
🚩 프로젝트 개요 및 목표
개요
이번 프로젝트는 제로베이스에서 데이터 취업스쿨을 수강 중 진행한 프로젝트로 제로베이스에서 제공된 데이터를 사용했다.
활용 데이터
- 서울 범죄 데이터(제로베이스에서 제공)
- 서울 인구수 CCTV 분석 데이터 (1차시에서 했던 프로젝트 결과물)
목표
- 인구수와 범죄의 관계 파악
- CCTV 개수와 범죄의 관계 파악
- googlemaps 모듈 활용해 위치 정보 추출
- 검거율을 통한 경찰서의 검거 능력 파악
- seaborn, folium을 활용한 각종 데이터 시각화
🚩 1. 서울 범죄 데이터 살펴보기
🔎 원본파일 불러오기
 🔎 info()로 데이터를 확인 해보자.
🔎 info()로 데이터를 확인 해보자.
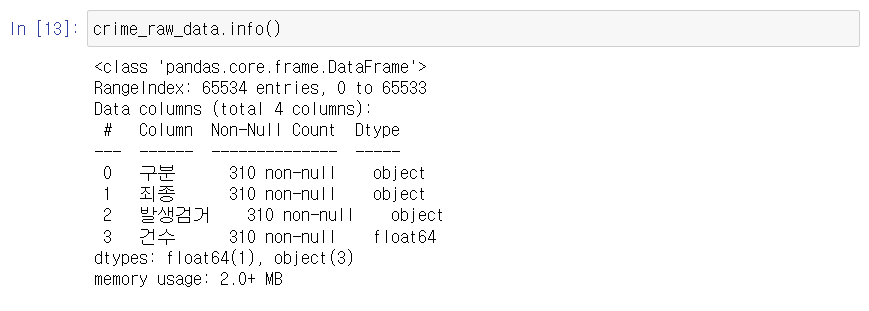
- index가 0 ~ 65533으로 나오는데 데이터 개수는 310개다.
- 뭔가 이상하니 데이터를 더 살펴 봐야한다.
- 특정 컬럼(여기서는 죄종)을 unique() 함수를 활용해 조사해보자.
- nan값이 들어 있음을 확인.
- notnull() 함수를 활용해 마스킹하자.
- 마스킹이란 원하는 조건으로 다시 데이터프레임으로 만드는 방법이다.
- 원하는 조건 : nan(null) 값은 제거한 데이터 프레임🔎 마스킹 작업

- notnull()을 사용해보니 데이터와 인덱스가 서로 310개가 잘 맞는다.
- 마스킹 후 다시 변수에 담아줘서 사용할 수 있게 해야 한다.🚩 2. 데이터 프레임 튜닝( pivot_table()활용)
🔎 pivot_table()을 활용해 데이터 프레임 튜닝
- 구분 컬럼을 인덱스로.
- 각 범죄검거, 발생으로 컬럼 구분.
=> | 구분 | 살인발생 | 살인검거 |.....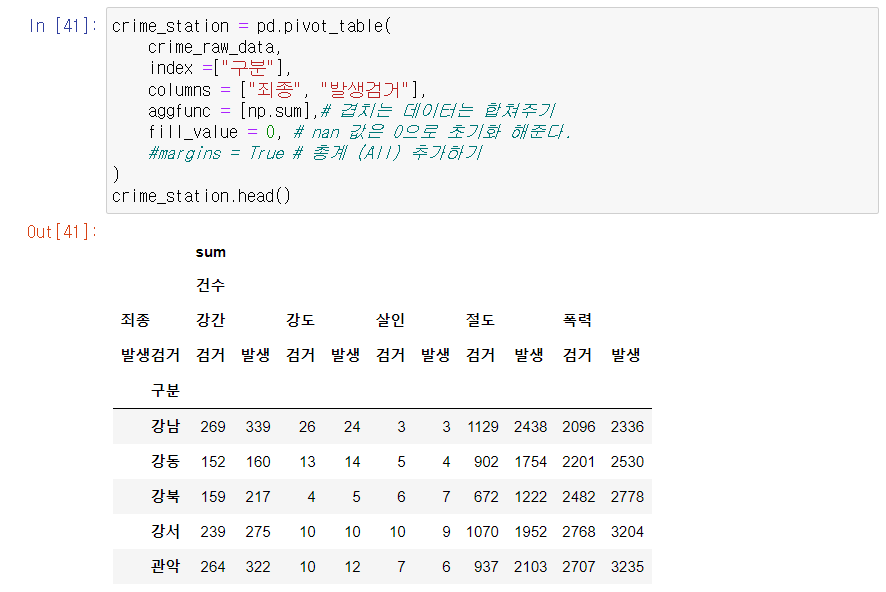
- 여기서 컬럼명을 보면 당황할 것이다.
- 이는 pivot테이블을 사용하며 컬럼명들이 합쳐졌기 때문이다.
- 이를 멀티 컬럼이라하며 불필요한 멀티 컬럼을 없애주자.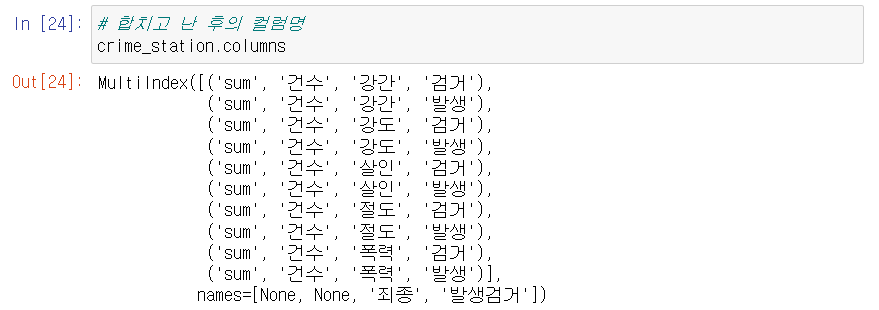
🔎 멀티 컬럼 제거 하기
- 각 컬럼명이 4개 씩 들어있다.
- 앞에 sum, '건수'는 컬럼명에서 필요가 없으니 지워주자.
- 컬럼명을 지우는 함수는 droplevel([])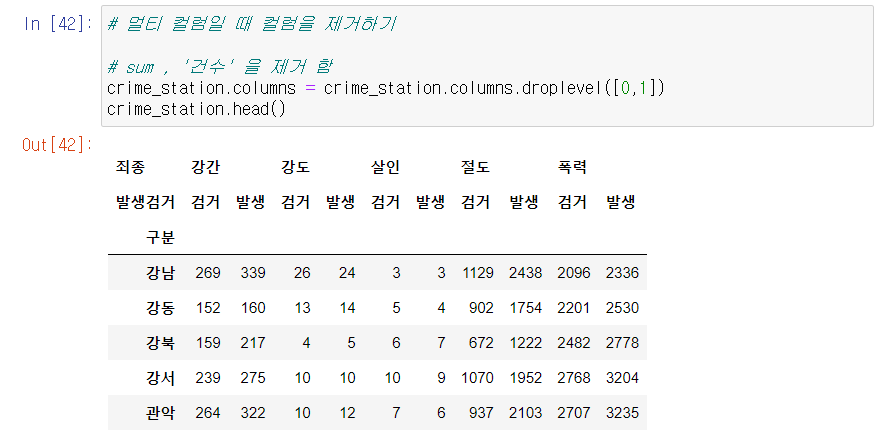
- 현재 인덱스의 정보는 각 경찰서 이름으로 되어있다.
- 각 경찰서가 어디 구에 있는지 지역구 위치정보가 필요하다.
- Google Maps API를 활용해 지역이름 찾아보자.🚩 3. 경찰서 위치 정보 찾기(Google Maps API 활용)
🔎 googlemaps 셋팅
활용 셋팅 법은 구글에 잘 나와있으니 찾아보길 바란다.
여기서는 포스팅 안하겠다.
모듈을 불러와 하나의 경찰서를 검색해보자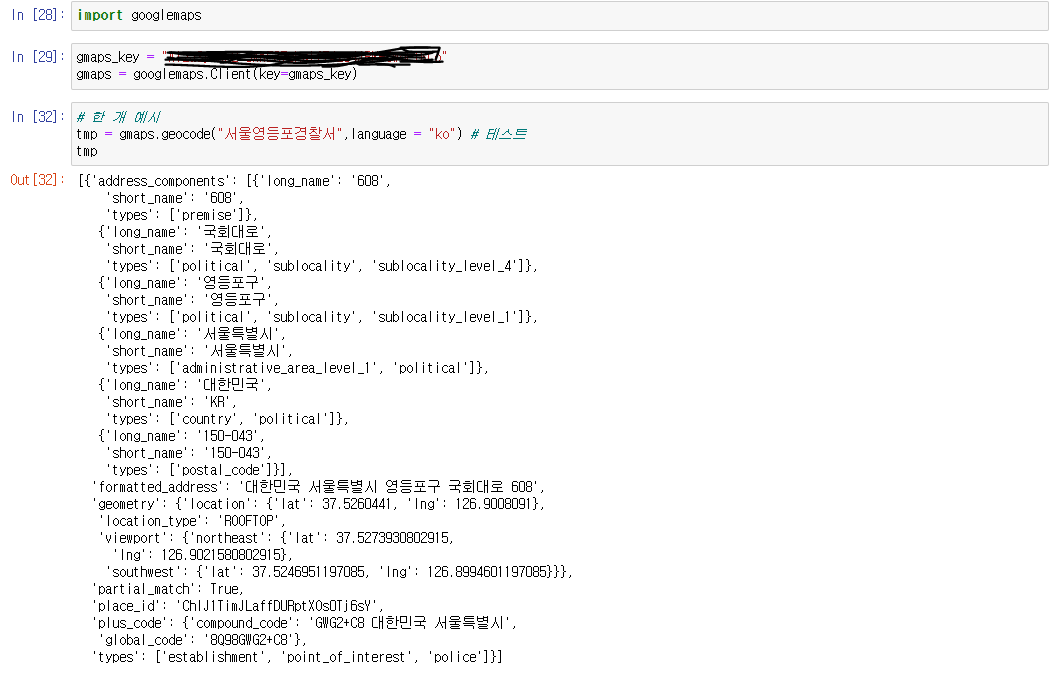
- 결과가 리스트로 나오고 안에는 딕셔너리가 들어있다.
- 리스트 요소에 접근, 딕셔너리에서 get(key)을 사용해 원하는 value(위도,경도,지역구) 값을 반환하자
🔎 경찰서 위치 정보 컬럼 추가
- 이제 원본데이터에 추가하자.
- 각 지역이름 컬럼 : 구별
- 위도 : lat
- 경도 : lng
- 이 후 전부 출력해봤더니 종암 경찰서가 제대로 추출이 안됬다.
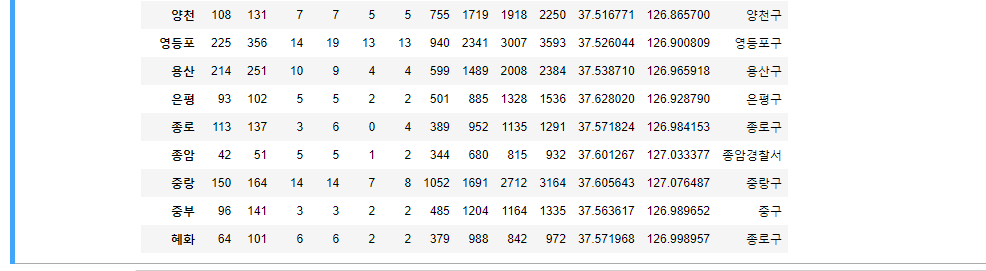
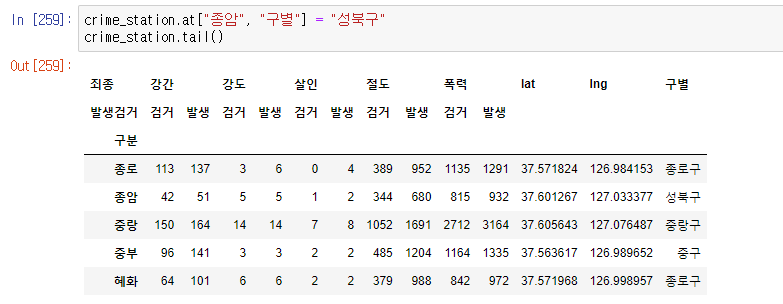
- 종암경찰서를 검색해보니 성북구에 위치해있다. 성북구로 직접 변경해주자.
🚩 4. 데이터 정리 및 추가
🔎 컬럼명 깔끔하게 정리
- 현재 각 범죄들 컬럼명이 "강도", "발생", "강도", "검거" 이렇게 따로 있다.
- 이를 강도검거, 강도발생, 살인검거, 살인발생 이런식으로 바꾸자.
- 반복작업에 리스트를 반환하니 리스트 컴프리헨션 방법을 사용해보자.
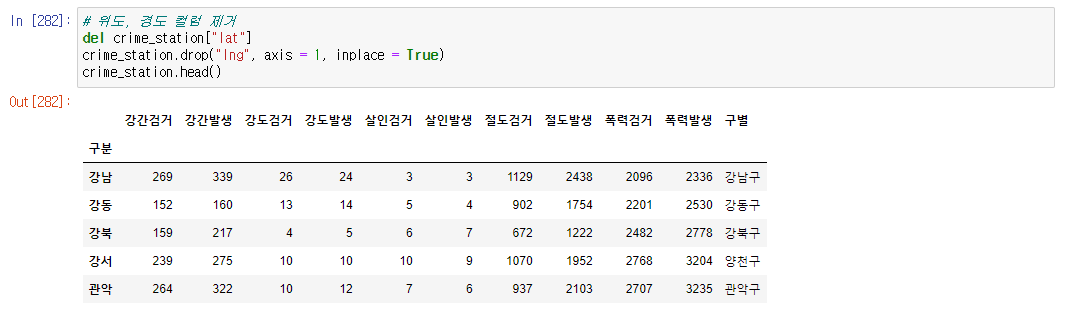
- 또한 위도, 경도 컬럼은 제거하자.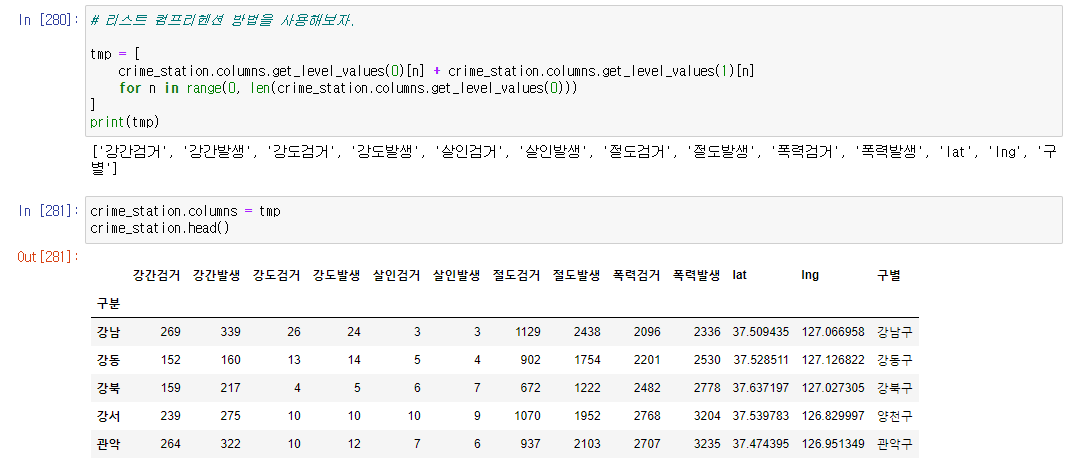
🔎 지역이름을 인덱스로 변경
- CCTV 데이터 프레임과 합치기 위해 각 구 이름이 인덱스로 오게 만들자.
- pivot_table을 활용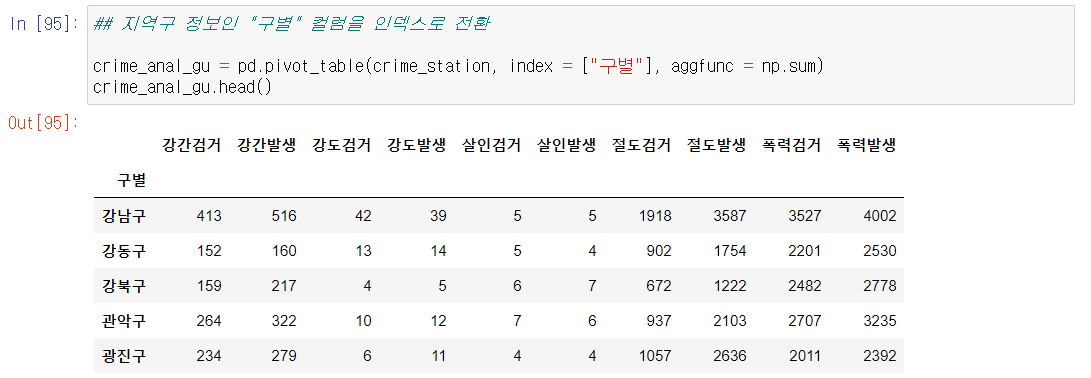
🔎 각 범죄의 검거율 컬럼 추가
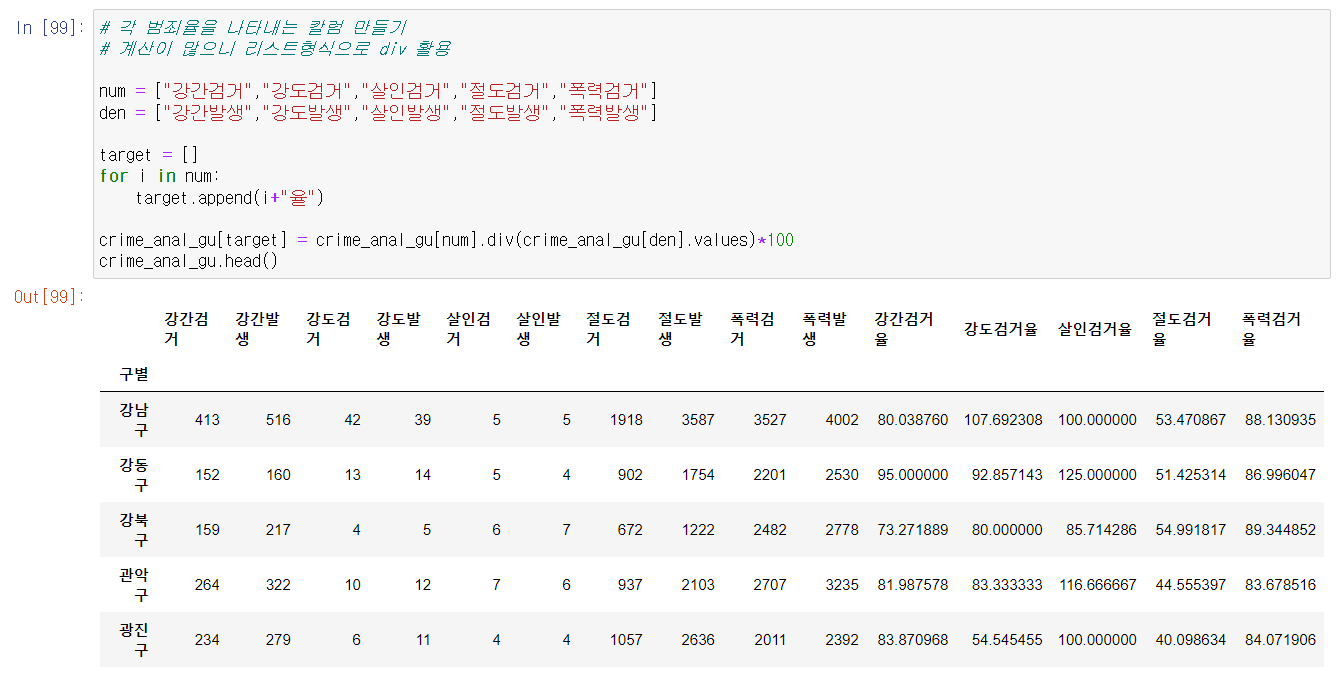
- 이제 검거 컬럼은 삭제
- 범죄발생 컬럼은 범죄 컬럼으로 치환하자
- 살인발생 => 살인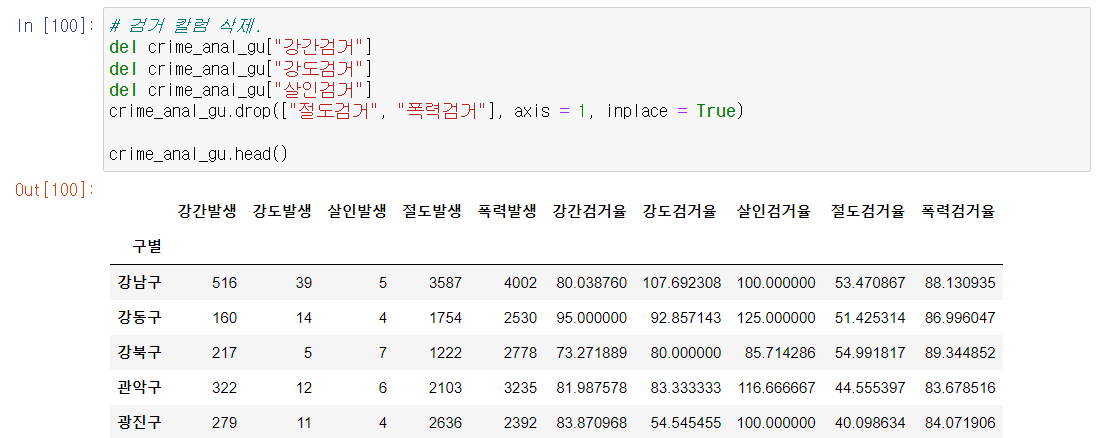
- 여기서 검거율을 잘 보면 100이상 값이 보인다.
- 상식적으로 검거율이 100이 넘을 수가 없다.
- 몇 년 전 미해결 이었던 범죄를 집계 당시 검거하면서 검거 집계수가 올라갔을 수 있다고 추측해본다.
- 일단 100이상인 검거율은 100으로 마스킹 하자.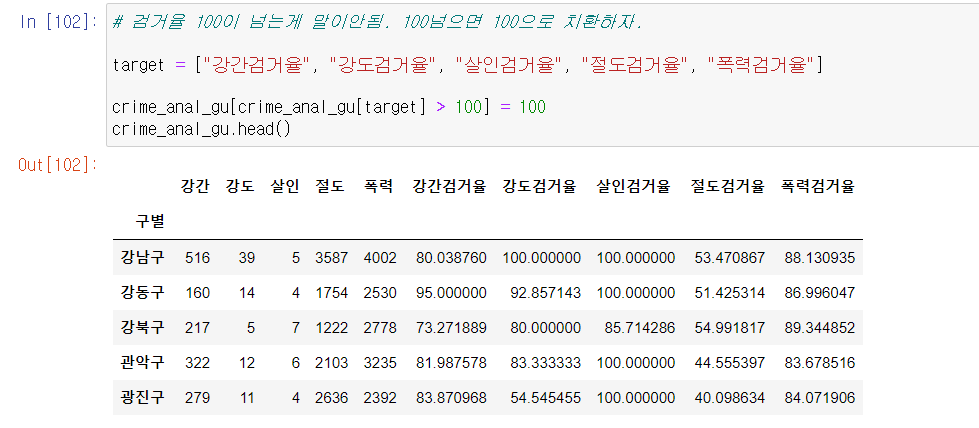
🚩 5. 데이터 튜닝 (정규화)
- 범죄 데이터 값의 천의 자리 까지 나타나서 편차가 클 경우 시각화에 어려움이 있다.
- 최고값을 1. 최소값을 0으로 정규화하는 작업을 하자.
- 각 범죄 컬럼 값들을 각 범죄컬럼의 max값으로 나누면 정규화가 된다.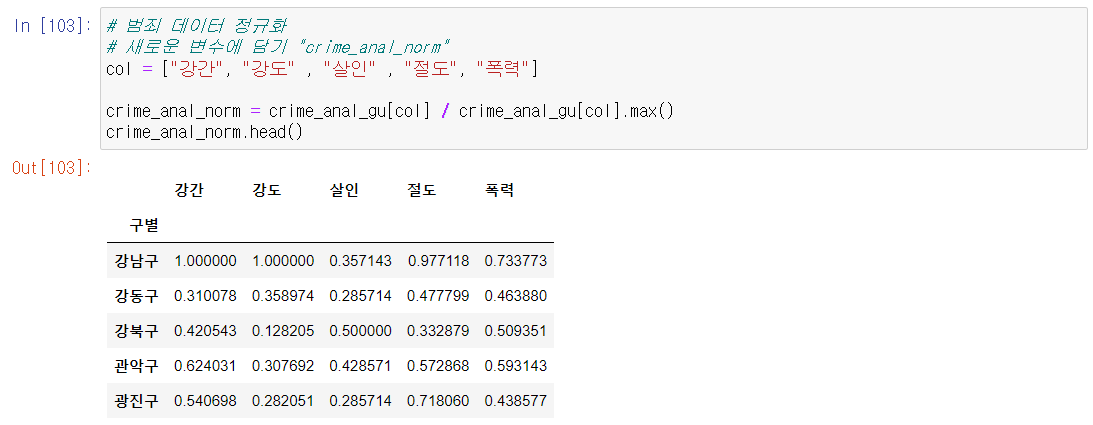
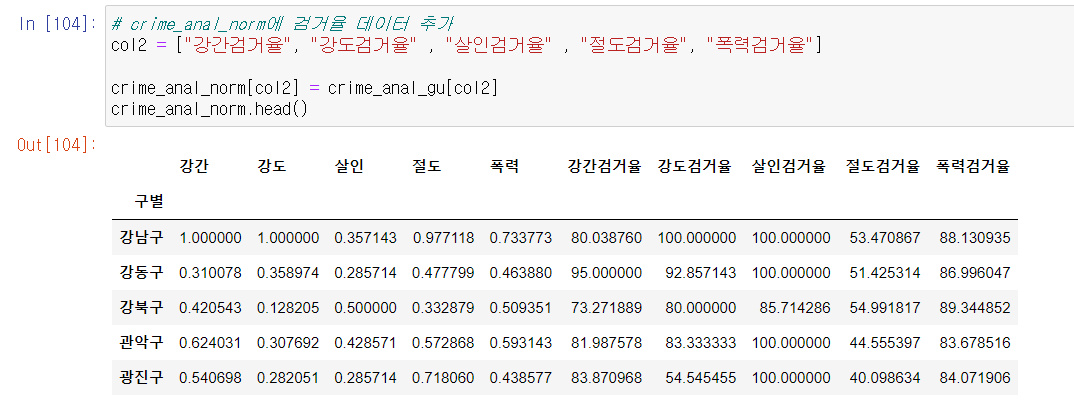
🚩 6. 데이터 추가 (1차시 결과 데이터)
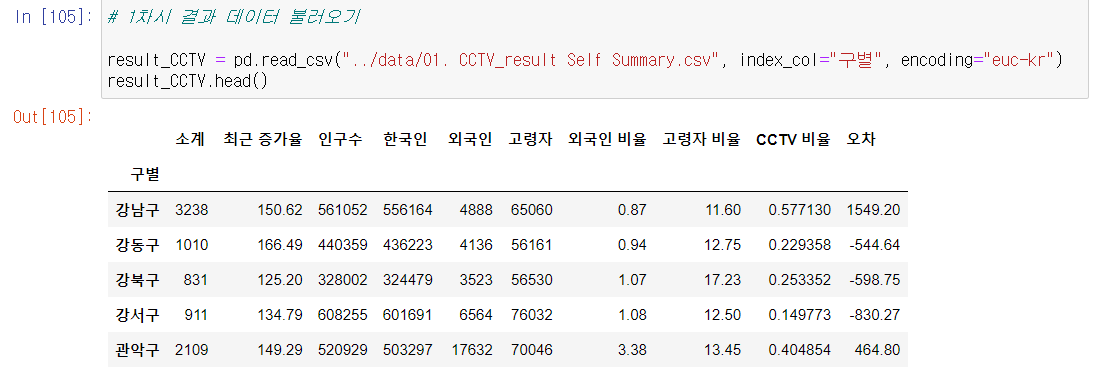
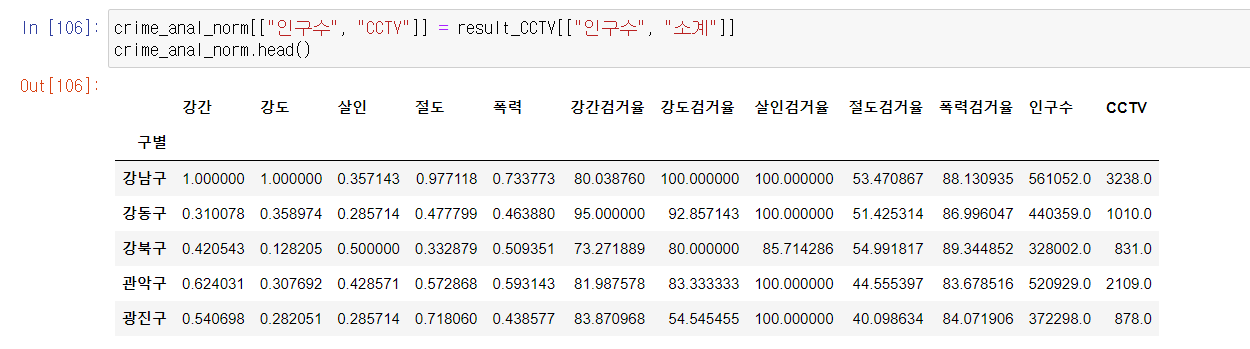
- 1차시에 했던 CCTV 자료에서 인구수와 CCTV 소계 컬럼을 추가하자.
🚩 7. 데이터 튜닝
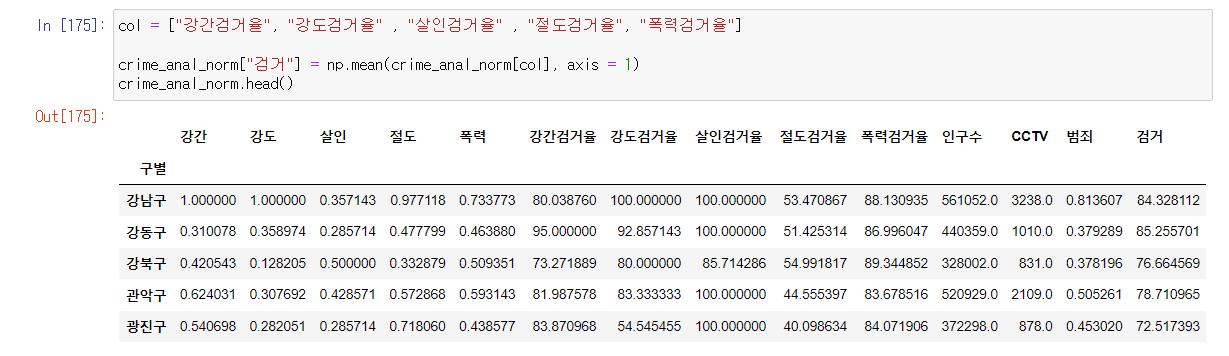
- 범죄의 종류를 다 합친 범죄 컬럼을 만들어서 경향을 비교하는게 좋을 것 같다.
- 이때 범죄 컬럼을 다 합쳐 평균을 내어 범죄 컬럼으로 만들 것이다.
- 검거율도 다 합쳐 하나의 검거 컬럼으로 만들자.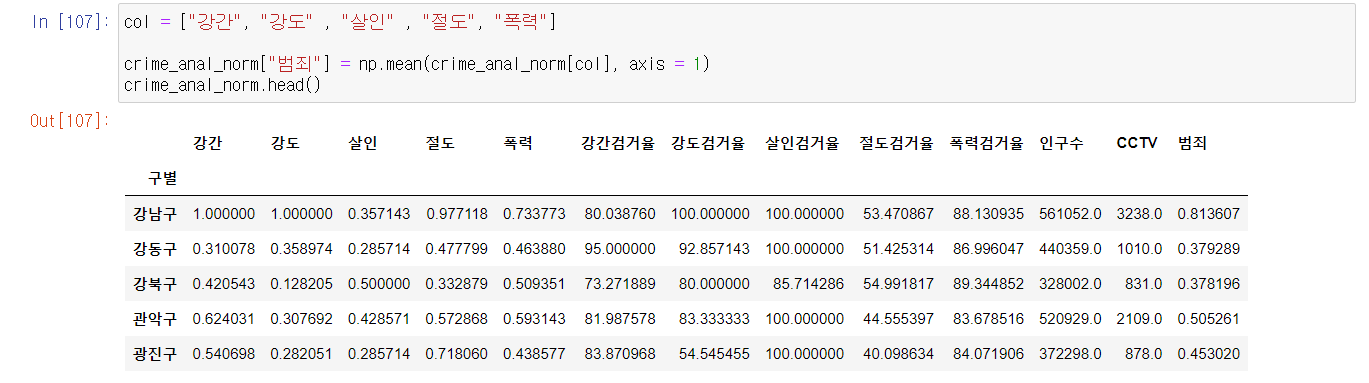
🚩 8. 저장
- 데이터 정리 및 튜닝은 어느정도 끝났다.
- 이제 시각화를 하기 전에 저장하자.
- 시각화에 앞서 seaborn, folium의 간단한 사용법을 먼저 포스트 하겠다.

코린이 공부중