YOLO v11 Segmentation [논문 리뷰]
Segmentation model [논문 리뷰]
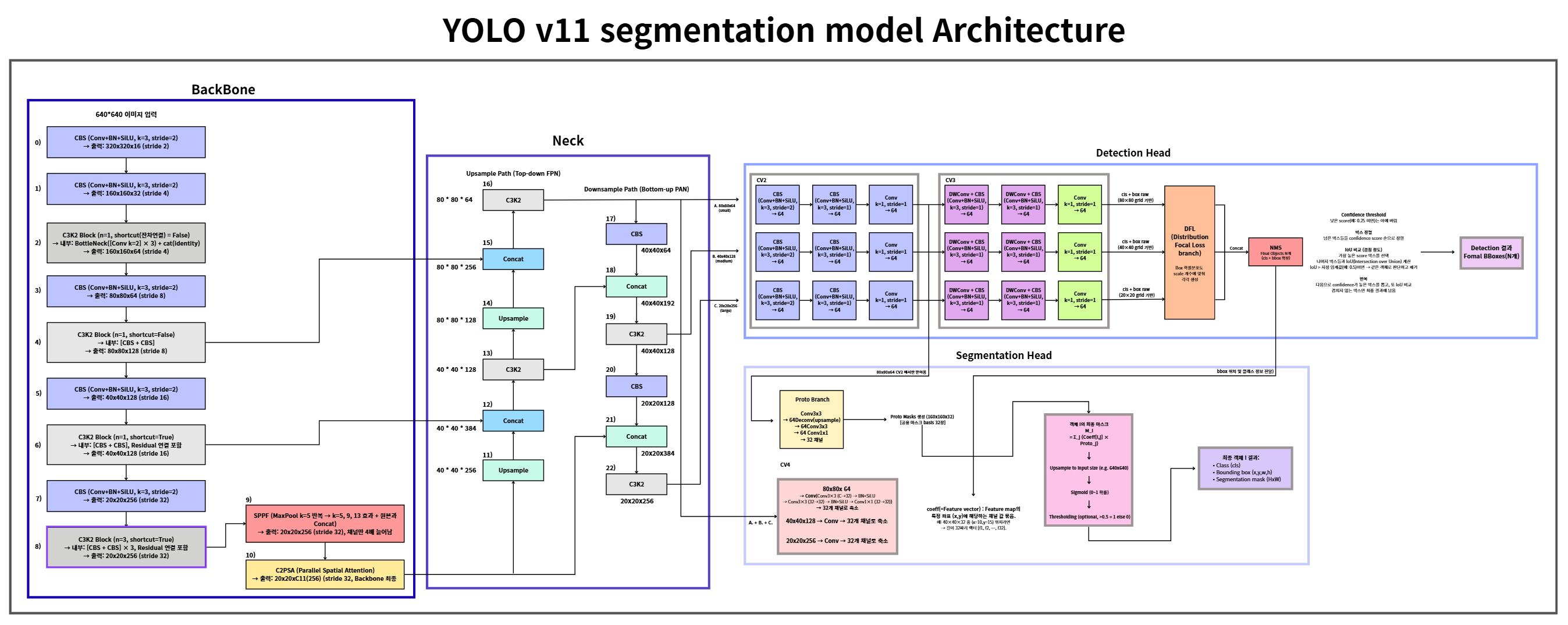
YOLO 시리즈는 객체 탐지(Object Detection)에서 시작해, 이제는 세그멘테이션(Segmentation)까지 확장된 대표적인 모델입니다.
하지만 YOLO v11 Segmentation 전체 아키텍처를 한눈에 확인할 수 있는 자료가 없었습니다.
이번 글에서는 직접 구조를 분석하고 도식화한 YOLOv11-Seg Full Architecture를 기반으로,
Backbone → Neck → Detection Head → Segmentation Head까지 전체 과정을 정리해보겠습니다.
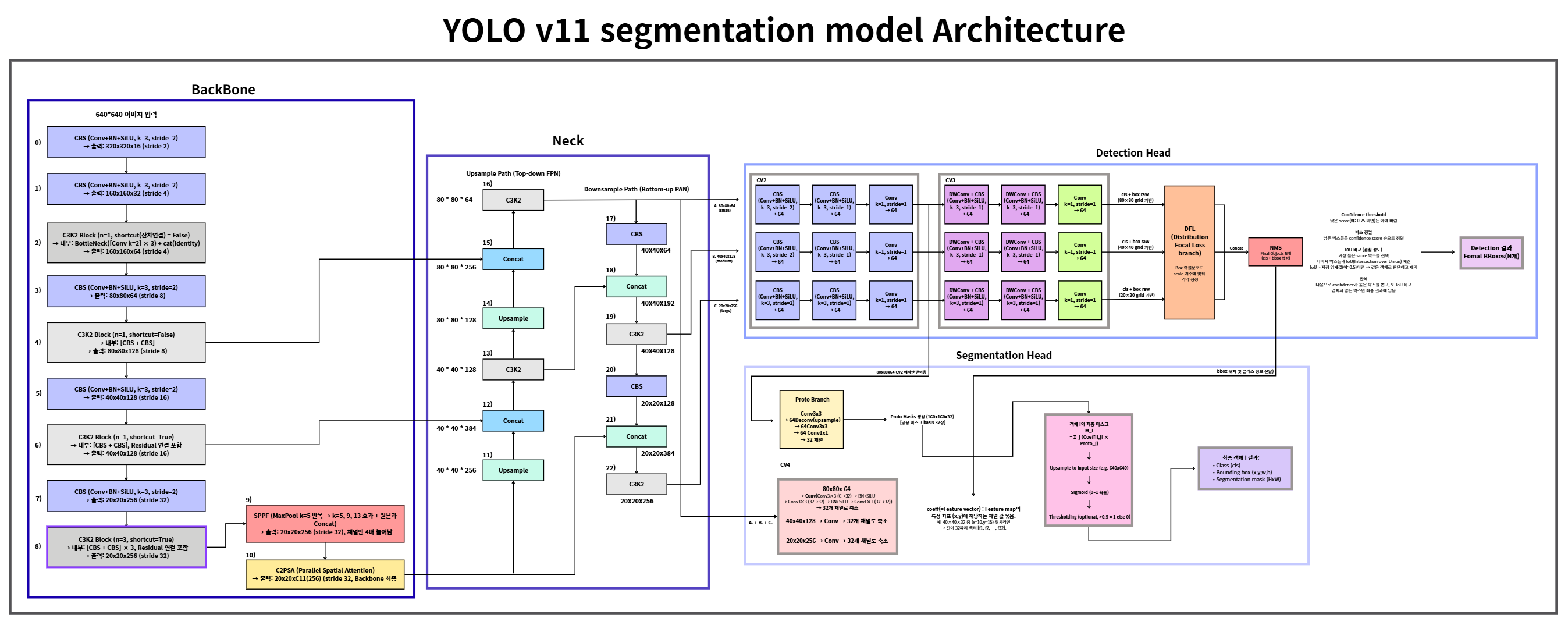
Backbone
Backbone은 입력 이미지를 받아 점차 해상도를 줄여가며 특징을 뽑아내는 역할을 합니다.
- 입력 크기:
640 × 640 × 3 - 주요 블록
CBS: Conv + BN + SiLUC3k2 Block: 병렬 conv 구조, 일부 residual 연결 포함SPPF: 다양한 receptive field 확보C2PSA: YOLO v11에서 새롭게 추가된 Parallel Spatial Attention 모듈
Backbone을 거치면 최종적으로 20 × 20 × 256 feature map이 생성되고, 이게 Neck으로 전달됩니다.
Neck (FPN + PAN)
Neck은 FPN과 PAN 구조를 결합해 멀티 스케일 feature를 만듭니다.
-
FPN (Top-down)
- 고레벨 feature를 업샘플링해 저레벨 feature와 결합
-
PAN (Bottom-up)
- stride=2 Conv로 다운샘플링하며 정보 보강
최종적으로 3가지 크기의 feature가 만들어집니다.
80 × 80(small object)40 × 40(medium object)20 × 20(large object)
Detection Head
Detection Head는 각 스케일 feature에서 클래스와 바운딩 박스를 예측합니다.
- cv2: 입력 feature 채널 정규화
- cv3: Depthwise + Pointwise Conv 조합 →
cls + box raw출력 - DFL (Distribution Focal Loss)
- 좌표를 단순 수치가 아니라 분포 형태로 학습
- 박스 위치를 더 정밀하게 보정
- NMS (Non-Maximum Suppression)
- 겹치는 박스 중 confidence가 높은 것만 남김
Detection Head의 최종 출력: N개의 객체 후보 (cls + bbox)
Segmentation Head
세그멘테이션은 YOLO에서 독특하게 Proto + Coeff 방식을 사용합니다
Proto branch
- 입력:
80 × 80 × 64 - ConvTranspose → 업샘플 →
160 × 160 × 32 proto mask생성 - Proto mask = 모든 객체가 공유하는 basis mask 집합
Coeff branch (cv4)
- 입력: Neck의 multi-scale feature (
80×80,40×40,20×20) - Conv 연산 →
32채널 feature map - Detection Head에서 확정된 bbox 위치 → 객체별 coeff 벡터 (길이 32) 추출
최종 마스크
객체 i의 마스크는 계산방식:
[ Mi = \sum{j=1}^{32} \text{Coeff}[i,j] \times \text{Proto}_j ]
즉, proto 32장을 coeff 비율대로 섞어 최종 instance mask를 만듭니다.
최종 출력
YOLO v11 Segmentation의 최종 결과
- Class (cls): 객체 레이블
- Bounding box (x, y, w, h): 위치와 크기
- Segmentation mask (H × W): 픽셀 단위 객체 영역
최종적으로 각 객체는 (cls, bbox, mask) 세트로 출력됩니다.
비유
- Proto mask: 팔레트에 놓인 32가지 기본 색
- Coeff: 색을 섞는 비율 (예: 빨강 20%, 파랑 70%, 초록 10%)
- Final mask: 팔레트의 색을 섞어 만든 고유한 그림
이 방식 덕분에 객체마다 새로운 마스크를 CNN으로 직접 생성하지 않고도 효율적으로 instance mask를 얻을 수 있습니다.
마무리
YOLO v11 Segmentation은
- Backbone에 C2PSA를 적용해 특징 표현을 강화했고,
- Head에서는 Proto × Coeff 구조를 통해 효율적인 세그멘테이션을 구현했습니다.
덕분에 객체 탐지와 세그멘테이션을 동시에 처리하면서도
연산 효율과 정확도의 균형을 잡을 수 있는 구조가 완성되었습니다.
이번에 정리한 아키텍처는 아직 공식 문서나 논문 어디에도 정리된 적이 없기 때문에,
YOLO v11 객체 탐지 모델과 함께 Segmentation을 이해하거나 연구할 때 꽤 도움이 될 것이라 생각합니다.
