Title : MOKA: Open-World Robotic Manipulation through
Mark-Based Visual Prompting(by Kuan Fang, Fangchen Liu, Pieter Abbeel and Sergey Levine, Robotics: Science and Systems, Delft, Netherlands, July 15-July 19, 2024)
1. Abstract
- Open-world에서 일반화를 위해 로봇 시스템은 물리적 세계와 사용자 명령을 깊이 이해하여 다양한 복잡한 작업을 해결할 수 있어야 함.
- 본 논문에서는 자유 형식의 Language Instructions로 Robot Manipulator 작업을 해결하기 위해 VLM을 활용한 MOKA(Making Open-World Keypoint Affordances)를 제안함
- MOKA의 핵심 접근 방식은 Affordance를 컴팩트한 포인트 기반 표현으로 변환하는 것. 즉, 관찰된 이미지에 대한 VLM의 prediction과 물리적 세계에서의 로봇 동작간의 연결을 형성
- VLM이 Zero-shot 및 few-shot 방식으로 추론할 수 있도록 하기 위해, 이미지에 마크(표시)를 주석으로 추가하는 시각적 프롬프팅 기법(visual prompting technique)를 제안함
- 이를 통해 Affordance 추론을 시각적 질문-응답 문제로 변환
- 본 연구에서는 MOKA의 성능을 다양한 테이블탑 Manipulator 작업에서 평가함(tool use, deformable body manipulation, object rearrangement)
2. Introduction
- 기존 접근 방식은 원시 센서 입력을 처리하여 Language 기반 환경에 대한 정보를 얻은 후, LLM을 사용하여 추론 및 계획하는 방식이었음
- 그러나 이러한 방법은 환경과 객체의 세부적인 visual details한 정보를 간과할 수 있음.
- 또한, 기존 접근 방식은 LLM이 유사한 작업에서 원하는 Prediction을 수행할 수 있도록 하는 컨텍스트 내 예제(in-context examples) 설계에 많은 노력이 필요함 -> 작업의 범위에 한계가 있음
- 본 논문에서는 자유 형식의 언어 지시(free-form language instrctions)에 따라 새로운 조작 작업을 해결하기 위해 VLM을 활용하여 로봇의 능력을 효과적으로 부여하는 방법을 연구함
- 핵심 아이디어는 VLM의 이미지 예측과 물리적 세계에서의 로봇 동작을 연결하는 Affordance 표현을 찾는 것
어포던스(Affordance): 어떠한 행동을 하도록 유도한다는 의미

- Fig.1 에서 볼 수 있듯이 MOKA는 open-world의 객체 및 작업에 대해 정의된 Keypoints 및 Waypoint의 집합으로 구성된 컴팩트한 Affordance 표현을 활용함.
- 본 논문의 Contribution은 다음과 같음
- VLM의 RGB이미지 Prediction과 로봇의 물리적 동작을 연결하는 Point기반 Affordance 표현
- Affordance 추론을 일련의 시각적 질문-응답 문제로 변환하는 마크 기반 시각적 프롬프팅 방법 제안
- 제안된 방법인 MOKA가 Zero-shot 및 few-shot방식으로 open-world manipulation 작업을 효과적으로 수행할 수 있음을 실험적으로 입증
3. Problem Statement
- MOKA의 목표는 로봇이 새로운(보지 못한) 물체와 목표를 포함하는 Manipulation task을 수행할 수 있도록 하는 것
- 각 작업은 자유 형식의 언어 지시 로 설명
- Fig.1 에서 보듯 로봇에게 "안경을 치운 후 테이블 위의 쓰레기를 닦아라" 라는 명령이 주어지면, "안경을 치우고"와 "테이블 위의 쓰레기를 닦아라" 라는 하위 task를 을 기반으로 분해한 후 순차적으로 해결
- 각 시간 단계 에서 로봇은 환경에서 관찰 를 recevied하고 이를 기반으로 행동 를 선택하여 로봇을 제어함.
- 관찰 :
- 카메라 센서가 캡쳐한 RGBD 이미지(Color + Depth)
- 로봇의 위치 및 상태 정보
- 행동 :
- 6-DOF Gripper 자세(x,y,z 위치 및 회전)
- Gripper 손가락 상태(열림/닫힘 등)
- VLM을 으로 표기, 이는 특정 순서로 제공되는 언어 및 시각 입력 목록을 처리하여 text responses를 생성할 수 있는 모델
- VLM의 응답은 다음과 같은 입력 프롬포트 설계를 통해 제어 할 수 있음
- 문제 설명
- 입력 및 출력 형식
- 컨텍스트 내 예제(in-context examples)
- 을 통해 도출된 응답은 로봇 동작을 표현하는 좌표(Point coordinates) 및 기타 속성으로 변환되어, 이후 로봇의 동작 계획 및 실행에 사용될 수 있음
4. Marking Open-world Keypoint Affordance
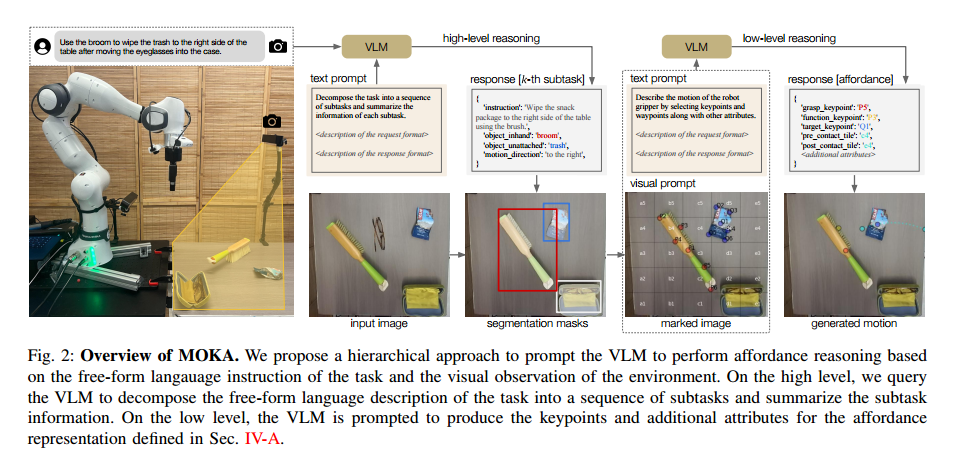
4.1 Point-based Affordance Representations
- VLM을 통해 Open-world Manipulation task를 해결하려면, VLM의 prediction결과와 로봇이 수행하는 동작을 연결하는 Interface가 필요함
- 저자들은 다양한 Manipulation task를 수행할 수 있는 Point-based Affordance 표현을 설계함, 작업별로 개별적으로 동작 primitives를 설계하는 대신, 통합된 Keypoint와 waypoint 세트를 사용해 동작을 지정함
- 이 Point들은 VLM에 의해 2D 이미지에서 Prediction되고, 이후 SE(3) Space(3D 위치와 회전)을 기준으로 변환됨. 이후, 이 포즈를 기반으로 로봇 동작의 trajectory가 생성됨.
- 로봇의 동작은 객체 중심(Object-centric)방식으로 지정된다.
- Fig.2 를 보면, 환경 내 물체와의 다양한 상호작용에 적용될 수 있어야 하며, 이는 두 가지 유형의 물체를 고려함
- 손에 들린 물체() - 예: 빗자루
- 로봇과 분리된 물체() - 예: 쓰레기
- 로봇의 동작은 두 단계로 구성됨
- 잡기 단계(grasping phase): 로봇이 를 환경에서 잡고 들기
- 조작 단계(manipulation phase): 로봇이 동작을 수행하며 를 도구로 사용하거나 직접적으로 와 접촉
Keypoint 및 Waypoint 정의와 사용
- grasping keypoint()는 로봇 그리퍼가 물체를 잡아야 하는 위치를 지정함. 작업에 가 포함되지 않는 경우, 잡기 단계는 생략됨
- manipulation 단계에서는 로봇의 그리퍼가 추가로 정의된 point set에 의해 지정된 동작 trajectory를 따름
- 기능 키포인트()는 manipulation 단계에서 가 와 접촉하는 위치를 지정함, 은 로봇 그리퍼 자체에 위치하며, 로봇과 사이에 직접 접촉이 이루어짐
- 목표 키포인트()는 manipulation 단계에서 이 접촉할 부분을 지정함
- 또한, Pre-contact Waypoint()와 Post-contact Waypoint()를 자유 공간에 정의하여, keypoint와 함께 manipulation 동작을 지정함
- manipulation 단계에서 로봇은 이 , , 를 순차적으로 연결하는 경로를 따르도록 움직임. 또한, 로봇 그리퍼는 잡기 단계에서는 잡기 방향(grasping orientation, ), Manipulation 단계에서는 조작 방향(Manipulation orientation, )을 따라야함.
- MOKA에서 이러한 Keypoint와 추가 속성을 Affordance 표현으로 요약하며, 이는 dictionary 형태로 구조화됨
4.2 Affordance Reasoning with Vision-Language Models
- 정의된 Affordance representation을 Prediction하기위해, VLM 을 사용함. 이 VLM은 Internet-scale data로 pre-train 되었으며, 일반적인 VQA(Visual Question Answering) 문제를 해결하는데 활용됨
- MOKA는 계층적 프롬프팅 프레임워크(hierarchical prompting framwork, Fig.2 참고)를 사용하여 Affordance 추론을 VLM이 해결할 수 있는 일련의 VQA 문제로 변환함.
- 계층적 프레임워크는 다음과 같은 입력을 사용함
- 자유 형식의 언어 지시
- 환경의 RGB 이미지 관찰
- MOKA는 초기 관찰 을 분석하고, VLM을 사용하여 작업 을 일련의 하위 작업(subtask)으로 분해함.
- 각 subtask에 대해 VLM은 다음 정보를 제공하도록 요청받음
- 하위 작업의 요약
- 손에 들고 있는 물체()및 환경 내의 물체()에 대한 설명
- 동작 설명(예: "왼쪽에서 오른쪽으로 이동")
High-level Reasoning
- 초기 관찰 과 언어 지시 이 주어졌을 때, VLM에 언어 프롬프트 를 제공하여 고수준 응답를 생성함
- 여기서 는 작업을 해결하기 위해 필요한 개의 subtasks 목록을 포함하는 문자열(String) 형태의 구조화된 정보를 포함함
- 저자들은 VLM이 을 dictionary 리스트 형태로 생성하도록 프롬프트를 설계하였음
- Fig.2에서 각 dictionary는 다음 정보를 포함함
- sub task의 언어 설명(예: "빗자루를 사용하여 간식 패키지를 테이블의 오른쪽으로 밀어라")
- 조작할 물체 정보
- 손에 들린 물체(): 빗자루
- 환경 내 물체(): 간식 패키지
- 동작 방식에 대한 설명(예: " 왼쪽에서 오른쪽으로")
- 이 high-level plan은 이후 VLM의 low-level reasoning을 통해 세부적인 affordance representation 을 생성하는데 사용됨
Low-level Reasoning
- VLM을 다시 프롬프트하여, 4.1에서 정의한 Affordance representation을 생성하도록 함
- : -번째 sub task에 해당하는 정보를 에서 추출한 것
- : 원시 시각 관찰 을 처리하는 함수
2D에서 3D 좌표 변환
- VLM이 2D 이미지에서 직접 3D 좌표를 예측하는 것은 어렵고 정의하기도 어려움
- 따라서 VLM이 이미지 내에서 2D 좌표를 출력하도록 한 후, 이를 다시 3D 공간으로 변환하는 방식을 사용함
- 세 가지 주요 Keypoint()
- 물체 표면에 정의됨
- RGB이미지와 카메라 파라미터를 이용하여, 2D 좌표의 깊이 값을 기반으로 3D 좌표를 계산
- 자유 공간 내 Waypoint
- VLM이 Text 응답으로 Prediction된 높이(Height)값을 기반으로 생성
- 세 가지 주요 Keypoint()
4.3 Mark-Based Visual Prompting
- Low-level reasoning을 수행하려면, VLM이 2D 이미지에서 Keypoint와 Waypoint를 생성하여 특정 sub task 동작을 실행 할 수 있어야 함.
- 하지만, VLM은 연속값 좌표를 직접 생성하는 것보다 다지선다형 문제(Multiple-choice questions)를 푸는 데 더 능숙함.
- 이에 따라, 저자들은 마크 기반 시각적 프롬프팅(mark-based visual prompting) 전략을 사용하여 VLM에서 원하는 출력을 추출하는 방법을 설명함
Mark-based visual promting 개요
- MOKA는 VLM의 추론 능력을 활용하여 Point기반 Affordance representation을 Prediction할 수 있도록 마크(mark, 시각적 프롬프트) 세트를 사용함
- 이 마크는 점(dots), 그리드(grids), 텍스트 표기(text notations)로 구성되며, 시각적 관찰 이미지 위에 주석(annotation)으로 추가됨
- VLM이 좌표를 직접 생성하는 것이 아니라, 후보 영역을 선택하는 방식으로 문제를 변환 즉, VLM이 주어진 후보 영역 중 하나를 선택하는 다지선다형 문제로 변환하여, 보다 tractable(처리하기 쉬운)한 방식으로 문제를 해결함
Keypoint 선택 방법
- Keypoint는 다음 두 가지 객체 위에서 정의됨
- 손에 들린 객체()
- 환경 내에서 분리된 객체()
- 이 객체들은 high-level reasoning에서 결정된 정보를 기반으로 선택됨
Waypoint 선택 방법
- 전체 작업 공간에서 직접 샘플링하는 대신, RGB 이미지 관찰을 그리드로 나누어 waypoint를 선택함
- 본 연구에서는 로 설정하여 그리드를 생성
- VLM은 pre-contact 및 post-contact keypoint가 위치해야 할 타일(tile)을 선택
- 선택된 타일 내부에서 uniform sampling을 통해 waypoint 좌표를 결정
4.4 Motion Generation with Predicted Affordances
- VLM에서 선택된 Keypoint와 waypoint를 얻은 후, 이를 실제 로봇에서 실행 가능한 동작으로 변환해야함
- 이를 위해 모든 Point를 2D 이미지에서 SE(3) 공간(3D 위치 및 방향 공간)으로 변환해야 함
- Keypoint 변환
- 객체(object)위에서 정의된 Keypoint인 경우, depth-aligend 깊이 이미지에서 해당 Point를 직접 가져와 로봇 좌표계로 변환할 수 있음
- Waypoint 변환
- 자유 공간에서 선택된 Waypoint의 경우, 해당 Point는 어떤 물체에도 부착되어 있지 않으므로, 3D 공간으로 역투영(deproject)하기 위해 높이(height)정보가 필요함
- 이를 해결하기 위해 VLM에 waypoint의 높이를 결정하도록 요청함
- Waypoint가 목표 지점과 같은 높이에 위치한느 경우(예: 밀기, Pushing)
- Waypoint가 목표 지점보다 높은 위치에 있는 경우(예: 물체 배치, Placing)
- 또한, VLM이 Manipulation 단계에서 손에 들린 물체()의 방향을 반환하도록 요청함
- 에서 으로 향하는 벡터를 이용하여 객체의 방향을 지정
- 로봇이 물체를 집는 동작(grasping)과 같은 물리적 고려 사항은 Pre-train된 VLM의 능력을 초과함
- 따라서, VLM의 예측과 기존 로봇의 grasping 알고리즘을 결합하여 사용
- VLM이 예측한 를 직접 사용하지 않고, 와 가장 가까운 위치 및 방향을 갖는 후보 그리퍼 위치를 선택하여 최적의 집기 위치를 결정하는 grasp sampler를 사용
4.5 Bootstrapping through Physical Interactions
-
MOKA의 성능을 향상시키기 위해 실제 세계에서의 물리적 상호작용을 활용하는 두 가지 방법을 고려
- VLM 정책을 실행하여 목표 작업을 수행하면서 로봇의 경험을 수집
-
in-context learning
- 성공적인 궤적(successful trajectories)을 VLM의 high-level 및 low-level resoning을 안내하는 in-context examples 로 활용함
- 2~3개의 in-context examples만으로도 VLM의 성능을 크게 향상시킬 수 있음
-
Policy Distillation
- MOKA는 실제 로봇 학습을 위한 demonstration datasets을 수집하는데 활용될 수 있음
- succesfully trajectory를 수집할 때, multi-view 이미지와 로봇의 자기수용감각(proprioception)상태를 기록
- 이후, 단순한 행동 복제(behavior cloning) 목표를 사용하여 visumotor 정책을 학습
5. Experiments
-
저자들은 MOKA의 성능을 다음과 같은 3가지 지표로 평가함
- MOKA가 보지못한 task에서, 이미지 기반으로 Affordance를 효과적으로 추론 할 수 있는가?
- MOKA의 Prediction을 Low-level motion으로 변환한 후, 제안된 task에 얼마나 잘 수행할 수 있는가?
- MOKA는 실제 환경에서의 실험을 통해 학습 할 수 있는가?(in-context learning or policy distillation)
-
먼저 MOKA의 성능을 baseline method와 비교하여 평가하며, 4가지 manipulation 작업을 대상으로 Zero-shot 및 in-context learning 환경에서 실험을 수행
-
이후, 정성적 평가(qualitative analysis) 및 강건성 평가(robustness analysis) 진행
-
각 평가 작업은 다양한 객체 상호작용(object interation) 및 도구 사용(tool-use) 시나리오로 진행
5.1 Experimental Setup
- 저자들은 MOKA를 다음 두 개의 baseline method와 비교하였음
- Code-as-policies(https://arxiv.org/pdf/2209.07753)
- 코드 예제를 프롬프트로 제공하여 Language Model이 생성한 프로그램을 로봇 시스템에서 실행하는 프레임워크
- VoxPoser(https://arxiv.org/pdf/2307.05973)
- LLM이 3D Voxel map을 생성하여 가치 함수(Value function)를 구축하는 방법
- Code-as-policies(https://arxiv.org/pdf/2209.07753)
- 저자들은 MOKA를 두 가지 설정에서 평가하였음
- MOKA Zero-shot: 별도의 학습 없이, 기존 모델을 바로 실행
- MOKA In-context: 기존의 성공 사례를 컨텍스트 내 학습으로 활용
- MOKA가 생성한 successful trajectories는 demonstration data로 활용 가능함
- 단순히 MOKA가 생성한 successful trajectories를 학습하여 모델을 훈련하면, VLM의 지식(Knowledge)을 학습된 정책(Policy)으로 distill 할 수 있음
- 저자들은 Octo라는 80만개(800K)의 다양한 로봇 trajectory data로 pre-train된 모델을 사용하였음
- Language Instructions 또는 goal images를 활용하여 작업을 정의하며, 현재 관찰 이미지(current observations)을 입력으로 받아 diffusion transformer-based) 정책 구조를 사용하여 동작을 생성
5.2 Quantitative Evaluation

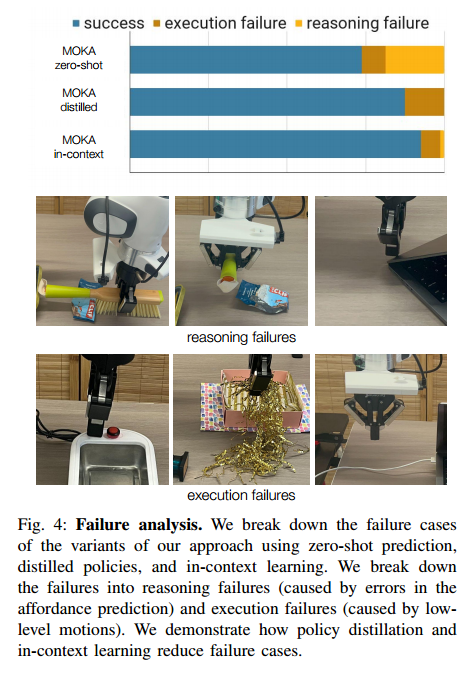
- 4가지 task에 대한 정량적 평가는 TABLE 1에 있음, 각 task에 대해, 10번의 실험 중 성공 횟수를 보여줌
Experiment result
- MOKA는 총 8개의 subtasks을 포함한 4개의 task에서 SOTA 성능을 달성
- in-context learning을 활용하면 일관된 성능 향상을 보임
- 대부분 작업에서 VoxPoser와 MOKA Zero-host은 유사한 성능을 보임
- GPT-4V의 잘못된 예측으로 인한 실패는 "추론 실패(reasoning failures)"로 분류
- 빗자루를 뒤집어서 잡는 문제
- 잘못된 목표 각도로 인해 빗자루를 잘못된 방향으로 향하게 한 문제
- 잘못된 target point로 인해 노트북 경첩을 눌러버리는 문제
- VLM이 올바른 예측을 했으나, 실행 단계에서 실패한 경우는 "실행 실패(execution failures)"로 분류
- 그리퍼가 버튼을 약간 빗나간 경우
- 그리퍼 손가락 사이로 케이블이 미끄러져 빠져나간 경우
- 결과적으로는 policy distillation와 in-context learning은 총 실패 횟수를 줄이는 데 기여
- policy distillation 모델을 사용한 경우, VLM이 더이상 Pipline의 일부가 아니므로, "추론 실패(reasoning failures)"가 발생하지 않음

6. Conclusion and Discussion
- MOKA는 VLM을 사용하여 로봇이 다양한 Manipulation task를 Zero-shot 및 few-show 방식으로 해결할 수 있도록하는 간단하면서도 효과적인 접근 방식 제안
- 현재의 VLM은 3D공간, contact physics, robotic control 분야에 대한 깊은 이해가 부족하여, MOKA의 성능을 제안하는 요인 중 하나.
- 향후 연구로는 위와 같은 한계를 극복

Robotics