[논문 리뷰] Radio Machine Learning Dataset Generation with GNU Radio - 1편
Abstract
본 논문에서는 radio signal processing domain에 적용되는 ML의 새로운 application에 대해 다룬다. 또한 사용할 수 있는 method들에 대한 간단한 background를 제공하고, 해당 분야의 잠재적인 발전에 대해 논의한다.
논의 내용은 model의 학습, 테스트, 평가를 위해 좋은 dataset을 제공하는 것이 얼마나 중요한지에 대한 것이고, 여러 radio machine learning task들을 위한 open source synthetic dataset들도 소개한다.
이러한 일들은 해당 분야에서 작동하는 것들에 대한 강력한 common baseline과 많은 기술들을 빠르게 평가하고 비교할 수 있는 benchmark measure를 제공하기 위한 것들이다.
Motivation & Background
ML은 지난 10년 동안 빠른 속도로 발전해왔고, 여기에는 여러 가지 핵심 이유들이 존재한다. 먼저 알고리즘이 다방면으로 빠르게 개선되었고, GPU의 발전과 함께 computational power도 크게 향상되었다. 또한 잘 선별된 large dataset에 접근하는 것은 사람들이 idea를 빠르게 비교하고, 새로운 approach를 평가하며, large parameter space를 가진 모델을 학습하도록 할 수 있는 또하나의 핵심 요소이다.
CV와 NLP 등의 분야에서 연구하는 사람들은 현재 ML의 다양한 SOTA 발전을 밀어붙이고 있지만, 안타깝게도 radio signal processing에서의 발전은 눈에 띄게 더딘 상태이다. 하지만 ML 분야의 최신 발전이 radio domain에 응용될 가능성은 매우 높은 상태이다.
따라서 통신 분야의 연구자들은 이러한 ML method들을 점점 고려하고 있다. 그러나 다른 응용 분야들에서 볼 수 있는 것과는 달리 연구를 평가하기 위한 common benchmark와 open dataset이 부족한 상황이다.
Early Methods
DNN은 빠르게 성장하여 많은 ML problem들에 적용되기 시작했다. DNN을 위한 많은 아이디어들은 수년 동안 존재해왔는데, 그 중에는 대표적으로 weight (가중치) set으로 구성된 input에 간단한 activation function을 적용시킨 perceptron이 있다. 이는 다양한 함수의 classification이나 regression에 다음 식과 같은 형태로 사용될 수 있다.
아래는 neural network를 통해 loss function과 loss gradients chaining을 사용하는 back-propagation에 대한 식이다.
한편, MSE와 같이 network loss function에 대한 key concept들이나 perceptron에 있는 neural network의 weight들을 tuning 하기 위해 gradient backpropagation을 사용하는 개념은 40년이 넘도록 존재했었는데 왜 이제서야 주목을 받게 된 것일까?
Recent Advances
최근 발전 동향에 대해 설명한 부분이다. 2016년도 논문이라 그런지 대부분 쉽게 찾아볼 수 있는 개념들로 구성되어 있으니 이 부분은 논문을 참조하도록 하자.
Differences From Other ML Domains
Radio domain data에는 기존 ML 영역에 존재하는 많은 application과는 다른 challenge들이 존재한다.
Radio 통신 신호는 잘 구성되어 있으며 사람이 만든 transmitter에 의해 synthetical 하게 만들어진다. 하지만 전송 시 신호는 가혹한 channel effect를 많이 겪게 되고, 이는 수신된 radio 통신 신호의 복사본에 존재하는 variation 집합을 만들어 unique한 difficulty를 만든다.
통신 system은 일반적으로 capacity limit에 가깝게 동작하도록 설계되기 때문에 information bit들은 매우 조밀하게 packing 되고, 보통 상대적으로 간단한 basis function set 혹은 encoding을 사용한다. 하지만, 용량에 대한 최적화가 일반적인 기준이기 때문에 redundancy나 context를 많이 제공하지는 않는다.
이러한 특징은 spatial correlation과 known objects가 scene의 대부분을 차지하는 image domain이나, 오직 known sequence에서 단어를 합성하기 위해 상대적으로 길게 인식할 수 있는 formant (포먼트, 소리가 공명되는 특정 주파수 대역)가 발생하는 speech recognition domain과는 극명한 대조를 이룬다. 즉, 이 두 domain에서는 오류 복구에 크게 도움이 될 수 있는 상대적으로 강력한 a-priori distribution 및 pattern을 갖는다.
Wireless system에서의 channel 효과는 다양한 전파 환경에서 발생하고 신호에 큰 영향을 주는데, 모든 real OTA system에 포함되어 있는 몇 가지 효과를 살펴보면 다음과 같다.
-
알 수 없는 propagation delay 뿐만 아니라 asynchronous traffic과 protocol schedule로 인해 random인, 신호의 도착 시간.
-
분리된 radio system에서 작동할 수 있는 sample clock으로 인해 random한 symbol rate error.
-
수많은 analog front-ends, reflectors, propagation medium으로 인한 알 수 없는 phase-delay와 free running clocks, oscillators로 인해 발생하는 random한 carrier phase 및 frequency error.
-
Propagation multi-path interference와 reflectors 등으로 인한 non-impulsive delay spread.
-
Emitter와 reflector, receiver의 motion으로 인한 Doppler offsets.
-
Gaussian thermal noise (열 잡음), impulsive noise, co-channel 및 adjacent (인접) channel interference.
이러한 효과들 중 일부는 다른 domain에도 공통적으로 존재할 수 있지만 큰 차이가 존재한다. 예를 들어, voice recognition domain에서도 random arrival time, pitch(frequency) offset, word length dilation (확장) 문제들이 모두 존재한다. 하지만 이들은 훨씬 큰 time scale에서 발생하고, less densely packing 된 voice formant를 encoding 한다. 하지만 symbol의 의미가 milli-second 단위가 아닌 micro- 혹은 nano-second 단위의 time shifts로 달라진다. 그래도 여전히 수신 신호의 unknown time과 dilation은 1D Affine 변환으로 생각할 수 있고, 이는 voice recognition system에서 timing recovery를 하기 위해 사용하는 attention model과 크게 다르지 않다.
통신 시스템에서 일반적으로 사용되는 complex base-band representation은 (다른 domain들과) 상당히 큰 차이를 나타낸다. 우리는 이를 audio나 finance에서 사용하는 multi-channel time-series 처럼 다룰 수 있지만, channel들 사이에는 random phase와 같은 확실한 property가 존재한다.
따라서, 우리가 이들(실수 및 허수 부분을 의미하는 것 같음)을 독립적인 channel로 취급한다면 기본적인 polar representations property를 놓칠 수 있고, 이로 인해 기본적인 representation level에서는 다루기 어려운 phase recovery나 frequency recovery, Doppler/LO-tracking 등의 task가 생긴다.
우리는 복소수 값으로 구성된 neural network에서의 auto-differentiation을 전체적으로 (holistically) 다룰 필요 없이, 위의 문제를 해결하기 위한 layer로 complex convolution과 같은 새로운 primitive operation을 도입할 수도 있다. 하지만 이는 모든 복소수 연산을 포함하는 것에 있어 여전히 open problem이다.
Multi-path와 equalization은 또다른 주요 issue이다. 이들은 비록 voice recognition dataset에 존재하고 있지만 통신 domain에서는 조금 더 빡센 problem 인데, 이는 dense 한 정보의 packing과 multi-path 성분들 및 information symbol이 발생하는 time scale 때문이다.
대부분의 wireless system에서 common time varying random channel 효과들은 존재한다. 따라서 저자는 논문에서 이러한 효과를 dataset에 포함하고, 가능한 한 각 문제에 대한 현실적인 설명을 하기 위해 노력했다.
Building a Dataset
GNU radio는 robust한 dataset을 구축하기 위해 필요한 도구들을 이미 많이 가지고 있다. 여기에는 synthetical 하게 생성한 신호들에게 simulated channel 전파 모델을 적용할 수 있도록 설계된 많은 channel simulation module set과 modulator, encoder, demodulator set이 포함된다. High level 관점에서 보면, 이러한 논리 module들을 단순히 GNU radio에 이어 dataset을 만들 수 있다.
High level dataset generation.
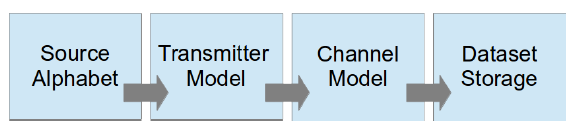
Source Alphabet
논문에서는 모든 신호에 대해 두 개의 data source들을 선택했다.
먼저 analog modulations에서는 목소리와 같은 continuous 신호가 필요하기 때문에, 공용으로 사용할 수 있는 Serial Episode #1의 복사본을 사용했다.
Digital modulation에서는 ASCII로 구성된 셰익스피어의 Gutenberg work를 모두 사용하는데, 이때 symbol과 bit들이 동일한 확률로 나오도록 whitening randomizer가 적용되었다.
정리하면 논문의 모든 modem들은 위에서 언급한 두 가지 data source를, 해당하는 digital 혹은 analog data source와 함께 사용한다.
Signal Modulation
Modulation process.
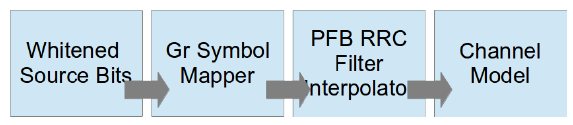
저자는 모든 digital modulation에 걸쳐 일정한 normalized symbol rate을 얻기 위해 symbol 값 하나당 normalized sample들을 선택한다. Single carrier modulation에서 이는 간단하지만, 우리는 OFDM이나 SC-FDMA와 같은 multi-carrier system에서도 명목상 유사한 BW 점유율 값을 추정해야 한다. (?)
우리의 목표는 최대한 비슷한 observed symbol rate 및 occupied BW 값을 가지는 신호를 만드는 것인데, 이들은 channel simulation과 larger environmental simulations에서 다양해질 수 있다.
PSK, QAM, PAM에 대해서는 gr-mapper OOT module을 사용한 transmitter를 구현하는데, 이는 다양한 constellation을 가진다. 또한 symbol rate 당 원하는 sample 개수를 얻기 위해 finite impulse response (FIR) root-raise cosine (RRC) filter를 interpolate 한다.
GFSK, CPFSK, FM, AM, AMSSB를 위해서는 mainline GNU Radio의 구현에서 GNU Radio hier block들을 사용했다.
Channel Simulation
Channel simulation process.
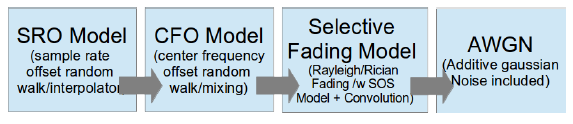
Channel simulation에서는 GNU Radio Dynamic Channel Model hierarchical block을 사용한다. 여기에는 다음과 같은 수많은 desired effect들이 포함되어 있다: Random processes for center frequency offset, sample rate offset, AWGN, multi-path, and fading etc.
-
Sample Rate Offset (SRO) Model: Output sample 하나 당 의 input sample 비율을 따르는 fractional interpolator. 은 거의 0 값과 같다. 또한 clipped random walk procesess를 따라 sample clock offset을 simulate 한다.
-
Center Frequency Offset (CFO) Model: 수신 신호를 Hz 단위의 frequency와 mix하는 digital oscillator 및 mixer. 이때 해당 frequency 값은 carrier frequency offset을 simulate 하기 위한 clipped random walk process 이다.
-
Selective Fading Model: GNU Radio에서 구현했던 것과 같이 random phase noise를 가진 sum-of-sinusoids method를 구현한다. 이는 random한 시간에 따라 변화하는 channel response taps를 사용하여, 들어오는 dataset에 대해 Rician/Rayleigh fading process를 simulation 하기 위함이다.
-
Noise Model (AWGN): 원하는 SNR을 따르는 특정 noise power level에서 수신단의 thermal noise simulation을 구현해주는 baise GNU Radio AWGN model이다.
Normalizing Data
Data normalization은 ML에서 dataset을 사용하기 전에 수행되어야 할 중요한 단계이다. 저자는 real world 실험에서 존재하지 않을 것 같거나 simulation의 단순한 artifact인 residual한 feature들은 모두 없애고 싶어 한다. 본 실험에서는 저장된 각 신호가 unit energy를 갖는 128개 성분의 sample data vector로 구성되어 있다.
Packaging Data
저자는 radio software ecosystem 외의 ML 환경에서도 data를 쉽게 사용할 수 있도록 package 했다. 이를 위한 가장 간단한 방법은 ML 영역에서 자주 사용하는 numpy나 cPickle 형식의 차원 vector로 dataset을 저장하는 것이다.
저자는 각 simulation의 output stream으로부터 랜덤하게 time segments를 sampling 한 뒤, output vector에 저장한다. 여기서 사용하는 tensor의 shape은 이고, 4차원 real float32 vector 이다.
이때 우리는 datastream 으로부터 개의 example을 가지고, 각각은 128개의 complex floating point time sample로 구성된다. 즉, 로 이는 이미지 영역에서 RGBA 값을 표현할 때 일반적으로 쓰이는 표현이다. I, Q channel을 표현하기 위해서 로 설정하고, time dimension의 표현을 위해 로 둔다.
Radio domain에서의 연산은 보통 complex baseband 환경에서 고려되기 때문에, (Tensorflow와 같은) ML toolbox에서의 많은 연산들은 잘 적용되기 힘들다. 따라서, 저자는 위와 같이 I/Q 성분을 분리하여 해당 문제를 해결한다. Complex value로 구성된 neural network를 위한 automatic differentiation 환경은 아직 충분히 발전되지 않았고, 위와 같은 표현으로 complex convolutional layer를 구성해도 많은 이점을 얻을 수 있기 때문에, 저자는 이러한 표현이 당분간은 충분하다고 주장한다.
Reference
O'shea, Timothy J., and Nathan West. "Radio machine learning dataset generation with gnu radio." Proceedings of the GNU Radio Conference. Vol. 1. No. 1. 2016.
