dataset 준비
dataloader
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pd.read_csv(csv_file, header=None)
# Dataset을 위한 특수 메소드, 데이터셋의 길이를 반환
def __len__(self):
return len(self.data_df)
# Dataset을 위한 특수 메소드, n번째 아이템을 반환
def __getitem__(self, index):
label = self.data_df.iloc[index, 0]
# 10개 숫자중 label의 숫자에만 1로 one-hot encoding
target = torch.zeros((10))
target[label] = 1.0
# 0-255의 이미지를 0-1로 정규화
image_values = torch.FloatTensor(self.data_df.iloc[index, 1:].values) / 255.0
# 레이블, 이미지 데이터 센서, 목표 텐서 반환
return label, image_values, target
def plot_image(self, index):
img = self.data_df.iloc[index, 1:].values.reshape(28, 28)
plt.title("label = " + str(self.data_df.iloc[index, 0]))
plt.imshow(img, interpolation='none', cmap = "Blues")
plt.show()mnist_dataset = MnistDataset('data/mnist_train.csv')
mnist_dataset.plot_image(17)
판별기
# discriminator class
class Discriminator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
nn.Linear(200, 1),
nn.Sigmoid()
)
# create loss function
self.loss_function = nn.MSELoss()
# create optimiser, simple stochastic gradient descent
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# counter and accumulator for progress
self.counter = 0;
self.progress = []
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, inputs, targets):
# calculate the output of the network
outputs = self.forward(inputs)
# calculate loss
loss = self.loss_function(outputs, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))판별기 성능 확인(진짜 가짜를 구별할 능력이 있는지)
def generate_random(size):
random_data = torch.rand(size)
return random_data
D = Discriminator()
for label, image_data_tensor, target_tensor in mnist_dataset:
D.train(image_data_tensor, torch.FloatTensor([1.0]))
D.train(generate_random(784), torch.FloatTensor([0.0]))
for i in range(4):
image_data_tensor = mnist_dataset[random.randint(0, 60000)][1]
print(D.forward(image_data_tensor).item())
for i in range(4):
print(D.forward(generate_random(784)).item())생성기
# generator class
class Generator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(1, 200),
nn.Sigmoid(),
nn.Linear(200, 784),
nn.Sigmoid()
)
# create optimiser, simple stochastic gradient descent
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# counter and accumulator for progress
self.counter = 0;
self.progress = []
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, D, inputs, targets):
# calculate the output of the network
g_output = self.forward(inputs)
# pass onto Discriminator
d_output = D.forward(g_output)
# calculate error
loss = D.loss_function(d_output, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))- 생성기 능력 확인
G = Generator()
output = G.forward(generate_random(1))
img = output.detach().numpy().reshape(28, 28)
plt.imshow(img, interpolation='none', cmap='Blues')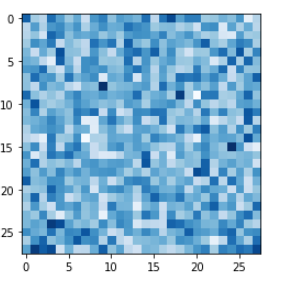
특이한 점은 현재 손실값으로 MSE loss를 사용하기 때문에
0.5의 제곱, 즉 0.25가 나오는 것이 생성기와 판별기의 밸런스가 맞는 상태라는 것이다.
학습 후 분석
%time
D = Discriminator()
G = Generator()
for label, image_data_tensor, target_tensor in mnist_dataset:
# 1단계, 참에 대한 판별기 훈련
D.train(image_data_tensor, torch.FloatTensor([1.0]))
# 2단계, 거짓에 대한 판별기 훈련
D.train(G.forward(generate_random(1)).detach(), torch.FloatTensor([0.0]))
# 3단계, 생성기 훈련
G.train(D, generate_random(1), torch.FloatTensor([1.0]))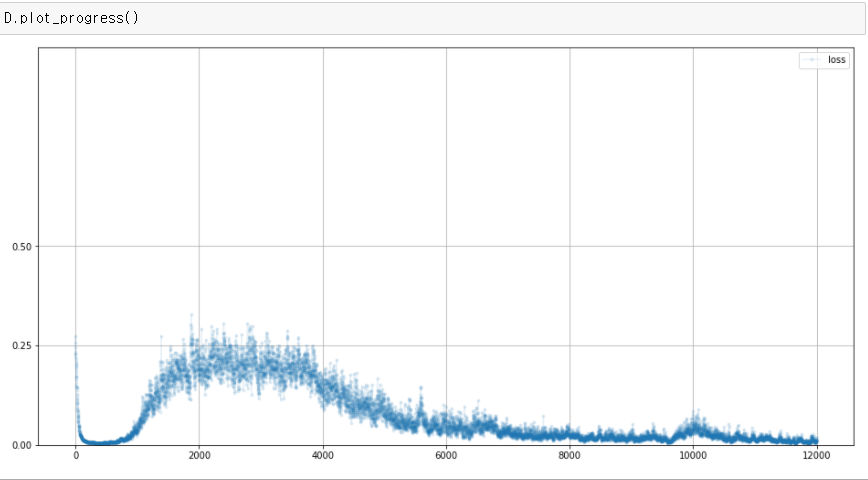
초기에는 판별기가 앞섰고, 점점 생성기의 성능이 올라가서 밸런스가 맞춰지다가, 결국 판별기가 성능이 우세한 상황이 계속 된다
f, axarr = plt.subplots(2,3, figsize=(16, 8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random(1))
img = output.detach().numpy().reshape(28, 28)
axarr[i, j].imshow(img, interpolation='none', cmap='Blues')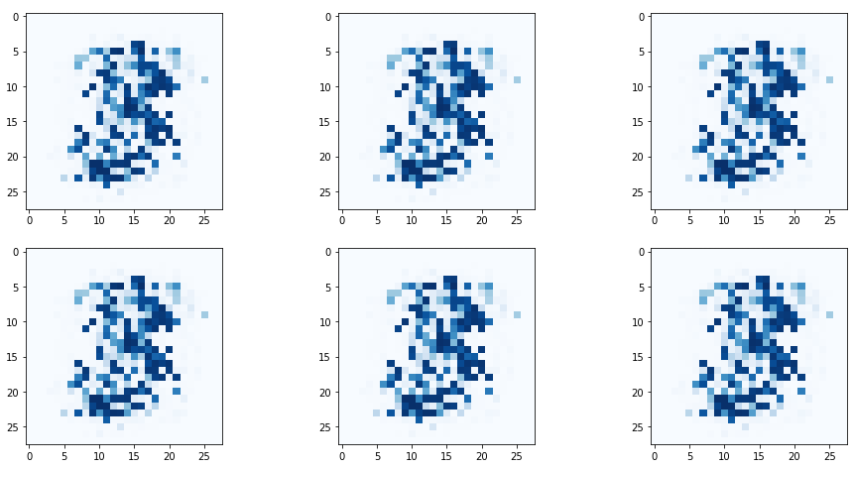
생성된 이미지는 어느정도 패턴이 있어보이면서도,
똑같은 형태를 가지고 있다(차이가 있다고 하더라도 식별 불가능할 정도)
이러한 현상을 모드 붕괴(mode collapse)라고 한다.
모드 붕괴가 일어나면 생성기는 오직 하나 혹은 극히 일부의 선택지만 만들어낸다. 2020년 강의 자료 기준 이 현상에 대해서는 계속 연구 및 발전 중이라고 한다.
이를 설명하는 그럴듯한 이론 중 하나는 생성시가 판별기보다 앞서나간 후에, 항상 판별기를 통과할 수 있는 꿀 지점을 발견해버리고 그것만 계속 사용하는 것이다.
어떻게보면 판별기를 더 자주 훈련시켜서 성능을 향상시키면 이러한 것을 완화할 수 있을 것 같지만 실제 효과는 없다고 한다.
훈련의 양보다는 질이 중요하기 때문이다.
제대로 판별기가 일을 하지 못 하면(질이 떨어지면) 좋은 피드백을 줄 수 없기 때문이다.
GAN 성능 강화
훈련 품질을 높여야 함은 앞에서 이해할 수 있었다(좋은 피드백을 받아야 한다)
훈련의 질을 높이기 위해서
- 손실 함수
- 분류 문제에서 MSEloss보다 BCE(이진 교차 엔트로피)가 더 효과가 좋다
- 이 때 이상적인 손실값은 0.25가 아니라 ln(2), 0.69 이다.
- 활성화 함수
- 기울기 소실에 대처할 수 있다
- 정규화
- 평균을 0으로 맞추고 분산을 제한하여 극단적인 값을 피할 수 있다
를 사용할 수 있다.
따라서 판별기와 생성기의 신경망을 조금 변경한다.
# 판별기
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 1),
nn.Sigmoid()
)
# 생성기
self.model = nn.Sequential(
nn.Linear(1, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 784),
nn.Sigmoid()
)- 또한 옵티마이저를 Adam을 사용한다.
# 판별기 and 생성기
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.0001)다시 생성되는 이미지를 확인해보면,
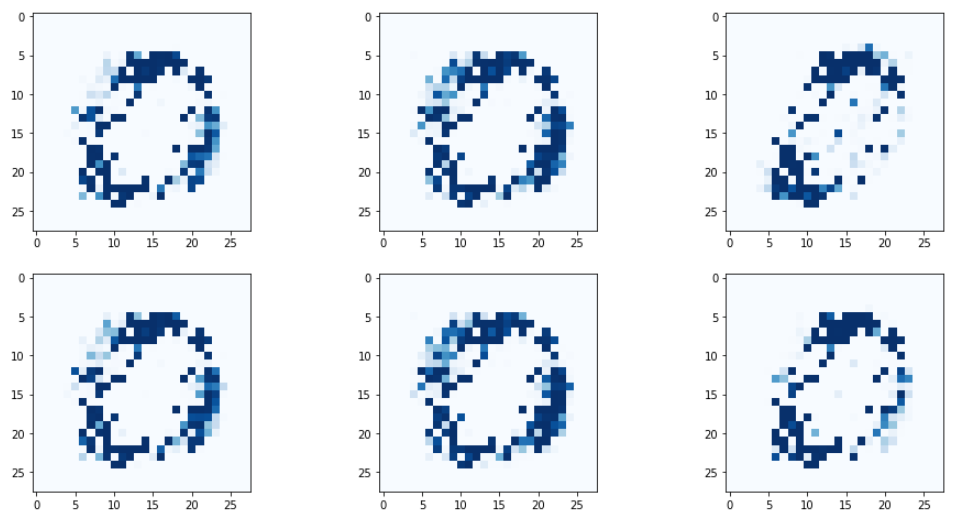
아까보다 좀 더 이미지간 차이가 유의미해지긴 했으나
역시 전체적으로 생성되는 패턴이 동일한 문제가 남아있다.
입력 seed 값을 늘려보는 것으로 개선이 가능하다.
기존 random한 숫자 1개를 입력받는 것에서
100개로 늘려보면
# 생성기
self.model = nn.Sequential(
nn.Linear(100, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 784),
nn.Sigmoid()
)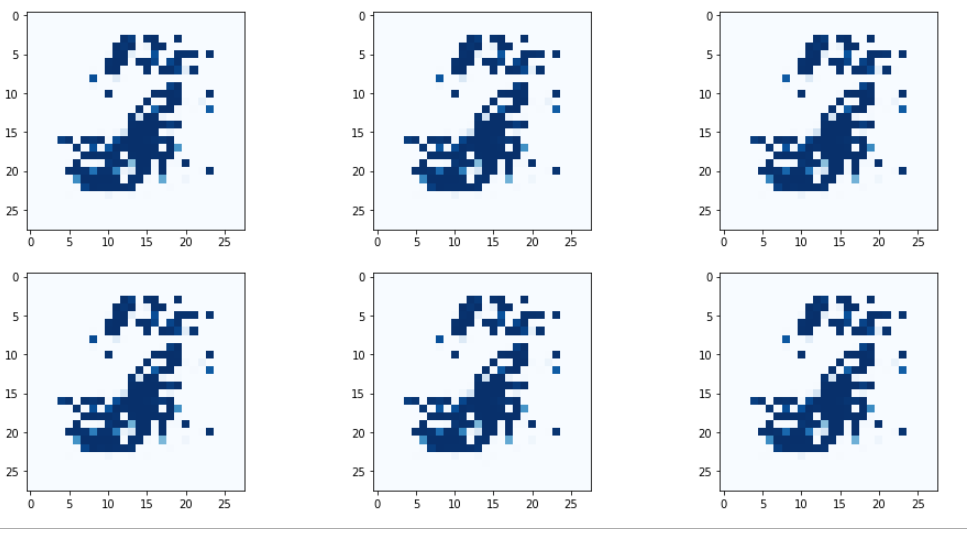
뭔가 좀 더 변화가 생기긴 했는데, 모드 붕괴가 해결되지는 않았다.
판별기와 생성기에 주는 시드값의 성질이 달라야된다고 한다.
판별기의 경우에는 실제 데이터에서 관찰되는 값이 0에서 1사이의 값에서 나오게 해야 한다.
생성기의 경우에는 0에서 1사이의 값일 필요가 없고, 신경망의 학습에서는 평균이 0이고 분산이 제한된, 정규화된 값들이 학습에 유리하다.
즉 생성기에서는 표준정규분포, 평균이 0이고 분산이 1인 분포에서 값을 뽑는게 유의미하다.
torch.rand = 0과 1 사이의 숫자를 균등하게 생성
torch.randn = 평균이 0이고 표준편차가 1인 가우시안 정규분포에 맞추어 숫자를 생성
여기까지 진행하면 모드 붕괴가 해결되어
시드값에 따라 다양한 종류의 숫자 형태가 생성되게 되고,
에포크를 늘림에 따라 품질이 좋아진다.
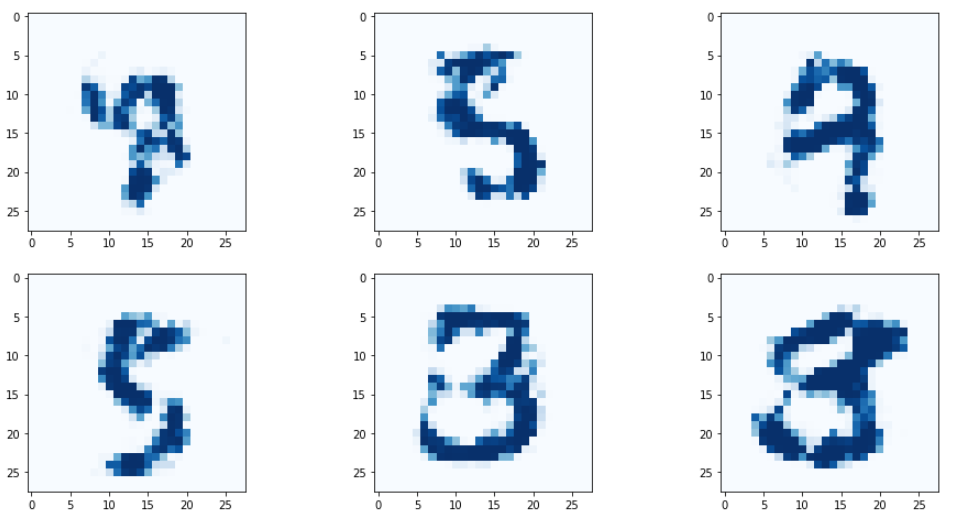
모드 붕괴는 문제 도메인에 따라 항상 해결되는 것이 아니고
고수들도 해결하지 못 하는 경우도 많다고 한다.
모드 붕괴를 해결하기 위해서
여러가지 조취를 취할줄 알아야겠다.
GAN과 SEED
그런데, seed에 의해 생성된 이미지에는 어떤 특성이 있다.
seed A와 seed B가 있을 때,
seed A에서부터 seed B까지의 값을 12단계로 나눠서 이미지를 생성하면
seed A에서 생성된 이미지에서, 점점 seed B에서 생성되는 이미지로 변화하는 모습을 볼 수 있다.
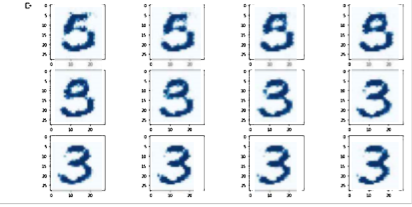
seed A와 seed B를 더하면,
seed A의 이미지와 seed B의 이미지를 더한 것과 같은 이미지가 생성된다.
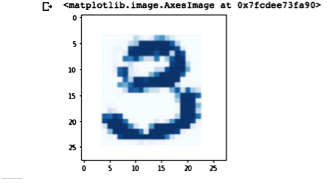
seed A에서 seed B를 빼면,
단순히 seed A의 이미지에서 seed B와 겹치는 부분이 제거되는 형태는 아니다
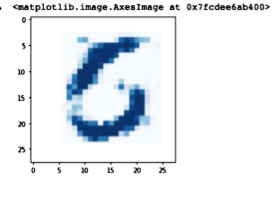
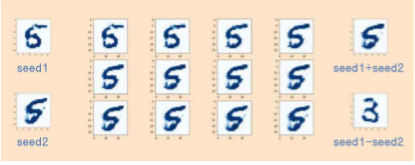
위 이미지의 결과에서, seed에 의해 생성되는 이미지는
생각보다 훨씬 복잡한 논리로 돌아가는 것을 시사한다.
(seed1 - seed2에서숫자 3이 나오는 모습)
