이번 시리즈는 고려대학교 산업경영공학부 강필성 교수님의 강의를 참고하였습니다. Business Analytics라는 과목이고, 데이터사이언스 분야의 내용이 잘 정리되어 있어 공부하기 좋을 것 같아 이번 시리즈를 연재하게 되었습니다. 부족한 점이 많겠지만 데이터사이언스 공부를 하는데 도움이 되었으면 합니다.
[Logistic Regression]
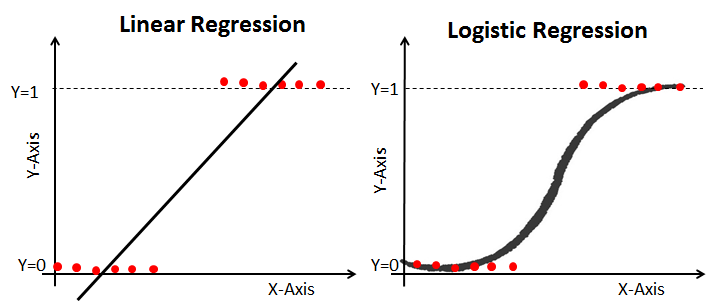
Logistic Regression은 연속형 변수를 종속변수로 갖는 회귀의 이름을 가지지만 특이하게도 범주형 변수를 종속변수로 가지는 회귀분석이다. 즉, 분류 문제를 해결하는 분석 방법이다.
만약 심장병 유무(유(1), 무(0))가 종속변수, 나이가 독립변수인 경우 회귀선을 그리게 되면 다음과 같은 데이터 포인트와 회귀선을 얻을 수 있다.
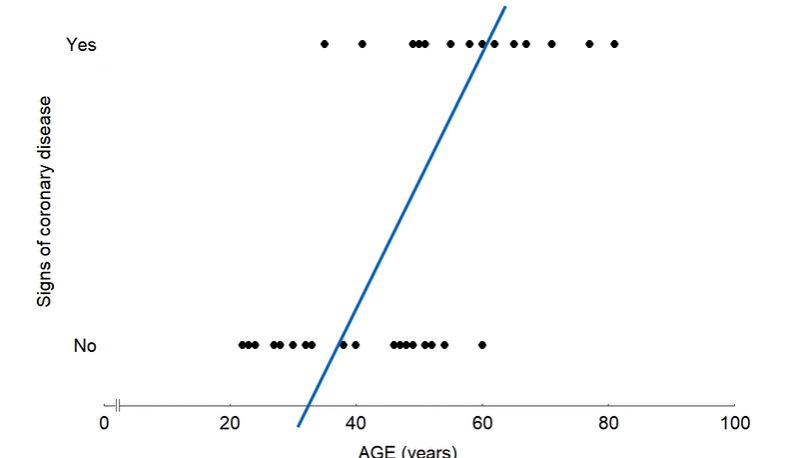
이렇게 얻어진 회귀선의 경우 데이터를 잘 설명하지 못할뿐더러
와 같은 회귀식에서 좌변의 범위는 인데 반해, 우변의 범위는 로 좌변과 우변의 범위가 달라지는 일이 발생한다.
즉, 회귀식의 좌변은 0과 1로 지정되는 반면, 우변은 범위에 제한이 없다.
그러므로 선형 회귀는 종속변수의 범위를 벗어난 부분까지 다루기 때문에 이는 0 또는 1의 값을 갖는 데이터를 잘 설명하기 어렵다. 이에 종속변수의 범위인 0과 1사이로 회귀선을 제한해주는 로지스틱 회귀분석이 등장하게 된다.
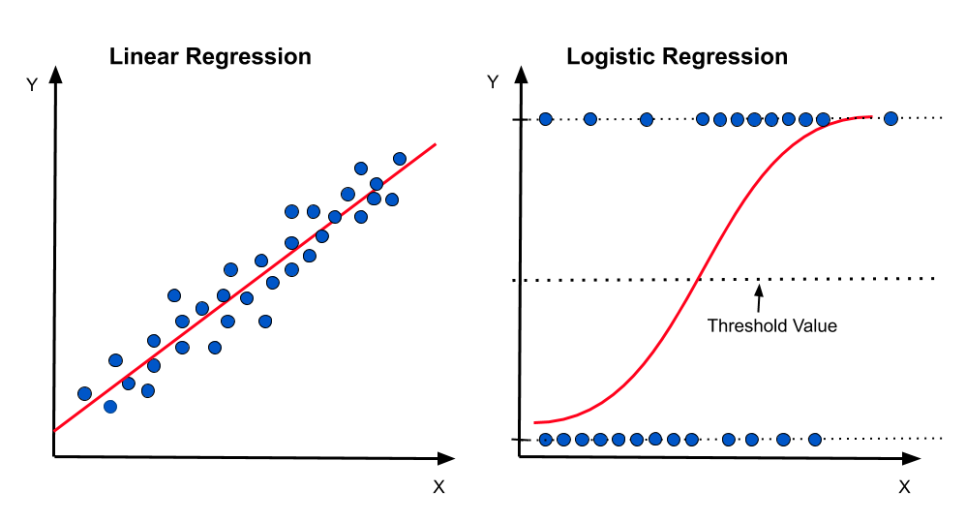
위와 같은 회귀식에서 우변은 어떤 독립변수가 중요한지, 설명력이 존재한다는 장점을 가지고 있기 때문에 우리는 좌변을 변형시켜 회귀식이 성립하도록 고쳐준다.
그럼 좌변을 어떻게 고치냐?
그 답이 바로 로지스틱 회귀식을 이해하기 위한 가장 중요한 포인트이다.
이를 위해 첫번째 알아야 할 개념은 odds(승산)이다.
이진 분류 문제에선 를 Class I에 속할 확률이라고 할 때 Odds는 위 식을 따른다.
Odds의 개념을 통해 0 또는 1의 값을 가졌던 좌변의 범위를 다음과 같이 확장할 수 있게 된다.
와 같이 0 또는 1의 값을 가지는 종속변수의 값 를 확률의 개념을 사용하여 로 0과 1사이의 값으로 만들어준다.
이후, Odds의 정의를 활용하여 를 사용함으로써 좌변의 범위를 다음과 같이 확장시킬 수 있다.
하지만 Odds만으로는 아직 양수의 범위로 제한이 있으며 Asymmetric(비대칭)하다. 이때 Odds에 Log를 씌워주게 되면 Odds의 단점을 해결해줄 수 있다.
위 식에서 만약 가 1이라면 로 가고, 가 0이라면 로 간다. 그러므로 를 모두 커버할 수 있다.
또한, Symmetric하다.
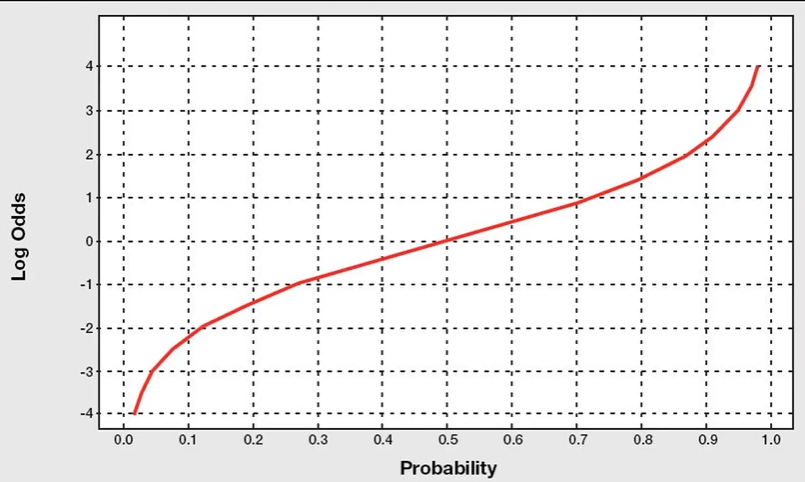
이처럼 일 때 0의 값을 가지며 이를 기준으로 대칭적인 모습을 보인다.
따라서 최종적으로 Logistic function의 회귀식은 다음과 같다.
그리고 이때 를 Logit이라고 한다.
좌변을 logit을 사용한다는 점에서 위 식을 사용하는 회귀분석을 로지스틱 회귀분석이라고 한다.
그러므로, 성공확률에 대한 로그승산을 선형식으로 추정하는 것이 바로 로지스틱 회귀분석이라고 할 수 있다.
또한 위 회귀식을 지수변환 후 정리하면 다음과 같은 식으로 나타낼 수 있다.
위 식을 다음과 같이 나타내기도 한다.
[Learning]
선형회귀의 회귀계수는 Closed form Solution이 존재한다고 이전 글에서 다뤘다.
(참고) https://velog.io/@withs-study/DSBA-ITS504-Multiple-Linear-Regression
하지만 로지스틱 회귀분석의 회귀계수는 Closed form Solution이 존재하지 않는다. 그래서 다른 방법을 사용해서 회귀계수를 최적화해야 한다. 그렇다면 왜 로지스틱 회귀분석에서 회귀계수는 Closed form Solution을 가지지 않을까?
MLE
이에 대한 답은 Maximum Likelihood Estimation(MLE) 개념을 통해 확인할 수 있다.
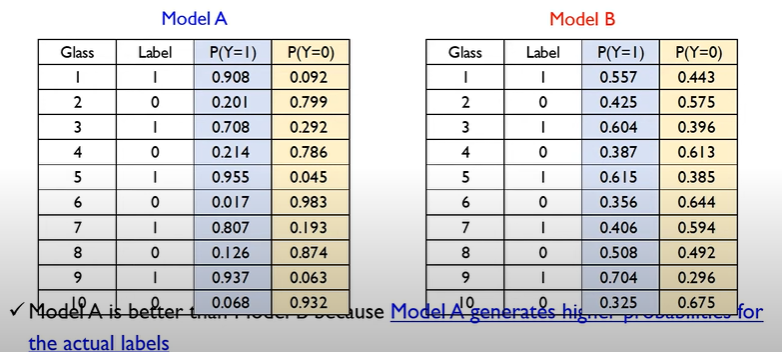
위 표처럼 로지스틱 회귀모델 A, B가 주어질 때, 실제 Label에 맞게 Class에 할당될 확률이 명확하게 나눠지는 A가 더 나은 모델임을 알 수 있다.
그리고 이는 Likelihood(우도)를 통해서 이론적으로 확인가능하다.
로지스틱 회귀에서 Likelihood function은 모델이 올바른 Class로 구분할 확률이다.
즉 모델 A에서 Glass 1의 우도는 0.908, Glass 2의 우도는 0.799, Glass 3의 우도는 0.708이라는 의미이다. 또한 만약 각 데이터가 Independent and Identically Distribution(iid)라면,
위 식이 성립하기 때문에 모델 자체의 우도는 각 Glass들의 우도의 곱으로 나타낼 수 있다.
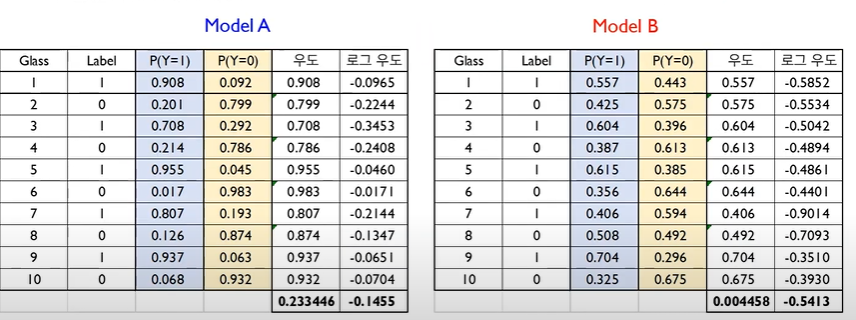
위 표처럼 모델 A, B 각각의 우도를 계산할 수 있다. 또한 모델 A의 우도가 모델 B의 우도보다 크기 때문에 모델 A의 성능이 더 뛰어나다고 할 수 있는 것이다.
하지만 로지스틱 회귀에선 우도가 확률로 주어지므로 0과 1 사이의 값을 가진다. 따라서 Dataset이 많아질수록 0에 가까워진다는 문제가 발생할 수 있다. 이에 로그 우도를 도입하여 이 문제를 해결할 수 있다.
그래서 위 식처럼 우도를 최대화, -log(우도)를 최소화하여 모델을 학습시키는 데 사용한다.
이를 Maximum likelihood estimation(MLE)라고 한다.
그럼 이제, MLE를 통해 Dataset의 우도를 최대화하는 회귀계수를 찾아보겠다.
로지스틱 회귀분석에서 각 데이터의 likelihood 값은 다음 식과 같다.
이때 는 0 또는 1이므로 다음과 같이 정리할 수 있다.
각 데이터는 iid라 하면, 각 모델에 대해 최종적인 Likelihood function은 각 데이터의 Likelihood 값을 모두 곱한 것과 같으므로 다음과 같이 정리된다.
위 식에 Log를 씌워서 정리하면 다음과 같이 구해진다.
하지만 이렇게 구해진 log(likelihood)는 와 비선형 관계이다. 따라서 explicit solution이 없다.
그래서 Gradient descent(경사하강법)와 같은 최적화 알고리즘을 통해 Trial & error로 수렴해가는 과정을 거쳐 최종적인 해를 찾아가야 한다.
Gradient Descent(경사하강법)
Gradient Descent(경사하강법)은 목적함수(Objective function)을 최소화하는 것을 목표로 한다.
경사하강법의 필요성
하지만 경사하강법에 대해 알아보기 전에 경사하강법의 필요성에 대해 먼저 다루겠다.
이 단원은 너무 좋은 참고 글이 있어서 그대로 인용했다.
(출처) 공돌이의 수학정리노트
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
"gradient descent는 함수의 최소값을 찾는 문제에서 활용된다.
함수의 최소, 최댓값을 찾으려면 “미분계수가 0인 지점을 찾으면 되지 않느냐?”라고 물을 수 있는데,
미분계수가 0인 지점을 찾는 방식이 아닌 gradient descent를 이용해 함수의 최소값을 찾는 주된 이유는
우리가 주로 실제 분석에서 보게 되는 함수들은 닫힌 형태(closed form)가 아니거나 함수의 형태가 복잡해 (가령, 비선형함수) 미분계수와 그 근을 계산하기 어려운 경우가 많고, 실제 미분계수를 계산하는 과정을 컴퓨터로 구현하는 것에 비해 gradient descent는 컴퓨터로 비교적 쉽게 구현할 수 있기 때문이다.
추가적으로, 데이터 양이 매우 큰 경우 gradient descent와 같은 iterative한 방법을 통해 해를 구하면 계산량 측면에서 더 효율적으로 해를 구할 수 있다."
따라서 우린 gradient descent 알고리즘을 통해 목적함수를 최소화함으로써 모델을 최적화하는 것이다.
Algorithm
그럼 이제 본격적으로 경사하강법의 알고리즘을 다루겠다.
경사하강법 알고리즘은 다음과 같다.
- initial weight(초기값)을 지정해준다.
- 미분가능한 cost function의 Gradient를 구해준다.
- Gradient가 최소가 되는 방향으로 분석가가 지정한 step size만큼 이동한다.
- 이동한 지점에서도 위 과정을 통해 최적점으로 이동할 때까지 1~3단계를 반복한다.
간단한 4가지 과정이지만 조금 더 자세히 살펴보자.
2번부터 보면, 첫째는 미분 가능한 Cost function이다.
딥러닝에서와 같이 일반적으로 사용되는 gradient-based optimization에서는 gradient를 계산하고자 미분을 계산하기 때문에 Cost function을 미분 가능한 함수를 사용하는 것이 중요하다.
이와 같은 이유로 연구에서는 직관적인 MAE를 회귀 평가지표로 쓰는게 아닌 미분이 가능한 MSE 내지, RMSE를 평가지표로 사용한다.
두번째는 Gradient이다.
Gradient는 이전 글인 "[선형대수 기초] Chapter 1 미분"에서 다뤘듯이
가 2개라면 다음과 같이 구해진다.
즉, 기울기의 벡터값?과 같은 모습이다.
세번째는 Step size이다.
딥러닝에서는 일명 학습률(learning rate)라고 한다.
만약 학습률이 너무 크다면 최적점으로 수렴하지 않고 발산해버리고, 학습률이 너무 작다면 최적점으로 수렴하는데 너무 오랜 기간이 걸릴 수 있다.
그렇기 때문에 trial & error를 통해 학습률을 조정해주는 것이 중요하다.
네번째는 최적점이다.
이차함수의 경우 최적점이 한 점이지만 다음과 같이 local minimum이 있을 수 있다.
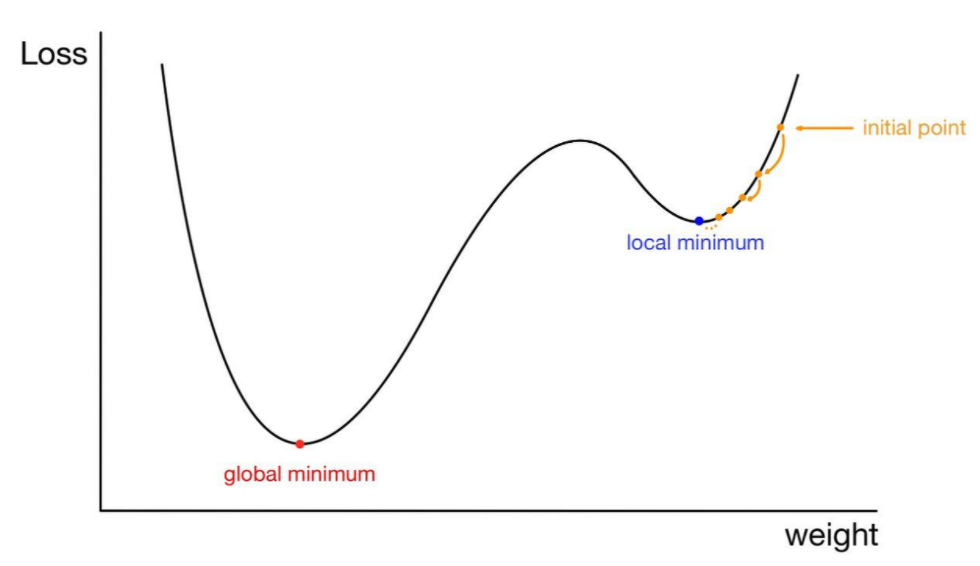
gradient descent 알고리즘에서 초기값이 랜덤하게 설정되기 때문에 어떤 경우에는 local minimum에 빠져서 수렴하는 경우가 발생할 수 있다.
따라서 이 역시도 trial & error를 통해 해결하는 방법 밖에 없다. 만약 시간이 난다면 이런 문제를 해결하기 위한 연구 논문들을 추가적으로 읽고 리뷰하겠다.
다시 돌아와서, 만약 이러한 trial & error를 통해 gradient descent를 한다면 gradient가 0이라면 그 점이 바로 최적점이고,
0이 아니라면 gradient의 역방향으로 가중치(로지스틱 회귀에선 )를 조정해주며 학습을 이어나간다.
글이 너무 길어진 관계로 gradient descent의 수학적인 부분과 로지스틱 회귀에서의 적용에 대한 단원부터는 다음 글에서 이어서 다뤄보겠다.
