
🚩 웹이란
웹은 인터넷 상에서 텍스트나 그림, 소리, 영상 등과 같은 멀티미디어 정보를 하이퍼텍스트 방식으로 연결하여 제공합니다. 하이퍼텍스트(hypertext)란 문서 내부에 또 다른 문서로 연결되는 참조를 집어 넣음으로써 웹 상에 존재하는 여러 문서끼리 서로 참조할 수 있는 기술을 의미합니다.
이처럼 기본적으로 웹사이트 여러 참조(태그)들이 얽혀있는 문서다. HTML이라는 형식으로 쓰여진 문서이다. 그래서 우리는 HTML 문서에 담긴 내용을 가져 오도록 request(요청) 해야 한다. 파이썬에는 애초에 requests라는 라이브러리로 편리하게 사용이 가능하다.
🚩 웹 스크래핑(크롤링)
웹 스크래핑(크롤링)이란 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다.
크롤링과 스크래핑의 실질적인 차이는 없지만, 일반적으로 스크랩핑은 하나의 페이지를 수집하는 것이며, 크롤링은 동적으로 웹페이지를 돌아다니면서 수집하는 것을 말한다.
공통된 목적으로 '우리가 정한 특정 웹 페이지에서 데이터를 추출하는 것'이다. 우리가 특정 주제의 뉴스만을 가져오거나, 인기 검색어 정보를 가져오는 것, 어떤 상품의 가격을 모니터링하는 것 모두 웹 스크래핑, 크롤링이다.
여기서는 beautiful soup이라는 라이브러리를 사용해 크롤링을 진행해 볼 것이다.
🚩 beautiful soup 이란
beautiful soup이란 파이썬에서 사용할 수 있는 웹데이터 크롤링 라이브러리다. beautiful soup을 사용하기 위해선 html의 태그를 사용하여 크롤링하기 때문에 html태그에 대한 기초적인 이해가 필요하다. 아래에서 beatiful soup을 활용하여 간단한 html의 기능을 살펴보자.
🚩 beautiful soup 기초
🔎 예시 html 사이트
예로 공부해볼 test_sam.html을 켜보면 다음과 같다.

🔎 beautiful soup로 html 불러오기
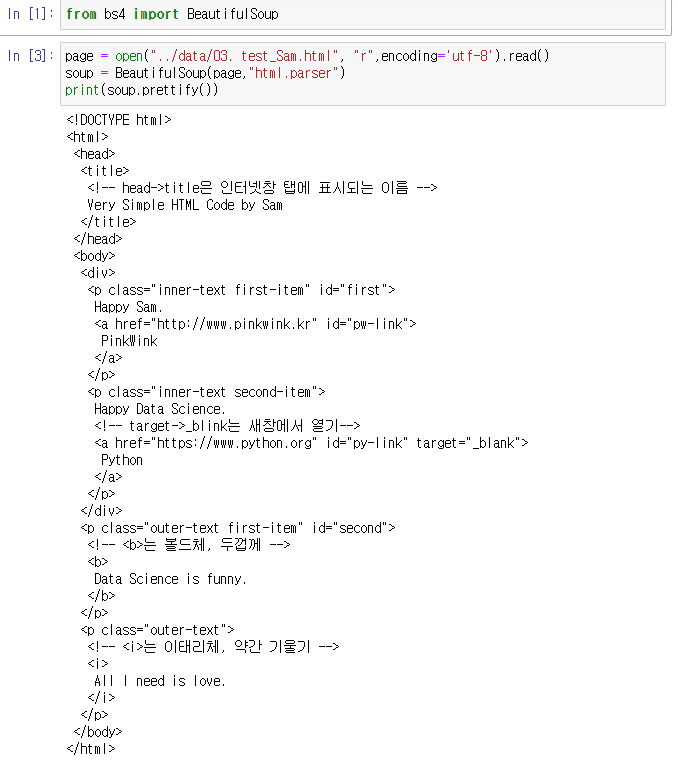
<p class="inner-text first-item" id="first">
Happy Sam.
<a href="http://www.pinkwink.kr" id="pw-link">위의 문구를 예시로 공부해보자.
여기서
p : 태그
class="inner-text first-item" : 속성
id="first" = ID
Happy Sam : 텍스트
href : 주소 속성
라고 한다.
여기서 중요한 점은 id는 고유값으로 id는 하나뿐이다. 즉, 찾을 때 아이디로 찾으면 바로 찾을 수 있다. id가 없으면 직접 추출해야한다. 추출 방식은 find와 select가 있다.
🔎 find()
- find 함수는 html의 내용을 위에서부터 읽어내려오면서 P 라는 태그를 발견하면 그 값을 반환하고 종료하는 방식이라고 생각하면 된다.

- 속성을 추가하면 더 자세하게 추출할 수 있다.

- ID로도 추출할 수 있다.

- 뒤에 .text를 붙이면 텍스트를 추출한다.

🔎 find_all()
- 찾는 태그의 모든 정보를 리스트에 담아서 반환해준다.

- 당연한 말이지만 자세하게 적을 수록 자세하게 추출 가능.
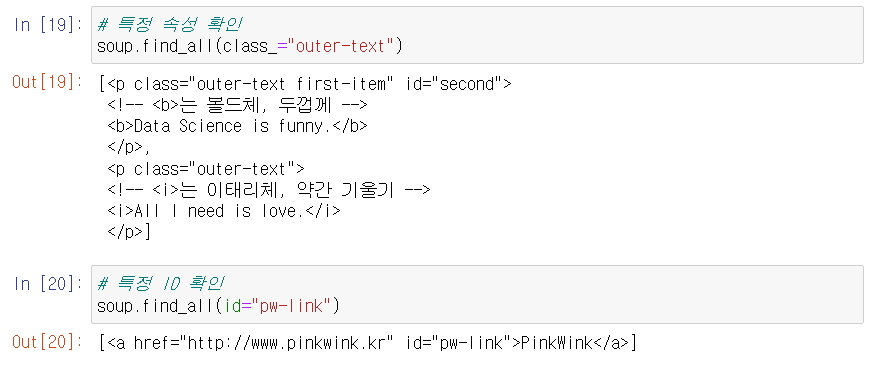
🔎 href로 주소 찾기
- 찾은 정보 뒤에 ["href"] 를 붙여주면 주소가 나온다.

🔎 select()
- find_all()이랑 동일한 기능을 한다. 찾는 태그의 모든 정보를 리스트에 담아준다.

🔎 select_one()
- find()와 동일한 기능을 한다. 하나의 태그만 불러온다.

- 속성, 아이디, 하위 정보 검색 방법
속성을 검색할땐 (.)점, 아이디를 검색할땐 (#)을 붙인다.
또한 하위 영역을 표시할땐 (>) 로 나타낸다.ex)
아이디를 사용할 경우 : #first > a, ID가 first인 태그 하위에 a 태그들을 불러와라.(ID 하위의 a 태그)
class를 사용할 경우 : .second-ex > a, second 속성 하위에 a 태그들을 불러와라. (class 하위의 a 태그)🔎 find vs select
-
import 모듈
- find : urllib.request
- select : requests -
find, find_all VS select, select_one
- find_all, select : 다중 선택 - 리스트 반환
- find, select_one : 단일 선택 - 하나의 정보만 반환
🔎 웹사이트 불러들이기
우리가 크롤링을 할때 사이트와 HTTP 통신을 한다고 한다. HTTP 통신은 Request(요청)과 Response(응답)으로 이루어 진다. 즉, 크롤링하는 주체는 요청자(클라이언트)이다. 그리고 요청을 받은 사이트가 응답하는 구조인 것이다.
코드 형식
요청 -> 응답 -> 원하는 작업 이렇게 진행된다. -> req = Request(url) # 요청할 주소를 req에 담는다. 요청 형식을 만든다. -> res = urlopen(req) # urlopen으로 요청한 주소를 열어 HTTPResponse 객체를 반환한다.(반환 받는다) -> soup = Beautiful(respone, "html.parser) # 반환받은 HTTPResponse 객체에서 html 코드를 읽어들인다.
예시 사진

다음 포스트에서는 beautifulsoup을 활용한 간단한 예제들을 풀어보겠다.
