참고자료
본 글은 공부중 궁금했던 부분이나 애매하게 알고 있다고 생각했던 부분을 정리한 글이다. 따라서 오류가 있을 수 있기 때문에 100%신뢰하는 것은 권장하지 않는다.
물론 훈수도 100% 인정한다.
1. Embedding? 그먼씹?
자연어 처리 분야(NLP)를 공부하다보면 마주는 단어가 있다.
Word-Embedding

우리가 사용하는 문장은 아래와 같은 구조를 갖고 있다.
Son is world-class player

우리가 눈으로 직접확인 할 수 있듯이 해당 단어는 여러개의 단어들로 구성되어 있다.
이를 Deeplearning 모델에 입력으로 넘겨주기 위해서는 컴퓨터가 이해할 수 있는 표현으로 변환시켜주어야한다.
컴퓨터가 해당 문장을 직접적으로 이해할 수 없기 때문이다.
컴퓨터가 이해할 수 있는표현은 무엇일까?
바로 수학적 표현이다
이러한 변환에는 대표적으로 희소표현, 밀집표현이 있다
1.1 희소표현(Sparse Representation)
다른 표현으로는 원-핫 벡터라는 말로 표현할 수 있다.
쉽게 말해서 Son 이란 단어의 인덱스의 값만 1이고 나머지의 인덱스에서는 0으로 표현이 되는 것이다.
이는 사전 에 모든 학습데이터의 단어들 종류를 알고 있어야한다.
이해를 돕기 위해서 Son, is, world-class, football, player 5개의 단어로 학습데이터가 구성되어 있다고 가정해보자
그러면 {Son : 0, is : 1, world-class : 2, football : 3, player : 4} 라는 사전을 만들 수 있다.
이를 활용해서 각 단어에 대한 희소표현으로 변환해보면
Son = [1, 0, 0, 0, 0]
is = [0, 1, 0, 0, 0]
world-class = [0, 0, 1, 0, 0]
등으로 표현을 할 수 있다.
가장 간단한 표현이라고 할 수 있다.
하지만 매우 눈치가 빠른 사람이라면 해당 표현의 문제점을 바로 알아차렸을 것이다.
바로 단어의 수가 증가하면 할 수록 표현을 위한 차원의 수가 증가한다는 것이다.
위와 같이 종류가 5개밖에 없는 경우에는 별로 상관이 없겠지만
요즘 LLM모델 같이 큰 모델을 학습하기 위해서는 대량의 데이터가 필요하고
해당 자연어 데이터의 경우 수십 또는 수백만개의 단어로 구성될 것이기 때문이다.
따라서 희소표현으로 단어를 표현하게 되면, 하나의 단어를 표현하는데 엄청난 차원을 사용하게되고 이는 차원 낭비, 불필요한 계산복잡도, 그리고 모델 성능에도 좋지않는 영향을 준다.
1.2 밀집표현(Dense Representation)
밀집표현은 벡터의 차원을 단어 집합 (사전)의 크기로 정하지 않는다.
앞에서 살펴본 희소표현의 경우 단어를 표현하기 위해서 단어의 집합(사전)의 크기로 했다는 것과 비교된다고 할 수 있다.
대신 사용자가 설정한 차원의 값으로 단어의 벡터 표현의 차원을 맞춘다.
희소 표현의 경우 0과 1로만 표현이 되었다면 밀집표현에서는 실수 값으로 표현이 된다.
앞에 예를 다시 가져와보자
Son = [1, 0, 0, 0, 0]
is = [0, 1, 0, 0, 0]
world-class = [0, 0, 1, 0, 0]
희소표현은 위와 같이 할 수 있었다. 현재 학습데이터에 단어가 5개만 존재했다고 가정을 했기 때문에 Son을 표현하는데 5개의 차원만 필요했다.
이제, 이를 확장해보자
만약 학습데이터에 단어가 10000개가 존재한다고 한다면
Son = [1, 0, 0, 0, 0 ....] 10000개의 차원으로 표현하여야한다.
따라서 이러한 부분때문에 희소 표현에서 차원 낭비가 발생하는 것이다.
이제 이를 밀집표현으로 변환해보자
만약 사용자가 256으로 차원을 설정했다고 해보자
그러면 Son = [0.2, 1.8, -2.1, 3.1 ....] => 256차원으로 표현된다.
이러한 표현을 밀집표현이라고 한다.
1.3 워드 임베딩(Word Embedding)
이러한 밀집표현으로 표현하는 방법을 워드 임베딩(word embedding)이라고한다.
임베딩 방법에는 LSA, Word2Vec, Glove 등 다양한 방법이 있다.
오늘 알아볼 nn.Embedding은 위 방법에는 포함되지 않는다.
대신에 단어를 -> 랜덤한 밀집 벡터로 변환한 이후, 이를 인공신경망 역전파시 가중치로 학습하는 방식으로 단어 벡터를 학습한다.
Word2Vec과 Glove 같은 방법을 활용하는 것은 pretrained 되어진 워드 임베딩을 활용하는 것이다.
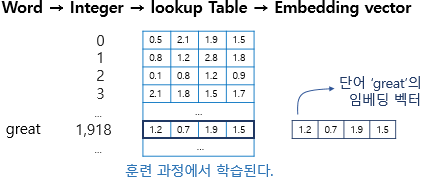
워드 임베딩은 위 사진에 나와있는 과정으로 진행된다.
단어 -> 이를 int로 변경 (원핫 인코딩의 인덱스와 같고, lookup table의 인덱스임) -> lookup table 구성 (랜덤한 백터로 변환, 이때 차원은 사용자가 지정한 차원) -> 모델 훈련과정에 가충치로 여겨지면 학습된다.
nn.Embedding을 한번 구현해보자
(물론, 정확히 똑같지는 않지만 동작 방식은 같다)
import torch
train_data = 'son is world-class football player'
# 단어 집합 (중복 제거)
word_set = set(train_data.split())
# 단어 집합의 각 단어에 고유한 정수 맵핑.
vocab = {word: i+2 for i, word in enumerate(word_set)}
vocab['<unk>'] = 0 # 없는 key (단어)
vocab['<pad>'] = 1 # 패딩
embedding_table = torch.randn(len(vocab), 4)
print(embedding_table)
sample = 'kim is world-class football defense player in Korea'.split()
idx = []
for word in sample:
try:
idx.append(vocab[word])
except KeyError:
idx.append(vocab['<unk>'])
idx = torch.LongTensor(idx)
print(idx)
lookup_result = embedding_table[idx, :]
print(lookup_result)
>>>
# embedding_table
tensor([[ 2.1414, -0.1481, -0.0503, -0.2888],
[ 0.4452, 0.5367, 0.5446, -1.1621],
[-0.5841, -0.2463, -0.1149, -0.9258],
[-1.1169, 0.5772, 0.2164, 0.1103],
[ 1.0133, -0.5053, 0.9519, -1.3847],
[ 0.4232, -1.8766, 0.5633, 1.6499],
[ 1.0312, -0.8288, -0.7583, -0.6039]])
#idx
tensor([0, 3, 4, 5, 0, 6, 0, 0])
#lookup_result
tensor([[ 2.1414, -0.1481, -0.0503, -0.2888],
[-1.1169, 0.5772, 0.2164, 0.1103],
[ 1.0133, -0.5053, 0.9519, -1.3847],
[ 0.4232, -1.8766, 0.5633, 1.6499],
[ 2.1414, -0.1481, -0.0503, -0.2888],
[ 1.0312, -0.8288, -0.7583, -0.6039],
[ 2.1414, -0.1481, -0.0503, -0.2888],
[ 2.1414, -0.1481, -0.0503, -0.2888]])
2. nn.Embedding 과 nn.Linear의 차이점
멀리서 보면 두 func의 기능은 차이가 없어보일 수 있다. (둘다 임의의 차원으로 변환시켜준다는 점에서)
하지만,
아주아주아주 x 100 쉽게 설명하자면
nn.Linear는 Dot product를 통해서 input x weight를 통해서 값을 변화시키고
(물론 연속되는 값에 대해서 input.matmul(weight.t())가 수행됨)
nn.Embedding은 범주형의 값에 대한 조회 테이블이다.
즉, nn.Embedding은 input을 값을 계산하는 수식의 값으로 사용하는 것이 아니라 , 만들어진 table에 조회에 사용한다.
따라서 nn.Embedding을 수행할때, 모든학습 데이터의 단어수를 알아야한다.
이를 통해서 사용자가 임의로 지정한 차원만큼 크기의 테이블이 만들어지고 (단어가 10000개이고 차원이 256이라면 -> 10000 x 256의 행렬이 Embedding 테이블임)
이를 input의 단어 인덱스로 조회하는 것이다.
따라서 인덱스의 크기 (1 < 2라는 의미)의 의미를 갖지는 않는다. 단순히 조회용이다.
물론 Embedding의 weight는 역전파에서 수정이 된다.
