Title : End-to-End Urban Driving by Imitating a Reinforcement Learning Coach (by Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu and Luc van Gool, published at ICCV 2021.)
논문 링크 : https://arxiv.org/pdf/2108.08265
github: https://github.com/zhejz/carla-roach?tab=readme-ov-file
1. Abstract
자율주행을 위한 End-to-End 접근 방식은 차가 길을 스스로 주행할 수 있도록 처음부터 끝까지 모든 것을 AI가 처리하는 방식임. 이런 방식은 보통 Human Expert의 시범, 즉 사람 운전자가 어떻게 운전하는지를 AI가 보고 배우는 방식으로 이루어짐
하지만 이런 방식은 문제가 있음, 사람은 실제로 운전을 잘하지만, AI가 효율적으로 학습하는 필요한 "dense on-Polcy Supervision"(밀도 높은 피드백) 을 제공하는 데는 적합하지 않다. 예를 들어, AI는 운전하면서 매 순간 피드백을 받아야 하지만, 사람이 그런 밀도 높은 정보를 제공하기는 어렵기 때문이다.
이를 해결하기위해 "automated experts"(자동화된 전문가) 를 도입하였음. 이 automated expertes는 사람이 아닌, 고급 정보(예: 주행 경로, 주변 차량의 정확한 위치 등)을 이용해서 스스로 훈련을 받음. 이 automated experts가 수천 번의 주행을 통해 학습하면서, AI에게 효율적으로 피드백을 줄 수 있는 능력을 갖추게 됨.
하지만 기존의 automated experts도 한계가 있음. 대부분 규칙 기반 시스템으로 주행 시뮬레이터에서 실제 환경과 같은 데이터를 얻을 수 있음에도 불구하고 최적의 성능을 내지 못하였음 이는 수작업으로 설계된 규칙들에 크게 의존했기 때문임 -> 주어진 상황에서 차가 언제 멈추고 언제 출발해야 하는지, 차선을 언제 어떻께 바꿔야 하는지 같은 규칙들이 미리 정의되어 있는데, 이 규칙들이 실제 주행 환경에서는 융통성이 떨어지는 경우가 있기때문
그렇기에 본 논문에서는 강화 학습을 기반으로 한 새로운 automated experts를 도입하면서 BEV라는 기술을 추가함. 이 방식은 수작업 규칙 대신, AI가 스스로 더 많은 정보를 바탕으로 결정을 내릴 수 있도록 해줌 -> 다시 말해, AI는 주어진 상황에서 사람처럼 구체적인 결정을 내리기보다는, 주위 환경 전체를 파악하고 스스로 학습하여 최적의 행동을 선택하게 됨.
이 방식으로 훈련된 AI는 시뮬레이터(CARLA)에서 기존의 주행 방식보다 더 높은 성능을 보임, 실제로 새로운 도시에 가거나 날씨가 변해도, 시뮬레이터에서 78%의 성공률을 기록하며 잘 적응함을 보임.
2. Introduction
Expert demonstrations는 end-to-end 자율주행 알고리즘에 필수적임.
- 모방 학습(Imitation Learning)방법 : Expert의 행동을 직접적으로 모방하는 방법
- 강화 학습(Reinforcement Learning)방법 : Expert demonstration을 사용하여 지도 학습을 통해 모델의 일부를 사전 훈련함으로써 샘플 효율성을 개선
Expert demonstration은 두가지 범주로 나눌수 있는데
- Off-Policy demonstration : 전문가가 직접 차량을 조종하고 에이전트는 이를 그대로 학습함. 여기서 에이전트는 전문가의 경로와 행동만 보고 따라하기 때문에, 만약 에이전트가 실수를 했을 때 그 실수로부터 배울 기회가 없음.
- On-Policy demonstration : 에이전트가 스스로 운전하고, 전문가가 그에 대한 피드백을 제공함. 이 경우 에이전트가 자신의 실수로부터 배울 수 있게 해주기 때문에 공변량 편향(convariate shift)을 완화하는데 필수적임. 하지만 문제는 human expert가 실시간으로 차량의 센서 데이터를 보고 매 순간 정확히 피드백을 주기 어렵기때문에 인간으로부터 충분한 데이터를 수집하는 것은 현실적으로 매우 어렵다.
이런 문제를 해결하기 위해 연구자들은 "automated experts"에 주목하였음. automated experts는 사람 대신 컴퓨터 시스템이 고급 센서와 데이터를 사용해 시연을 생성한다. 하지만 기존의 automated experts도 여전히 한계가 있음. 주로 수작업으로 만든 규칙에 의존했고, 시뮬레이터에서 주어지는 실제 정보조차 제대로 활용하지 못한 문제가 있음. 이런 이유로 기존 automated experts은 최적의 주행 성능을 내지 못하였음.
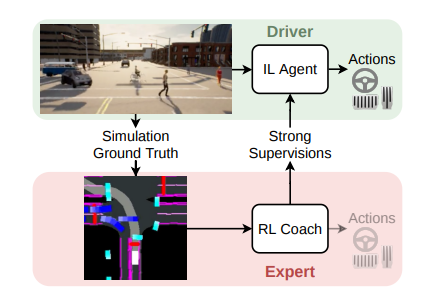
본 논문에서는 해결책으로 Roach와 BEV 기술을 도입하였음.
Roach는 새로운 강화 학습 기반 전문가로 BEV 이미지를 사용하여 차 주변의 도로 상황을 정확하게 파악함. 기존의 규칙에 의존하지 않고, 에이전트가 주변 정보를 직접 분석하고 학습할 수 있도록 돕는 역할을 함. 예를 들어, Roach는 마치 하늘에서 내려다보는 시점으로 주변 차량, 도로 표지판, 신호등, 보행자까지 모두 볼 수 있기에 에이전트는 어떤 규칙에 의존하지 않고 상황을 실시간으로 분석하고 더 나은 결정을 내릴 수 있음.
성과로는 시뮬레이터 CARLA에서 auto pilot을 능가하는 새로운 성능 상한선을 세웠고, 새로운 도시나 날씨에서도 잘 적응하여 NoCrash 벤치마크에서 78%의 성공률을 기록하였음 또한 CARLA leaderboard에서도 최첨단 성능을 달성하였음.
 |
|---|
| Roach: RL Coach |
3. Method
3.1 RL Coach
Roach는 세 가지 특징을 가지고 있음
1. 이전의 RL 에이전트와 달리, Roach는 다른 expert의 데이터에 의존하지 않음
2. rule-based 오토파일럿과 달리, Roach는 end-to-end가 가능하므로, 적은 엔지니어링 노력으로 새로운 시나리오에 일반화 할 수 있음.
3. 샘플 효율성(sample efficiency)이 높아 제안된 Input/Output representation과 exploration loss을 사용하여 Roach를 처음부터 훈련시켜 6개의 Leaderboard맵에서 최고의 전문가 성능을 달성하는데 single GPU에서 일주일도 걸리지 않음
Roach는 로 매개변수화된 Policy network 와 로 매개변수화된 Value network 로 구성되어 있다. Policy Network는 BEV 이미지 과 측정 벡터 을 행동 분포 로 매핑하고 마지막으로 Value Network는 Policy Network와 동일한 입력을 받아 스칼라 값을 추정함.
3.1.1 Input Representation
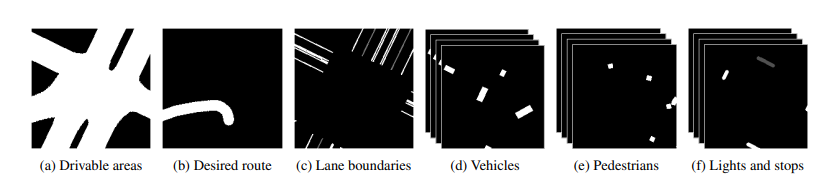
문제의 복잡성을 줄이기 위해 BEV semantic segmentation image인 를 사용하는데 여기서 BEV image는 실제 시뮬레이션 상태를 사용하여 렌더링되며, 크기의 Gray-scale 이미지로 구성된다.
 |
|---|
| The BEV representation used by Roach |
위 그림처럼 주행 가능한 영역(Drivable areas, (a))과 의도된 영역(Desired route, (b))이 렌더링되어 있고, 차선(Lane boundaries, (c))에서 실선은 흰색, 점선은 회색으로 렌더링 되어있다. 운송 수단(Vehicles, (d))는 자전거 타는 사람과 차량이 흰색 경계 상자로 렌더링된 K개의 Gray-Scale image로 이루어진 시간 순서의 시퀀스이다. 보행자(Pedestrians, (e))도 (d)와 동일하다. 교차로의 정지선과 정지 신호의 트리거 영역(Lights and Stops, (f))도 렌더링이 되어있는데 빨간 불과 정지 신호는 가장 밝은 색으로, 노란 불은 중간 밝기로, 녹색 불은 더 어두운 색으로 렌더링 된다. 정지 신호는 활성 상태 일때, 즉 자차가 그 근청 들어오면 렌더링 되고, 자차가 완전히 멈추면 사라진다. 여기서 BEV representation이 자차가 멈췄는지를 기억하게 함으로써, recurrent structure가 없는 Network architecture를 사용할수 있어 Roach의 모델 크기를 줄였다. 또한 Roach에 BEV에서 표현되지 않은 자차 상태를 포함하는 측정 벡터 을 입력으로 제공하는데 여기에는 조향, 가속, 브레이크, 기어, 가로 및 세로 속도와 같은 실제 측정값들이 포함되어있다.
3.1.2 Output Representation
CARLA의 action은 조향 , 가속 , 그리고 브레이크 이다. 문제의 복잡성을 줄이는 방법으로는 waypoint plans를 predicting하고 PID controller가 이를 추적하여 low-level action을 생성하는 것이다. 그러나 PID 제어기는 trajectory tracking에 신뢰할 수 없으며 과도한 매개변수 조정을 요구함. 이러한 문제를 해결하기 위해 Roach는 직접 행동 분포(directly action distributions)를 예측한다. 그 행동 공간은 조향과 가속을 위한 이며, 양의 가속은 스로틀(가속 페달), 음의 가속은 브레이크에 대응한다. action을 설명하기 위해 Roach는 베타 분포(Beta distribution) 을 사용한다. 여기서 는 각각 1과 0에 대한 집중도를 나타낸다.
3.1.3 Training
Roach는 Policy Network 와 Value Network 를 훈련시키기 위해 clipping이 적용된 Proximal Policy optimization(PPO) 를 사용한다. 두 네트워크를 업데이트하기 위해, CARLA에서 를 실행하여 궤적(trajectory)를 수집한다. trajectory = {}는 BEV 이미지인 , 측정 벡터 , 행동 , 보상 그리고 에피소드를 종료하는 event인 를 포함한다.
Value Network는 expected return을 회귀하도록 훈련되고 Policy Network는 다음과 같이 업데이트 된다.
는 Generalized Advantage Estimation(GAE)를 사용하여 추정된 클리핑된 정책 그레디언트 손실이다.
는 exploration을 하기위해 일반적으로 사용되는 최대 엔트로피 손실이다.
는 에이전트가 다양한 상황을 탐색하도록 돕는 데 사용된다. 운전 상황에서 에이전트가 특정 행동을 선택할 때, 이 가 에이전트의 행동 분포를 "균일한 분포"에 가깝게 만들도록 한다. 그러면 왜 균일 분포로 넣는지 궁금할것인데, 균일 분포로 넣는 이유는 에이전트가 학습할 때 특정 행동만 자주 하게 되면 다양한 상황에 적응하기 어려워지기 때문이다. 그래서 균일 분포로 행동 분포를 밀어넣어주게 되면 이는 다양한 행동을 시도해보기 때문에 에이전트가 여러 가지 행동을 골고루 시도하도록 하는것이다. 하지만 교통 규칙을 고려하면 모든 상황에서 무작위 행동을 하는 것은 좋지않다. 그래서, 교통 규칙을 지키는 선에서 더 의미 있는 방향으로 에이전트가 탐색하도록 하는 "탐색 손실 " 이라는 일반화된 형태를 도입한다.
탐색 손실는 에이전트가 특정 상황에서 실수를 반복하지 않도록 "조언"을 제공하는 역할을 한다. 예를 들어, 에이전트가 운전 중에 충돌하거나 신호를 무시하는 등의 문제가 발생하면, 탐색 손실을 통해 그런 실수를 줄이는 방향으로 행동을 조정하는 것이다.
- : 에이전트가 다양한 행동을 탐색하도록 만드는 역할을 함, 모든 상황에서 행동 분포를 균일하게 만들어 다양한 행동을 시도하게 함.
- : 특정 상황에서 더 적절한 행동을 하도록 조언을 제공하는 역할, 즉 에이전트가 에피소드의 마지막 단계에서 발생한 문제(예: 충돌, 신호무시)를 다음에 반복하지 않도록 함.
는 다음과 같이 정의된다. - : 지시 함수, 특정 조건이 만족하면 1이 되고, 그렇지 않으면 0이됨
- : 에피소드를 종료시키는 사건을 나타냄, 충돌, 신호 무시, 경로 이탈 등
- : KL-발산으로, 에이전트의 현재 행동 분포와 "탐색 사전분포" 사이의 차이를 측정
- : 특정 사건 z를 방지하기 위해 미리 정의된 행동 분포, 이 분포는 에이전트에게 어떻게 행동해야 할지 조언을 제공함.
적용 예를 들어보면, 에이전트가 충돌을 하거나 신호를 무시했을 경우, Roach는 그 상황에서 에이전트가 감속하도록 권장한다. 이를 위해 를 설정함
- 충돌이나 신호 무시가 발생했을 때: 에이전트가 감속하도록 = B(1, 2.5)를 사용, 이 분포는 에이전트가 가속을 줄이고 브레이크를 밟도록 유도함
- 차가 차단된 경우 : 차가 차단되어 움직이지 않을 때는 에이전트가 속도를 높여 빠져나가도록 = B(2.5,1)을 사용
- 경로 이탈의 경우 : 조향에 대해 균일한 분포 B(1,1)을 적용해 경로를 더 잘 유지할 수 있도록 함
3.1.4 Implementation Details
Network Architecture는 아래의 그림 (a)에 나와있음. Roach는 BEV를 encode하기 위해 6개의 conv Layer를 사용하고, measurement vector를 encode 하기 위해 2개의 Fully-Conntected Layer(FC)를 사용한다. 두 인코더의 출력은 Concat되어 또 다른 2개의 FC Layer에 의해 처리되어 latent feature인 을 생성하며, 이는 각 2개의 FC hidden Layer을 가진 value head와 policy head에 입력된다. Trajectory는 10 FPS로 6개의 CARLA 서버에서 수집되며, 각 서버는 6개의 LeaderBoard 맵 중 하나에 대응한다. 각 에피소드 시작 시, start location과 Goal location의 쌍이 무작위로 선택되며, path planning은 A* 알고리즘을 사용해 계산된다. 목표에 도달하면 새로운 무작위 목표가 선택되며, 따라서 Z에 있는 종료 조건 중 하나가 충족되지 않는 한 에피소드는 끝나지 않는다.
 |
|---|
| Roach and CILRS Network Architecture |
3.2 IL Agents Supervised by Roach
이 부분은 어떻게 Roach를 이용해 IL(모방 학습) 에이전트를 더 효과적으로 훈련시킬 수 있는지 설명하고 있다. 논문에서는 그 예로 DA-RB라는 모방 학습 에이전트를 사용하였으며, 이 에이전트는 카메라 이미지와 차량의 측정값을 입력으로 받아, 차량이 어떻게 움직여야 할지를 예측한다.
3.2.1 CILRS
CILRS의 Network Architecture는 위 그림(b)에서 볼 수 있다. CILRS는 두 가지 입력을 받는데, 1. 카메라 이미지인 를 처리하는 인식 모듈과 2. measurement vector 인 를 처리하는 측정 모듈이 있다. 각각의 모듈에서 나온 결과를 Concat하여 latent feature인 라는 것을 만든다. 이 은 차량이 주어진 상황에서 어떻게 움직여야 할지 판단하는 데 사용된다.
CILRS는 차량의 주행 지침에 따라 branch를 만든다. 각 branch는 차량의 연속적인 행동(조향, 가속 등)과 속도를 예측하는 데 사용된다. Loss function으로는 에이전트가 정확하게 행동하도록 학습시키기 위해 두 가지 Loss function을 사용한다.
- Action Loss(LA)
- 에이전트가 예측한 행동이 실제 expert의 행동과 얼마나 다른지 측정
- 여기서 는 expert의 행동(즉, 에이전트가 따라야 할 "정답"같은 것), 는 신경망이 예측한 행동
- Speed Prediction regularization(LS)
- 에이전트가 예측한 속도가 실제 측정된 속도와 얼마나 다른지 측정
- 여기서 는 실제 측정된 속도, 는 신경망이 예측한 속도이다.
3.2.2 Action Distribution Loss
Action Loss를 대체하기 위해 행동 분포에 기반한 새로운 Action Loss를 제안함. CILRS의 행동 헤드는 분포 매개변수를 예측하도록 수정되며, 손실은 Roach가 예측한 행동 분포 와 CIRLS 에이전트가 예측한 행동 분포 사이의 KL-divergence로 공식화 된다.
3.2.3 Feature Loss
IL 에이전트가 Roach로부터 운전 기술을 더 효과적으로 배울 수 있도록 도와주는 방법 중 하나이다.
- Latent Feature
- 에이전트가 실제 운전 상황에서 중요한 정보를 뽑아내어 기억하는 방식
- Roach는 주행에 필요한 중요한 정보를 이 Latent Feature에 담아놓는다. 그리고 이 Latent Feature을 활용해 차량의 행동을 결정한다.
- Feature Matching
- 두 AI 모델 간에 지식을 공유하는 방법으로 Roach의 Latent Feature을 IL 에이전트에게 전달하여 IL 에이전트가 Roach와 비슷한 방식으로 운전 상황을 이해하고 반응하도록 도와줌
Roach는 운전 상황을 BEV로 인식하기 때문에, 랜더링 방식이나 날씨의 변화에 영향을 덜 받음 Roach의 Latent Feature를 IL 에이전트에게 전달하면, IL 에이전트도 이런 변화에 적응할 수 있음
- 두 AI 모델 간에 지식을 공유하는 방법으로 Roach의 Latent Feature을 IL 에이전트에게 전달하여 IL 에이전트가 Roach와 비슷한 방식으로 운전 상황을 이해하고 반응하도록 도와줌
Feature Loss 의 수식은 다음과 같음
은 Roach의 latent feature, 은 IL 에이전트의 latent feature
3.2.4 Value Loss
Roach가 예측한 Value는 예상되는 미래의 reward를 추정하므로 주행과 관련된 정보를 포함하고 있다. 이는 상황이 얼마나 위험한지와 관련이 있기 때문이다. 예를 들어, 에이전트가 교차로에 접근할 때 앞으로 위험한 상황이 예상되면 그 상황의 "가치"는 낮아진다.
CILRS에 Value Head를 추가하고, 부수적인 작업으로 가치를 회귀함.
3.2.5 Implementation Details
구현은 DA-RB를 따르면서 ImageNet에서 Pre-train된 Resnet-34를 Image Encoder로 사용한다. 수평 시야각(FOV)이 100'인 광각 카메라 이미지인 를 주어졌을 때 1000차원의 특징을 생성한다. 이후 이미지와 measurement Encoder의 출력은 Concat되어 세 개의 FC Layer를 거쳐 을 생성하며, 이는 과 동일한 크기를 가짐
4. Experiments
4.1 Benchmarks
모든 평가는 CARLA 시뮬레이터에서 수행되었으며, NoCrash와 오프라인 LeaderBoard 벤치마크에서 Roach를 평가하였음. 각 벤치마크는 에이전트가 데이터를 수집할 수 있도록 허용된 훈련용 도시와 날씨를 지정하고, 새로운 도시와 날씨에서 에이전트를 평가한다.
NoCrash 벤치마크는 유럽의 단일 차선 도로와 T자 교차로로만 구성된 Town 1에서 Town2로의 Generalization을 고려한다. 이와 대조적으로 LeaderBoard 벤치마크는 고속도로, 미국식 교차로, 로터리, 정지 신호, 차선 변경 및 합류를 포함한 다양한 교통 상황을 다루는 6개의 지도에서 더 어려운 Generalization을 고려한다.
NoCrash 벤치마크를 따라, 네 가지 훈련용 날씨 유형에서 두 가지 새로운 날씨 유형으로의 일반화를 테스트함. 하지만 계산 자원을 절약하기 위해 네 가지 훈련용 날씨 유형 중 두 가지만 평가하였음. NoCrash 벤치마크에는 각 지도의 보행자와 차량 수를 정의하는 세 가지 수준의 교통 밀도가 있다. 본 논문의 저자들은 NoCrash-dense에 중점을 두고, 밀집 교통 환경에서 자주 나타나는 혼잡을 피하기 위해 regular와 dense traffic 사이의 새로운 수준인 NoCrash-busy를 도입함. 오프라인 LeaderBoard의 경우 각 지도의 교통 밀도는 혼잡 교통 설정과 비교할 수 있도록 조정됨.
4.2 Metrics
Roach에서는 NoCrash에서 제안된 Metrics인 성공률과 CARLA LeaderBoard에서 새롭게 도입한 지표인 주행 점수로 측정하였음.
- 성공률 : 충돌이나 차단 없이 완료된 경로의 비율
- 주행 점수 : 경로 완료율(주행 경로의 완료된 비율)과 위반 패널티(모든 위반 사항을 종합한 할인 계수)의 곱으로 정의
예를 들어, 에이전트가 하나의 경로에서 두 번의 빨간불을 위반했고, 빨간불 위반에 대한 패널티 계수가 0.7이라면, 위반 패널티는 가 된다. 성공률에 비해 주행 점수는 더 세분화된 지표로, 더 많은 종류의 위반 사항을 고려하며 장거리 경로를 평가하는 데 더 적합하다.
4.3 Performance of Experts
4.3.1 Sample Efficiency
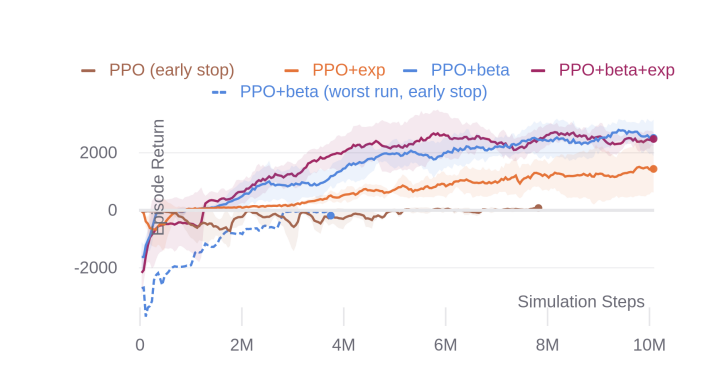
PPO의 샘플 효율성(Sample Efficiency)를 개선하기 위해, Roach는 카메라 이미지 대신 BEV를, 가우시안 분포 대신 베타 분포를, 그리고 엔트로피 손실에 더해 탐색 손실을 사용하도록 제안하였다.
실험에서는 BEV를 사용하는 이점은 명백하기 때문에, 베타 분포와 탐색 손실만을 제거하여 실험을 진행하였다. 아래 그림에서 볼 수 있듯이 가우시안 분포와 엔트로피 손실을 사용하는 기본 PPO는 정지 상태가 가장 보상이 큰 Local Minimun 에 빠진다. 탐색 손실을 활용하면, "PPO+exp"는 비교적 높은 분산과 낮은 샘플 효율성에도 불구하고 성공적으로 훈련 될 수 있다. 베타 분포는 상당한 도움이 되지만, 탐색 손실이 없으면 불충분한 탐색으로 인해 훈련이 일부 사례에서는 적절하지 않음.
-> Roach(PPO+exp+beta)는 베타 분포와 탐색 손실을 모두 사용하여 안정적이고, 샘플 효율적인 훈련을 보장
 |
|---|
| Learning Curves of RL experts |
4.3.2 Driving Performance
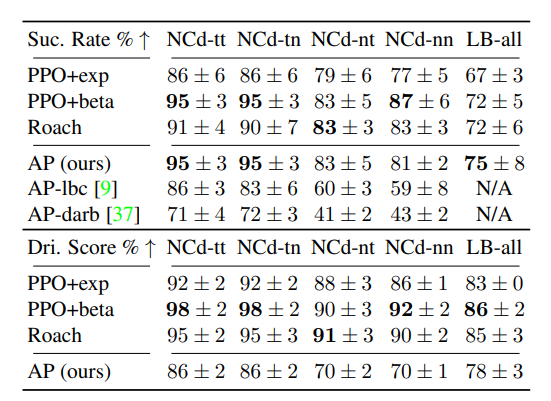
아래 표는 NoCrash-dense와 동적 날씨 및 혼잡한 교통 상황에서의 76개의 모든 LeaderBoard 경로에서 서로 다른 experts를 비교한 표이다. 논문에서 제시한 Roach를 통해 배운 AP(Auto Pilot)은 LBC와 DA-RB에서 사용된 AP보다 더 높은 성공률을 달성한 expert임.
일반적으로 RL Expert들이 AP보다 성공률과 더 높은 주행 점수를 달성하는데 이는 RL Expert들이 신호등을 잘 처리하기 때문.
 |
|---|
| Success rate and driving score of experts. NCd: NoCrash-Dense, tt: 훈련된 도시 및 날씨, tn: 훈련된 도시 및 새로운 날씨, nt: 새로운 도시 및 훈련된 날씨, nn: 새로운 도시 및 새로운 날씨, LB-all: dynamic한 날씨에서 76개의 LeaderBoard의 경로 |
4.3.3 Ablation
DA-RB+ 모델을 오토파일럿을 이용해 훈련하였을 때, 성능이 좋지 않음 특히, 새로운 날씨나 도시에서 성능이 떨어짐. 오토파일럿 대신 Roach를 도입하여 supervise 하면 성능이 훨씬 좋아짐. 오토파일럿보다 상황에 더 잘 대처하며, 행동 분포와 탐색 손실을 통해 더 안정적이고 효율적으로 훈련되어짐.
 |
|---|
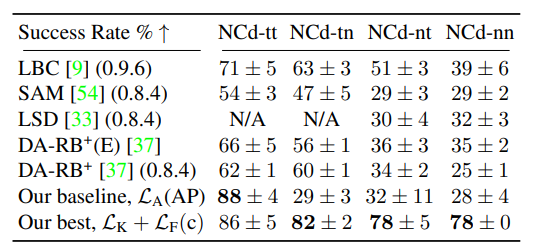
| Success rate of camera-based end-to-end IL agents on NoCrash-dense |
 |
|---|
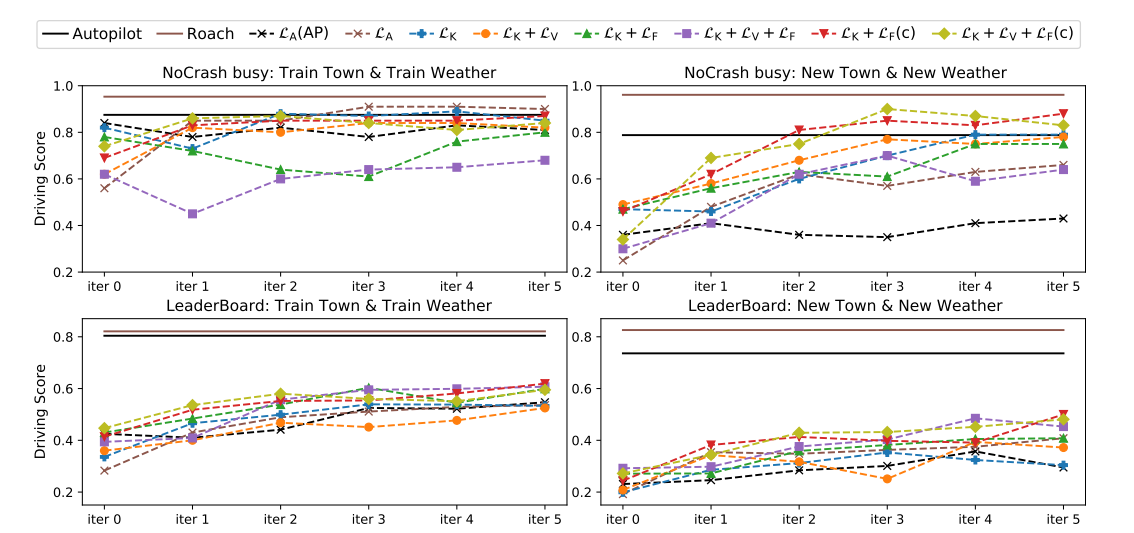
| Driving score of experts and IL agents |
4.3.4 Comparison with the SOTA
위 표를 보면 와 가장 성능이 좋은 에이전트 를 NoCrash-dense benchmark에서 최점단 기술과 비교함. 는 DA-RB+ 와 유사한 성능을 보이지만, 새로운 날씨로 일반화 성능이 떨어짐. 는 Roach의 supervise 덕분에 영향을 받지 않기 때문에 일반화가 잘되고 성능 도 향상
4.3.5 Performance and Infraction Analysis
아래 표는 새로운 도시와 날씨 환경에서 혼잡한 교통 상황의 NoCrash 벤치마크에서 세부적인 성능과 위반 분석을 제공함.
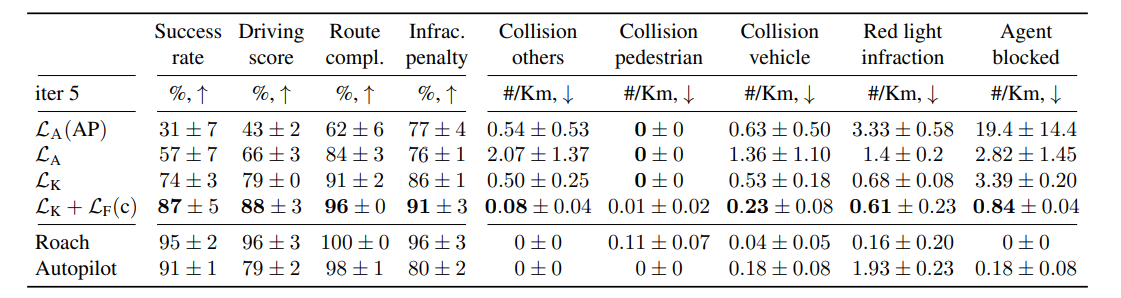 |
|---|
| Driving performance and infraction analysis of IL agents on NoCrash-busy, new town & new weather |
의 Agent blocked 수치가 매우 높은 이유는 비가 그친 후 물웅덩이에서의 반사 때문임. 이러한 문제점을 Roach를 모방함으로써 크게 안화되었음.
는 에이전트가 신호등을 더 잘 처리하여 88%의 expert 수준의 점수를 달성하였음.
5. Conclusion
본 논문에서는 Roach라는 RL Expert와 이 Expert를 모방하는 효과적인 방법을 제시하였음.
BEV representation, Beta distribution, exploration loss 을 사용하여 Roach는 CARLA에서 새로운 성능 상한을 설정하면서 높은 샘플 효율성을 보여주었음.
Roach를 실제 On-Policy 데이터에 적용하려면 BEV가 부분적으로 완화하는 사실감 외에도 여러 sim-to-real gaps 문제를 해결해야함.
