[논문 리뷰] Over-the-Air Deep Learning Based Radio Signal Classification - 2편
Dataset Generation Approach
24개의 다른 analog, digital modulator들이 광범위의 single carrier modulation scheme들을 포괄하는데 사용된다. 또한 저자는 여러 개의 propagation scenario들을 고려했다.
첫 번째로는 아래의 그림과 같은 model로부터 얻은 여러 개의 simulated wireless channel들이다.
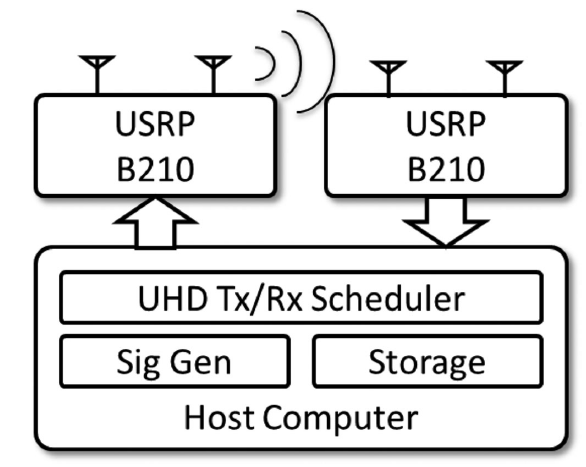
Dataset 신호 생성 및 synthetic channel 손상 modeling을 위한 system.

두 번째로는 아래 그림의 clean signal을 이용한 OTA transmission channel을 생각했다. (synthetic channel impairments는 없음)
Over-the-air test 구성.
Digital 신호는 roll-off values 의 범위를 가진 root-raised cosine pulse shaping filter로 만들어진다.
한편 synthetic data sets에 있는 각 example에 대해, 아래의 표를 따라 random variable들을 뽑는다. 그렇다면 우리는 매 example 마다 uncorrelated 한 random channel을 새로 초기화 할 수 있다.
Table 1. Random Variable Initialization
| Random Variable | Distribution |
|---|---|
저자는 dataset을 구성하는 요소를 2가지 고려한다. 첫 번째로 "Normal" dataset 이다. "Normal" dataset은 11개의 class로 이루어지며, 상대적으로 적은 information density를 가지고 있다. 또한, 이들은 impaired 환경에서 자주 볼 수 있다. 대부분의 경우, 이 11개의 신호들은 high SNR 상황에서 상대적으로 간단한 classification task를 대표한다. (MNIST digits와 비슷)
두 번째로는 24개의 모든 modulation들로 구성되어 있는 "Difficult" dataset이다. 여기에는 QAM256이나 APSK256 같은 high order modulations도 포함되는데, 이들은 real world에서 매우 높은 SNR & low-fading channel 환경일 때 사용된다. 하지만 저자는 그러한 scenario에서 예상될 수 있는 정도를 뛰어넘은 impairments를 적용하고, classification을 위한 short-time observation windows를 고려한다. ( # of samples )
Short-time classification은 real world system에서 short observation이나 short signal bursts를 다루는 경우에 해당된다. 이러한 조건 하에서 낮은 SNR example들을 이용하면 (), 전체 dataset을 사용하여 거의 100%에 가까운 classification을 할 수 없을 것이므로 이후의 연구에서 좋은 benchmark로 사용될 수 있을 것이다.
두 dataset types에 포함된 modulation들의 종류는 다음과 같다.
-
Normal Classes: OOK, 4ASK, BPSK, QPSK, 8PSK, 16QAM, AM-SSB-SC, AM-DSB-SC, FM, GMSK, OQPSK
-
Difficult Classes: OOK, 4ASK, 8ASK, BPSK, QPSK, 8PSK, 16PSK, 32PSK, 16APSK, 32APSK, 64APSK, 128APSK, 16QAM, 32QAM, 64QAM, 128QAM, 256QAM, AM-SSB-WC, AM-SSB-SC, AM-DSB-WC, AM-DSB-SC, FM, GMSK, OQPSK
참고로 raw dataset은 RadioML website에서 이용할 수 있다.
(논문에 나와있는 링크는 없어진걸로 보아 여기로 바뀐게 아닐까 싶음)
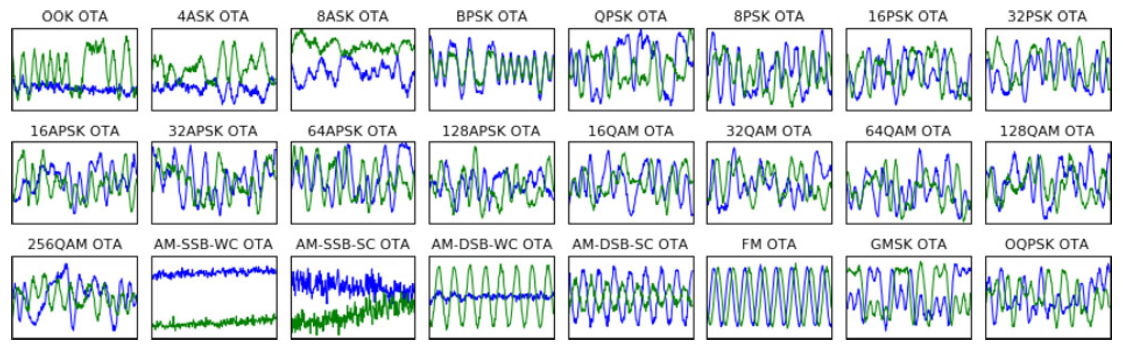
I/Q time domain examples of 24 modulations over-the-air at roughly 10 dB .
()
I/Q time domain examples of 24 modulations from synthetic dataset at 2 dB .
()

Over-the-Air Data Capture
저자는 wireless channel impairments를 simulate하기 위해 OTA test-bed도 구현했는데, USRP B210 software defined radio (SDR)를 사용하면 이러한 test-bed에서 신호를 modulation하고 전송할 수 있다. 두 번째 B210 (with a separate free-running LO, LO: 기준 주파수원을 공급해주기 위한 주파수 소스원)은 900MHz ISM 대역의 양호한 실내 무선 채널을 통해 날아오는 신호를 수신하기 위해 사용된다. (참고로, ISM 대역이란 산업·과학·의료(Industry-Science-Medical) 등에 쓰이는 주파수 대역을 의미한다)
Raido front-end 단으로는 AD9361 radio frequency integrated circuit (RFIC)를 썼고, 약 2 parts per million (PPM)의 frequency (and clock) stability를 가진 LO를 사용한다.
신호는 약 1MHz 정도 off-tune 하는데 이는 direct conversion과 연관있는 DC signal impairment를 피하기 위함이고, 신호는 base-band에 저장한다. (offset은 오직 LO error에 의해서만 일어남) 수신된 test emissions는 emitter 단에서의 modulation을 위해 수정되지 않은 상태로 ground truth labels와 함께 저장된다.
Signal Classification Models
이제 radio signal classification method들을 더 자세히 알아보자.
Baseline Method
Baseline method는 higher order moments 목록을 이용하고 아래의 표에 주어진 여러 aggregate signal behavior statistics를 이용한다.
Table 2. Features Used
| Feature Name |
|---|
우리는 1024개의 sample에 대해 위의 statistic들을 모두 계산할 수 있고, 이들을 example의 각 statistic과 연관된 real value들의 집합인 feature space로 옮길 수 있다. 이 새로운 표현법은 각 example vector의 dimension을 에서 로 줄여서, classification task를 더욱 간단하게 만든다. 저자는 이러한 feature들로부터 modulations를 분류하기 위해 gradient boosted trees의 ensemble model인 XGBoost를 사용한다.
Convolutional Neural Network
아래의 Table 3.에서 확인할 수 있는 것처럼 저자는 VGG architecture의 원리를 1D CNN을 이용하여 적용시켰다.
이는 쉽게 학습되고, small radio signal classification task를 효과적으로 수행하기 위해 쉽게 학습되고 배치(deploy) 될 수 있는 간단한 DL CNN 설계 접근 방식을 나타낸다.
여기서 중요한 점은 CNN에 입력되는 feature는 각 radio signal에 대해 unit variance로 정규화 시킨 raw I/Q samples 라는 것이다. 저자는 raw radio signal에 어떠한 pre-processing이나 expert feature extraction을 수행하지 않았고, 그 대신 network가 high dimension data로부터 직접 raw time series features를 학습하도록 했다. Complex valued auto-differentiation은 아직 practical 하게 사용하기 적절하지 않기 때문에 real valued network가 사용되었다.
Table 3. CNN Network Layout
| Layer | Output dimensions |
|---|---|
| Input | |
| Conv | |
| Max Pool + Conv | |
| Max Pool + Conv | |
| Max Pool + Conv | |
| Max Pool + Conv | |
| Max Pool + Conv | |
| Max Pool + Conv | |
| Max Pool | |
| FC/Selu | |
| FC/Selu | |
| FC/Softmax |
Residual Neural Network
CV 영역에서는 deep residual networks (RNs)를 사용하는 것이 매우 효과적이라는 사실이 알려져있다. Time series radio classification에 대해서도 RNs를 사용하는 방안이 연구되었는데, 보다 빠른 epoch 안으로 학습이 되었지만 accuracy 측면에서 performance 증대가 크게 일어나지는 않았다. 이에 저자는 수정한 RN을 modulation recognition 문제에 적용하여, CNN에 비해 발전된 성능을 얻었다. 사용한 residual 구조는 아래의 그림과 같다.
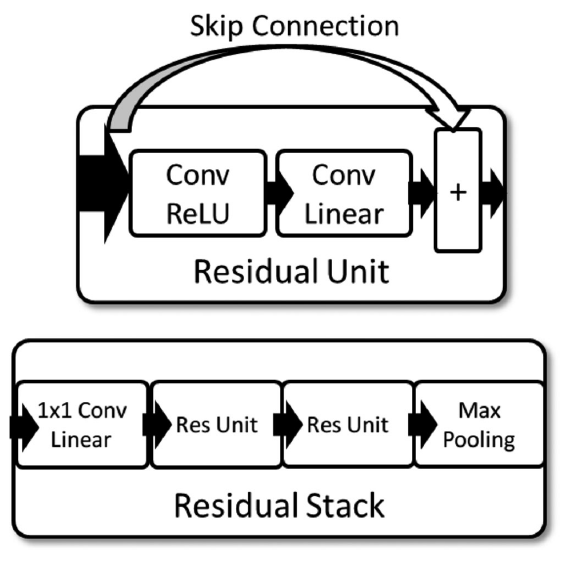
Table 4.는 로 설정한 우리의 실험에서 가장 잘 작동했던 구조를 나타낸 결과이다.
Table 4. ResNet Network Layout
| Layer | Output dimensions |
|---|---|
| Input | |
| Residual Stack | |
| Residual Stack | |
| Residual Stack | |
| Residual Stack | |
| Residual Stack | |
| Residual Stack | |
| FC/Selu | |
| FC/Selu | |
| FC/Softmax |
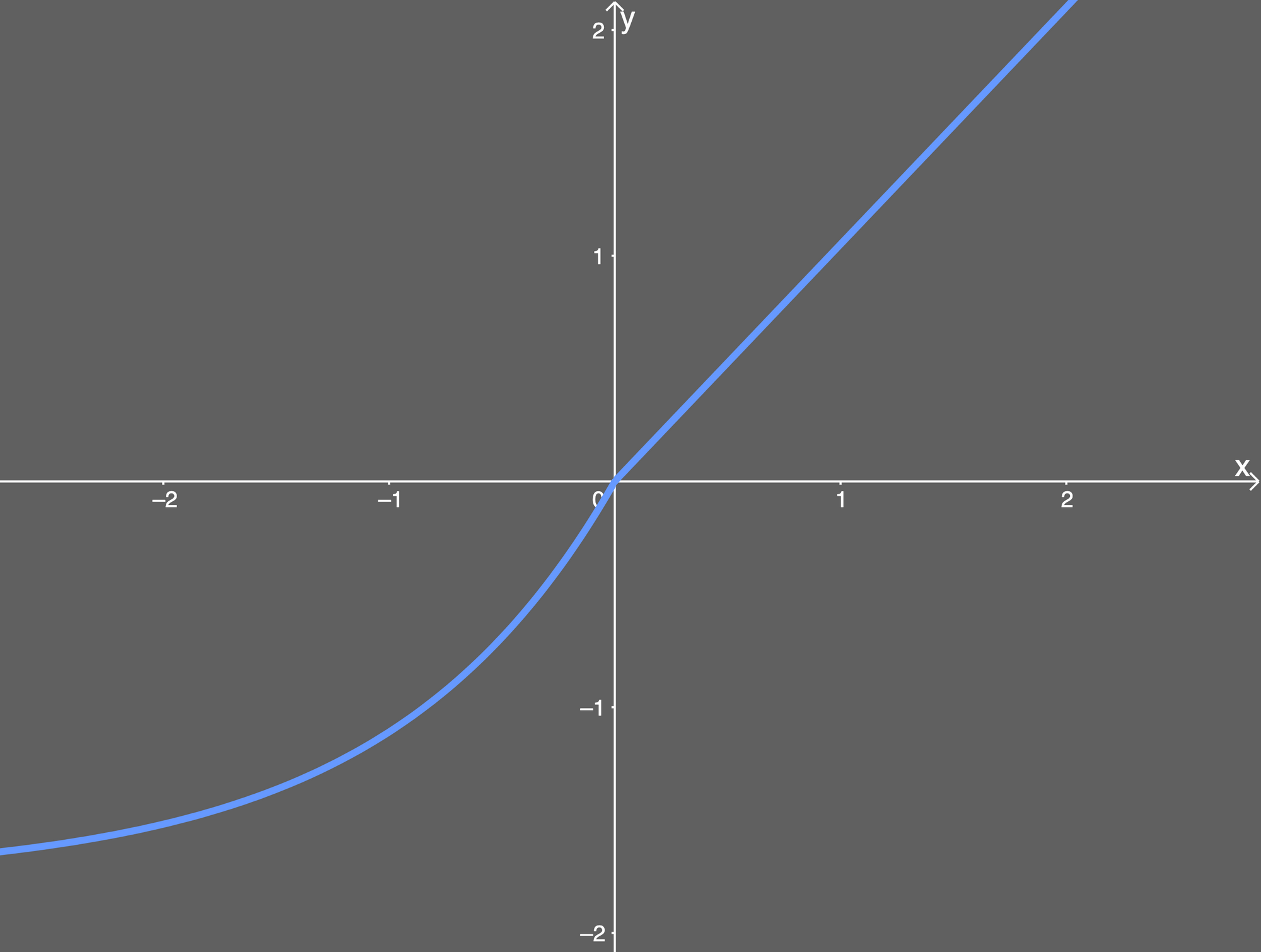
마지막으로 통상적으로 쓰이는 ReLU + Dropout의 조합을 뛰어넘기 위해, FC layers에서 self-normalizing neural networks를 사용했다. 해당 부분의 구현은 scaled exponential linear unit (SELU) activation functions, mean-response scaled initialization (MRSA), Alpha Dropout을 적용하여 진행했다.
- SELU function
SELU의 그래프는 다음과 같다.
Sensing Performance Analysis
DL 기반 radio signal classification solution을 설계할 때 꼭 고려되어야 할 요소들 (성능에 큰 영향을 줄 수 있는), 이를 테면 design, deployment, training, data들에 대한 고려 사항은 매우 많이 있다.
논문에서 고려한 사항은 무엇이 있는지 알아보자. (더 많은 그래프는 논문을 직접 참고하자)
Classification on Low Order Modulations
먼저, lower difficulty dataset을 이용하여 lower order modulation type들에 대한 성능을 비교해보았다. 각각이 1024개의 sample들로 구성되어있는 백 만개의 example로 구성된 dataset을 이용하여 학습을 진행했고, VGG CNN과 RN에 대해 high SNR에서 완벽한 성능을 얻을 수 있었다. 특히 낮은 SNR에 대해서는 VGG와 RN의 성능이 비슷했지만, high-SNR에서는 RN을 사용한 결과가 훨씬 더 좋은 것을 알 수 있었다. 참고로 RN을 사용하여, baseline과 비교해 같은 accuracy 획득을 위한 SNR 이득을 얻을 수 있었다.
이후의 실험에서는 higher information rates에서의 24 high order modulations에 대한 classification을 고려하여, 보다 더 어려운 task에 대해 실험을 진행했다.
(e.g. high order PSK, QAM, APSK)
Classification Under AGWN Conditions
AWGN에서의 signal classification task는 통신 분야에서 가장 기본으로 연구되었던 problem으로, 일반적으로 analytic feature extractor가 가장 좋은 성능을 보여주어야 하는 조건이다. (analytic model assumptions와 matching)
저자는 RN, VGG, BL method에 대해 samples, examples 를 사용한 full dataset과 residual stacks를 사용하여 셋의 성능을 비교했다. 그 결과, difficult dataset을 사용한 상황에서 residual network의 성능이 high, low SNR에 대해 모두 가장 좋다는 것을 확인할 수 있었다.
Classification Under Impairments
Real world 상황에서 wireless 신호들은 많은 effect들에 의해 손상된다. 비록 simulation과 modeling을 위해서는 AWGN이 자주 사용되지만, 앞에서 언급한 effect들은 거의 무조건 존재한다고 생각해도 좋다.
따라서 학습한 classifier가 그러한 impairments 상황 하에서 얼마나 잘 작동할 것인지 고려하는 것과 그러한 effect들이 성능 저하에 어떤 영향을 미치는지 이해하는 것이 중요하다.
실험은 impairment model을 사용하여 RN과 BL에 대해 각각 진행되었다. 사용된 impairment 설정에는 다음과 같은 요소들이 있었다; AWGN,
(위의 표기에서 는 LO offset에 대한 것으로 인 경우를 minor LO offset, 인 경우를 moderate LO offset으로 표현함. 는 여러 fading model을 표현하기 위해 사용됨.)
Fading model에 대해서는 moderate LO offset이 사용되었다. 흥미로운 점은 LO offset 상황에서 RN의 성능이 올라가는 것이었다. 저자는 이를 LO offset의 추가로, positive regularizing effect가 적용되어 성능의 향상을 보인 것이라고 해석했다. 참고로 BL classifier를 사용했을 때는 오히려 LO offset으로 인해 성능의 감소가 일어났다.
논문의 Fig. 10을 참고하면, moderate LO impairment effect 상황에서의 각 model에 대한 성능을 바로 비교할 수 있다. 먼저 unsynchronized LOs와 Doppler frequency offset이 존재하는 수많은 real world system 상황에 대해 RN approach를 사용하면 거의 6dB의 성능 이득을 얻을 수 있었다. 또한 high SNR 에서는 20%의 accuracy 증가를 확인할 수 있었다.
본 실험에서 사용한 설정은 samples, examples 이다.
Classifier Performance by Depth
Model의 size는 large neural network model이 복잡한 feature들을 정확히 표현하는 능력에 상당한 영향을 줄수도 있다. 이에 대한 실험으로 (RN의) residual stack 개수 이 증가함에 따른 validation accuracy를 관찰하였고, 그 값이 증가하는 것을 확인할 수 있었다. 하지만 특정 시점부터는 (여기에서는 인 경우) 오히려 결과가 조금 안 좋아지는 것도 확인할 수 있었다.
Layer stack 개수의 각 경우에 대한 보다 자세한 parameter 개수 구성은 논문을 보도록 하자.
Classification Performance by Modulation Type
여기서는 각 modulation type들에 대한 classifier의 성능을 비교해보았고, 같은 classification accuracy를 얻기 위한 SNR 차이가 modulation type에 따라 까지 차이나는 것을 확인할 수 있었다.
AM과 FM 같이 lower informations rates 및 unique structure를 가진 몇몇 신호들은 low SNR에서 더 잘 식별된 반면, high-order modulations는 성능을 robust 하기 위해 더 높은 SNR을 필요로 했다. 즉, carrier가 있는 AM modulation은 더 식별하기 쉬운 경향이 있고, 일반적으로 higher order modulations는 동일한 classification 정확도를 얻기 위해 더 높은 SNR을 필요로 한다. 또한 모든 modulation type은 SNR 근처에서 정확도 80% 이상에 도달했다.
한편, 저자는 SNR이 0 이상인 상태에서 AWGN validation example들에 대한 24 classes의 confusion matrix를 뽑아보았다. 이때 가장 크게 error가 발생한 부분은 다음과 같았다.
high order PSK(16/32-PSK) 끼리, high order QAM(64/128/256-QAM) 끼리, AM modes 끼리 (confusing with-carrier(WC) and suppressed-carrier(SC))
상당한 noise를 동반한 short-time observations, 그 중에서도 특히 higher order QAM과 PSK에 대한 유의미한 error는 단순히 정보의 부족과 비슷한 symbol 구조로 인해 발생하는 것으로 보인다. (?)
또한 AM modulation에서는 추가적인 음성 data set size가 성능을 개선시켰을 것으로 보았다.
마지막으로 ASK modulations는 엄청 좋은 성능을 보였는데, 일반적으로 amplitude variation이 phase variation 보다 나은 것을 알 수 있었다.
Classifier Training Size Requirements
Data-centric ML method를 사용할 때 종종 dataset은 학습한 model의 quality에 상당한 영향을 끼친다. 저자는 dataset이 미치는 영향을 고려하기 위해 training set 안 example signal의 총 개수를 , 각 example을 구성하는 (time-length에 대한) sample의 개수를 로 두어 실험을 진행했다. 그 결과, dataset size가 model training에 엄청난 영향을 주는 것을 알았다.
Performance vs training set size (here )
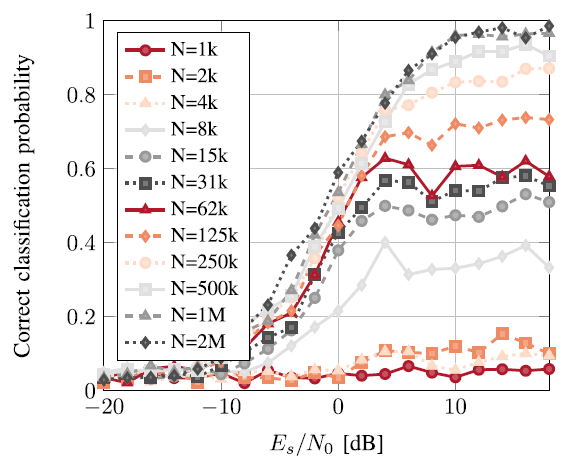
위의 그래프는 충분한 training data를 가지는 것이 performance에 매우 중요하다는 것을 시사하고 있다. 하지만 2M의 data size를 사용한 가장 큰 case에 대해서 single SOTA NVIDIA V100 GPU로 학습을 진행해도 수렴을 위해 약 16시간이 걸렸고, 이는 이러한 dataset size를 사용하여 중요한 실험을 진행하는 것이 힘들다는 것을 의미한다. 또한 1M와 2M 간의 차이가 크게 없는 것도 확인할 수 있었다.
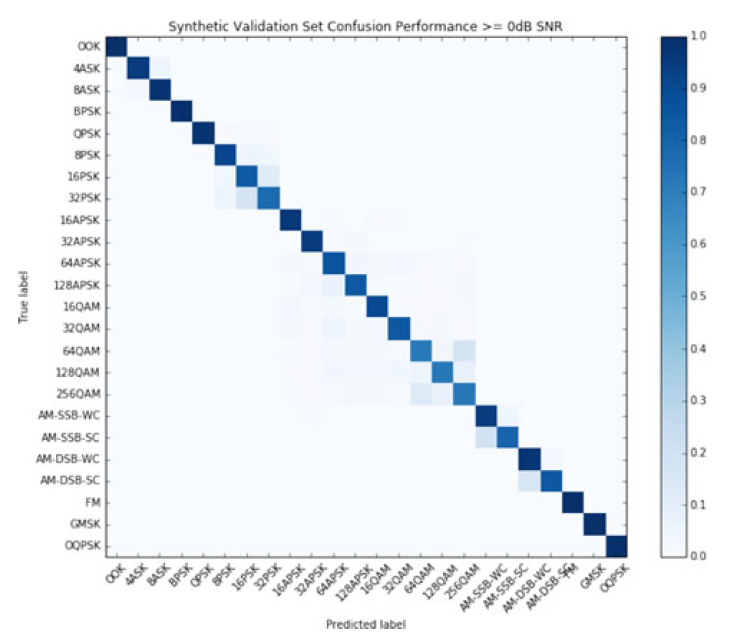
아래 그림은 0dB 이상의 SNR에서 test example을 이용하여 , 를 사용한 best mode에 대해 class-confusion matrix를 구한 결과이다. 여기서 저자는 의 dataset을 사용하였는데, 이는 AWGN보다 조금 더 나은 성능을 보여주기 때문이다.
Fig. 17. (in paper)
24-modulation confusion matrix for ResNet.
Synthetic dataset with 에서 trained, tested.
다음은 한 번의 classification을 위해 사용된 example 당 time sample의 개수(=window size)를 변화시킴에 따른 model의 성능을 관찰한 결과이다.
Fig. 18. (in paper)
Performance vs example length in samples . here.
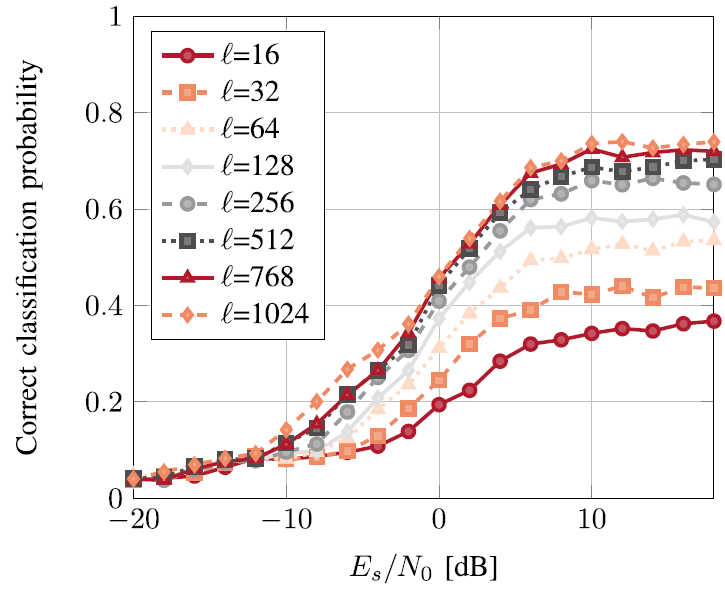
저자는 CNN이 위와 같은 512, 1024의 size 까지 잘 확장되는 것을 확인했지만 memory requirements 나 training time requirements 등의 이유로 인하여, 더 큰 input windows에 대해서는 추가적인 scaling strategies가 필요할 수도 있다는 사실을 발견했다.
Over-the-Air Performance
이전에 설명했던 USRP setup을 사용하여 24 modulation dataset에 대해 개의 OTA example들을 만들었다. Training과 test set의 비율은 8:2로 설정하였고, classification task를 위한 RN은 바로 학습할 수 있다.
위의 설정으로 NVIDIA V100을 이용하여 14시간 동안 실험을 진행했고, OTA dataset에 대해 test set 정확도 를 얻었다. (all examples are roughly dB SNR)
Direct training을 기반으로 한 OTA test set performance의 confusion matrix figure는 논문 (Fig. 19.)를 참고하자.
Transfer Learning Over-the-Air Performance
논문에서는 OTA signal classification을 transfer learning 문제로도 고려해보았다. 즉 model은 synthetic data에 대해 학습하고, OTA data에 대해서만 evaluate 및 fine-tune을 진행하는 것이다.
Transfer learning은 ResNet의 layout을 나타낸 Table 4. 에서 마지막 세 개의 FC layer들을 제외한 모든 layer들에 대해 parameter weights를 freeze하고 update를 진행하는 방식으로 적용되었다.
Fine-tune을 적용시켜 성능이 좋아지는 것을 확인했다.
결론적으로 moderate LO offset 상황에서 학습한 model의 성능이 OTA data에 대해 가장 좋았다. (Synthetic data (train): 94%, OTA data (evaluate): 87%)
아래의 그림을 보자.
Before and after applying fine-tuning.
24-modulation confusion matrix for ResNet trained on synthetic and tested on OTA examples with SNR (~ 10dB).
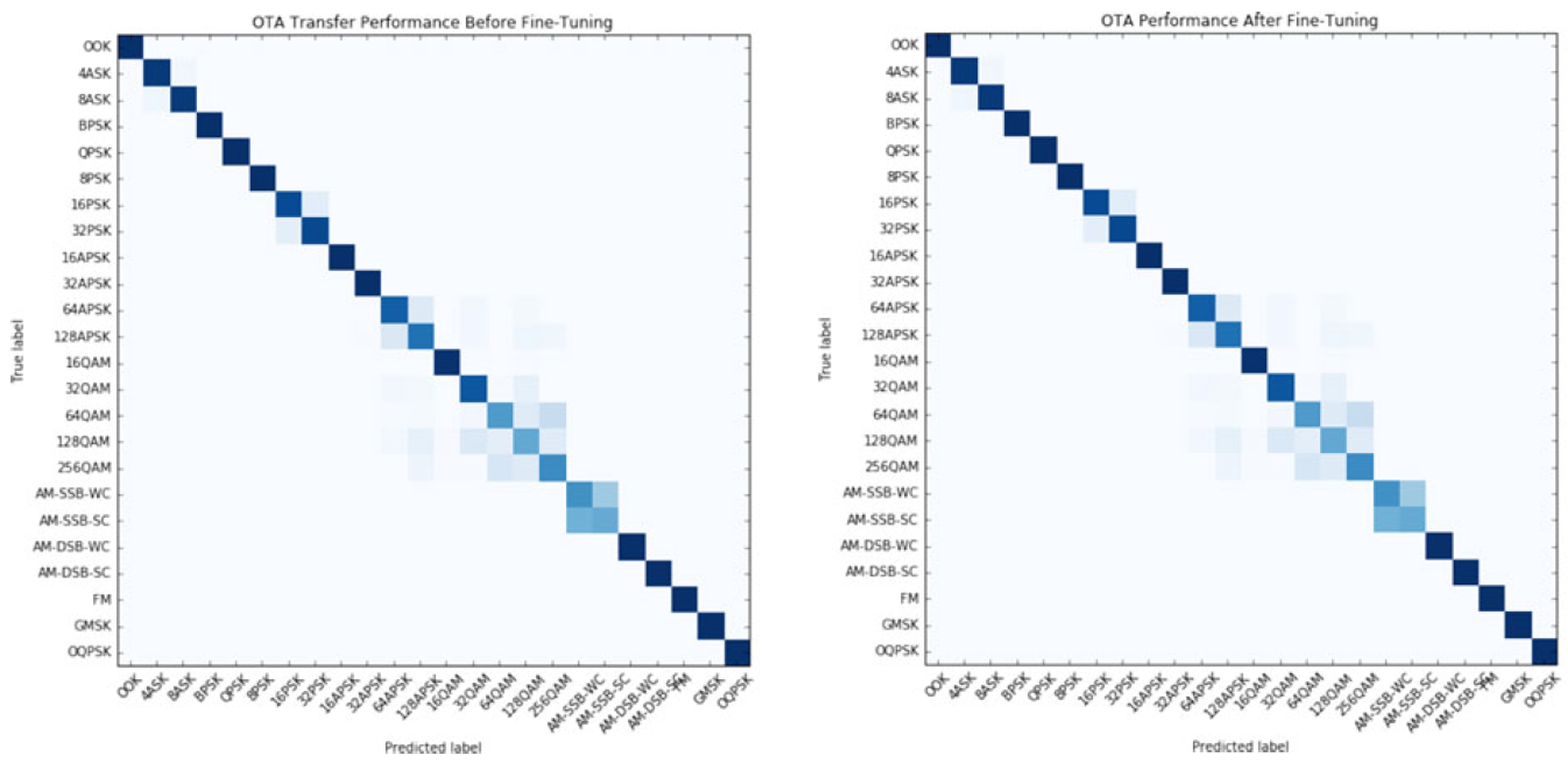
이를 통해 학습을 진행하기 전 가장 헷갈리는 case는 다음의 두 가지로 보였다:
- Suppressed, non-suppressed carrier analog signals 구분
- Higher order QAM, APSK mode 끼리의 구분
해당 모델은 다음의 여러 이유로 인해 우리가 가지고 있는 모델 중 OTA data와 가장 잘 matching 되는 것으로 보인다.
먼저 OTA data에는 매우 작은 LO deviation만이 존재한다. (장치 관련 이유)
두 번째로 indoors radio의 근접성과 clean LOS 성분이 지배적인 impulse response (즉, 상대적으로 higher delay indirect paths에 거의 에너지가 없는 상태)로 인해 매우 작은 (near impulsive) delay spread가 적절하기 때문이다.
만약 더 가혹한 impairments 환경에서 학습을 시킨다면, OTA data에 대한 성능이 상당히 감소될 것으로 보인다.
저자는 model의 성능을 점점 가혹해지는 (harsh) real world 환경에서 평가할 때 그들의 transfer learning이, 비슷하게 impaired (손상) 되고 real wireless conditions와 가장 잘 match 되는 (matching LO distributions, matching fading distributions 등) synthetic models를 선호할 것으로 예상한다. 이 방식으로는, 이러한 종류의 system을 직접 target signal 환경 혹은 잘 맞는 model이 유도될 수 있는 매우 좋은 impairment emulation model에서 학습시키는 것이 중요할 것이다. 이때 가능한 완화 (mitigation) option에는, 변화하는 무선 전파 환경에 대한 일반화 능력을 개선시키기 위해 network 구조에 radio transformer network와 같은 domain-matched attention mechanism들을 포함하는 것이 있다.
Conclusion
저자는 deep residual 구조를 사용할 때 deep network가 훨씬 효과적이라는 것과, synthetical 하게 학습한 deep networks가 OTA dataset에 효과적으로 transfer 될 수 있다는 것을 보였다. (7%의 accuracy loss는 존재했음) 또한 training data만 충분히 있으면, 직접 OTA data에 대해 효과적으로 학습할 수 있다는 것도 보였다.
비록 오늘날 이러한 classification task에서 잘 labeling 된 dataset을 많이 얻는 것은 어렵고 channel model이 real world condition과 맞지 않을 수 있지만, 저자는 이러한 system을 학습할 때 실제로 필요한 사항들을 수치화했고 성능에 미치는 영향을 수량화 하는 것에 도움을 주었다.
논문에서는 그들의 방식을 이용하면 high SNR OTA dataset을 사용하는 것과 equivalent synthetic dataset을 사용할 때의 성능이 거의 똑같다는 것을 입증했다. 또한 특히 한정된 transfer learning data를 사용할 수 있을 때, transfer learning이 빠르고 효과적이라는 것을 보였다. 하지만 논문에서는 충분히 큰 dataset에 대해 full model을 직접 학습시킨 것과 비교했을 때, 동일한 accuracy/sensitivity 성능을 얻지 못했다.
앞으로 simulation method가 발전함에 따라 synthetic dataset은 real world data distribution에 점차 가까워질 것이고, large scale real data를 획득 및 labeling 하는 비용이 많이 들고, 어려울 때 transfer learning과 data augmentation 기술은 모두 중요한 tool로 적용될 수 있을 것이다.
Reference
O’Shea, Timothy James, Tamoghna Roy, and T. Charles Clancy. "Over-the-air deep learning based radio signal classification." IEEE Journal of Selected Topics in Signal Processing 12.1 (2018): 168-179.
