
머신러닝 / 딥러닝 할 때 성능지표를 보는게 중요함!
그래서 이번 happy_face 하면서 성능지표 나온거에 대해
왜 이게 중요하며 어떻게 나온지 한번더 정리하기로함!
성능지표
딥러닝 모델은 단순히 "공부를 했다"는 것만으로는 부족함.
얼마나 정확하게(Precision), 하나도 놓치지 않고(Recall), 균형있게(F1-score)
찾아내느냐가 실전 사용의 핵심이기 때문임.
그래서 runs파일 -> 라벨안에 있는 지표들은 모델의 '성적표'와 같다.
Results.png
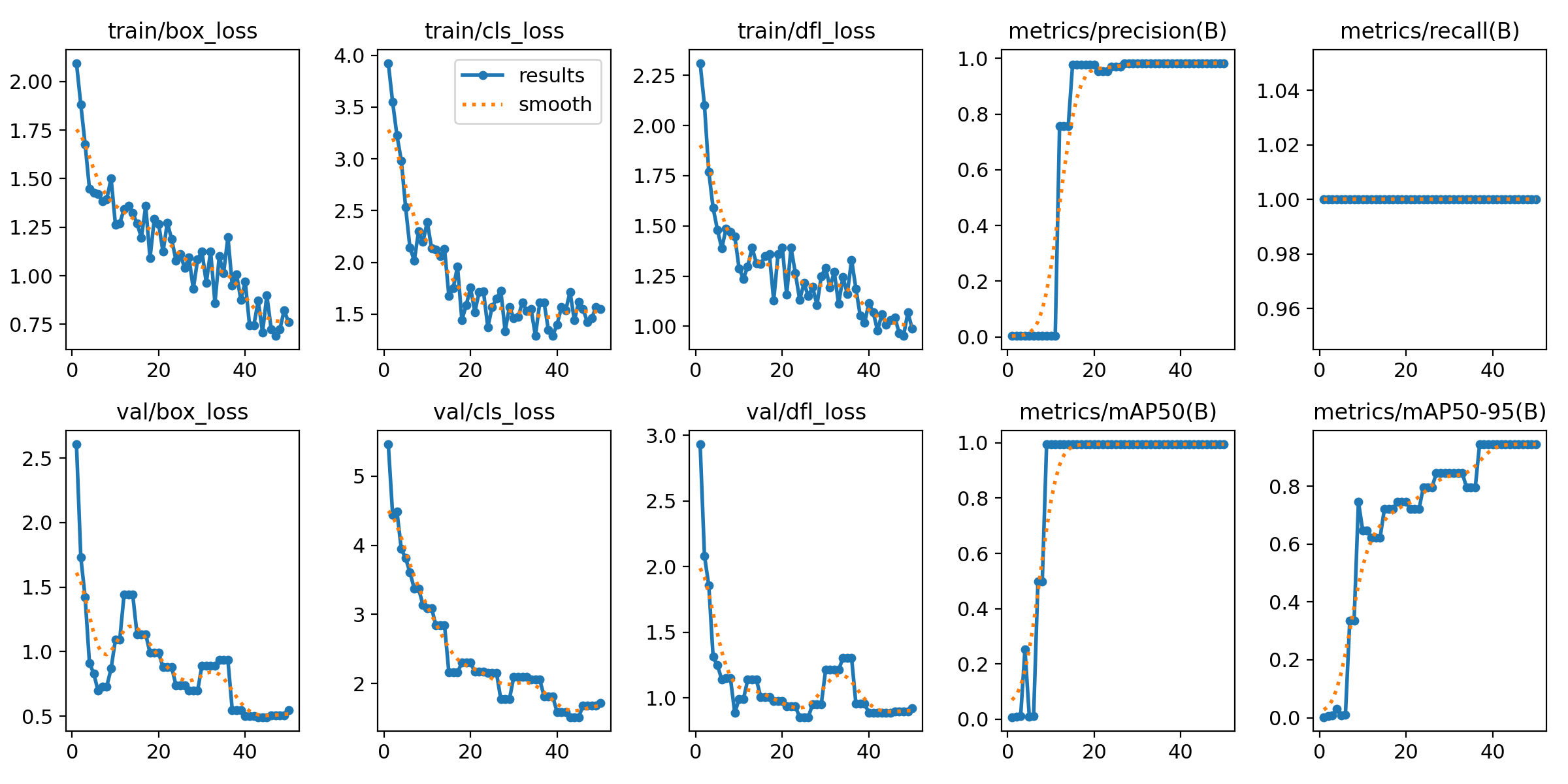
가장 먼저 봐야할 전체 흐름도!
- loss(손실) : 왼쪽의 train/box_loss, cls_loss 등 그래프가 아래로 같이 떨어지고 있음. 이 모델이 정답과 예측의 차이를 줄여나가며 잘 학습했다는 뜻임.
- Metrics(성능) : 오른쪽의 mAP50그래프가 급격히 상승해 1.0(100%)에 도달했음. 이건 모델이 학습 데이터에 대해서는 완벽하게 잘맞히고 있다는걸 의미함.
Precision-Recall(PR) 곡선
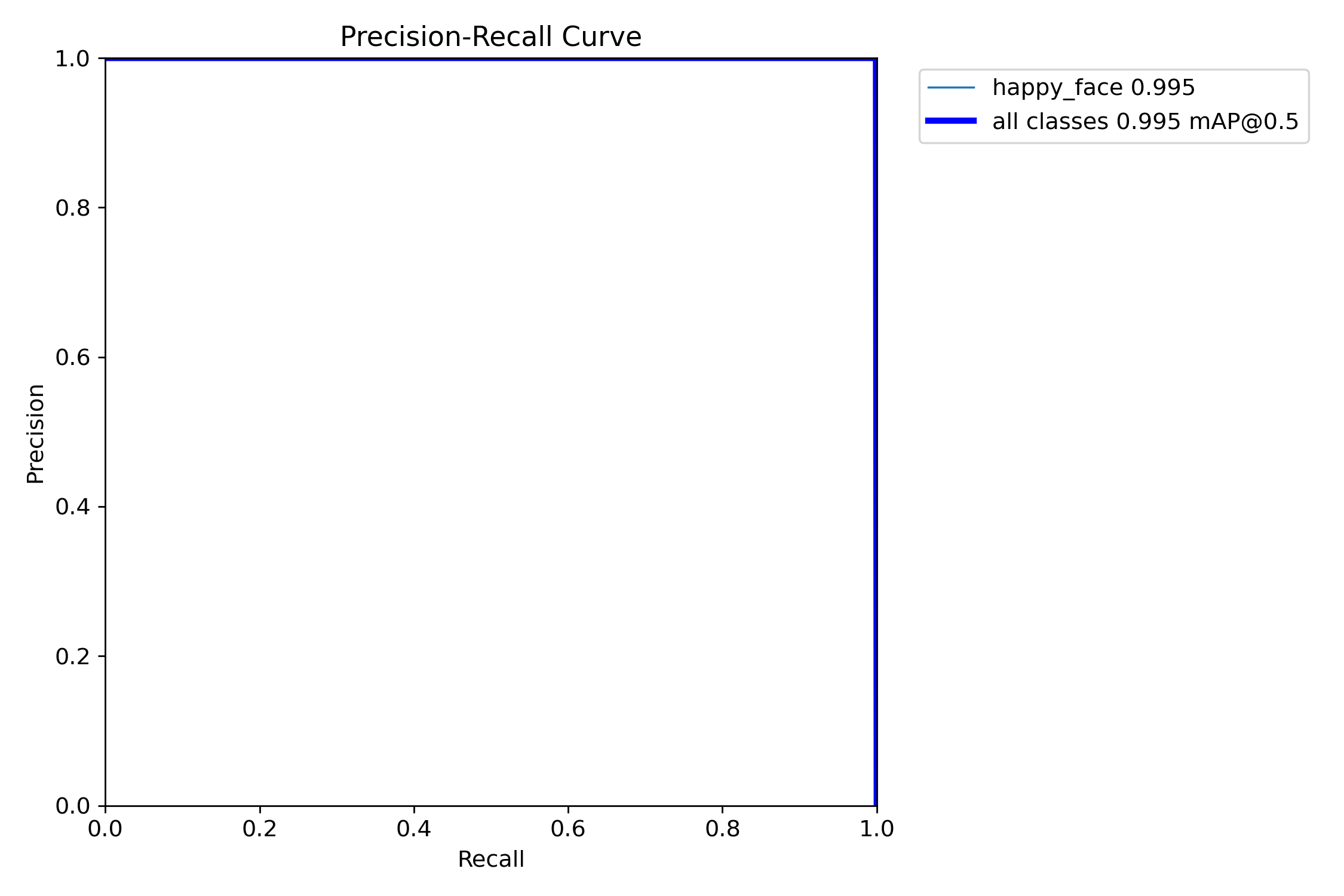
- 의미 : 정밀도(Precision)와 재현율(Recall)사이의 관계임.
- 보는 방법 : 선이 오른쪽 상단 구석(1,1)에 붙어 있을수록 좋음. 현재 그래프는 면적이 0.0995로, 거의 완벽한 사각형을 그림. 매우 우수한 성능이다라는걸 알수있음.
F1-Confidence 곡선
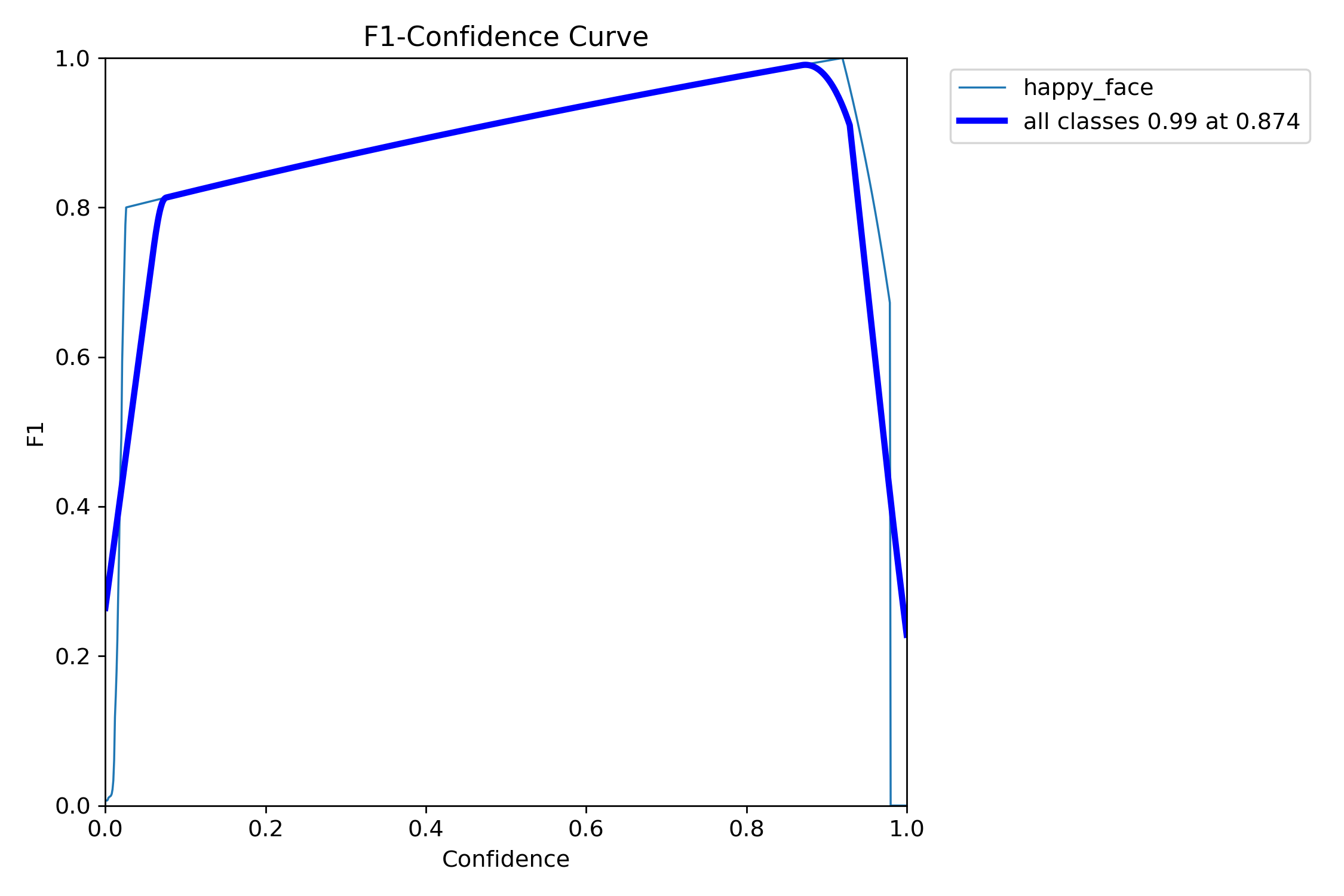
- 의미 : "몇 %이상의 확신이 들 때 박스를 쳐야 가장 효율적일까?"를 알려줌.
- 보는 방법 : F1-score는 정밀도와 재현율의 평균값임. 그래프를 보면 Confidence 0.0874정도에서 F1-score가 0.99로 최대치가 됨. 즉, 모델이 "이건 87% 확률로 happy_face야"라고 판단할 때 가장 믿을 만하다는 뜻임.
혼돈 행렬 (Confusion_matrix)
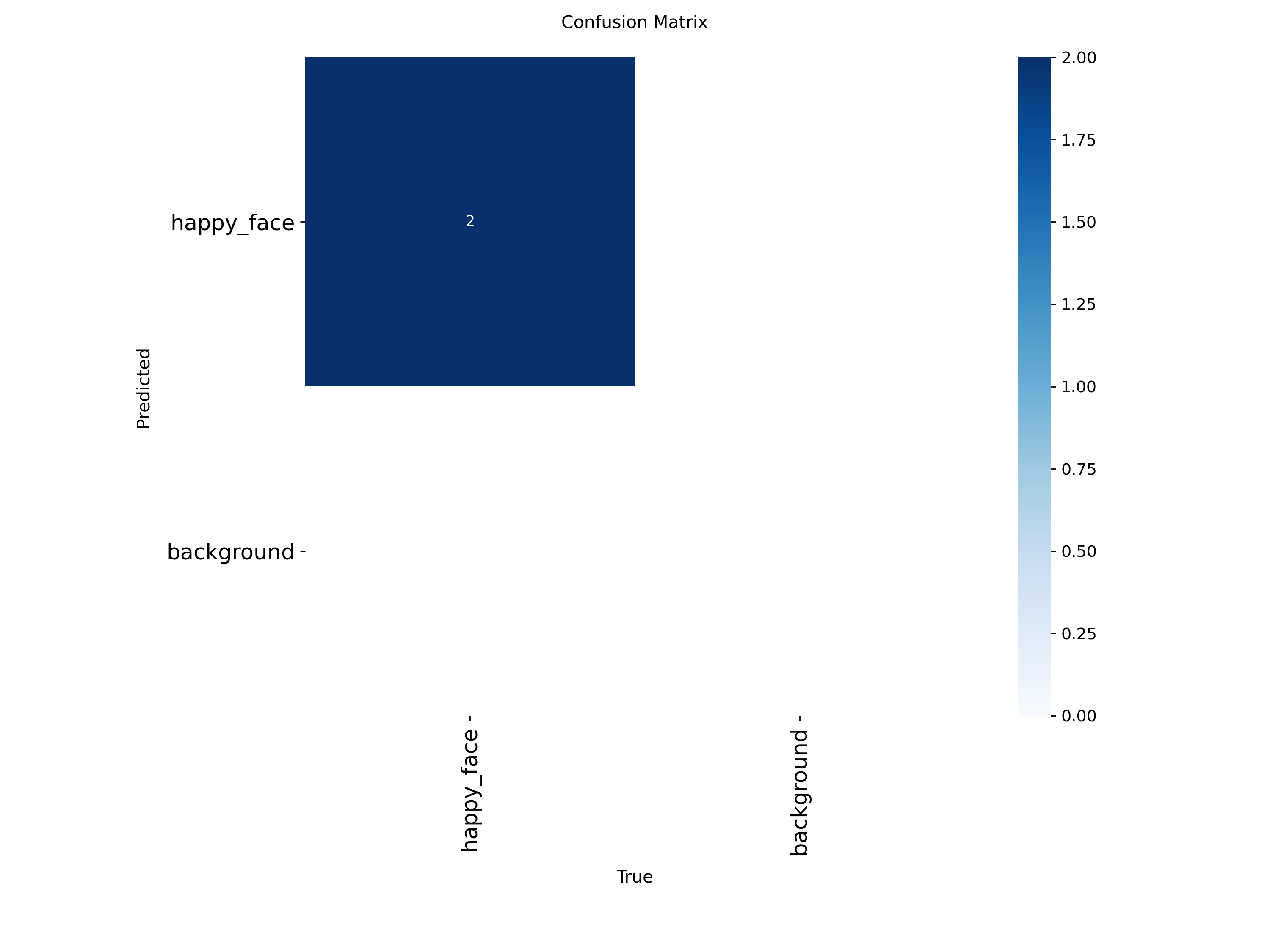
- 의미 : 모델이 헷갈려 하는 클래스가 있는지 보여줌
- 보는 방법 : 대각선 방향(happy_face vs happy_face)에만 숫자가 있고 나머지는 깨끗함. 즉, 배경을 얼굴로 착각하거나 얼굴을 배경으로 놓치는 실수가 전혀 없다는 뜻임.
주의할 점 (Insight)
현재 데이터가 20장으로 매우적은데 지표가 1.0(100%)에 가깝게 나오고 있음.이 두가지 가능성있다고생각함!
1. 성공적인 학습 : 대상(happy_face)의 특징이 매우 뚜렷해서 적은 데이터로도 완벽히 학습됨.
2. 과적합(Overfitting)위험 : 학습한게 20장의 사진은 잘 찾았지만, 새로운 장소나 다른 조명에서 찍은 사진을 보여주면 아예 못찾을 확률이 크지않을까

곽숭아_놀이터