회사에서 서비스 확장을 위해서 특정 인덱스에 담겨있던 데이터를 다른 인덱스에 옮겨줘야할 일이 생겼다. 같은 팀원분이 pipeline으로 하면 된다고 알려줘서 그에 대해 알아보고자 한다.
Ingest Pipeline이란?
인덱싱전에 데이터를 보완처리하여 수집할 수 있다. 프로세서 를 통해 가능한 작업을 수행할 수 있다. 예를 들어, 기존 데이터에서 필드를 제거하고 텍스트에서 값을 추출하여 데이터를 보강할 수 있다.
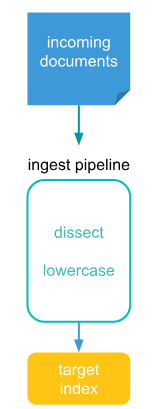
- 파이프라인 처리를 핸들링하는 Ingest Node역할을 가진 노드가 최소 한개는 반드시 있어야한다. 수집처리해야하는 양이 많으면 dedicated ingest nodes 를 만드는 것을 추천한다.
- 엘라스틱서치 보완기능이 활성화되어 있다면, 파이프라인을 관리하기 위해서는
manage_pipeline이라는 클러스터 권한을 가지고 있어야한다. **enrich라는 프로세서를 포함한 파이프라인을 만든다면 추가적인 셋업이 필요하다.**
Pipeline 생성 및 관리
Rest API 로도 가능하지만, 간편하게 키바나에서도 파이프라인 설정이 가능하다.
- 목록 보기 : Stack Management > Ingest Pipelines
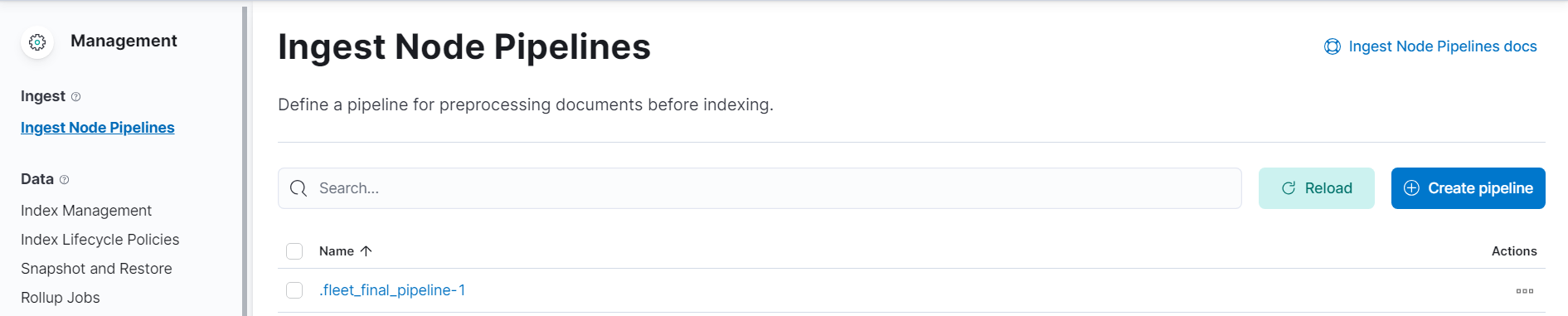
- 파이프라인 생성 : Stack Management > Ingest Pipelines > create pipeline
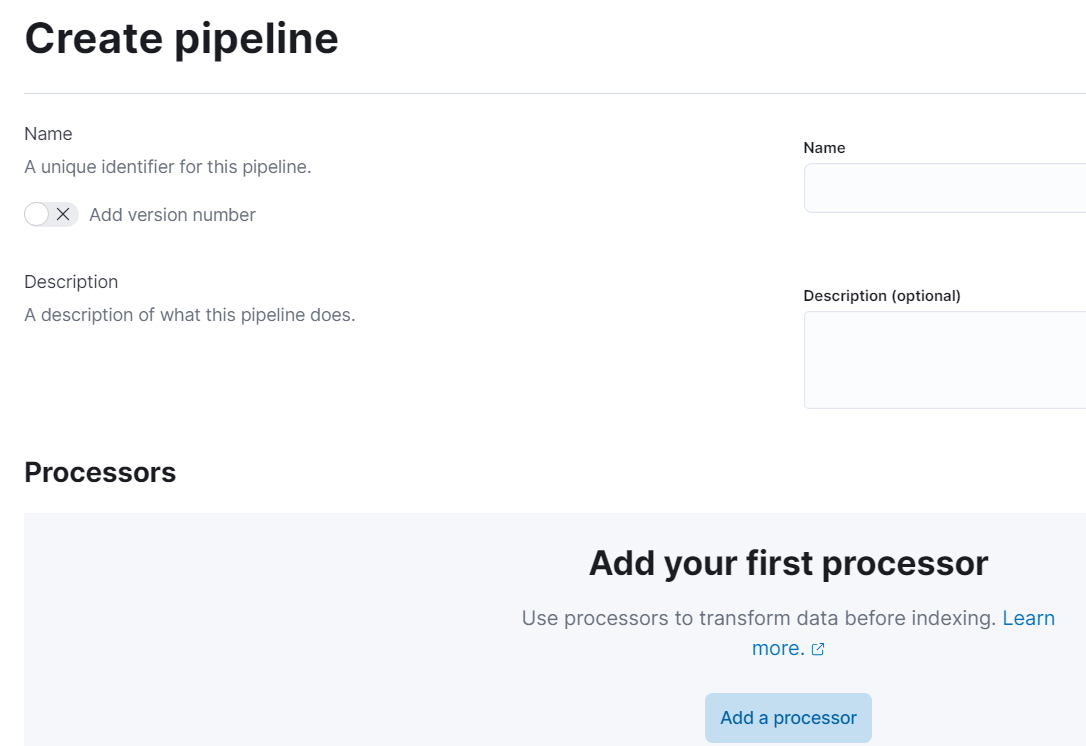
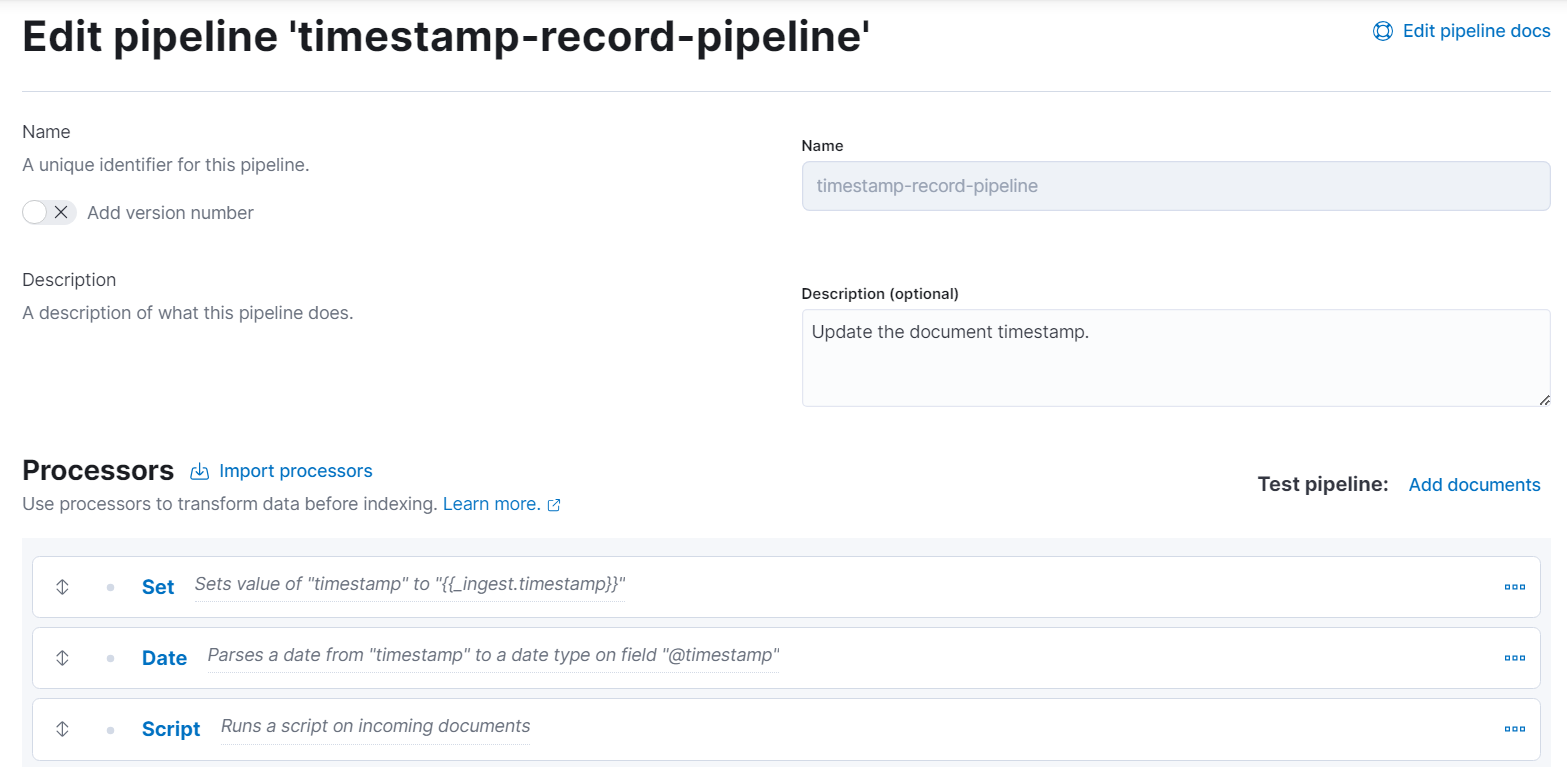
- 파이프라인 프로세서 생성 : Stack Management > Ingest Pipelines > Create pipeline > Add a processor
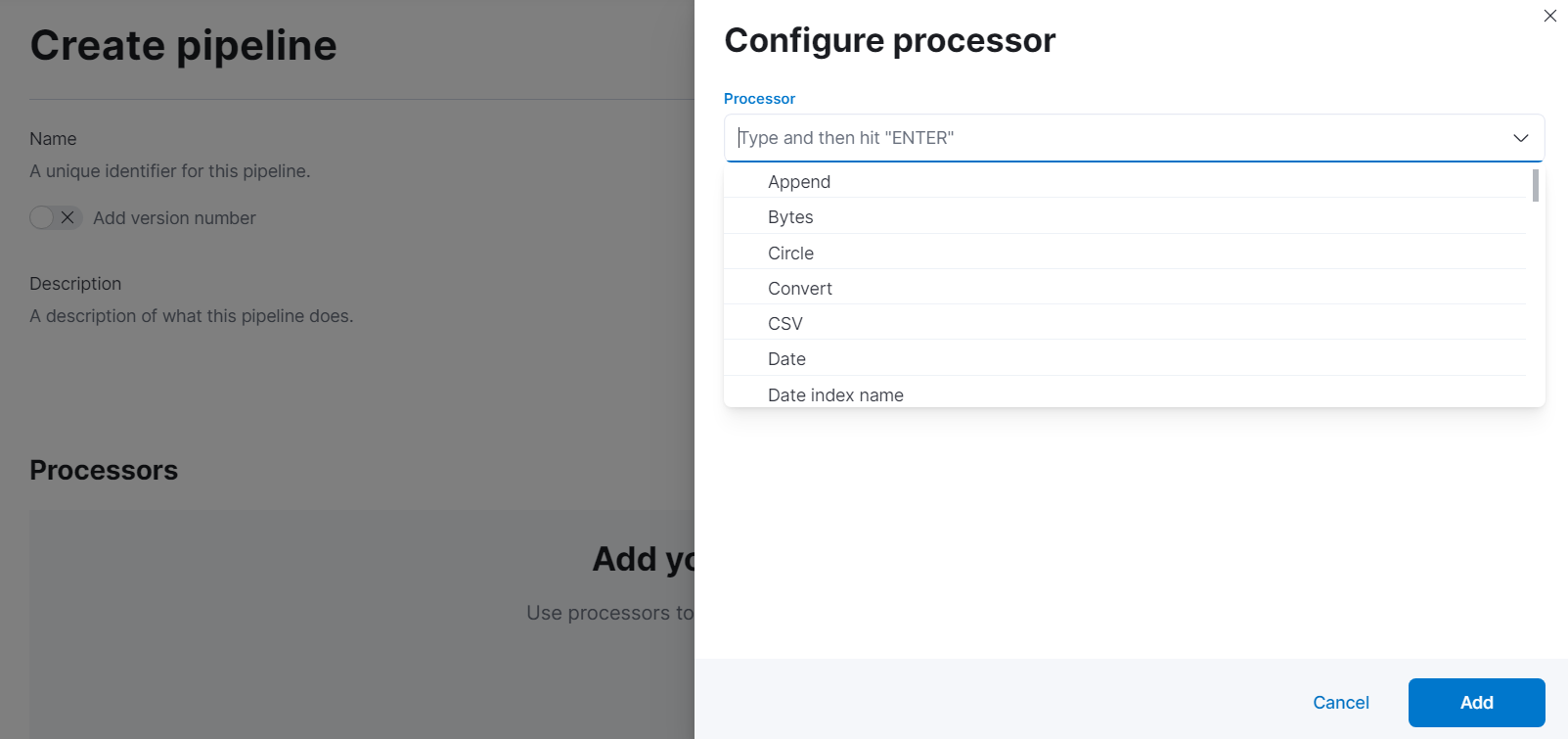
-
여러가지 processor가 있지만, 내가 사용한 몇 가지만 소개해보겠다. 나머지는 해당 경로 참고
-
Set : 하나의 필드를 설정하여 지정한 값으로 세팅해준다. 필드가 이미 존재한다면 지정한 값으로 대체된다.
// set을 가진 파이프라인 생성 PUT _ingest/pipeline/set_os { "description": "sets the value of host.os.name from the field os", "processors": [ { "set": { "field": "host.os.name", "value": "{{{os}}}" } } ] } // 파이프라인 테스트를 위해 "os": "Ubuntu" 데이터 insert POST _ingest/pipeline/set_os/_simulate { "docs": [ { "_source": { "os": "Ubuntu" } } ] } //결과 { "docs" : [ { "doc" : { "_index" : "_index", "_id" : "_id", "_version" : "-3", "_source" : { "host" : { "os" : { "name" : "Ubuntu" // 파이프라인에 의해 추가 } }, "os" : "Ubuntu" }, "_ingest" : { "timestamp" : "2019-03-11T21:54:37.909224Z" } } } ] } -
Date : 날짜 필드에 날짜를 분석하여 문서의 타임스탬프로 사용하거나 특정 날짜 포맷으로 사용한다. 기본적으로
timestamp라는 새 필드를 추가한다. 다른 필드명으로 하고 싶다면,target_field라는 옵션을 사용할 수 있다.{ "description" : "...", "processors" : [ { "date" : { "field" : "initial_date", "target_field" : "timestamp", "formats" : ["dd/MM/yyyy HH:mm:ss"], "timezone" : "Europe/Amsterdam" } } ] } -
Script : 들어오는 문서에 인라인으로 또는 이미 저장되어 있는 스크립트를 실행한다. 스크립트 캐시가 사용되고 있다. 성능을 향상시키기 위해서는 스크립트 캐시 크기를 적절하게 조정하는 것이 좋다.
POST _ingest/pipeline/_simulate { "pipeline": { "processors": [ { "script": { "description": "Extract 'tags' from 'env' field", "lang": "painless", "source": """ String[] envSplit = ctx['env'].splitOnToken(params['delimiter']); ArrayList tags = new ArrayList(); tags.add(envSplit[params['position']].trim()); ctx['tags'] = tags; """, "params": { "delimiter": "-", "position": 1 } } } ] }, "docs": [ { "_source": { "env": "es01-prod" } } ] } //결과 { "docs": [ { "doc": { ... "_source": { "env": "es01-prod", "tags": [ "prod" ] } } } ] } -
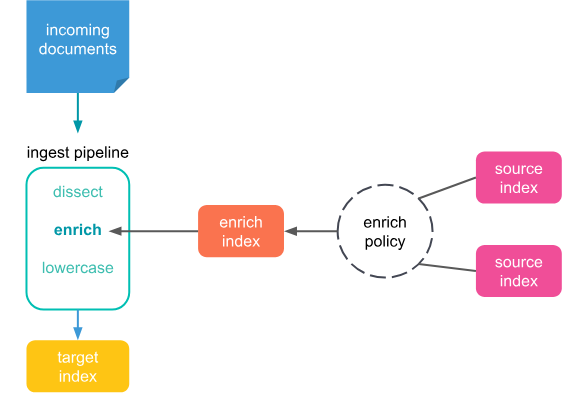
Enrich : 다른 인덱스의 데이터로 문서를 보충한다.
-
들어오는 문서에 몇가지 정책을 적용하여 데이터를 추가한다.
-
필수사항
- 인덱스
read권한이 필요 enrich_user역할을 부여
- 인덱스
-
정책 설정
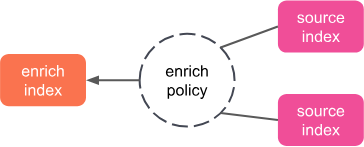
PUT /_enrich/policy/my-policy { "match": { "indices": "users", "match_field": "email", "enrich_fields": ["first_name", "last_name", "city", "zip", "state"] } } -
정책 실행
PUT /_enrich/policy/my-policy/_execute -
enrich 파이프라인 설정
PUT /_ingest/pipeline/policy_test { "description" : "Enriching user details to messages", "processors" : [ { "enrich" : { "policy_name": "my-policy", "field" : "email", "target_field": "user", "max_matches": "1" } } ] } // 데이터 insert PUT /my_index/_doc/my_id?pipeline=policy_test { "email": "mardy.brown@asciidocsmith.com" } // 결과 { "found": true, "_index": "my_index", "_type": "_doc", "_id": "my_id", "_version": 1, "_seq_no": 55, "_primary_term": 1, "_source": { "user": { "email": "mardy.brown@asciidocsmith.com", "first_name": "Mardy", "last_name": "Brown", "zip": 70116, "city": "New Orleans", "state": "LA" }, "email": "mardy.brown@asciidocsmith.com" } }
-
-
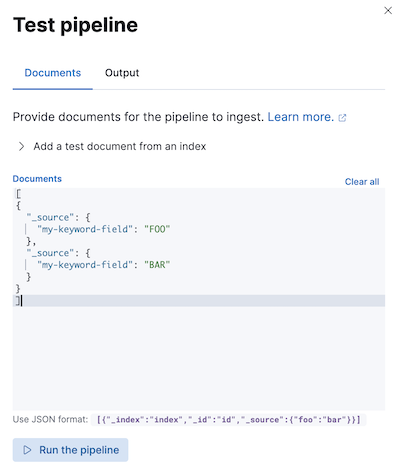
- 파이프라인 생성한 프로세스 테스트 : Stack Management > Ingest Pipelines > Edit pipeline > Add documents

발새발개
저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!