[논문 리뷰] Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
논문 리뷰
Title : Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation(IEEE Transactions on Intelligent Transportation Systems)
논문 링크 : https://ieeexplore.ieee.org/document/10254445
github: https://github.com/OscarHuangWind/DRL-Transformer-SimtoReal-Navigation.git
1. Abstract
- 기존의 Deep Reinforcement Learning(DRL)의 접근법은 낮은 데이터 효율성 문제를 갖고있음
- 그 이유중 하나로, 목표 정보는 인지 모듈과 분리되어 decision-making condition에 직접 도입되기 때문에 이로 인해 goal-irrelevant features of the scene representation 학습과정에서 방해 요소로 작용하기 때문이다.
- 이를 해결하기 위해 Goal State를 scene Encoder의 입력으로 고려하여 scene representation이 Goal Information과 결합되도록 유도하고 효율적으로 autonomous navigation을 실현하는 Goal-guided Transformer-enabled reinforcement learning(GTRL) 을 제안함
- 또한 구체적으로, vision transformer의 새로운 변형인 Goal-guided Transformer(GoT)를 제안하고, 데이터 효율성을 높이기 위해 export 사전 지식으로 Pre-train함
- 이후, GoT에서 Goal-Oriented scene representation을 입력으로 받아 결정 명령(decision commands)를 출력으로 생성하는 강화 학습 알고리즘을 구현
- 그 결과, scene representation이 goal-relevant features에 집중하도록 유도하여 DRL 학습 과정의 데이터 효율성을 크게 향상시켜 뛰어난 Navigation성능을 제공
- 시뮬레이션, 실제 시험 결과 모두에서 data efficiency, performance, robustness, generalization 모두 다른 SOTA 와 비교했을때 우수한 성능을 보임
2. Introduction
기존의 autonomous navigation methods는 SLAM기술로 맵에 대한 prior knowledge에 의존하는 방식으로 연구되었음. 하지만 이러한 접근법은 맵의 정확도에 크게 의존하고 unknown environment에서는 실패할 확률이 높음
따라서 laser scan 또는 visual image를 직접 활용하여 맵이 없는 Navigation strategy를 개발하는 것이 현재 unmanned ground vehicle(UGV)연구에서 큰 관심을 끌고있는 새로운 분야임
self-Attention 기반 Transformer가 CV분야에서 이미지 입력을 처리할 수 있는 변형인 Vision Transformer(ViT)가 제안되었고, 로봇 조작과 자율주행과 같은 다양한 분야에 적용되었음.
하지만, ViT기반 DRL 알고리즘을 UGV에 적용하여 맵이 없는 autonomous Navigation, 특히 Goal-Driven Task에 구현한 연구는 아직없음
이에따라 본 논문의 저자들은 Goal state를 scene encoder의 Input으로 넣어 scene representation과 Goal state를 결합시켜 효율적인 Navigation을 실현하기 위한 새로운 Goal-guided Transformer-enabled Reinforcement Learning(GTRL)을 제안함.
ViT에서 physical 과 visual state를 처리하기 위해 새로운 ViT변형인 Goal-guided Transformer(GoT)를 backbone으로 하며, 최종적인 decision-making system인 GoT-SAC를 구현했음
3. Method
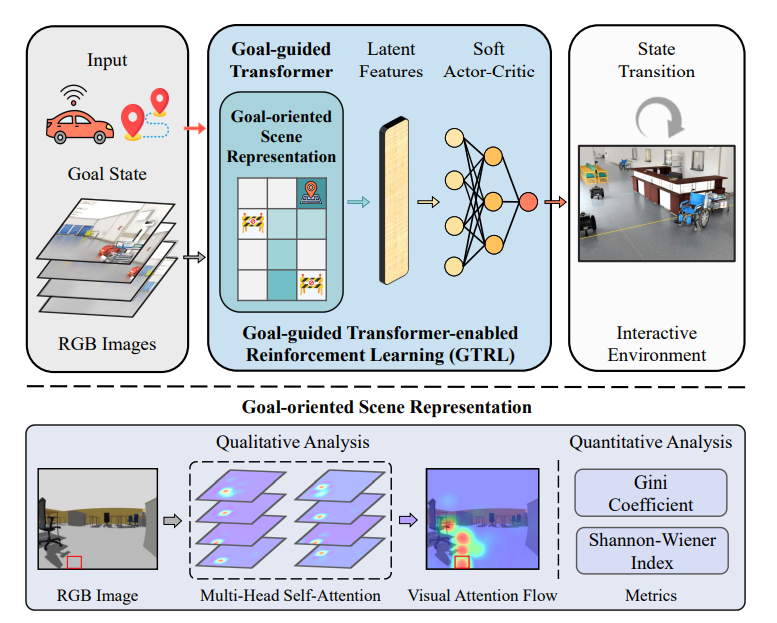 |
|---|
| 제안된 접근법의 전체 프레임워크 |
A. Framework
map이 없는 환경에서 Navigation을 하기 위해서는 DRL-based approach가 목표 정보를 이해하고 분석할 수 있어야함. 한가지 solution으로는 Parameterized된 목표 상태를 condition이 아닌 입력으로 처리하며, 이를 Original RGB-img 와 함께 입력으로 넣어 scene representation의 능력을 향상시키는 것이다.
논문의 저자는 Multi-Modal(Goal state, Visual State)입력을 연속적인 Sequence로 새로운 Transformer인 GoT를 통해 Goal-oriented scene representation을 학습한다.
이후 Goal-oriented scene representation의 feature가 추출되면, 이 feature를 SAC Model에 넣어 Environment와 상호작용함으로써 목표 위치에 접근하기 위한 decision policy를 학습하게 된다.
위 사진이 overall framwork이다. 순서를 보면
- 첫 번째, Goal State와 RGB image를 같은 차원으로 평탄화 시켜 GoT인코더에 입력함.
- 두 번째는 이러한 embedded된 patch들을 Mutli-Head Self-Attention(MSA)를 통해 Goal과 관련된 feature로 인코딩되어 이후의 SAC 모델로 들어감
- 마지막으로, GoT-SAC는 목표 관련 latent features에 따라 결정을 내리며, UGV는 GoT-SAC알고리즘이 내린 결정(명령)을 실제로 실행하여 환경에서의 상태 변화를 일으킨다, 그 후, 학습 과정이 끝나고 모델이 정책을 잘 학습하였는지 확인하기 위해 훈련된 모델을 정성적(Visual Attention Flow)및 정량적(Gini 계수 및 shannon-Wiener 지수)으로 평가한다.
- 정성적 분석(Qulitative Analysis)
- visual Attention Flow와 같은 시각화를 통해 모델이 장면의 어떤 부분에 주의를 기울였는지 분석
- 정량적 분석(Quantitative Analysis)
- Gini 계수와 Shannon-Wiener 지수와 같은 metrics를 사용해 모델의 성능을 수치적으로 평가
- 정성적 분석(Qulitative Analysis)
B. Goal-Guided Transformer
 |
|---|
| Goal-guided Transformer Architecture and Pre-train With Expert Priors |
- 입력(Input)
- 목표 정보(Goal Information)
- 물리적 상태(Physical State)로 표시되며, 목표의 위치와 같은 물리적 정보가 포함된다.
- 이 정보는 다층 퍼셉트론(MLP)을 통해 처리되며, "Goal Tokens"로 변환된다.
- 시각 상태(Visual State)
- 로봇의 카메라로부터 얻은 Original RGB 이미지.
- 이 이미지는 작은 이미지 패치(논문에서는 8x8 패치)로 분할됨, 각 패치는 "Input Tokens"로 변환
- 임베딩된 토큰(Embedded Tokens)
- "physical state token(Goal token)"과 "visual state token"이 결합되어 있는 상태
- 이 token들은 위치 임베딩(Position Embedding)을 통해 최종 입력으로 변환되며, GoT인코더로 전달됨
- 인지 시스템(Perception)
- GoT Encoder:
- Multi-Head Attention : 각 입력 토큰에 대해 여러 Attention을 사용하여 scene의 중요한 특징들을 추출
- Layer Normalization : 모델의 안정성을 높이기 위해 사용
- MLP : 중간 특징을 더욱 처리하여 Goal-relevant Latent feature 생성
- Goal-relevant Latent Features
- 이 단계에서 추출된 Goal-relevant feature은 이후의 decision system에 전달됨
- 의사 결정 시스템(Decision Making)
- 결정(Decision):
- GoT 인코더에서 추출된 Goal-relevant Latent feature을 기반으로, 로봇이 어떻게 행동할지 결정
- 이는 강화 학습(SAC 알고리즘)을 통해 학습
- 모방 학습(Imitation Learning)
- 인간 전문가(Human Expert)와 전문가 사전 지식(Expert priors)
- GoT모델은 Human Expert와 Expert Priors를 통해 모방 학습을 수행
- 이를 통해 모델이 처음부터 더 나은 시작점에서 학습을 시작할 수 있도록 도와줌(hot-start initialization)
전체적으로 보면 목표와 시각정보를 입력으로 받아, GoT 인코더를 통해 목표 관련 특징을 추출하고 이 특징을 바탕으로 의사 결정을 내리며, 모방 학습을 통해 학습된 모델을 더욱 강화시킴
C. Goal-Guided Transformer-Enabled Reinforcement Learning
GTRL의 입력은 두 가지 요소로 구성된다.(Original RGB images, Goal State)
카메라는 시야각이 220도인 fisheye 카메라로 160x120 original RGB image를 사용하며 가장 최근의 4프레임을 쌓아서 사용함.
또한, 추가적으로 더 robust하고 tranferable한 decision policy를 학습하기 위해 입력 이미지에 픽셀 수준의 노이즈를 증강시킴
 |
|---|
| original image와 Gaussian noise-augmentation이 적용된 이미지 비교 |
Goal state 의 경우 상대 거리(relative distance)와 heading error(방향 오차)를 포함하는 2차원 방식으로 제공된다.
구체적으로 goal state의 첫번째 차원은 normalized된 relative distance로 정의되며 다음과 같이 계산됨
여기서 는 UGV의 실시간 위치를 나타내고, 는 목표 지점의 임의의 위치를 나타내며, 는 유클리드 norm 연산을 의미하고, 는 상대 거리를[0,1]범위로 매핑하는 정규화 상수이다. 이에 따라 goal state의 두 번째 차원은 UGV의 방향과 Goal state를 가르키는 방향 벡터 간의 heading error로 연관시킴
여기서 는 UGV의 방향 각도를 나타낸다. 상대 거리와 마찬가지로, 방향 오차를 normalization한다.
GTRL은 로 나타나는 decision commands를 출력하며, 여기서 는 [0,1]범위의 선형 속도이고, 는 범위의 각속도이며, 이 명령들은 ROS을 통해 UGV로 전달된다. autonomous navigation의 목표는 Goal Position까지 도달하기 위한 목표 지향적인 결정(goal-driven decision)과 충돌 없는(collision-free) path planning을 구현하는 것이다. 그러므로 본 논문의 저자들은 GTRL의 converge efficiency를 높이기 위해 연속적인 보상과 희소 보상을 결합한 보상함수를 설계하였다.
구체적으로, 보상함수로는 다음과 같이 4가지 개별 요소로 구성된다.
- : 휴리스틱 보상
- : 행동 보상
- : 목표 지점에 도달한 보상
- : 충돌 패널티
휴리스틱 보상은 UGV가 goal position으로 이동하도록 motivate하게 설계되었다.
여기서 는 상수 가중치이다. 유사하게, 저자들은 UGV가 가능한 빨리 Goal Position에 접근하도록 하지만 최소한의 조향 작업으로 행동하도록 행동 보상을 설계하였다.
여기서 abs는 절댓값 연산이다. 마지막으로 두 가지 희소 보상, 즉 목표 도달 보상과 충돌 패널티는 다음과 같이 설계되었다.
여기서 는 목표 지점에 대한 일정한 여유를 나타낸다. 이후, 특정 시간 단계 t에서 GoT로부터 추출된 latent features인 를 고려하여 SAC알고리즘은 위에서 언급한 보상함수를 기반으로 decision policy 를 학습한다. 저자들은 SAC 알고리즘에서 널리 사용되는 일반적인 기술 중 하나는 over-estimation을 해결하는 이중 Q-네트워크(double Q-networks)를 많이 사용한다고 주장하며 GoT-SAC에도 이를 적용했다고 말한다.
GoT-SAC의 critic network의 parameter는 평균 벨만 제곱 오차(MBSE) Loss function을 최소화하여 업데이트 된다.
여기서 는 double target Q-networks로부터의 다음 단계의 상태-행동(state-action) 값을 나타내며 다음과 같이 계산된다.
여기서 는 optimal policy 와 state-action값 사이의 무작위성(stochastic)을 조정하는 temperature parameter이다. 이에 따라, actor-network는 soft state-action function을 최대화함으로써 parameter를 업데이트 한다.
 |
|---|
| GTRL 알고리즘 |
- 초기화 단계:
- GoT 네트워크 초기화 : pre-trained 된 parameter 를 사용하여 GoT네트워크 초기화
- actor-critic network parameter 초기화 : 와 를 초기화
- entropy parameter 초기화 :
- batch_size N , replay buffer 초기화 : 배치 크기 N과 리플레이 버퍼 D를 초기화하고, D를 빈 상태로 둔다.
- target parameter 할당 : 을 로 초기화
- episode 반복 루프:
- 환경 상태 초기화 : 로 환경 상태를 초기화
- 목표 상태 초기화 : 로 목표 상태를 초기화
- 단계 반복 루프:
- 목표 토큰 매핑: Gt= MLP(s{goal,t})로 목표 상태를 MLP를 사용하여 목표 토큰으로 변환
- 장면 표현 : 로 목표 관련 장면 표현을 추출한다.
- 액션 샘플링: 에서 액션 를 샘플링한다.
- 환경과 상호작용: 환경과 상호작용하여 보상 및 새로운 상태, 새로운 목표 상태 을 얻는다.
- transition 저장: transition(을 replay buffer D에 저장한다.
- critic update:
- 데이터 배치 샘플링: replay buffer D에서 배치 데이터를 샘플링한다.
- critic (MBSE) LOSS 계산: critic LOSS 계산
- critic network parameter update
- actor update:
- 데이터 배치 샘플링: replay buffer D에서 배치 데이터를 샘플링한다.
- actor LOSS 계산: actor LOSS계산
- actor network parameter update
- if automatic tune 활성화시:
- temperature parameter 업데이트- target network update:
- target network update: target network 을 로 업데이트 한다.
4. Experiments
A. Baseline Algorithms
저자는 trustworty한 end-to-end navigation을 위해 제안된 GTRL방법을 벤치마킹하기 위해 시뮬레이션과 실제 환경에서 qualitative, quantitative 성능을 비교하기 위해 최신 RL(Reinforcement Learning) 및 DIL(Deep Imitation Learning) 알고리즘을 기준으로 사용
- ConvNet-SAC: SOTA(state-Of-The-Art) off-policy DRL 알고리즘으로 ConvNet을 scene representation encoder로 사용함. 저자는 goal-conditional 방식으로 ConvNet에서 인코딩된 latent feature에 물리적인 goal-state를 augment 함
- ViT-SAC: ViT-DQN이라는 SOTA ViT기반 DRL알고리즘에서 파생되었으며, ViT-DINO를 DQN 인코더의 백본으로 사용한다. 원래의 중요한 특성을 잃지 않으면서, 본 논문에서는 DQN을 SAC로 교체하여 end-to-end navigation 에 맞게 조정하고, 이를 논문에서는 ViT-SAC라고 부름
- MultiModel CIL: SOTA Conditional IL(CIL)알고리즘으로, 학습과정에서 인간의 명령 또는 목표 벡터를 조건으로 고려한다. 본 논문에서는 Goal-driven autonomous navigation 작업에 맞추기 위해 원본 연구에서 제안된 두 가지 아키텍처 중 명령 입력(command-input)방법을 선택함
- MoveBasd Planner: goal-driven autonomous navigation을 위해 UGV에서 널리 사용되는 전통적인 Planner이다. 본 논문에서는 공정성을 위해, Global map을 쓰지않고, 실시간 장애물 회피를 위해 8x8 Local Map을 사용한다.
B. Export Priors
본 논문에서는 GoT를 pre-train하기위해 인간 참가자들에게 goal-driven navigation 작업을 수행하도록 요청하였고 image state-action 쌍 형식으로 데이터를 수집하였음.
그 결과, 총 200개의 trajectory를 얻었고 이는 17,215개의 state-action 쌍으로 구성되어있음.
이러한 데이터셋을 train dataset과 validation dataset 8:2 비율로 나누어 DIL 과정에 사용하였고 learning process는 최대 반복 횟수 한도에 도달하거나 validation loss가 증가하기 시작할때 종료됨 -> 가장 낮은 validation loss에 의해 결정된 최적의 모델이 이후의 decision-making learning process에 사용됨.
train dataset : 13,372
val dataset : 3,443
C. Simulation Assessment
시뮬레이션 환경은 Intel Core i7-10700 CPU, 64GB RAM, NVIDIA GTX 1660 SUPER Graphic Card가 장착된 컴퓨터에서 진행되었으며, Gazebo를 사용하여 map을 만들었음.
각 알고리즘을 500 에피소드동안 훈련하며, 각 에피소드는 최대 200 Step으로 설정되었음.
에피소드는 목표 위치에 도달하거나, 충돌이 발생, UGV가 최대 Step 수를 초과할때 종료되었음. DRL 기반 정책을 더 generalize하고, sim-to-real transferability를 달성하기 위해, RGB 이미지에 픽셀 수준의 Gaussian Noise를 Augment하였고, 각 에피소드마다 initial location과 goal position을 변경함. 또한, collision을 detect하기위해 시뮬레이션에 laser sensor를 추가로 설정하였고, ROS에서 Odometry messages를 subscribing하여 목표 정보를 가져옴.
아래 그림은 GoT-SAC와 모든 DRL 기반 기준 알고리즘의 학습 곡선을 보여줌. 논문에서는 statistics를 측정하고, robustness를 evaluate하기위해 각 알고리즘을 다섯 가지 다른 random seed로 실행함. 구체적으로, 빨간 점선과 실선은 에피소드당 GoT-SAC와 다른 알고리즘의 average reward를 나타내며, 음영 영역은 다섯 번의 실행에서의 분산을 나타냄.
GoT-SAC는 다른 DRL 기반 알고리즘보다 상대적으로 낮은 분산으로 더 높은 reward 수준을 달성하며, GoT-SAC모델들은 ViT-SAC모델과 비교하여 129%와 86%이상으로 더 빠른 수렴을 보이고 훈련 효율성을 향상시킨다. 초기 단계에서는 ConvNet-SAC의 수렴속도가 상대적으로 적은 Parameter수 때문에 약간 더빠르지만, average episode return 은 논문에서 제안된 알고리즘보다 훨씬 낮은걸 확인할 수 있음.
전체적으로 수렴 곡선은 제안된 접근법이 더 나은 데이터 효율성을 보이며, 다른 알고리즘에 비해 적은 양의 데이터(더 적은 훈련 에피소드)를 소비하면서 향상된 성능(더 높은 reward)를 달성함을 의미함.
 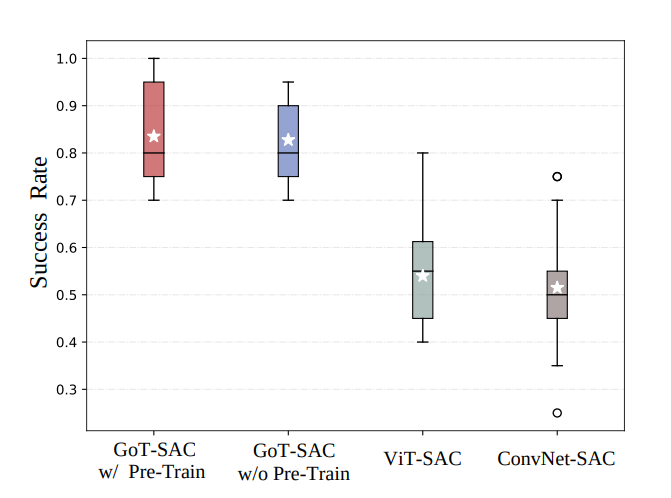 |
|---|
| GoT-SAC와 다른 DRL기반 알고리즘의 학습 곡선과 Success Rate Boxplot(검은색 실선과 '별'은 각각 중앙값과 평균을 나타내고 빈 원은 이상치를 나타냄) |
D. Attention Visualization and Evaluation
우수한 효율성과 성능 외에도, GTRL 접근법은 Goal-orient scene representation 덕분에 model의 해석 가능성 측면에서 중요한 이점을 갖고 있음.
제안된 접근법은 fast convergence와 excellent performance를 분석하기 위해 무작위로 샘플링된 RGB Image에 대해 GoT encoder의 Attention을 추출하였음.
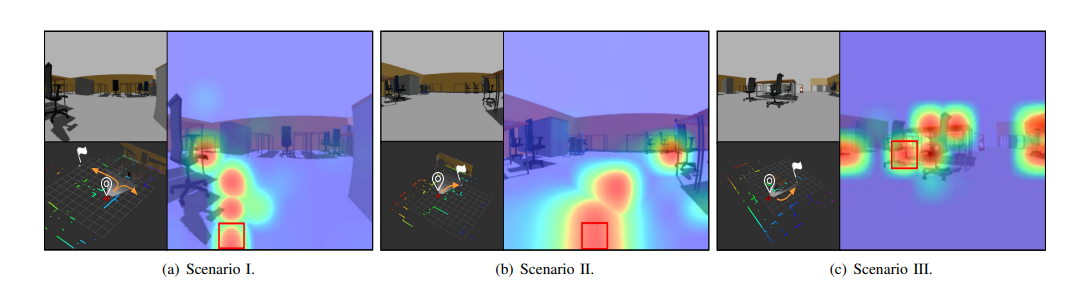 |
|---|
| Attention Flow Visualization, 각 시나리오에서 왼쪽 사진은 원래의 RGB이미지와 목표 정보를 보여주고, 오른쪽 사진은 Attention Flow로 masking된 RGB 이미지(Attention 수준은 파란색(낮음)에서 빨간색(높음)으로의 색상 변화 표현 |
Queried image patch는 빨간 사각형으로 강조 표시되며, Attention 수준은 파란색(낮음)에서 빨간색(높음)으로의 색상 변화를 통해 표현된다.
- Scenario 1(그림 a):
- UGV가 다가오는 T 교차로로 향하고 있으며, 목표 위치는 사무실 의자와 책상 뒤쪽의 왼쪽에 위치하고 있음,
- visual Attention flow map에서 attention은 목표 지점으로의 집중하고 있음을 확인
- Scenario 2(그림 b):
- 명확히 목표 지점에 대한 visual path가 보임
- Scenario 3(그림 c):
- 이전의 두 Scenario와 달리 주행 가능한 공간 대신 obstacle에 대한 image patch에 대한 쿼리를 수행
Attention이 대부분 인접 obstacle에 대해 강조하며, 명백히 주행 불가능한 영역을 가르키는 것을 발견함, 따라서 UGV가 장면을 분석하고 collision-free path로 도달하는 방법에 대해 명확히 설명을 제공할 수 있음
또한, 제안된 접근법을 뒷받침하기 위해 ViT-SAC모델과 정량적으로 평가하고 비교하였음. 각 모델을 세번의 무작위 에피소드를 실행하고 전체 프레임을 평균내어 통계적 특성을 측정함. -> 비교할 label이나 실제 값이 존재하지 않기 때문에, 이는 Unsupervised task 임.
그렇기 때문에, 이 실험에서 두 가지 Unsupervised metrics를 사용함. Attention weights distribution의 균등성을 측정하기 위한 Gini계수와 Attention concentration을 평가하기 위한 Shannon-Wiener지수를 사용하였음.
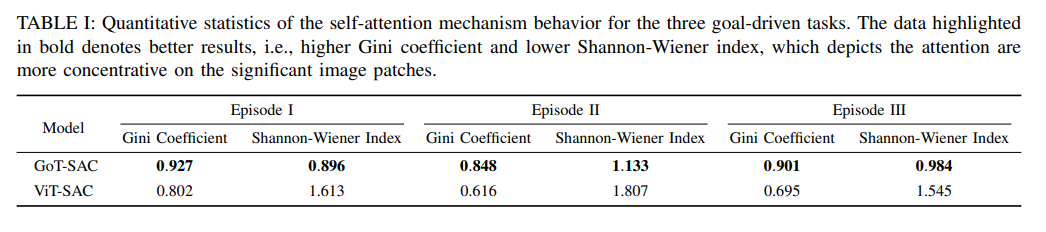 |
|---|
| 세 가지 에피소드에 대한 self-Attention mechanism behavior, 더 높은 Gini계수와 더 낮은 Shannon-wiener지수를 나타내며, 이는 Attention이 중요한 image patch에 더 집중된다는 것을 의미 |
두 지표 모두 GoT-SAC모델의 Attention이 더 희박하고 작업 관련 image patch에 더 집중되는 경향이 있음. 이는 goal-oriented scene representation에 대한 해석 가능성이 있음을 증명함.
또한, Attention이 모델 성능에 어떻게 영향을 미치는지 실험을 통해 보여주었는데, 로봇이 이동하고자 하는 Attention이 집중된 부분에 변환를 주는 교란 기반 방법(perturbation-based method)방법을 사용
모델이 가장 중요한 image patch에 가장 높은 가중치를 갖는 곳을 일부러 변형하였을때(장애물에 대한 Attention을 10% 줄임) 로봇의 성공률이 기존의 GoT-SAC보다 62.5%저하된것을 관찰하였음.
 |
|---|
| 다양한 Attention수준에 따른 Success Rate Comparison |
E. Ablation Study of Goal-guided Transformer Parameters
GoT의 Architecture 즉, Self-Attention(SA)Head와 encoder block의 수라는 두가지 매개변수가 알고리즘 훈련 성능에 미치는 영향을 조사.
하나의 랜덤 시드를 고정하고, SA Head와 Encoder block의 9가지 조합을 테스트하였음. 실험 결과, SA Head와 Encoder block의 수가 많아질수록 성능이 약간 좋아졌고, 8개의 블록과 16개의 헤드로 구성된 그룹이 가장 빠른 수렴 속도를 보였으며 가장 높은 보상 성능을 보임
본 논문에서는 시뮬레이션에서 실제로의 실험에서 하드웨어 플랫폼의 경량 설계와 계산 능력을 고려하여, 각 블록당 4개의 헤드가 있는 2개의 encoder block을 사용
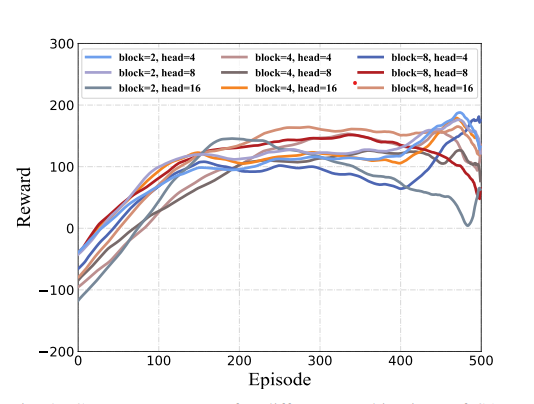 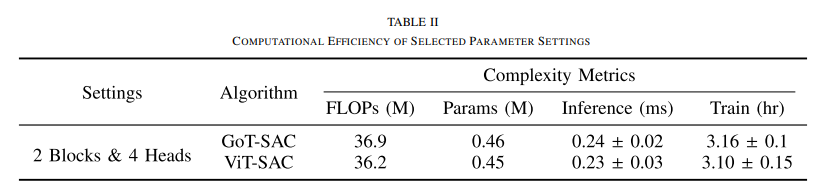 |
|---|
| SA Head와 encoder block parameters에 따른 수렴 속도 비교 그래프와 GoT-SAC와 ViT-SAC 알고리즘 비교 |
F. Sim-to-Real Assessment
시뮬레이션 환경에서의 성능 평가 외에도, 실제 환경에서 autonomous navigation을 위한 실험
Agent Model: SCOUTMINI
edge computer: NVIDIA Jetson Xavier
Sensor: ZED2i stereo camera, IMU, fisheye camera(220도 초광각 시야)
GoT-SAC는 Goal-information과 fisheye RGB image를 UGV로 ROS를 통해 정보를 전달하고 실시간 결정 추론(real-time decision inference)을 UGV chassis에 CAN통신을 보내어 모션 제어를 실현함.
구체적으로, UGV가 각 목적지에 도착 후 짧은 휴식을 취하며 하나씩 도달하도록 유도하는 네 개의 목적지를 설계하고, 최종적으로 시작점 근처로 돌아오도록 하였음. 이 실험은 알고리즘이 정적 장애물을 피하고 주어진 목표 위치로 빠르게 Navigation하는 능력을 테스트하는 것을 목표로함.
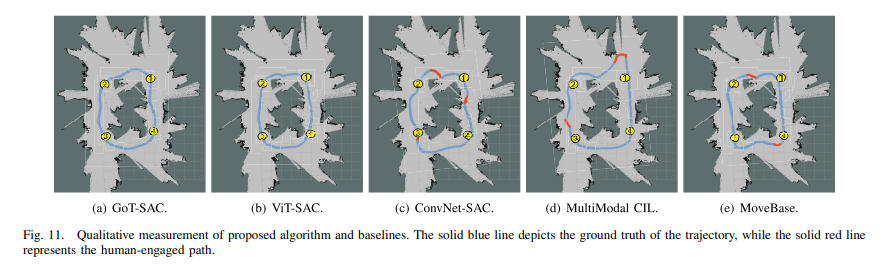  |
|---|
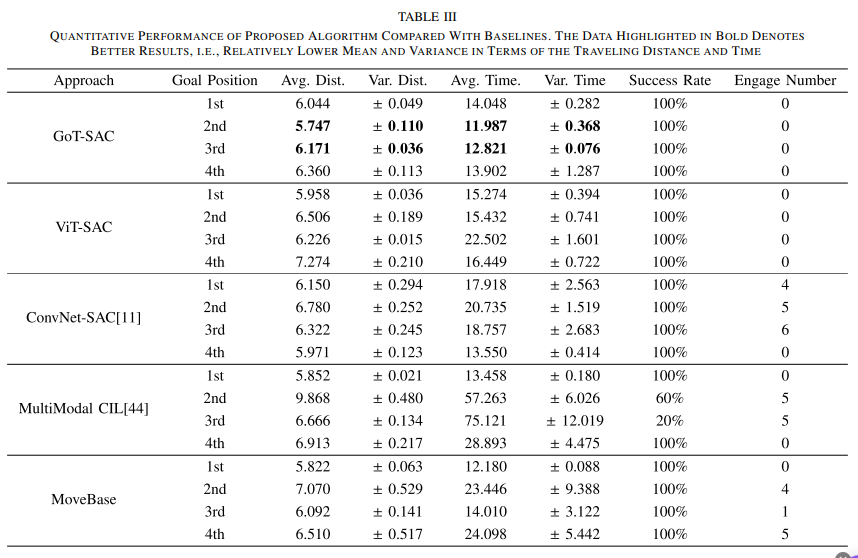
| 각 알고리즘 성능의 Qualitative measurement와 Quantitative Table |
위 그림에서 UGV의 Trajectory를 파란색으로 Human Trajectory(인간의 개입)를 빨간색으로 표시하였다. GoT-SAC정책은 부드럽고 collision-free navigation을 수행하는 반면, 나머지 세 알고리즘(ConvNet-SAC, MultiModal CIL, MoveBase)모두 인간의 개입이 필요함.
ViT-SAC도 시뮬레이션 환경에서의 평가 동안 낮은 평균 성공률에도 불구하고 동등하게 우수한 성능을 보임.
또한, Policy의 performance와 robustness를 더 깊이 비교하기 위해, 각 goal-driven task에 대해 여섯 가지 통계 지표를 사용했다. 이동거리의 평균과 분산, Navigation time의 평균과 분산, 성공률(Success Rate), 인간의 개입 횟수(Engagement number)이다. 특히 UGV가 goal position에 1분 이내에 도달하면 Successfully한 도착으로 간주하며, Collision이 발생할 가능성이 있을 때 UGV 제어에 개입함.
GoT-SAC모델이 ViT-SAC과 MoveBase 를 포함한 다른 기준 알고리즘과 비교하여 모든 영역에서 뛰어난 performance와 robustness를 보여줌. 전반적으로, sim-to-real 실험의 정량적 및 질적 결과는 SOTA 학습 기반 접근법과 고전적인 UGV 항법 방법을 포함한 다른 기준 알고리즘과 비교하여 GoT-SAC의 우수성을 입증함.
추가적으로 저자들은 GoT-SAC의 generalization 능력을 검증하기 위해 알려지지 않은 Unknown environment에서 테스트하였음.
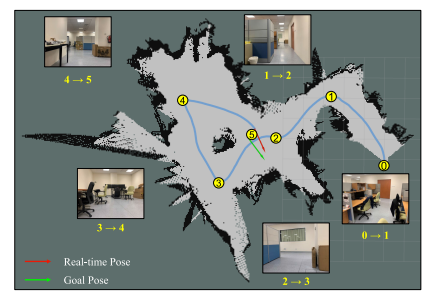 |
|---|
| 새로운 실험 환경 |
실험 결과, GoT-SAC 모델은 Collision이나 engagement없이 5개의 목적지에 접근하며, generalization와 transferability를 갖추고 있음을 보임.
5. Conclusion And Discussions
이 논문에서는 goal-driven Autonmous Navigation을 위한 Transformer 기반 DRL 접근법(GTRL)을 제안함.
이 접근법은 Goal Information을 scene representation의 입력으로 사용하여 데이터 효율성을 크게 향상시킴. 시뮬레이션 및 실제 환경에서의 실험 결과, GTRL은 데이터 효율성, 성능, 강건성 및 시뮬레이션-현실 전이 능력에서 우수성을 입증함. 그러나 강한 조명으로 인한 지면 반사와 동적 장애물(예: 지면과 유사한 색상의 옷을 입은 보행자)과 같은 상황에서 성능 저하가 발생하였음.
이를 개선하기 위해 향후에는 실내 환경에서 실외 환경으로 전이하고, 더 다양한 입력 모달리티를 통합할 계획함. 또한, 위치 오류를 완화하기 위한 abnormal detection 및 re-localization functions도 추가할 예정임

잘보고가요