FocalTransNet: A Hybrid Focal-Enhanced Transformer Network for Medical Image Segmentation [논문 리뷰]
Segmentation model [논문 리뷰]
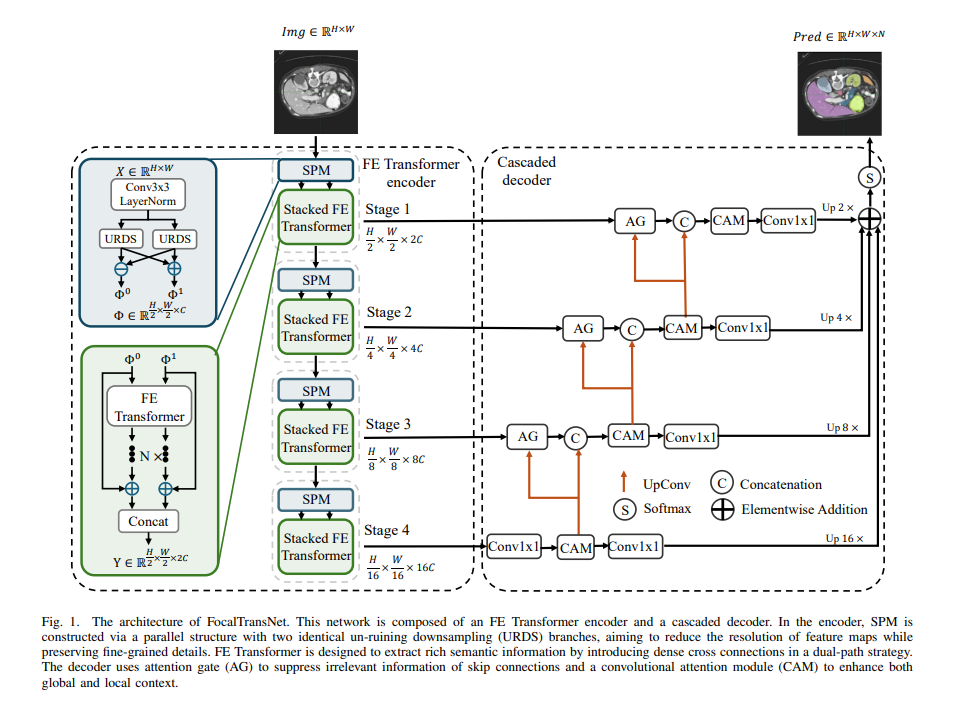
FocalTransNet 인코더 구조 정리 (SPM + FE Transformer)
원문 해석
의료 영상은 노이즈와 아티팩트 때문에 대비(contrast)가 낮고, 경계(edge)가 흐릿한 경우가 많습니다. 게다가 장기나 조직은 모양도 다양하고 분포도 복잡합니다. 그래서 관심 영역(ROI)을 정확히 분할하려면, 모델이 로컬(local) 특징과 글로벌(global) 문맥을 동시에 잘 이해할 수 있어야 합니다.
현재 많은 연구들이 트랜스포머와 CNN을 결합해서 이 능력을 키우려 하지만, 대부분은 단순히 스킵 연결이나 병목 계층에 트랜스포머를 넣는 정도에 그칩니다. 이런 방식은 로컬/글로벌 특징의 상호작용이 충분하지 않아서, CNN과 트랜스포머의 보완적 장점과 시너지 효과를 다 살리지 못합니다.
→ 이 문제를 풀기 위해, 저자들은 FE Transformer라는 새로운 하이브리드 특징 추출 모듈을 제안했습니다. 이 모듈은 CNN과 Self-Attention을 이중 경로(dual-path)로 함께 사용해서 로컬/글로벌 특징을 동시에 잡아냅니다. 또 두 경로를 촘촘한 크로스 연결(dense cross-connections)로 연결해서 상호작용과 융합을 강화했습니다. 실험(섹션 VI-B)과 비교 연구를 통해 이 모듈의 효과를 검증했습니다.
계층적 특징 추출 과정에서 다운샘플링은 연산 효율을 높이고 리셉티브 필드를 확장하는 데 꼭 필요합니다. 하지만 기존의 풀링, 선형 프로젝션, 스트라이드 합성곱 같은 방법들은 세밀한 정보 손실 문제가 있습니다. 그런데 이 디테일은 의료 영상 분할에서 정말 중요합니다. 예를 들어, 미묘한 질감이나 경계 정보가 비슷한 조직을 구분하는 핵심일 수 있습니다.
→ 이를 해결하기 위해 저자들은 SPM(Symmetric Patch Merging) 모듈을 제안했습니다. 이 모듈은 다운샘플링된 특징과 원본 특징의 차이를 활용해, 세밀한 정보 보상 메커니즘을 만듭니다. 또 Difference Map을 추가해서, 미묘한 패턴 구분에 도움이 되는 고주파(high-frequency) 신호를 강조하고, 모델이 고주파 디테일에 더 민감하게 반응하도록 합니다. 섹션 VI-A에서 이 모듈의 성능을 비교/분석했고, 다양한 딥러닝 모델에 플러그-앤-플레이로 적용 가능하다는 걸 보여줍니다.
이번 글에서는 FocalTransNet 논문에서 제안된 핵심 모듈들의 구조와 동작 과정을 정리한다.
일단, 크게 보면 네 가지 모듈로 나눌 수 있습니다:
- SPM (Symmetric Patch Merging)
- FE Transformer
- AG (Attention Gate)
- CAM (Convolutional Attention Module)
1. SPM (Symmetric Patch Merging)
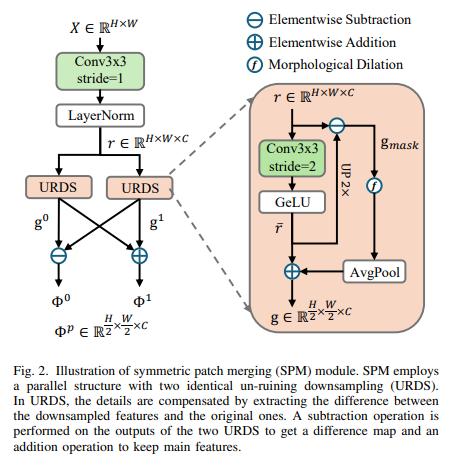
SPM은 단순 다운샘플링(pooling, stride conv 등)에서 발생하는 세밀한 정보 손실 문제를 해결하기 위해 제안된 모듈이다.
동작 과정
- 입력 특징 맵 X (크기: H×W) → 3×3 Conv + LayerNorm
→ 3×3 Conv + LayerNorm을 적용하여 채널 확장 및 정규화 - 두 개의 URDS(Un-Ruining DownSampling) 모듈을 병렬 구조로 배치
- 각 URDS: 입력을 스트라이드 2 Conv로 다운샘플링
- 다운샘플링된 특징과 원본을 비교하여 Difference Map 생성 → 디테일 복원
- 두 URDS 출력은 교차 연결 연산으로 결합
- 뺄셈(Subtraction) → 고주파(high-frequency) 성분 강조 (경계, 작은 패턴 등)
- 덧셈(Addition) → 저주파(low-frequency) 성분 유지 (전체 구조)
- 최종 출력: 두 개의 특징 맵
즉, 해상도를 절반으로 줄이면서도 세밀한 디테일을 최대한 보존하는 다운샘플링 방식이다.
2. FE Transformer
FE Transformer는 CNN과 Transformer의 장점을 모두 결합하는 Dual-path 구조로 설계되었다.
기존 하이브리드 네트워크가 단순히 두 모듈을 이어 붙이는 수준이었다면,
FE Transformer는 두 경로 간 촘촘한 교차 연결(Dense Cross-connections)을 통해
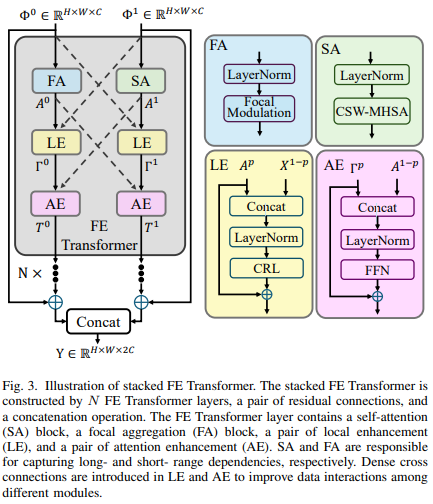
FE Transformer는 크게 네 가지 블록으로 나뉜다:
-
SA (Self-Attention Block)
- 장거리 의존성(long-range dependencies)을 포착
- Cross-shaped Window 기반 Multi-Head Self-Attention(CSW-MHSA)을 사용
- 전역 문맥(global context)을 강화하는 역할
-
FA (Focal Aggregation Block)
- 로컬 패턴 및 짧은 거리 의존성(short-range dependencies)을 포착
- Depthwise Convolution 기반으로 국소적인(high-frequency) 디테일 학습
- Self-Attention이 놓칠 수 있는 미세 구조 보완
-
LE (Local Enhancement Block)
- CNN 경로와 Transformer 경로 간의 특징을 교차 연결
- 입력 두 가지를 합쳐서 중요한 로컬 특징을 보강
- Cross-Region Learning(CRL) 모듈을 활용해 상호작용 강화
-
AE (Attention Enhancement Block)
- Attention 기반 특징을 더 깊게 강화
- Fully Connected Feed-Forward Network(FFN)을 활용
- 다른 경로에서 온 특징과 합쳐져 더 풍부한 표현 생성
동작 과정
- 입력: SPM에서 얻은 두 특징 맵 (\Phi^0, \Phi^1)
- 내부적으로 두 개의 경로를 동시에 수행
- CNN 경로 (FA 중심) → 로컬 특징 추출 (경계, 질감 등 세밀한 정보)
- Transformer 경로 (SA 중심) → 글로벌 특징 추출 (장거리 의존성, 전역 문맥)
- 두 경로는 LE / AE 블록을 통해 상호작용
- LE: 로컬 차원에서 두 경로 특징을 합쳐서 상호작용
- AE: Attention 차원에서 두 경로 특징을 합쳐 더 정교한 표현 생성
- Dense Cross-connections로 경로 간 연결을 촘촘하게 구성하여 정보 손실 최소화
- N개의 FE Transformer Layer를 스택 형태로 반복 적용
- 최종적으로 두 결과를 Concat
추가 설명
-
SA 블록: 전역 문맥(Global Context)을 이해하는 핵심 모듈
-
FA 블록: 국소적(Local) 디테일을 보완하는 CNN 기반 모듈
-
LE/AE 블록: 두 경로 사이의 정보 교환을 촘촘히 만들어 시너지를 극대화
-
스택 구조: 단일 블록보다 반복적으로 쌓아 올리며 더 강력한 표현 학습 가능
-
논문 내에서의 FE Transformer 모듈의 논의 내용에 해당하는 이미지는 바로 아래를 참조
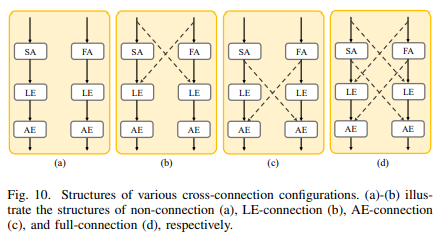
FE Transformer는 단순히 CNN과 Transformer를 붙여놓는 게 아니라, 로컬(local)과 글로벌(global) 특징을 깊게 융합한다는 점에서 차별화된다.
3. AG (Attention Gate)
Attention Gate는 디코더 단계에서 스킵 연결로 전달되는 불필요한 정보를 걸러내고, 중요한 특징만 통과시키는 역할을 한다.
동작 과정
- 인코더에서 넘어온 스킵 연결 특징을 입력으로 받음
- 이전 단계 디코더의 출력(업샘플된 특징)을 게이트 신호로 사용
- 두 입력을 비교하여 유용한 특징만 통과, 불필요한 특징 억제
- 결과적으로 잡음을 제거하고 의미 있는 정보만 디코더에 전달
AG는 “필요한 손님만 들여보내는 문지기” 같은 역할을 한다.
4. CAM (Convolutional Attention Module)
CAM은 디코더 단계에서 AG를 거친 특징을 더 정제하는 모듈로,
채널 어텐션 + 공간 어텐션을 동시에 적용한다.
동작 과정
- 입력 특징 맵에 Channel Attention 적용 → 어떤 채널(특징 종류)이 중요한지 학습
- Spatial Attention 적용 → 이미지 안에서 어떤 위치가 중요한지 학습
- 두 어텐션 결과를 결합 → 중요도가 높은 채널과 위치만 강조
- 최종적으로 강화된 특징 맵을 생성 → 1×1 Conv로 확률 맵 산출
CAM은 “중요한 채널과 위치에 스포트라이트를 비춰주는 모듈”이라고 이해할 수 있다.
5. 전체 흐름
- 입력 영상 (X)
↓ - SPM (URDS 포함) → 다운샘플링 + 디테일 보존
↓ - FE Transformer → CNN + Transformer Dual-path 융합
↓ - 인코더 출력이 디코더로 전달
↓ - AG → 스킵 연결에서 불필요한 정보 제거
↓ - CAM → 채널·공간 차원에서 중요한 정보 강조
↓ - 업샘플링 + 1×1 Conv → 각 단계 확률 맵 생성
↓ - 모든 단계 확률 맵을 합쳐 최종 세그멘테이션 결과 출력
최종 정리
- SPM: 다운샘플링 중 디테일 보존
- FE Transformer: 로컬+글로벌 특징 깊은 융합
- AG: 스킵 연결에서 불필요한 정보 차단
- CAM: 채널/공간 어텐션으로 중요한 특징 강조
- → FocalTransNet은 작은 디테일부터 전역 문맥까지 모두 반영해 높은 성능을 달성한다.
각 SPM, FE Transformer 등의 모듈에 대한 논의 내용은 자세하게 작성하지 않았기에 글에서 이해가 부족한 부분은 직접 찾아보는 것을 추천합니다.
마지막으로 한계점으로는, 완전 지도학습 방식이라 라벨된 데이터가 필요했으며, 의료 영상은 조직/장기 다양성과 복잡한 구조로 인해 수작업 라벨링 비용이 매우 크고 품질 관리에 어려움이 있었다고 합니다.
