Title : VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models (by Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, Li Fei-Fei, published at 7th Conference on Robot Learning (CoRL 2023), Atlanta, USA.
1. Abstract
- LLM은 로봇의 Motion Control에 있어서 우수한 성능을 입증함.
- 하지만, 대부분의 작업은 여전히 사전 정의된 motion primitives에 의존하여 환경과 상호작용을 수행하며, 이는 주요한 major bottleneck 으로 남아 있음.
- 본 논문에서는 명령 집합(open-set of instructions)과 객체 집합(open-set of objects)이 주어졌을 때, 다양한 Manipulation 작업을 수행하기 위한 로봇의 trajectories 즉, 6-DoF end-effector waypoint의 dense sequence를 생성하는 것을 목표로 함.
- LLM이 Language instructions을 기반으로 Affordance 및 constrains을 추론하는 데 뛰어나고 더 나아가, LLM을 VLM과 상호작용하여 3D Value Maps을 구성하여 에이전트의 Observation Space에 해당 지식을 연결시킬 수 있도록 함.
- 이렇게 구성된 Value Maps는 모델 기반 계획(model-based planning)프레임워크에서 사용되어, 사전 학습 없이(Zero-shot) closed loop에서 로봇 trajectories를 합성 할 수 있으며, 동적 방해(dynamic perturbations)에 대한 robustness를 제공
- 또한 제안된 프레임워크는 접촉이 많은 상호작용(contact-rich interactions)이 포함된 장면에서 동역학 모델을 효율적으로 학습함으로써 online experiences로부터 이점을 얻을 수 있음
- 제안된 모델이 시뮬레이션 환경과 실제 로봇 환경 모두에서 실험이 진행되었으며, 다양한 Manipulation 작업을 수행할 수 있는 능력을 입증함.
2. Introduction
- 본 연구에서는 추상적인 언어 명령(예: "set up the table")을 로봇의 행동으로 변환하는 문제를 다룸
- 기존 연구들은 어휘 분석(lexical analysis)을 활용하여 명령을 해석하는 방식을 다루었으나, 최근에는 언어 모델을 이용해 여러 단계의 Text Sequence로 분해하는 방법이 연구되고 있음
- 그러나 환경과 물리적으로 상호작용하려면, 기존 접근 방식들은 일반적으로 미리 정의된 Motion Primitive(즉, 로봇이 수행할 수 있는 기본적인 기술들)의 집합에 의존함.
- LLM은 언어를 기반으로 한 Affordance와 constraints을 추론하는데 매우 뛰어남. 또한, LLM의 코드 생성 능력을 활용하면 밀집된 3D Value Maps을 구성하여 로봇이 시각적 공간(Visual space)에서 이를 이해할 수 있도록 할 수 있음.
- 이를 위해, LLM은 CLIP 또는 Open-vocabulary detectors 등의 VLM과 상호작용 하여 시각적 정보를 처리하며, Numpy 등의 배열 연산을 활용하여 공간 데이터를 조작할 수 있음
- 예를 들어, "맨 위 서랍을 열고, 꽃병을 조심해라(Open the top drawer and watch out for the vase)"라는 명령을 주었을 때, LLM은 다음과 같이 추론할 수 있음
- 맨 위 서랍 손잡이를 잡아야함.
- 손잡이는 바깥쪽으로 당겨야 함.
- 로봇은 꽃병과 충돌하지 않도록 해야함.
- 이러한 추론을 바탕으로 LLM이 직접 파이썬 코드를 생성하여 관련된 객체나 부품의 Spatial-Geometric information을 획득할 수 있고, 3D Voxel을 조작하여 특정 위치에 reward나 cost를 할당할 수 있음(예를 들어, 손잡이 부분에는 높은 cost를 부여하고 꽃병 주변에는 낮은 cost를 부여하는 방식)
- 최종적으로 이렇게 구성된 Value maps는 motion planner의 object function으로 사용되며, 각 명령에 대한 추가적인 학습 없이(Zero-shot) 직접 로봇 trajectory를 생성 할 수 있음
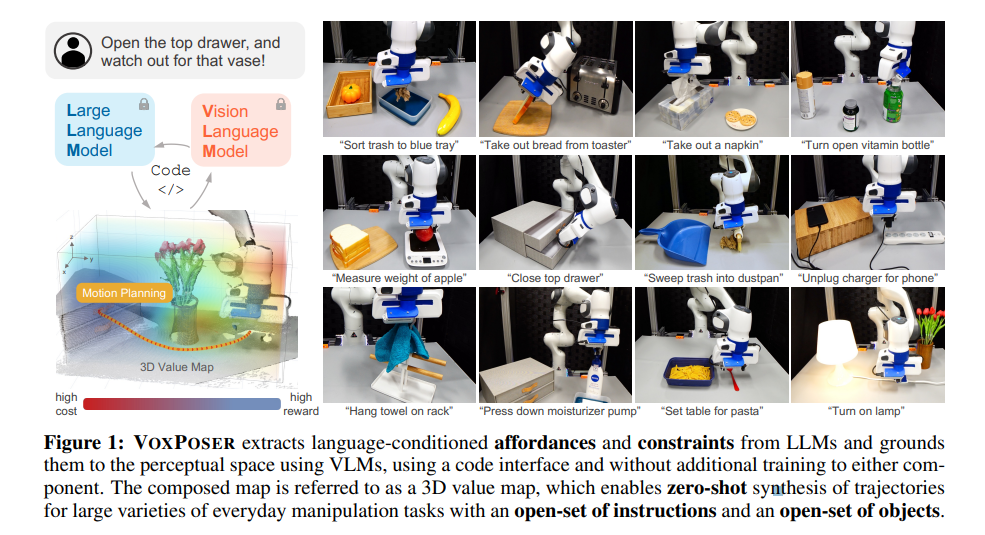
- 저자들은 이러한 접근 방식을 VoxPoser이라 명명하며, 이는 LLM이 추론한 Affordance와 Constraints을 VLM을 통해 3D Value Maps 형태로 변환하여, 로봇이 실제 환경에서 조작할 수 있도록 유도하는 기법
- VoxPoser는 언어 명령과 객체 명령에서 Zero-shot으로 다양한 일상 조작 작업을 수행할 수 있음을 입증하고, online interactions을 통해 제한적인 학습 데이터만으로도 접촉이 많은(contact-rich) 조작 환경에서 dynamics model을 효과적으로 학습할 수 있음을 보임
3. Method
3.1 Problem Formulation
-
free-form 언어 명령(예: "맨 위 서랍을 열어라")이 주어졋을 때, 이를 해결해야 하는 manipulation problem 을 고려해야함.
-
언어 명령 에 로봇의 trajectory를 생성하는 것은 매우 어려운 문제임. 왜냐하면 언어 명령이 임의적으로 긴 시계열(long-horizon)일 수도 있고, 명확하게 정의되지 않은(under-specified)경우도 있기 때문 -> 즉, 문맥적 이해가 필요함
-
본 논문에서는 이러한 문제를 개별적인 단계(하위 작업, sub-tasks) 로 나누어 접근함
-
예를 들어, "맨 위 서랍을 열어라"와 같은 명령을 subtask "서랍 손잡이를 잡아라", "서랍 을 앞으로 당겨라"와 같이 세부적인 task로 나눌 수 있음
-
이러한 분해(decomposition) 는 high-level planner(LLM 또는 search-based planner)에 의해 수행됨.
-
본 논문에서 다루는 문제는 각 조작 단계(manipulation task) 에 대해 로봇 의 motion trajectory 를 생성하는 것
-
robot trajectory는 dense end-effector waypoints의 시퀀스로 표현되며, Operational Space Controller에 의해 실행됨
-
각 Waypoint는 다음을 포함함
- 6-DoF end-effector pose
- end-effector velocity
- gripper action
-
주어진 번째 sub-task 에 대해, 최적화 문제는 다음과 같이 정의된다.
제약 조건 :
-
: 환경 상태(environment state)의 변화 과정
-
: 로봇 궤적
-
: 환경 상태 가 명령 를 얼마나 잘 수행하는지 평가하는 함수
-
: 제어 비용(control cost), 예를 들어 로봇이 총 제어 effort나 total time을 최소화하도록 유도
-
: 로봇의 동역학 및 운동학적 제약 조건
-
이러한 최적화 문제를 각 sub-task 에 대해 해결하면, 최종적으로 전체 명령 을 수행하는 로봇 trajectory 시퀀스를 얻을 수 있음.
3.2 Grounding Language Instruction via VoxPoser
자유 형식(free-form)의 언어 명령에 대해 를 계산하는 것은 매우 어려운 문제임
1. 언어가 표현할 수 있는 sementic space가 매우 방대함
2. 환경 상태 및 명령 이 명확하게 labeling된 로봇 데이터가 부족함
하지만, 본 연구에서는 대다수의 조작 작업을 로봇의 Observation Space에 존재하는 Voxel value map 으로 표현할 수 있는 critical observation을 제안함
이 value map은 장면 내의 관심 객체(entity of interest)(관심 객체: 로봇 end-effector, 조작할 물체 object, 물체의 특정 부분 object part)의 움직임을 유도하는 역할을 함

예를 들어, 위 그림처럼 맨 위 서랍을 열어라(open the top drawer)라는 명령이 주어지면
이 작업의 첫 번째 sub-task는 맨 위 서랍 손잡이를 잡아라(grasp the top drawer handle)임. 여기서 관심 객체(entity of interset)는 로봇의 end-effector가 됨. 따라서 Voxel value map은 서랍 손잡이에 대한 attraction을 반영해야 함.
즉, 로봇이 서랍 손잡이로 이동하도록 해당 영역의 값을 높게 설정(high reward)함.
이제, 추가 명령 꽃병을 조심해라(watch out for the vase)가 주어진다면, Voxel value map이 업데이트 되어 꽃병으로부터 밀어내는 힘(repulsion)을 반영해야 함. 즉, 꽃병 주변 영역의 값을 낮게 설정(Low cost)함으로써 로봇이 해당 영역을 피하도록 유도함.
본 연구에서는 관심 객체(entity of interest)를 , 그 궤적을 로 정의함.
이때 명령 에 대한 Voxel value map을 활용하여 를 근사할 수 있음.
- 는 관심 객체 가 번째 스텝에서 위치하는 (x,y,z) 좌표
- 즉, 관심 객체가 voxel map 상에서 지나가는 값을 누적하여 계산함. -> 이 값이 클수록 목표 작업을 더 잘 수행한다고 평가함.
VoxPoser의 역할: LLM을 활용한 3D Value map 구성
본 연구에서는 인터넷 규모의 데이터(Internet-scale data)로 pre-trained된 LLMs이 다음과 같은 능력을 갖추고 있음을 확인함.
- 관심 객체(entity of interset)를 식별할 수 있음
- 주어진 task를 반영하는 정확한 Value map을 생성할 수 있음
- Python 코드로 작성하여 이를 프로그램 형태로 표현할 수 있음
구체적으로 LLM이 명령을 주석(Comment)로 받은 경우, 다음과 같은 과정을 수행할 수 있음
- Perception APIs를 호출하여 VLM을 실행하고, 관련 객체의 spatial-geometrical 정보를 획득함.
- Numpy 연산을 생성하여 3D 배열을 조작함.
- 관련 위치에 정확한 값(Value)을 설정하여 Value map을 구성함.
이러한 방법을 VoxPoser이라 정의하며, 이는 다음과 같이 정의됨
= VoxPoser()
- = 시점 t에서의 RGB-D 관찰 데이터
- = 현재 명령
이후, Voxel map 가 희박(sparse)할 경우, 스무딩(smoothing) 연산을 적용하여 밀도를 높임 -> 이는 motion planner가 더 부드러운 궤적을 생성할 수 있도록 도움
Additional Trajectory Parametrization
기본적인 VoxPoser 공식에서는, LLMs이 Voxel Space에서 이산화된 좌표 을 실수 값 "비용(cost)"으로 매핑하는 함수 를 구성함. 이를 통해 위치(position) 기반 경로 계획을 최적화 할 수 있음
하지만, SE(3) 공간에서의 자세(pose)까지 고려하려면 추가적인 매개변수가 필요함.
- 회전 맵(Rotation Map)
- LLM을 활용하면 회전 정보(rotation)까지 포함하는 맵 SO(3)를 생성할 수 있음
- 예: end-effector가 손잡이의 지지면에 수직이 되도록 해야함.
- 그리퍼 맵(Gripper Map)
- LLM을 활용하면 Gripper(Open/Close)상태를 결정하는 맵 {0,1} 를 구성할 수 있음
- 예 : 손잡이를 잡으려면 그리퍼를 닫아야 한다.
- 속도 맵(Velocity Map)
- 특저 지점에서 목표 속도를 설정하는 속도 맵 를 구성할 수 있음.
이러한 추가적인 trajectory 매개변수화는 VoxPoser가 단순히 목표 위치만이 아니라, 자세(rotation), 손잡이 조작(gripper control), 속도 조절까지 최적화 할 수 있도록 확장함.
3.3 Zero-shot Trajectory Synthesis with VoxPoser
- task cost 를 구한 후,
위 수식의 전체 문제를 해결하여 Motion Trajectory를 계획할 수 있음
-
본 연구에서는 단순한 0차(zeroth-order) 최적화 방법을 사용하여 궤적을 생성함.
- 즉, 임의로 궤적을 샘플링하고, 해당 궤적을 제안된 목적 함수(Objective)에 따라 평가(score)하는 방식
-
이 최적화 과정은 모델 예측 제어(Model Predictive Control, MPC) 프레임워크 내에서 구현되며, 각 단계에서 현재 관찰 값(current observation)을 사용하여 궤적을 반복적으로 다시 계획(replan)함. 이렇게 하면 동적 방해(dynamic disturbances)가 발생하더라도 강건하게 궤적을 실행할 수 있음
-
그러나, VoxPoser는 관찰 공간(Observation Space)에서 dense rewards을 효과적으로 제공하므로, 매 단계마다 궤적을 다시 계획할 수 있어, 단순한 휴리스틱 기반 모델만으로도 본 연구에서 고려한 다양한 조작 작업을 성공적으로 수행할 수 있음이 확인됨.
-
또한, 일부 Value Map은 관심 객체(entity of interset)를 기준으로 정의되며, 이 관심 객체가 반드시 로봇일 필요는 없음.
-
따라서 동역학 모델(dynamics model)을 활용하여 로봇이 어떻게 움지기면 작업 비용(task cost)을 최소화할 수 있는지를 찾아야함. 즉, 로봇이 환경 간의 어떤 상호작용이 원하는 객체의 움직임을 유도하는지를 결정하는 과정이 필요함.
3.4 Efficient Dynamics Learning with Online Experiences
- VoxPoser는 온라인 경험(online experiences)을 통해 동역학 모델(dynamics model)을 효율적으로 학습함으로써 추가적인 이점을 얻음
- 요약하자면, 기존의 동역학 학습 방식의 문제점은 행동 샘플링(action sampling)이 무작위(random)로 이루어지기 때문에, 특정 작업(예: 문 열기)에 필요한 행동을 학습하는데 비효율적임
- 왜냐하면 문을 열려면 손잡이를 당겨야 하지만, 대부분의 무작위 샘플링은 다른 엉뚱한 행동을 시도할 가능성이 높다라는 이유때문
- VoxPoser는 LLM을 활용하여 "상식적으로 타당한" 초기 궤적 을 생성하여 완전히 무작위로 행동을 탐색하는 대신, Zero-shot 궤적 의 주변에서만 탐색(local exploration)하도록 설계하여 학습 효율을 높임
4. Experiments and Analysis
- LLMs and Prompting
- LLM이 자체적으로 생성한 코드를 재귀적으로 호출하는 방식
- OpenAI API의 GPT-4 사용
- 각 언어 모델 프로그램(Language Model Program, LMP)에는 5~20개의 example query 및 response를 포함하여 프롬프트 제공
- VLMs and Perception
- LLM이 object나 part를 질의(query)하면, 다음 절차를 수행하여 물체를 인식함
- OWL-ViT를 호출하여 물체의 Bounding Box를 검출
- segment Anything을 활용하여 해당 영역의 mask 생성
- video tracker XMEM을 사용하여 마스크를 지속적으로 추적
- RGB-D observation 와 함께 추적된 mask를 활용하여 object/part 의 포인트 클라우드 재구성
- Value Map Composition
- 다음과 같은 유형의 value map을 정의
- Affordance, avoidance, end-effector velocity, end-effector rotation, gripper action
- 각 value map 유형은 서로 다른 LMP를 사용
- LMP는 명령을 입력받아 shape(100,100,100,k)을 가지는 Voxel map을 출력
- 여기서 k값은 value map type에 따라 다름(affordance, avoidance는 k=1, rotation은 k=4)
- affordance map에는 Euclidean distance transform 적용, avoidance map은 Gaussian filter를 적용하여 smooth 변환
- 고수준 LMP 두 개를 추가로 정의하여 전체 프로세스 조정
- Planner : 사용자 명령 (예: 서랍을 열어라)을 입력받아 하위 작업(sub-task)을 생성
- Composer : 하위 작업 를 입력 받아 관련 value map LMP를 호출하여 구체적인 Language Parameterization을 적용
- 다음과 같은 유형의 value map을 정의
- Motion Planner
- Planner optimization에서 affordance 및 avoidance map만 고려
- 탐욕적 탐색(greedy search)을 사용하여 충돌을 피하면서도 end-effector의 3D 위치 시퀀스를 찾음
- Motion Planner의 cost map은 다음과 같이 정의됨
- affordance 및 avoidance amp을 Normalizaed한 후, affordance map에는 weight 2, avoidance map에는 weight 1을 곱하여 음수로 변환(negative of weighted sum)
- 최종적으로 생성된 6-DoF trajectory에서 첫 번째 waypoint를 실행한 후, 5Hz 주기로 새로운 trajectory를 다시 계획(preplan)함
- Dynamics model
- 모든 task에서 Known robot dynamics model을 사용
- end-effector가 waypoint를 따를 수 있도록 motion planning을 사용
- 대부분 task에서 관심 객체(entity of interset)는 로봇이므로, environment dynamics model은 사용되지 않음.
- 즉, 환경은 정적(static)이라 가정하고, 매 스텝마다 새로운 observation 값에 기반하여 trajectory을 replan함
4.1 VoxPoser for Everyday Manipulation Tasks

- 본 연구에서는 VoxPoser가 real world에서 zero-shot 방식으로 로봇 trajectory을 합성하여 일상적인 조작 작업을 수행할 수 있는지 검토
- 평가 방식
- 제안된 방법은 개방형 명령 집합(open-set of instructions)와 개방형 객체 집합(open-set of objects)에 대해 일반화가 가능함을 입증 (Fig 1)
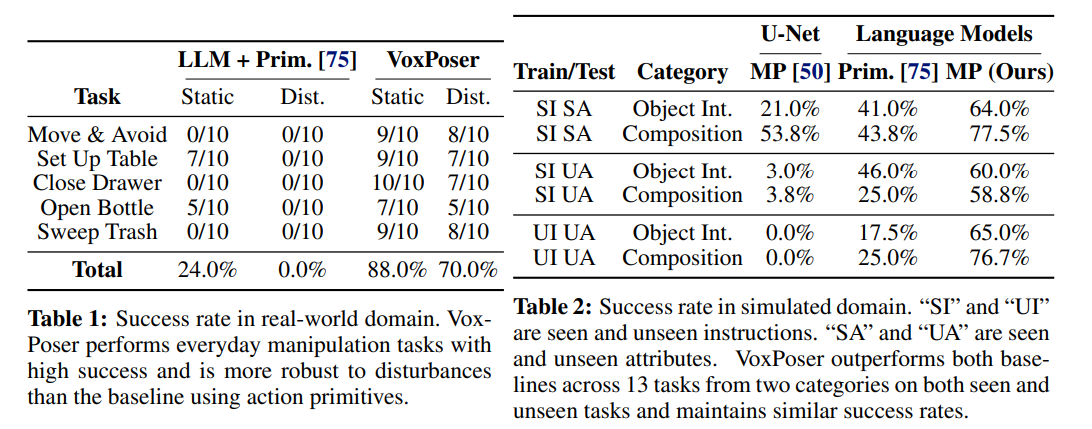
- 정량적 평가(quantitative evaluation)를 위해 5가지 task 선정(Table 1)
- 환경 실행(rollout) 및 가치 맵(value map) 시각화를 포함한 정성적 과(qualitative results)는 Fig 3
- 실험 결과
- VoxPoser는 일상 조작 작업에서 높은 평균 성공률(high average success rate)을 기록함
- 빠른 재계획(fast replanning) 능력 덕분에, 동적인 방해 요소(dynamics disturbances)에도 robust한 성능을 보임
- 예제 1: 움직이는 목표물(targets)이나 장애물(obstacle)이 있는 환경에서도 안정적으로 작동
- 예제 2: 서랍을 연 후, 로봇이 다시 서랍을 닫아도, VoxPoser는 다시 열도록 trajectory를 replan
- Code as Policies 방법과 비교
- 기존 연구 "code as policies"의 변형 모델과 비교 실험을 수행
- code as policies 방식:
- LLM을 사용하여 미리 정의된(simple primitives)의 매개변수를 조정하는 방식
- 예: 특정 위치로 이동(move to pose), 그리퍼 열기(open gripper) 등
- 비교 결과
- VoxPoser는 기존 접근 방식보다 성능이 좋음
- 기존 방식은 단순한 정책 로직을 연속적으로 연결(chaining sequential policy logic)하는 방식에 불과
- 반면 VoxPoser는 공간 정보를 조합하면서(spatial composition) 다른 제약 조건(constrains)도 동시에 고려하는 최적화 방식(joint optimization scheme)을 사용하기 때문에 성능이 좋음
4.2 Generalization to Unseen Instructions and Attributes
- VoxPoser가 보이지 않은(학습되지 않은, Unseen) 명령과 속성에 얼마나 일반화할 수 있는지를 평가하기 위해 시뮬레이션 환경에서 실험을 진행
- 객체 조작(Object Interactions)과 공간적 구성(Spatial Composition) 두 가지 범주로 나누어 실험
- 객체 조작: 컵을 지정된 위치로 이동시키기
- 공간적 구성 : 특정 객체 근처에서는 속도를 줄여 이동하기
- 비교 대상
- Code as Policies: LLM을 사용하여 사전에 정의된 프리미티브(pre-defined primitives)의 매개변수를 조정하는 방식
- U-net 기반 Cost map : U-net 모델을 사용하여 cost maps을 생성하고 이를 motion planning에 활용하는 방식 즉, VoxPoser와 달리 언어 모델이 직접 공간적 정보를 생성하는 것이 아니라, 학습된 모델을 통해 cost map을 생성
- 실험 결과(Table 2)
- VoxPoser가 모든 실험에서 뛰어난 일반화 성능을 보임
- VoxPoser는 LLM을 통해 직접 affordance와 constraints를 추론하고, 로봇의 value map을 생성하기 때문에 공간 정보를 기반으로 행동을 유도하기 때문
4.3 Efficient Dynamics Learning with Online Experiences
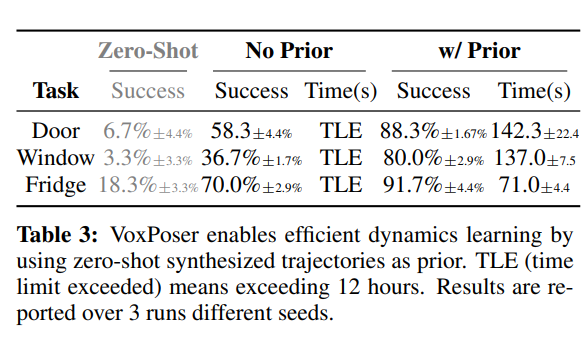
- VoxPoser를 이용해 zero-shot trajectory를 생성한 후 이 trajectory를 사전 정보로 사용하면 3분 미만의 online experience 효과적인 모델 학습이 가능, 하지만 사전 정보를 사용하지 않고 무작위 탐색을 하는 경우, 12시간 이상의 최대 제한 시간을 초과
- Door: 문 열기, Window: 창문 열기, Fridge: 냉장고 열기
4.4 Error Breakdown

- 각 구성 요소의 오류
- VoxPoser가 기존 방법들 보다 오류가 적어, 로봇 동작을 보다 더 정확히 생성할 수 있음
5. Conclusion, Limitations & Future Works
- LLM과 VLM을 활용하여 Affordance와 constraints을 추출하고, 이를 3D Spaital Space에 기반하여 로봇의 작업 task를 수행
- 뛰어난 일반화 제공
- 현재 motion planning은 end-effector trajectory만 고려하며, 팔 전체 plan은 고려하지 않음
- LLM 프롬프트를 수동으로 조정해야하므로, 효율적인 자동화 방법이 필요함
