0.Abstract
DenseNet은 다양한 receptive field를 Dense connection을 통해 중간 feature들을 보존하여 객체 탐지에서 좋은 성능을 보인다.
하지만 DenseNet backbone인 모델은 속도가 느리고 자원 사용 효율이 떨어진다. 이를 해결하기 위해 OSA(One-Shot Aggregation)로 구성된 VoVNet이라는 아키텍쳐를 제안한다.
1.Introduction
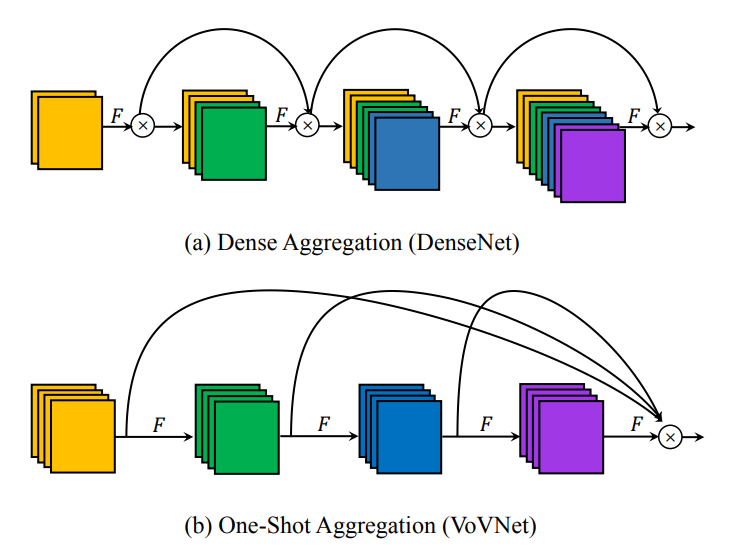
- DenseNet : 모든 layer들은 이전 feature들을 합쳐서 몇개의 새로운 출력만으로 입력의 크기를 증가시킨다.
- VoVNet : 마지막 feature map에서 모든 feature들을 한번에 연결하여 입력 크기를 일정하게 해주면서 출력의 크기를 증가시킨다.
( F : convolution layer , x : concatenation )
- DenseNet은 multiple receptive field의 feature map을 보존하고 축적하기 때문에 ResNet보다 다양하고 우수한 결과를 제공하지만, memory access cost(MAC)의 증가로 인한 많은 자원 사용과 GPU 병렬 계산에서의 병목 현상의 한계가 존재한다.
DenseNet의 concatenative aggregation은 가져가면서 효율적으로 개선하기 위해 VoVnet을 만듦
2.Factors of Efficient Network Design
주로 많은 연구들이 FLOPs나 모델의 크기를 줄이는데 우선시 해왔다. 하지만 FLOPs나 모델의 크기를 줄이는 것이 GPU inference time과 자원 사용을 줄이는데에 항상 영향을 주지는 않는다. efficient network design을 위해서는 다른 요인도 고려해야 된다는 것이다.
(FLOPs : 절대적인 연산량)
Memory Access Cost
CNN에서 자원 소모의 주된 원인은 메모리 엑세스이다. 특히, DRAM의 데이터를 엑세스하는 것은 더욱 많은 자원을 소비한다. 또한 이것이 GPU 프로세스의 병목 현상을 야기할 수 있다. MAC 계산은 다음과 같다.
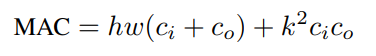
( k : 커널 크기, h/w : 입출력 높이/너비, ci/co : 입/출력 채널 크기)
GPU-Computation Efficiency
FLOPs을 줄이는 아키텍쳐는 부동 소수점 연산이 모두 동일한 속도로 처리된다는 아이디어를 기반으로 한다. 하지만 GPU에 배포됐다면 문제가 된다. GPU 병렬 처리 매커니즘 때문이다. GPU는 계산 능력을 효율적으로 활용하는 것이 중요한데, 이에 대해서 GPU-Computation Efficiency라는 용어를 사용한다.
일반적으로 GPU 계산 효율성은 모델마다 다르기 때문에 실제 GPU 추론 시간을 전체 FLOP에서 나누어 계산하는 FLOP/s(FLOPS)를 사용한다. FLOP/s가 높으면 GPU 전력을 효율적으로 사용하는 것을 의미한다.
3.Proposed Method
Rethinking Dense Connection
DenseNet은 성능 면에서 trade는 좋아보이지만, 에너지와 시간 면에서는 몇 가지 단점이 있다.
1. dense connection은 에너지와 시간이 많이 쓰이는 MAC를 야기한다.
2. dense connection은 GPU 병렬 계산에서 문제가 되는 병목 아키텍쳐의 사용을 요구한다.
입력의 크기가 선형적으로 증가하면 깊이는 그에 제곱으로 커지므로 문제가 된다. 이를 해결하기 위해 3 x 3 convolutaion layer의 입력의 크기를 일정하게 유지하기 위해 1 x 1 convolution layer를 추가하여 아키텍쳐를 완성한다.
이러한 단점 때문에 효율적이지 못하다.
One-Shot Aggregation
위의 그림 1(b)에서 보여주듯이 마지막 layer에서 한번에 feature를 OSA 모듈에 합친다. DenseNet과의 다른 점은 각 layer의 출력이 중간 layer의 입력 크기를 일정하게 만드는 layer로 라우팅되지 않는 것이다.
CIFAR-10에서 성능이 약간 감소했지만, MAC가 약 1/3 감소하였다. 또한 OSA는 GPU 계산 효율을 올려준다.
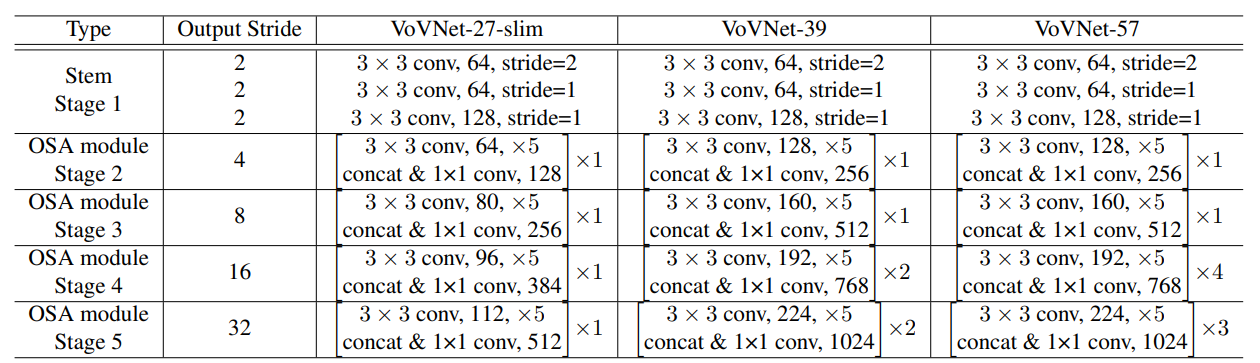
Configuration of VoVNet
OSA 모듈의 feature representation과 효율성으로 몇개의 모듈만으로 높은 정확도와 빠른 속도를 가진 VoVNet을 구성할 수 있다.
4.Experiments
VoVNet vs DenseNet
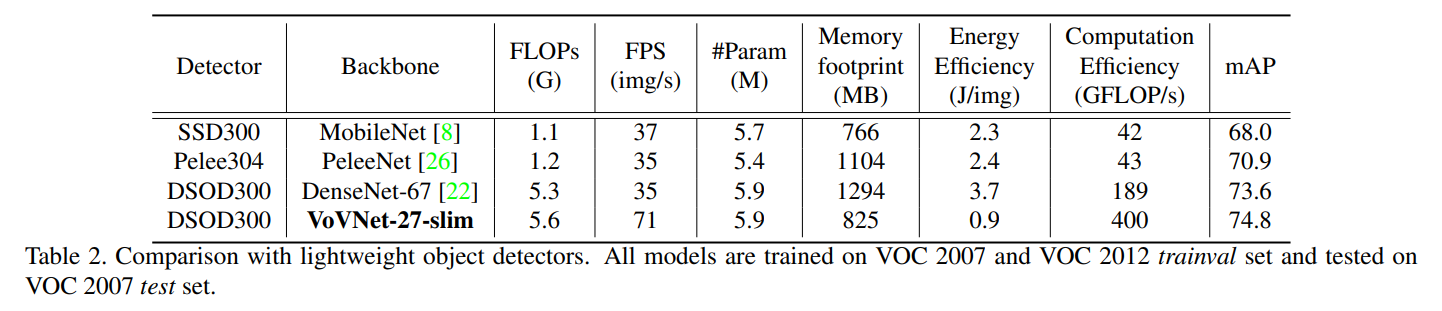
VoVNet-27-slim 기반 DSOD300은 74.87%로 DenseNet-67보다 성능이 좋음을 보였다. 또한 속도도 비슷한 FLOP을 사용하는 다른 모델보다 2배 빠른 것을 보였다.
DenseNet 변형 백본인 Pelee는 FLOP을 DenseNet-67보다 약 5배 적게 줄였다. 하지만 FLOP이 더 적음에도 비슷한 속도를 가진다. 논문에서는 dense block을 더 작은 layer로 분해하면 GPU 컴퓨팅 병렬 처리가 저하된다고 추측한다. VoVNet-27 slim 기반 DSOD도 3.97%의 차이로 더 좋은 성능을 보였다.
GPU-Computation Efficiency
네트워크가 GPU 컴퓨팅 리소스를 얼마나 잘 사용하는지를 나타내는 FLOP/s를 GPU 컴퓨팅 효율성으로 본다. 이는 VoVNet-27 slim이 400GFLOP/s로 가장 높고 MobileNet과 Pelee보다 약 10배 높음을 보인다.
5.Conclusion
실시간 객체 탐지를 위해 DenseNet의 단점(비효율성)을 개선한 VoVNet backbone network이다. OSA(One-Shot Aggregation)는 최종 feature map의 모든 feature를 한번에 모아 input 채널을 선형적으로 증가시키는 문제를 해결한다. 그 결과 MAC를 줄이고 GPU 효율성을 증가시켰다.
