Title : Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning(ICRA 2022 and IEEE RA-L paper)
논문 링크 : https://ieeexplore.ieee.org/document/9645287?source=authoralert
github: https://github.com/reiniscimurs/DRL-robot-navigation?tab=readme-ov-file
1. Abstract
- Deep Reinforcement Learning(DRL)을 통해 알려지지 않은 환경에서 목표 지향적(Goal-Driven) Exploration을 위한 자율주행 네비게이션 시스템을 제안함
- Points of interest(POI)은 환경에서 얻어지고, Optimal Waypoint(경유지)가 선택됨
- 이러한 Waypoint를 따라 로봇은 Global-Goal를 향해 이동하고, 지역 최적화 문제를 완화함
- local navigation을 위한 motion policy는 시뮬레이션에서 DRL 프레임워크로 학습
- 학습된 policy를 waypoint에서 Global-Goal로 로봇을 이동시키기 위해 local navigation layer로 통합된 navigation system 개발
- 즉, MAP에 대한 사전지식 없이 환경에 대한 탐색을 통해 POI를 찾아내고 이를 경유하며 Global-Goal로 이동
- 실험 결과, 복잡한 정적 및 동적환경에서 지도나 사전 정보에 의존하지 않고도 유사한 탐색 방법에 비해 우위를 점함을 보여줌
2. Introduction
기존의 SLAM(동시 위치 추정 및 지도 작성)시스템은 사람이 측정 장치를 조작하여 환경을 매핑하지만, 높은 비용과 여러 제약으로 인해 완전한 자율주행 탐사 시스템(사전 지식 없이 Global-Goal에 도달하기 위한)의 필요성이 대두되고 있음
하지만 탐사 로봇이 사전 지식 없이 Global-Goal에 도달하기 위해 해결해야하는 두가지 문제가 있음
문제 1. Global-Goal로 향하는 최적의 경로 결정
- 문제 : 로봇이 환경에 대한 사전 정보가 없는 상태에서 글로벌 목표에 도달해야함
- 해결 : 로봇은 센서 데이터를 이용해 주변 환경에서 가능한 탐색 방향(POI)을 찾아내고, 이 중 가장 최적의 경유지를 선택하여 Global-Goal로 향함
예를 들어 보면,
- 상황 : 로봇이 큰 창고에 있고, 로봇은 창고의 구조를 전혀 모르는 상태이다.
- 탐색 : 로봇은 주변을 탐색하면서 문, 복도, 벽의 모서리 등의 POI를 감지함
- 경유지 선택 : 로봇은 감지된 POI 중 가장 최적의 경유지를 선택, 예를 들어 열려 있는 문을 최적의 경유지로 선택할 수 있음
- 이동 : 로봇은 선택한 경유지를 향해 이동함, 그 과정에서 새로운 POI
게속 탐색하고, 다음 경유지를 선택하여 이동을 반복함
문제 2. 불확실환 환경에서 지도 데이터 없이 이동 정책 수립
- 문제 : 로봇이 미리 작성된 지도 없이 불확실한 환경에서 이동해야함
- 해결 : Deep Reinforcement Learning(DRL)을 통해 로봇은 불확실한 환경에서 목표를 달성할 수 있는 이동 정책을 학습, DRL은 로봇이 센서 데이터를 기반으로 실시간 의사 결정을 내리게 함
예를 들어 보면,
- 상황 : 로봇이 복잡한 미로에 있고, 미로에 대한 구조를 모름
- DRL 학습 : 로봇은 시뮬레이션을 통해 다양한 미로 환경에서 DRL을 사용해 장애물을 피하고 목표에 도달하는 법을 학습
- 실제 적용 : 로봇은 학습된 이동 정책을 실제 환경에 적용하여 미로를 탐색
- 지역 최적화 문제 해결 : 로봇이 미로의 일부에 갇히지 않고, 전체 목표에 도달하기위해, DRL은 로봇이 지역적인 최적 경로 대신 Global-Goal을 향해 나아가도록 도와줌
따라서, 이 논문에서는 인간의 개입이나 지도에 대한 사전 정보 없이 센서 데이터를 활용해 관심 지점(POI)을 추출하고, Optimal한 Waypoint를 선택하여 로봇을 Global-Goal로 이동시키는 완전한 자율주행 탐사 시스템을 제안함, DRL을 사용해 학습된 이동 정책은 지역 최적화 문제를 해결하며, 로봇이 불확실한 환경에서 효과적으로 Navigation할 수 있도록 도와줌
주요 기여
1. Goal-Driven Exploration을 위한 Global Navigation 및 Waypoint 선택 전략 설계
2. 연속 행동 공간에서 모바일 로봇 내비게이션을 위한 TD3 아키텍처 기반 신경망 개발
3. DRL 이동 정책과 Global Navigation 전략을 결합하여, 알려지지 않은 환경 탐사에서 지역 최적화 문제를 완화하고, 이를 검증하기 위한 광범위한 실험 수행
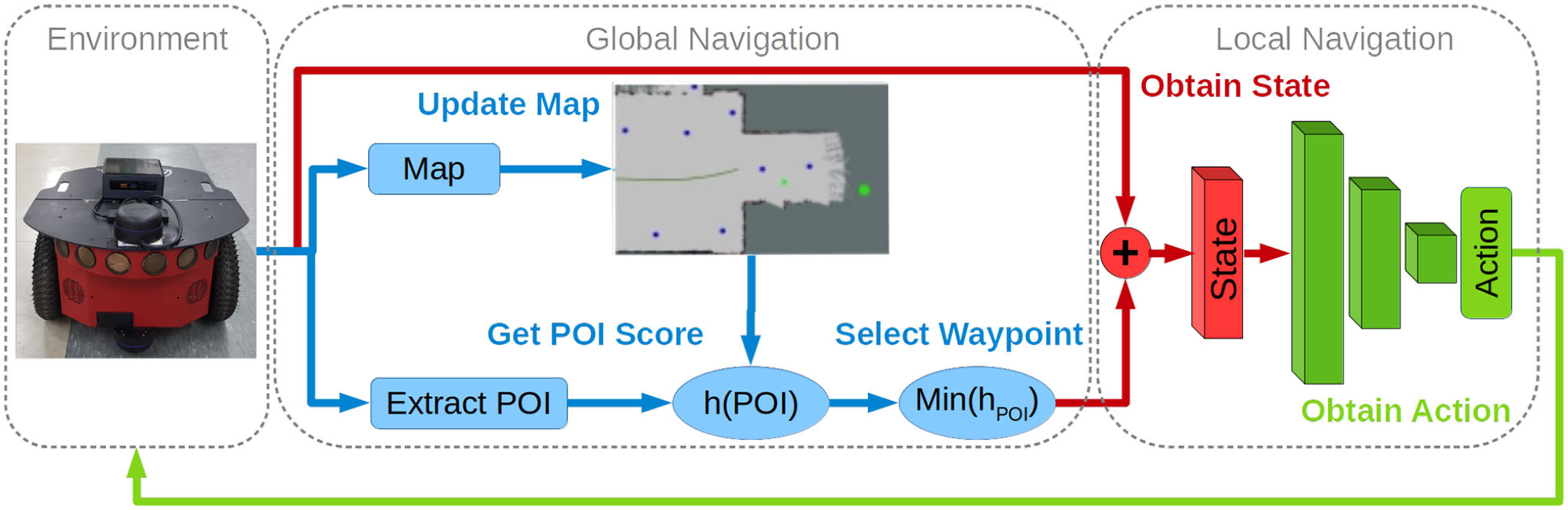
3. Method(Goal-Driven Autonomous Exploration)
 |
|---|
| 제안된 로봇 시스템 |
알려지지 않은 환경에서 Autonomous Navigation과 Exploration을 달성하기 위해, 본 논문에서는 POI에서 Optimal Waypoint 선택과 메핑을 포함한 Global Navigation과 DRL 기반의 Local Navigation으로 구성된 Navigation 구조를 제안함.
- POI는 환경에서 추출되며 평가 기준에 따라 Optimal Waypoint가 선택
- 각 단계에서 경유지는 로봇의 위치와 방향에 상대적인 극좌표 형식으로 신경망에 전달됨
- 행동은 센서 데이터를 기반으로 계산되어 Waypoint를 향해 실행됨
- Global-Goal를 향해 Waypoint사이를 이동하는 동안 메핑이 수행됨
내용에 대한 이해를 돕기위한 예시를 들면
로봇 청소기의 자율주행 탐사
1. Global Navigation
- 목표 : 집 전체를 청소하기 위해 각 방을 탐사하고, 최적의 청소 경로를 계획함
- POI 추출 : 로봇은 각 방의 문, 통로, 구성 등 중요한 지점을 관심 지점(POI)로 인식함
- Waypoint 선택 : 로봇은 POI 중 가장 가까운 문을 Waypoint로 선택하여 다음 방으로 이동함
- 메핑 : 로봇은 이동하면서 방의 지도를 업데이트함
- Local Navigation
- Waypoint 전달 : 로봇은 선택된 경유지를 극좌표 형식으로 신경망에 전달함. 예를 들어, "앞쪽 2미터, 오른쪽 1미터"와 같은 방식으로 Waypoint의 위치를 전달
- 상태 확인 : 로봇은 센서 데이터를 통해 현재 상태를 파악함. 예를 들어, 로봇의 앞에 장애물이 있는지, 바닥이 평평한지 등을 확인함
- 행동 결정 : 신경망은 현재 상태와 전달된 경유지 정보를 바탕으로 로봇의 다음 행동을 결정함. 예를 들어, "왼쪽으로 30도 회전한 후 직진"과 같은 행동을 결정
- 행동 실행 : 로봇은 결정된 행동을 실행하여 Waypoint를 향해 이동함. 이동 중에 장애물이 발견되면 실시간으로 경로를 수정함
- 종합
- Global Navigation은 로봇이 전체(예: 집 전체 청소)를 달성하기 위해 큰 그림을 그리는 역할을 함. 이는 POI를 추출하고, 최적의 WayPoint를 선택하며, 이동하면서 지도를 작성하는 것을 포함함
- Local Navigation은 로봇이 현재 상태에서 최적의 Waypoint로 이동하기 위해 필요한 실시간 결정을 내리는 역할을 함. 이는 센서 데이터를 기반으로 실시간 행동을 결정하고 실행하는 것을 포함함.
A. Global Navigation
로봇이 Global-Goal을 향해 Navigation하려면, Local Navigation을 위한 중간 Waypoint를 이용 가능한 POI에서 선택해야 한다.
초기에는 환경에 대한 정보가 없으므로 최적의 경로를 계산할 수 없음
따라서, 로봇은 목적지로 이동하거나 길이 막혔을때 길이 막혔을 때 가능한 대체 경로를 인식하기 위해 길을 따라 환경을 Exploration 해야함. 사전 정보가 없으므로 가능한 POI는 로봇의 주변에서 얻어야하며 메모리에 저장됨
논문에서는 새로운 POI를 얻기 위한 두가지 방법을 구현함
- 연속적인 레이저 읽기() 사이의 값 차이가 임계값보다 큰 경우
- 예시:
- 상황 : 로봇이 복도에 있음
- LiDAR 읽기:
- 첫번째 LiDAR읽기에서 벽까지의 거리는 2m
- 두번째 LiDAR읽기에서 벽까지의 거리는 5m
- 값 차이:
- 두 읽기 사이의 차이는 3m
- 이 차이가 임계값보다 크면 로봇은 이 지점에 빈공간이 있다고 판단하고 POI를 추가한다.
- 예시:
- 라이다 센서가 최대 범위를 가지기 때문에, 이 범위 밖의 읽기는 비수치형 타입으로 반환되며 이는 환경에서의 자유 공간을 나타냄
- 라이다 센서의 최대 범위가 10m라고 가정했을때 여러 방향으로 레이저를 발사했을 때, 일부 방향에서는 10m 범위 내에 벽이나 장애물이 없음.
- 이 방향에서의 레이저 읽기는 비수치형 값(예: "Infinity" 또는 "N/A")로 반환
- 로봇은 이 비수치형 값을 자유 공간으로 인식하고 해당 지점을 POI로 설정
이후, POI가 장애물 근처에 있는 것으로 판명되면 메모리에서 삭제함. 또한, 로봇이 이미 방문한 장소에서는 POI 생성 X
추가로 POI가 Waypoint로 선택되었지만, 여러 단계에 걸쳐 도달할 수 없는 경우, 해당 Waypoint는 삭제되고 새로운 Waypoint가 선택
 |
|---|
| 파란색 원 : 위와 같은 방법으로 추출된 POI, 초록색 원 : 현재 Waypoint, (a); 파란색 POI는 레이저 읽기 사이의 간격에서 얻어진 것, (b); 파란색 POI는 비수치형 레이저 읽기에서 추출된 것 |
이용 가능한 POI중 시간 t에서 최적의 Waypoint는 Information-based Distance Limited Exploration(IDLE) evaluation method를 사용하여 선택됨.
본 논문에서는 각 후보 POI의 적합성을 다음과 같이 평가함
각 후보 POI 의 점수 h는 세 가지 구성 요소의 합으로 이루어짐. 로봇의 위치 와 후보 POI 사이의 유클리드 거리 구성 요소 는 함수로 표현된다.
여기서 는 오일러 수, 는 점수를 할당받기위한 두 단계 거리 한계이다.
두 번째 구성요소인 는 후보 POI와 Global-Goal 사이의 유클리드 거리를 나타낸다.
마지막으로, 시간 t에서의 지도 정보 점수는 다음과 같이 표현된다.
여기서 는 다음과 같이 계산된다.
여기서 는 후보 점 좌표 와 주변의 정보를 계산하기 위한 커널 크기이고, 와 는 각각 커널의 너비와 높이를 나타낸다.
최소 IDLE점수(최소 거리)를 가진 POI는 Local Navigation을 위한 최적의 Waypoint로 선택된다.
B. Local Navigation
본 논문에서는 DRL을 사용해 시뮬레이션 환경에서 Local Navigation Policy를 별도로 훈련하며,
Twin Delayed Deep Deterministic Policy Gradient(TD3) 기반 신경망 구조를 사용하여 동작 정책을 훈련한다. TD3는 연속적인 행동 공간에서 행동을 수행할수 있게 해주는 Actor-Critic Network이다.
Local env는 로봇 앞의 180도 범위의 라이다 읽기 데이터로 이 정보는 로봇의 위치에 대한 Waypoint의 극좌표와 결합된다. 결합된 데이터는 TD3의 Actor Network에서 상태 입력 s로 사용된다. Actor Network는 두개의 Fully Connected Layers로 구성되어있다. 각 Layer 뒤에는 ReLU Activation Function이 뒤따른다.
마지막 Layer는 로봇의 linear velocity인 와 각속도 를 나타내는 두 개의 행동 매개변수 a가 있는 Output Layer와 연결된다. Output Layer에는 -1 ~ 1범위로 제안하기 위해 Activation Function 이 적용된다. 환경에서 행동을 적용하기 전에 다음과 같이 Maximum linear velocity 와 Maximum angular velocity 에 의해 스케일 조정된다.
Actor-Critic 쌍의 Q value 는 두 개의 Critic Network에 의해 평가된다. 두 Critic-Network는 동일한 구조를 가지지만, 매개변수 업데이트가 지연되어 매개변수 값의 Divergence를 허용한다. Critic-Network는 상태 와 행동 쌍을 입력으로 사용한다. 상태 는 Fully Connected Layer에 입려되며 ReLU Function으로 출력 가 생성된다.
이 Layer의 출력과 행동은 각각 동일한 크기의 두개의 Transformation Fully Connected Layers(TFC) 로 입력된다. 이 Layer는 다음과 같이 결합된다.
여기서 는 combined Fully Connected Layer(CFC), 는 각각 의 가중치이고, 는 의 편향이다.
그런 다음 ReLU Activation Function에 결합된 Layer 에 적용된다. 이후 1개의 Q value를 Output으로 내보낸다. Actor-critic 쌍의 Output 값이 Overestimation 되는 것을 방지하기 위해 두개의 critic 모델중 최소값의 Q value를 최종 Critic Output으로 내보낸다.
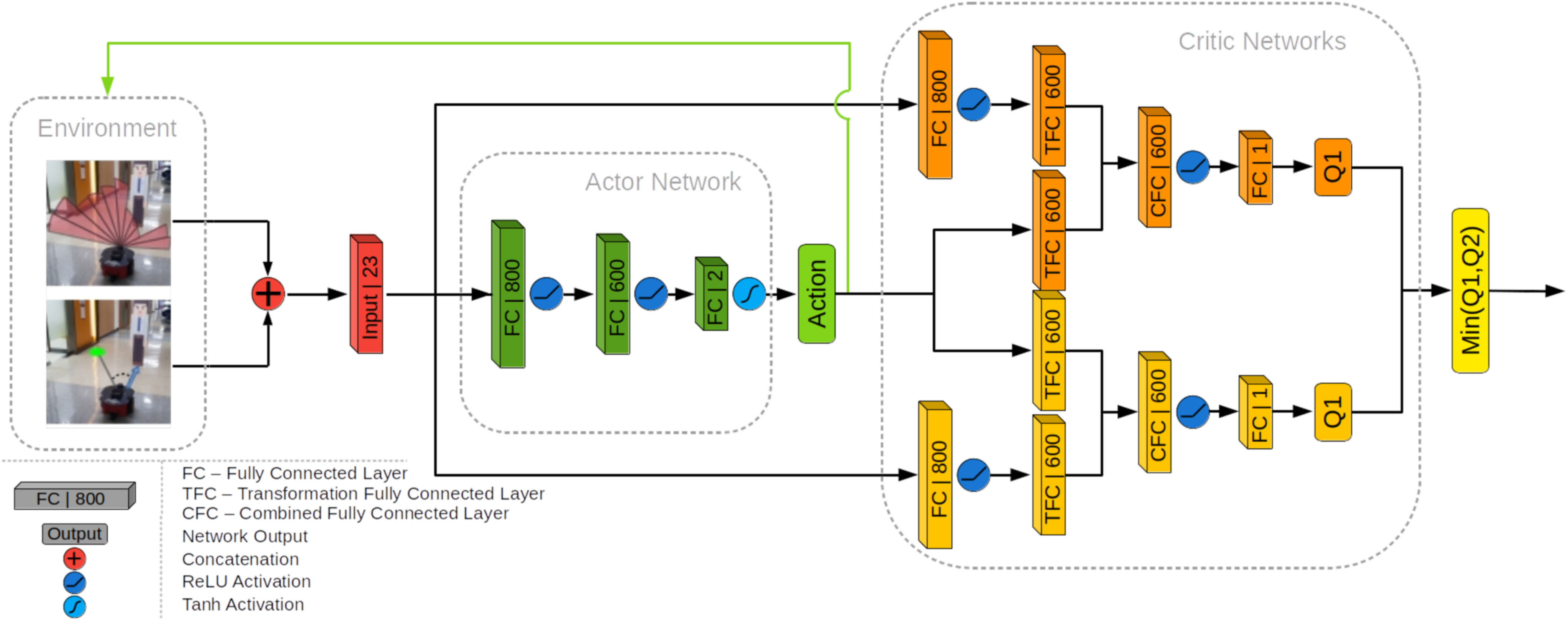 |
|---|
| Actor-Critic 부분을 포함한 TD3 Network Architecture |
Policy는 다음 함수에 따라 보상을 받는다.
시간 단계 t에서 State-Action 쌍의 보상 은 세 가지 조건에 따른다. 현재 시간 단계에서 목표까지의 거리 가 임계값 (논문에서는 1m)보다 작으면, Positive goal reward인 가 적용된다.
충돌이 감지되면, Negative collision reward 인 가 적용된다. 이 두조건이 모두 충족하지 않다면 현재 linear velocity 와 angular velocity 를 기반으로 즉각적인 보상이 적용된다.
주어진 Goal을 향한 Navigation 정책을 guide하기위해 다음과 같은 delayed attributed reward method가 사용된다.
여기서 n은 보상이 업데이트되는 이전 단계의 수를 나타낸다. 이는 Positive Goal reward이 목표에 도달하기 전 마지막 n 단계에 걸쳐 점점 감소하는 것을 의미한다.
C. Exploration and Mapping
Waypoint를 따라 로봇은 Global goal을 향해 guided 된다. 로봇이 Global goal에 가까워지면, 목표 지점으로 Navigation한다. 이동하는 동안 환경이 Explored 되고 지도화된다.
메핑과 함게 완전한 자율주행 Exploration 알고리즘의 psudo code는 다음과 같다.

psudo code의 알고리즘에 대해 설명하면
- globalGoal : 글로벌 목표를 설정
- : Global-Goal로의 내비게이션 임계값 설정
- while : "reachedGlobalGoal"이 "True"가 아닐동안 반복
- Global Goal에 도달하지 않았을 동안 반복 루프를 실행
- Read sensor data : 센서 데이터를 읽음
- 로봇의 현재 상태와 환경 정보를 수집
- Update map from sensor data : 센서 데이터를 기반으로 지도를 업데이트
- 로봇의 이동 경로와 주변 환경을 지도에 반영
- Obtain new POI : 새로운 POI를 획득
- 주변 환경에서 관심 지점을 탐지
- if then : 현재 시간 단계 t에서 목표까지의 거리 가 임계값 보다 작으면 다음을 수행
- Global Goal에 매우 가까워 졌는지 확인한다.
- if waypoint == globalGoal then : Waypoint가 Global Goal와 같다면 다음을 수행
- 현재 Waypoint가 Global Goal인지 확인
- "reachedGlobalGoal"을 "True"로 설정하여 목표에 도달했음을 표시
- else: 그렇지 않으면
- 현재 Waypoint가 Global Goal이 아닐 때 다음을 수행
- if then : 로봇의 현재 위치 와 Global Goal 사이의 거리가 보다 작으면,
- Global Goal에 매우 가까워졌는지 확인
- Waypoint를 globalgoal로 설정
- else: 그렇지 않으면
- 다른 POI를 탐색
- for i in POI do: POI목록을 순회함
- 각 POI에 대해 반복 작업을 수행함
- calculate from (1) : 식(1)을 사용하여 를 계산
- POI의 적합성 평가
- end for : POI 목록 순회를 종료
- Waypoint <- POI : 최소 h 값을 가진 POI를 Waypoint로 설정한다.
- 가장 적합한 POI를 Waypoint로 선택
16-18. end if : 조건문 종료
19 : Obtain an action from TD3 : TD3 네트워크로부터 행동을 얻음- 학습된 정책을 사용하여 다음 행동을 결정
- Perform action : 행동을 수행
- 결정된 행동을 수행함
- end while : 반복 루프 종료
4. Experiments
A. System Setup
시스템 설정:
- 훈련 설정:
- 하드웨어 : NVIDIA GTX 1080 그래픽 카드, 32GB RAM, Intel Core i7-6800k CPU
- 시뮬레이션 : Gazebo 시뮬레이터에서 800 Epsoide 동안 훈련(~8시간 소요), 각 Episode는 목표 달성, 충돌 감지, 또는 500 단계 후 종료
- 매개변수 : 최대 선형 속도 =0.5m/s, 최대 각속도 = 1 rad/s. 지연 보상은 마지막 n=10 단계 동안 업데이트
- 훈련 환경 : 각 Episode 마다 장애물 위치를 무작위로 변경한 10x10m 크기의 시뮬레이션 환경
 |
|---|
| 훈련 환경 예시 |
- 실제 환경 설정:
- 센서 : 서로 다른 높이에 장착된 두 개의 RPLiDAR 레이저 센서(최대 범위 10m), 로봇 앞쪽 180° 커버
- 데이터 처리 : 레이저 데이터를 21개의 그룹으로 나누어 입력 상태로 사용, Waypoint의 극좌표와 결합
- 지도 작성 : ROS SLAM Toolbox를 사용하여 지도 작성 및 로봇 위치 파악
- 실제 실험 하드웨어 : 정량적 실험을 위한 Intel NUC mini pc, 정성적 실험을 위한 NVIDIA RTX 2070 M과 Intel COre i9-10980HK CPU를 탑재한 랩톱
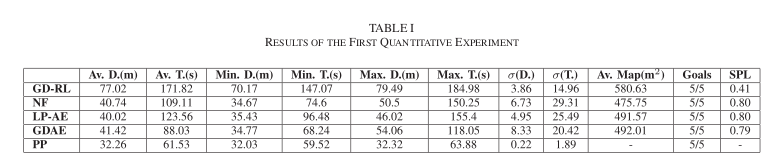
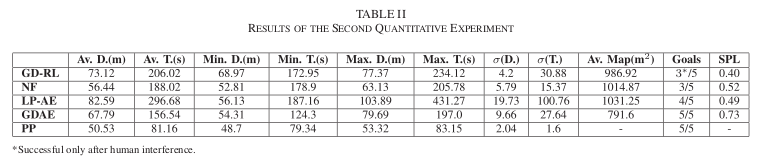
B. Quantitative Experiments
- 목표 : 제안된 Goal-Driven Autonomous Exploration(GDAE) 방법을 다른 Exploration 방법과 비교
- 비교 방법:
- Nearest Frontier(NF): SLAM 기반 탐사 전략으로, 목표까지의 거리를 포함하도록 업데이트
- Goal-Driven Reinforcement Learning(GD-RL) : Global Navigation 없이 Reinforcement Learning 기반 방법
- Local Planner Autonomous Exploration(LP-AE) : 신경망을 ROS Local Planner Package로 대체한 시스템
- Path Planner(PP) : 알려진 지도에서 Dijkstra 알고리즘으로 얻은 경로
- 기록된 데이터 : 이동 거리 D(m), 이동 시간 T(s), 기록된 지도 크기() , 목표 도달 성공 횟수
- 첫번째 실험 환경:
- 특징 : 매끄러운 벽과 여러 지역 최적화 포함
- 결과 : GDAE는 유사한 방법에 비해 비교적 짧은 이동 거리로 Global Goal에 도달했지만, Navigation time은 적게 소요됨. NF와 LP-AE방법은 Waypoint로 경로를 다시 계산하는데 필요한 대기 시간 때문에 시간이 증가, GD-RL 방법은 Local optimum trap에 빠져 벽을 따라가며 탈출, 이는 거리와 시간을 크게 증가시킴
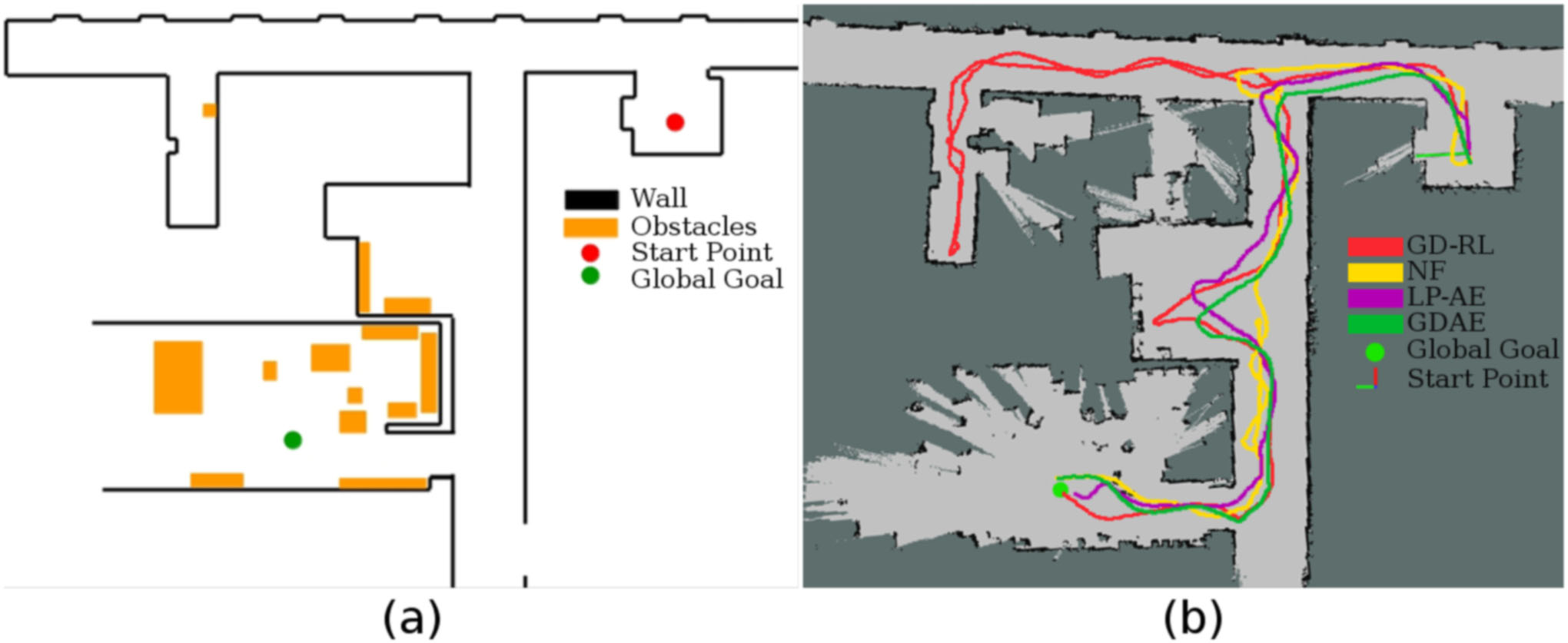  |
|---|
| 첫번째 실험 환경 |
- 두번째 실험 환경:
- 특징 : 가구, 의자, 테이블, 유리 벽 등 다양한 복잡성을 가진 장애물 포함
- 결과 : GDAE는 가장 짧은 시간과 비교적 짧은 거리로 Global Goal에 성공적을 도달, NF와 LP-AE 방법은 지도 정확도에 크게 의존, 여러 번 의자와 유리 벽과 같은 아직 등록되지 않은 장애물을 통과하는 경로를 계산하여 목표에 도달하지 못함. GD-RL 방법은 초기에는 Local optimum에서 최적화에서 탈출하지 못하고 Goal에 도달하지 못했으나, 이후 인간 운영자가 개입하여 로봇을 자유 공간으로 안내
  |
|---|
| 두번째 실험 환경 |
- SPL(Success weighted by Path Length) 결과 : 제안된 방법이 단순한 환경에서는 SLAM 및 Planning-based methods와 비교할 만한 성능을 보이지만, 복잡한 환경에서는 장점을 가짐
C. Qualitative Experiments
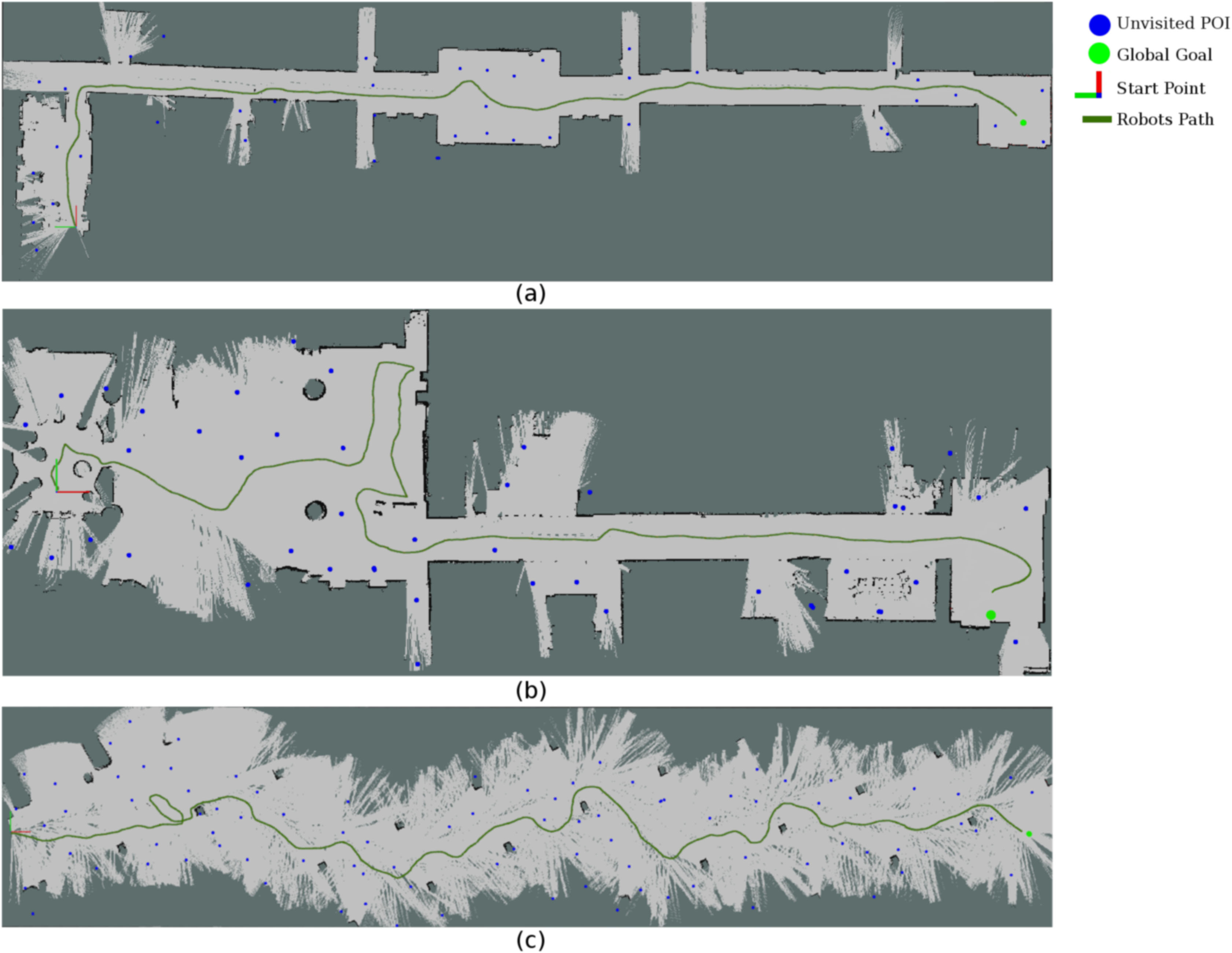
저자는 추가적으로 GDAE methods 방법을 사용하여 다양한 실내 환경에서 실험을 수행함.
논문에서 제안한 GDAE methods는 Navigation system이 다양한 규모와 복잡성을 가진 알려지지 않은 환경에서 Exploration 하고 Navigation하며 GLobal Goal에 대한 신뢰성 있게 찾을수 있음을 관찰함.
  |
|---|
| 추가적인 Large Scale 환경 |
5. Conclusions
본 논문에서는 Deep Reinforcement Learning(DRL)기반의 Goal-Driven Autonomous Exploration(GDAE)을 소개한다.
1. 시스템 통합 : GDAE 시스템은 Local Navigation과 Global Navigation 을 결합하여 효과적인 Exploration 을 수행
2. 성능 평가 : 실험 결과, GDAE 시스템은 이미 알려진 환경에서 Path Planning이 얻은 optimum solution에 상당히 근접하게 작동하며, SPL 측정 결과에 따르면 지도에 의존하는 SLAM 방법보다 복잡한 시나리오에서 더 신뢰할 수 있음
