 목표이다.
- 영상이 입력되었을 때, 수동으로 영상을 시간 순서대로 조회하며 자막을 입력할 수 있다.
- 서버는 프로그래머스 지원상 AWS를 사용할 예정이다.
- 웹 서버를 배포해야 한다.
- 예상되는 문제점 : 업로드, 버퍼링 시간이 오래 걸리는 점(영상 파일의 경우 대체로 용량이 클 것이기 때문에) : 상용 서비스를 만드는 것이 아니기 때문에 큰 고려 대상은 아니지만, 최소화 시키는 방법은 고려해야한다.
GAN 기반 음성 합성
- 본 프로젝트는 상용화를 목표로 하는 것이 아니고, 나 자신의 능력을 향상시키는 것을 목표로 한다.
-
따라서, 가장 효율적인 알고리즘일 필요는 없다.
-
유의미한 효과를 가진, 나름대로의 장점이 있는 최신 기술을 사용하는 것을 목표로 한다.
- 어떤 기술을 사용하던지, 나름대로의 이유가 있어야 하며, 그 과정에서 개선점을 최대한 찾아보자
효율성
- 상용화를 목표로 하지 않지만, 배포를 전제로 한 서비스이기 때문에 최대한 효율적으로 작성해서 사용에 심각한 문제가 일어나지 않도록 해야 한다.
심미성
-
앞서 기술적인 문제들이 먼저 해결되고 나면, UI는 직관적이고 사용이 편하도록 개선해야 한다.
-
깔끔하고 편리한 디자인을 목표로 한다.
프로젝트 진행 순서
딥러닝 모델이 준비되질 않으면, 다른 것은 모두 껍데기에 불과한 프로젝트이다.
따라서,
1. GAN에 대한 기초 공부
2. 음성 합성 GAN 모델 예제 구현
현재는 다음 모델 사용 계획 : HiFi-GAN
3. sample 데이터를 이용한 구현 모델의 서비스 적합성 평가
4. 해당 모델의 서비스 flow 디자인
5. 데이터 준비 및 사전 훈련 모델 준비
5. 웹 서버 구현(기초적인 UI)
6. 서버를 이용해서 웹 및 모델을 배포
7. UI 개선 및 모델 개선
으로 진행할 계획이다.
Generative Adversarial Networks, GAN 기초
일반적으로 신경망은 정보를 감소, 정체, 축약한다.
예를 들어 이미지 분류 문제에서,
n * m 이미지 픽셀 데이터를 k개의 출력(구분 종류)으로 변환한다.
이걸 반대로 한다면 어떨까?
개라는 입력을 주어서, n * m 이미지 픽셀 데이터를 출력한다면?
기본적으로 이를 백쿼리(backquery)라고 한다.
백쿼리를 통해 만들어진 이미지는 기본적으로 다음과 같은 특성이 있다.
- 같은 원핫 인코딩 벡터면 같은 결과를 출력한다.
- 그 레이블을 나타내는 모든 훈련 데이터의 뭔가 평균적인 이미지가 나온다.
그런데 이상적인 목표는 위의 내용이 아니라 다음과 같다.
- 각각 서로 다른 이미지를 만들어낸다.(다른 결과)
- 원래 입력되어야할 훈련 데이터처럼 보이는 이미지를 만들어 낸다.
일반적인 백쿼리로는 이런 목표 수행이 불가능하다.
그런데, 이를 가능하게 한 것이 GAN이다.
GAN 이전 까지 네트워크의 발달은
기존보다 크거나, 넓거나, 깊은 신경망 구조
혹은 새로운 활성화 함수
혹은 새로운 최적화 기법
으로 발달하였는데 GAN은 구조적으로 성질이 다르다.
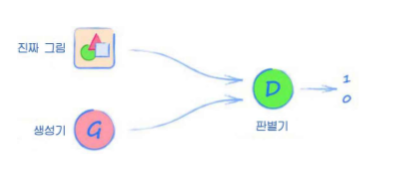
판별기는 입력값이 진짜 인지 아닌지 구별해야하고,
생성기는 자신이 만들어낸 가짜가 판별기를 통과하도록 해야 한다.
생성기가 만든 이미지가 판별기를 속이면 생성기에 보상을 주고
속이지 못 하면 생성기에 벌을 준다.
이 과정을 반복해서
판별기와 생성기를 서로 성능을 증가시키게 만든다(적대적 관계)
이때, 판별기와 생성기는 동시에 비슷한 수준으로 성장시켜가야한다.
GAN은 기초적으로 다음과 같은 단계로 구성한다.
- 판별기에 실제 데이터를 입력하고 분류한다. 결과는 1이 되어야 하며, 오차가 발생하면 이를 판별기를 업데이트하는데 사용한다.
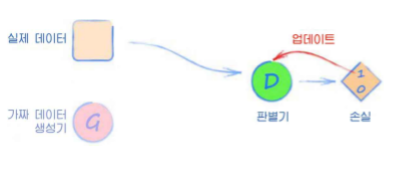
- 판별기에 생성기에서 만든 데이터를 입력하고 분류한다. 결과는 0이 되어야 하며, 오차가 발생하면 이를 판별기만 업데이트한다.
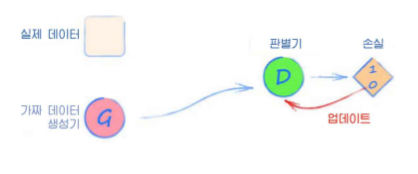
- 생성기를 훈련한다.
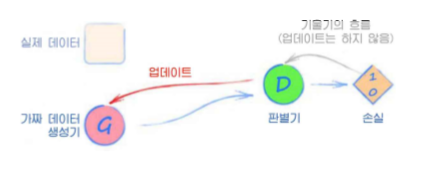
비슷한 수준이어야하다는 점에서,
생성기의 신경망은 많은 경우에 판별기의 복사본에서 시작한다
(물론 입력, 출력이 반대)
- 1010 GAN 예제
1,0,1,0의 입력이 진짜 데이터라고 판별하는 예제이다.
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
self.loss_function = nn.MSELoss()
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
self.count = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train(self, inputs, targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs, targets)
self.count += 1
if (self.count % 10 == 0):
self.progress.append(loss.item())
if (self.count % 10000 == 0):
print("counter : ", self.count)
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(1, 3),
nn.Sigmoid(),
nn.Linear(3, 4),
nn.Sigmoid()
)
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
self.counter = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train(self, D, inputs, targets):
# 신경망 출력 계산
g_output = self.forward(inputs)
# 판별기로 전달
d_output = D.forward(g_output)
loss = D.loss_function(d_output, targets)
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()생성기의 train을 위 그림의 3단계와 비교해보면,
생성기를 훈련할때는 판별기를 업데이트하지 않는다
%%time
image_list = []
D = Discriminator()
G = Generator()
# train Discriminator and Generator
for i in range(10000):
# 1단계 : 참에 대한 판별기 훈련
D.train(generate_real(), torch.FloatTensor([1.0]))
# 2단계 : 거짓에 대한 판별기 훈련
# G의 기울기가 계산되지 않도록 detach 함수를 이용
# G의 출력에 적용되어 계산 그래프에서 생성기를 떼어내는 역할
# D에서 호출된 backward에서 시작된 기울기 계산이 생성기까지 이어지는데, 이를 떼어냄으로써 방지
# 이는 결과에 영항을 주는 것이 아니라, 사실 이 계산이 필요없는 행위인데
# 큰 신경망 구조에서 시간 복잡도에 영향을 주기 때문
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
# 3단계 : 생성기 훈련
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
# add image to list every 1000
if (i % 1000 == 0):
image_list.append( G.forward(torch.FloatTensor([0.5])).detach().numpy() )
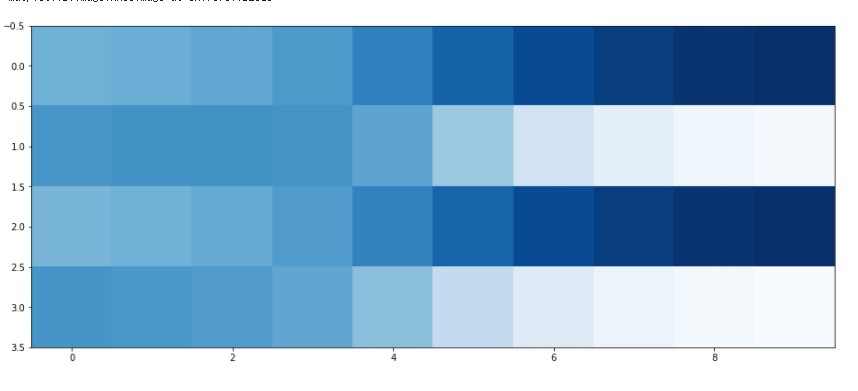
passGAN 훈련 3단계를 거친 후
generator가
점점 패턴을 가춰가는 것을 볼 수 있다
plt.figure(figsize = (16,8))
plt.imshow(numpy.array(image_list).T, interpolation='none', cmap='Blues')