
기존의 머신러닝은 단일 작업 학습의 방식이다. 이 방식은 새롭거나 예상치 못한 것이 없고, 고립된 학습 방법이다보니 지식의 축적이나 이전이 불가능하다. 또한 모델을 수정하지 않아 학습이나 적응을 하지 못한다. 따라서 모델을 적용한 중에 학습을 수행하여 이러한 문제를 해결할 수 있다.
사람의 지식은 단기기억과 장기기억으로 나눠지는데, 새로운 정보(단기기억) 중 중요도를 판별해서 배경지식(장기기억)으로 저장한다. 새롭게 무언가를 배웠다고 해서 이전에 배운 것들을 잊어버리거나 못하지 않는다. 이와 같이 Continual learning을 통해 학습한 모든 task의 수행이 가능한 모델을 만들 수 있다.
배경
● Task : 풀고 싶은 문제나 컴퓨터가 해야 할 작업
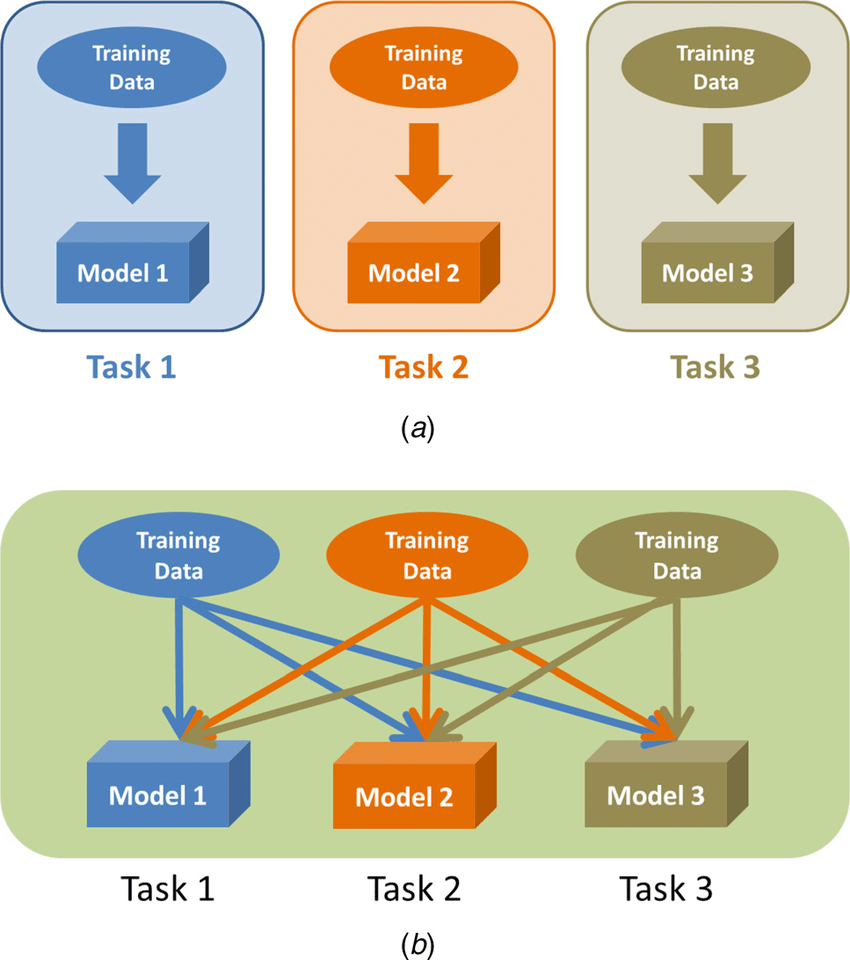
● Single-task learning (a) : 단일 task를 학습하는 방법론
● Multi-task learning (b) : 여러 task를 동시에 학습하는 방법론
지식 전이(knowledge transfer)를 통해 성능이 향상되는 것을 목표로 한다.
Task간 지식이 서로 공유되고, 전이되어 single-task보다 성능이 향상된다.
● Offline learning : 데이터셋을 한번에 주어주고 모델을 학습시킨다. (=Batch learning)
● Online learning : 데이터를 subset(mini-batch)형태로 순차적으로 주어주고 모델을 학습시킨다. 학습에 사용한 데이터는 저장이 불가능하여서 나중에 사용할 수 없다.
● Catastrophic forgetting(파괴적 망각)
Neural Network(인공신경망)은 single-task에 대해서는 뛰어난 성능을 보이지만, 다른 종류의 task를 학습하면 이전에 학습했던 task에 대한 성능이 현저하게 떨어진다.
신경망 모델이 이전 dataset으로 학습한 모델에 새로운 dataset을 학습하면 두 dataset간에 관련이 있다하더라도 이전 dataset에 대한 정보를 대량으로 손실이 난다.
● Semantic drift(의미 변화)
새로 학습하는 과정에서 pretrained weight가 과도하게 조정될 경우를 neural network의 node나 weight의 의미가 변했다고 해석할 수 있다.
예를 들어 어떤 node가 강아지의 귀에 대한 정보를 담고 있었는데, 고야잉를 학습한 후 node가 발바닥에 대한 정보를 처리하도록 바뀌는 것이다.
"데이터는 시간의 흐름에 따라 끊임 없이 성장한다."
- 연구의 방향이나 시장의 수요에 따라 데이터 / 클래스가 세분화된다.
- 증감된 데이터 / 클래스에 따라 새로운 task가 부여되기도 한다.
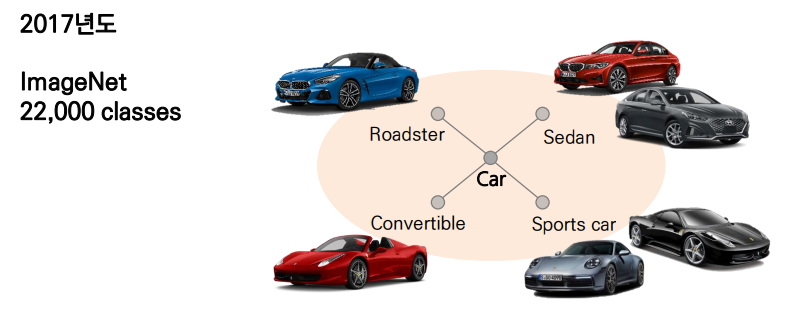
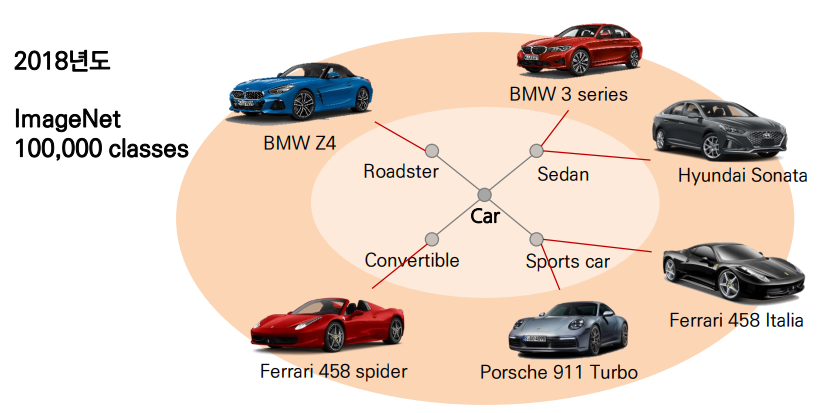

Continual learning 이란?
장기기억으로 넘어간 지식은 새로운 것을 배운다고 하더라도 잊어버리지 않는 인간의 인지를 모방하여 Neural network의 단점인 Catastrophic forgetting과 semantic drift를 해결하려고 만들어진 모델이다. 주요한 특징으로는 multi-task learning과 online learning이 있다. 여러 task를 하나의 모델에 순차적으로 학습하여 최종적으로 모든 task의 수행이 가능한 모델을 학습한다.
1. Memory Replay
학습 데이터를 나중에 사용할 수 없으니 진짜처럼 보이는 가짜 학습 데이터를 생성하는 generator 만듦.
진짜같은 가짜 학습 누적 데이터로 모델링
Ex) Deep generative replay(Kamra, N., Gupta, U. & Liu, Y., 2018)
2. Regulrization approach
네트워크 구조를 바꾸지 않는다.
새롭게 파라미터를 업데이트할 때, 이전 task에서 중요했던 파라미터는 조금만 변경되도록 regularization term을 추가한다.
Ex) Elastic weight consolidation (Kirkpatrick et al., 2017)
뉴럴 네트워크 확장하지 않고, weight들간의 차이를 최소화한다.
이전과 현재 task의 정보(파라미터, feature)를 같이 사용한다.
3. Dynamic architecture
새로운 task를 수용하기 위해 네트워크 구조를 동적으로 변경하여 catastrophic forgetting 문제 완화
네트워크의 neurons 또는 layers의 개수를 증가시키고 미세조정(fine-tuning)
Ex) Progressive networks - catastrophic forgetting 문제는 완화되지만, 학습되는 task가 증가할수록 네트워크 복잡도가 증가
이전에 배운 뉴런들을 고정시켜 더 학습이 안되게끔 하여 catastrophic forgetting을 방지
Ex) Dynamically expandable networs - Progressive networks의 한계점인 모델 아키텍쳐의 복잡도를 낮춤.
새로운 task와 이전 task의 차이에 따라 네트워크를 유동적으로 증가
이전 task에서 구축한 파라미터도 선택적으로 학습
Dynamically Expandable Networks
- Selecitve retraining
1) 첫번째 task학습
t = 1일때, L1-regularization을 이용해 weight를 sparse하게 학습
모델의 복잡도가 낮아지고 모델 경량화 효과를 가진다. -> overfitting 방지
2) 새로운 task와 관련된 파라미터만 골라서 재학습
t번째 task와 관련된 파라미터 탐색(parameter selection)
탐색된 t번째 task와 관련된 파라미터만 업데이트 - Dynamic network expansion
1) 새로운 task를 더 잘 반영할 수 있도록 네트워크 확장
(1) Selective retraining한 모델이 새로운 task에 좋은 성능을 보이는지 확인한다.
새로운 task가 이전 task와 비슷하면 selective retraining으로 충분
task에 대해 loss를 계산하고 임계치보다 큰 경우 네트워크 확장
(2) 좋은 성능을 보이지 않는다면, 새로운 task난이도를 고려하여(dynamically) 네트워크 확장한다.
임의로 k개의 뉴런을 layer별로 추가
Group sparsity regularization - Neywork split / duplication
1) Catastrophic forgetting 발생 방지
(1) 각 뉴런에서 catastrophic forgetting 발생했는지 확인
(2) 발생한 뉴런 복제 후 재학습

안녕하세요, 혹시 "데이터는 시간의 흐름에 따라 끊임 없이 성장한다." 라는 내용 아래에 있는 그림의 출처를 알 수 있을까요? 감사합니다.