
딥러닝 기초 2일차 정리
1.ML복습 : 결정트리의 진화, 앙상블(Ensemble)
데이터가 정형(표)형태이고 양이 아주 많지 않을 때는 여전히 강력한 도구임.
- 배깅(Bagging) : 병렬 구조. 여러 트리를 랜덤하게 만들어 투표함(예:Random Forest)
- 부스팅(Boosting) : 직렬 구조. 이전 트리가 틀린 문제를 다음 트리가 집중 학슴함. 가중 평균을 통해 합쳐짐(예 : XGBoost, LightGBM)
- Tip : LightGBM이 XGBoost보다 속도가 훨씬 빨라 실무에서 선호된다함.
- 결론 : 표 형태의 데이터 + 단순 분류 문제라면 Random Forest나 LightGBM이 가성비 최고임.
2.왜 딥러닝인가 (선형 vs 비선형)
- 선형적 관계 : 운동 시간-칼로리 소모처럼 정비례하거나 반비례하는 단순한 관계.
- 비선형적 관계 : 공부 시간-성적(계단식), 가격-만족도(지수적)처럼 복잡한 관계.
- 딥러닝의 존재 이유 : 현실 세계의 데이터는 대부분 비선형적임. 딥러닝은 활성화 함수를 통해 이 비선형성을 완벽하게 모사함.
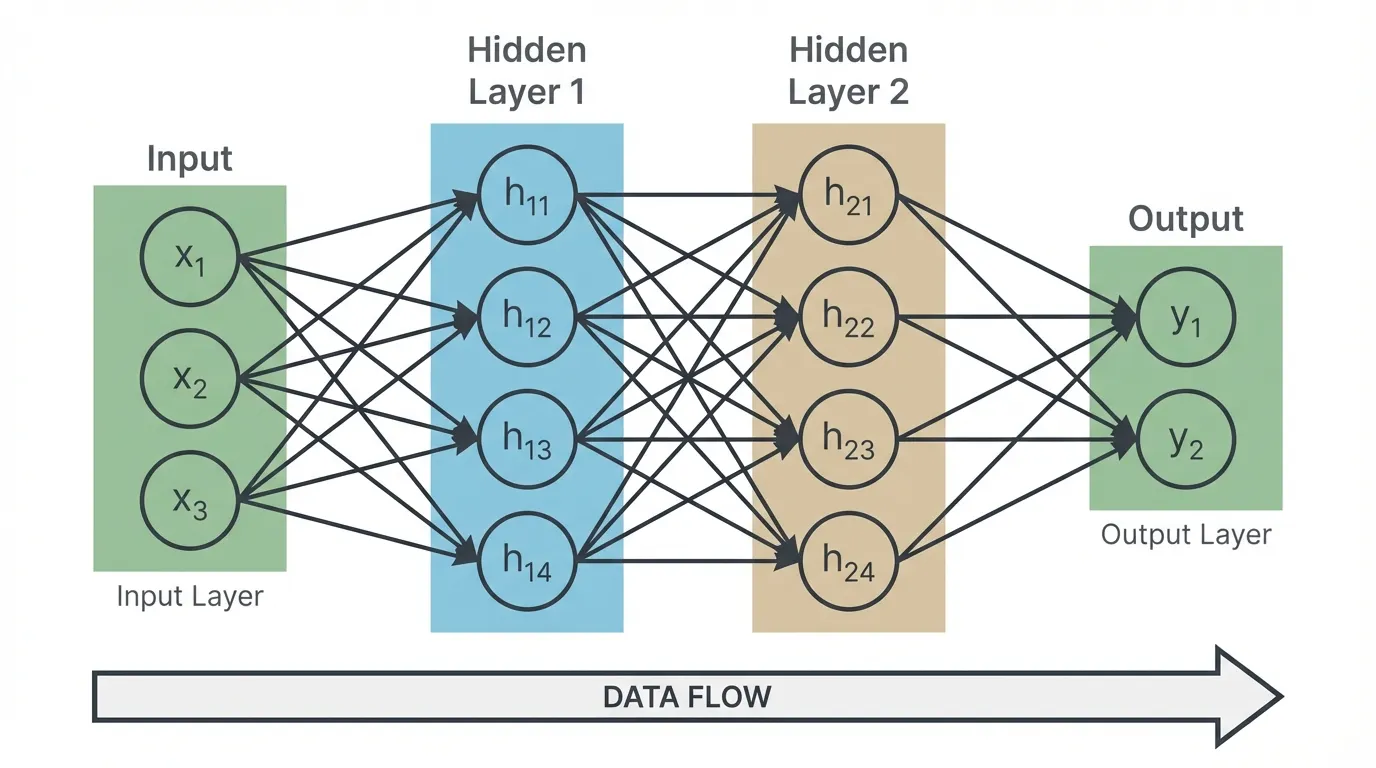
3.MLP(Multi-Layer Perceptron)의 설계 원리
퍼셉트론을 층층이 쌓은 구조.
- 지식 저장소(Parameter) : 가중치()와 편향()의 총합임. 이 숫자들의 모델의'지능'을 결정하며 GPU메모리를 차지하는 주범임.
- 너비 vs 깊이
- 노드(너비)를 늘리는 것보다 레이어(깊이)를 쌓는 것이 모델의 표현력을 높이는 데 훨씬 효율적임.
- 활성화 함수의 배치 : 선형 연산() 뒤에 반드시 비선형(ReLU 등)을 붙여야 층을 쌓는 의미가 생긴다.
4.모델 평가의 딜레마: 성능 지표 제대로 알기
단순히 "정확도(Accuracy)가 높다"고 좋은 모델이 아님.
- 임계치(Threshold) : 0.5라는 기준은 절대적이지 않음. 데이터 분포에 따라 조절해야 함.
- 주요 지표 4총사
- 정확도(Accuracy) : 데이터 불균형(예:의귀질환 0.1%)시 무의미함. 전부 음성이라 해도 99.9%가 나오기 때문임.
- 민감도(Recall/Sensitivity) : "실제 암 환자 중 암이라고 맞춘 비율". 놓치면 안 되는 문제에서 중요!
- 특이도(Specificity) : "정상인 중 정상이라고 맞춘 비율"
- 정밀도(Precision) : "암이라고 예측한 사람 중 실제 환자 비율".
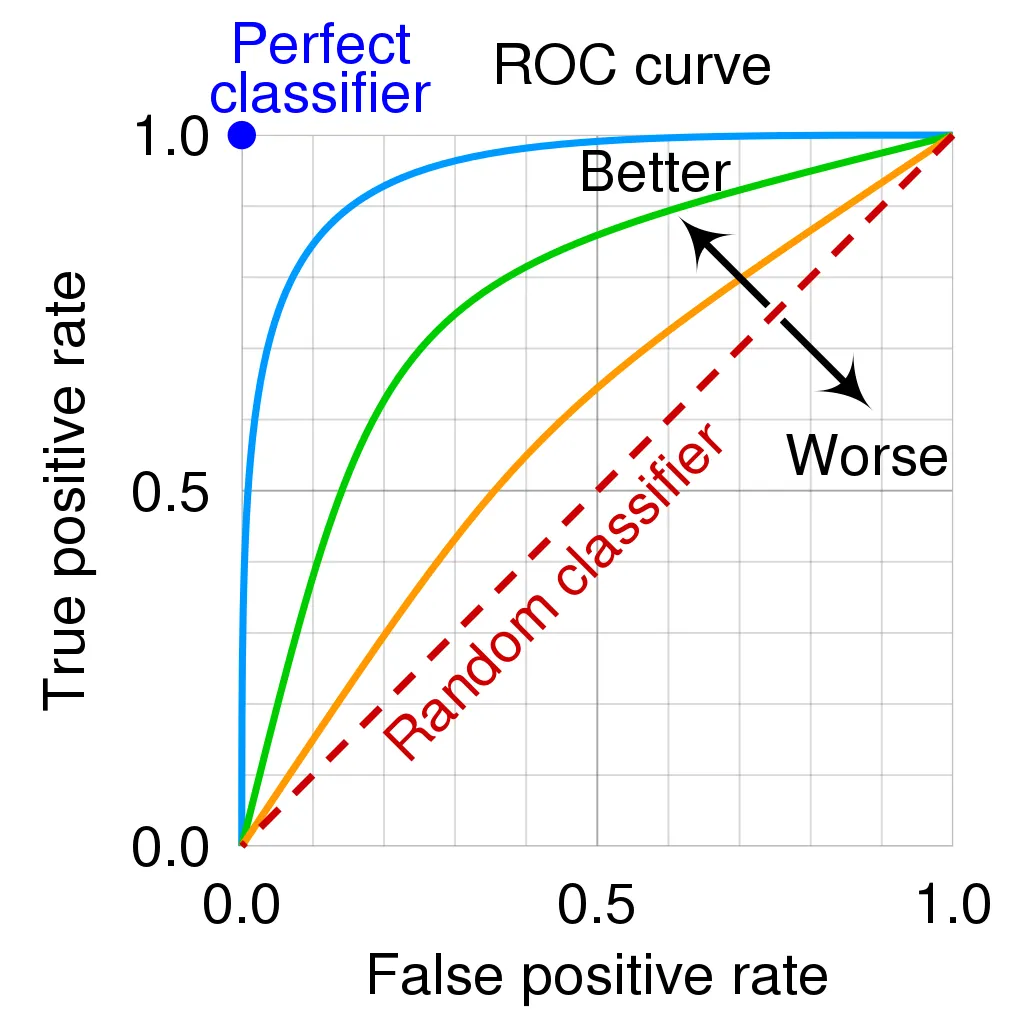
- ACROC : 임계치를 변화시키며 민감도와 특이도의 트레이드오프 관계를 한눈에 평가하는 지표임. 1에 가까울수록 좋은 모델임.
💡요약
- 정형 데이터에는 앙상블(LGBM 등) 모델이 효율적이다.
- 딥러닝 모델의 성능은 파라미터의 양과 층의 깊이에 비례한다.
3.모델 평가는 정확도뿐만 아니라 Recall, Precision, AUROC를 종합적으로 봐야 한다.

곽숭아_놀이터