
GROUP BY절과 집계함수
GROUP BY
GROUP BY절은 SELECT문에서 특정 컬럼(또는 특정 컬럼 내 데이터를 가공해서)의 데이터를 기준으로 그룹핑을 하여 그룹핑한 데이터 기준으로 집계함수를 사용할 때 이용합니다.
- GROUP BY 에 작성한 컬럼 내 데이터를 기준으로 동일한 데이터끼리 그룹핑 합니다.
- GROUP BY절에는 컬럼명 또는 해당 컬럼을 가공해서 사용할 수 있습니다.
예를들어, 날짜 데이터가 있는 컬럼이라면to_char(컬럼이름, 'YYYY-MM')식으로 특정 년월 단위로 가공하여 그룹핑 할 수 있습니다. - HAVING절에서는 GROUP BY로 그룹핑한 데이터 기준으로 조건절을 작성할 수 있습니다.
💡
WHEREvsHAVING- WHERE절의 경우 GROUP BY로 그룹핑 하기전에 실행되기 때문에, 그룹핑한 데이터 기준으로 조건을 주기 위해서는 HAVING 절을 이용해야합니다.
- HAVING 절로도 WHERE절 처럼 그룹핑한 결과와 상관없이 이용할 수 있긴하지만, HAVING 절의 경우 인덱스를 활용하는데 한계가 있기 때문에 가능한 그룹핑과 상관없는 조건은 WHERE절에서 사용하고, HAVING절은 그룹한 후 조건 체크가 필요할 때만 사용하는게 옳습니다.
- GROUP BY절에는 여러 컬럼을 작성할 수 있으며, 작성한 순서대로 그룹핑 되기 때문에 작성 순서에 영향을 받는다는 점을 주의해야합니다.
-- 사용법
SELECT 컬럼1, 컬럼2,,,
FROM 테이블명
[WHERE 조건절]
GROUP BY 기준컬럼1, 기준컬럼2,,,
[HAVING 조건절]
[ORDER BY 컬럼,,,]
[LIMIT [시작 인덱스, ] 개수]
;
-- 사용예시
SELECT
memberID, SUM(orderAmount)
FROM tbl_orderinfo
GROUP BY memberId
;GROUP BY vs OVER(PARTITION BY 컬럼)
GROUP BY 컬럼: 해당 SELECT문 전체를 지정된 열 내 동일한 데이터끼리 그룹화합니다.OVER(PARTITION BY 컬럼): 집계함수와 함께 사용하는 구문으로, 지정된 열 내 동일한 데이터끼리 그룹화 하는 구문 입니다.
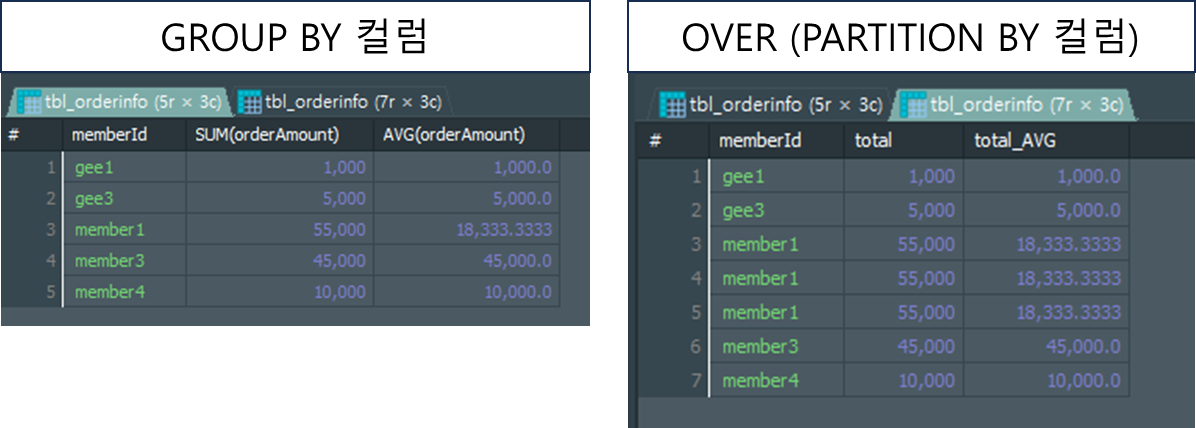
차이점
GROUP BY의 경우 해당 SELECT문 결과셋 자체에 대해 구룹핑하여 최종 결과셋을 출력하는 반면,OVER(PARTITION BY 컬럼)은 해당 열에 대해서만 구룹핑한 결과만을 출력하기 때문에 집계함수를 쓸 때마다 해당 구문을 작성해줘야합니다.GROUP BY의 경우 그룹핑한 데이터를 기준으로 한 행의 데이터만 표시하지만,OVER(PARTITION BY 컬럼)은 데이터 개수만큼 전부 동일한 데이터를 표시하게 됩니다.
-- GROUP BY VS OVER(PARTITION BY) 비교
# GROUP BY
SELECT
memberId
, SUM(orderAmount)
, AVG(orderAmount)
FROM tbl_orderinfo
GROUP BY memberID
;
# OVER(PARTITION BY)
SELECT
memberId
, SUM(orderAmount) OVER (PARTITION BY memberId) AS total
, AVG(orderAmount) OVER (PARTITION BY memberId) AS total_AVG
FROM tbl_orderinfo
;💡
OVER(PARTITION BY 컬럼)으로도 GROUP BY처럼 결과셋을 출력할 수 있다?
OVER(PARTITION BY)구문으로 작성된 경우에도DISTINCT키워드를 추가하여, 중복된 행을 제거하면 GROUP BY를 사용했을 때와 같은 결과셋을 반환 받을 수 있습니다.# 그냥 OVER(PARTITION BY 컬럼) SELECT memberId , SUM(orderAmount) OVER (PARTITION BY memberId) AS total , AVG(orderAmount) OVER (PARTITION BY memberId) AS total_AVG FROM tbl_orderinfo ; # DISTINCT + OVER (PARTITION BY 컬럼) SELECT DISTINCT memberId , SUM(orderAmount) OVER (PARTITION BY memberId) AS total , AVG(orderAmount) OVER (PARTITION BY memberId) AS total_AVG FROM tbl_orderinfo ;
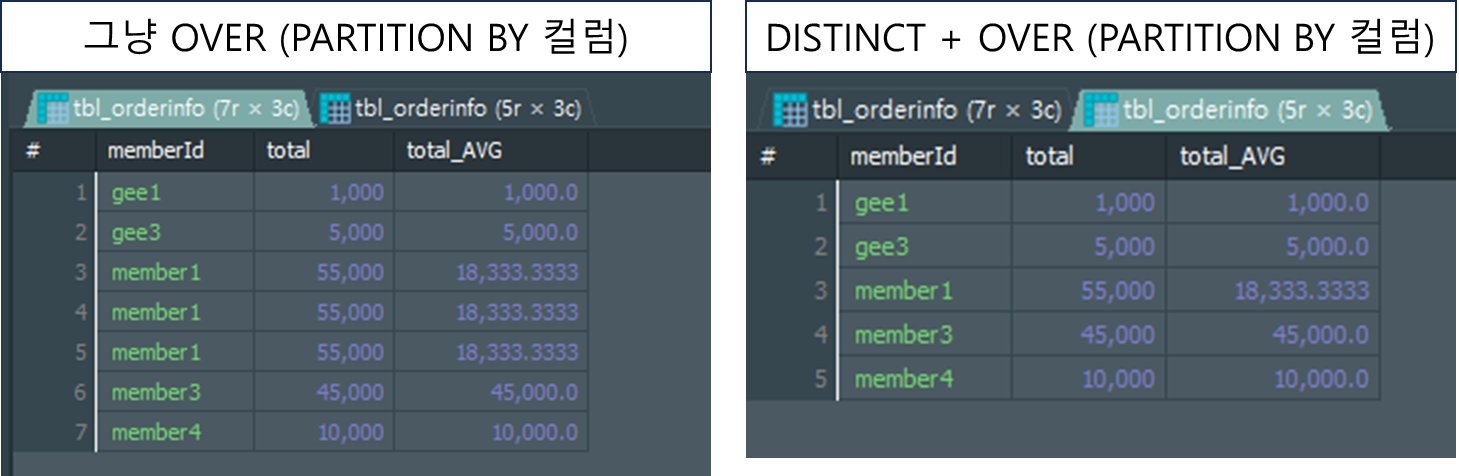
집계함수
집계함수는 GROUP BY없이 그냥도 사용할 수 있지만 특정 그룹별 집계를 조회하기 위해 GROUP BY절과 함께 자주 사용 됩니다.
아래는 자주 사용되는 집계함수를 확인해보겠습니다!
SUM()
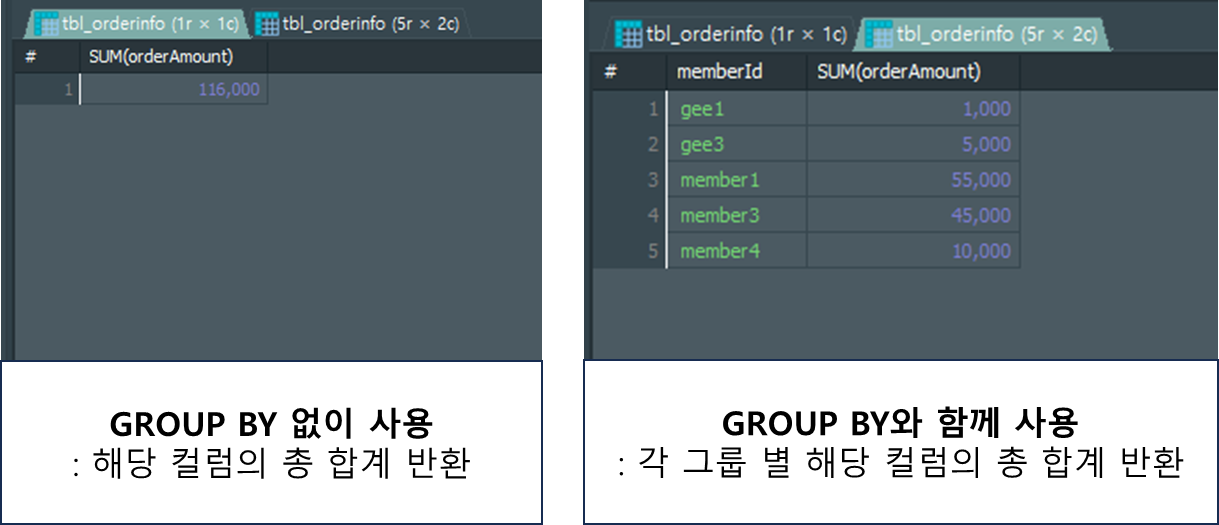
인자로 넣은 컬럼을 모두 더하여 합계를 반환해주는 집계함수 입니다.
GROUP BY절과 함께 사용 시 그룹핑한 그룹 별 합계를 반환해 줍니다.
-- 사용법
SELECT SUM(컬럼) FROM 테이블;
-- 사용예시
# GROUP BY 없이 사용
SELECT SUM(orderAmount) # 해당 테이블 내 orderAmount 열 모든 데이터를 합한 값 출력됨.
FROM tbl_orderinfo
;
# GROUP BY와 함께 사용
SELECT
memberId
, SUM(orderAmount)
FROM tbl_orderinfo
GROUP BY memberId
;AVG()
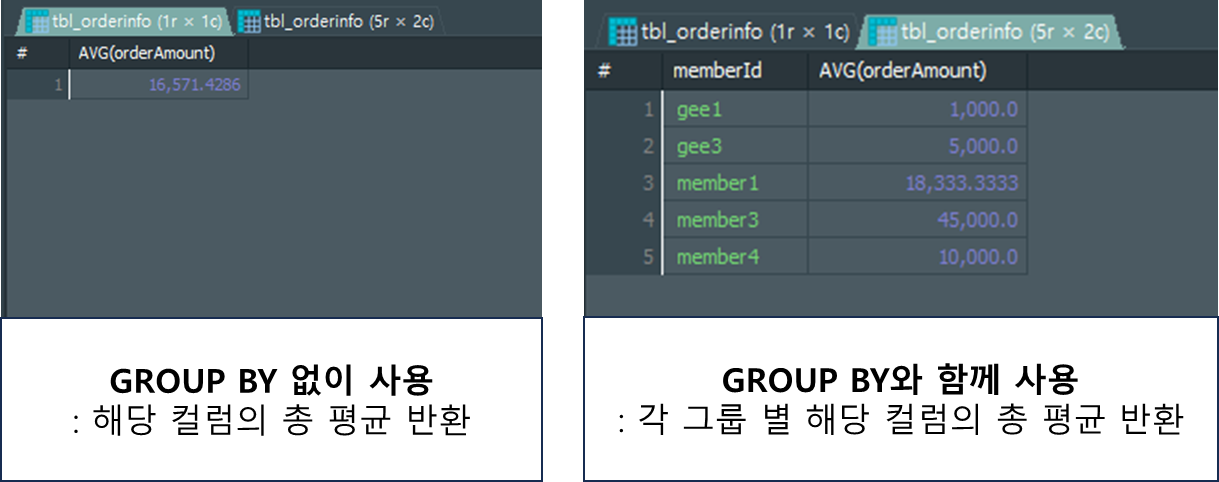
인자로 넣은 컬럼의 평균을 반환해주는 집계함수 입니다.
GROUP BY절과 함께 사용 시 그룹핑한 그룹 별 평균 반환해 줍니다.
-- 사용법
SELECT AVG(컬럼) FROM 테이블;
-- 사용예시
# GROUP BY 없이 사용
SELECT AVG(orderAmount)
FROM tbl_orderinfo
;
# GROUP BY와 함께 사용
SELECT
memberId
, AVG(orderAmount)
FROM tbl_orderinfo
GROUP BY memberId
;MAX() / MIN()
인자로 넣은 컬럼에서 가장 큰 값(MAX), 가장 작은 값(MIN)을 반환해주는 집계함수 입니다.
GROUP BY절과 함께 사용 시 그룹핑한 그룹 별 가장 큰 값(MAX), 가장 작은 값(MIN)을 반환해 줍니다.
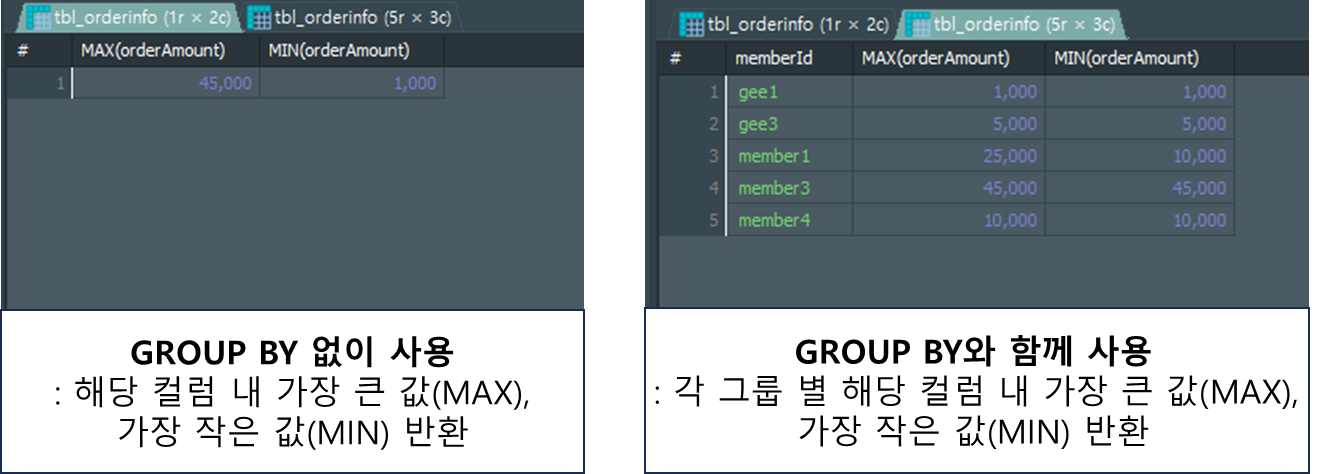
-- 사용법
SELECT MAX(컬럼), MIN(컬럼) FROM 테이블;
-- 사용예시
# GROUP BY 없이 사용
SELECT
MAX(orderAmount)
, MIN(orderAmount)
FROM tbl_orderinfo
;
# GROUP BY와 함께 사용
SELECT
memberId
, MAX(orderAmount)
, MIN(orderAmount)
FROM tbl_orderinfo
GROUP BY memberId
;COUNT()
인자로 넣은 컬럼의 데이터 개수(행 개수)를 반환해주는 집계함수 입니다.
GROUP BY절과 함께 사용 시 그룹핑한 그룹 별 데이터 개수(행 개수)를 반환해 줍니다.
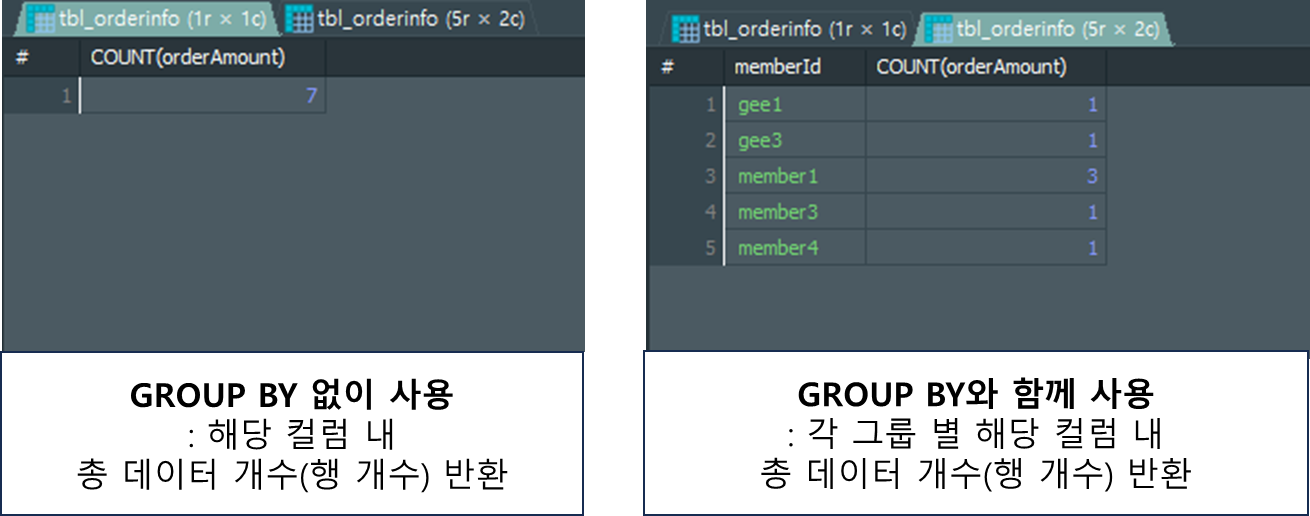
-- 사용법
SELECT COUNT(컬럼) FROM 테이블;
-- 사용예시
# GROUP BY 없이 사용
SELECT COUNT(orderAmount)
FROM tbl_orderinfo
;
# GROUP BY와 함께 사용
SELECT
memberId
, COUNT(orderAmount)
FROM tbl_orderinfo
GROUP BY memberId
;WITH ROLLUP절
WITH ROLLUP절의 경우 GROUP BY절에 사용할 수 있으며 그룹핑 된 그룹별 총 합계를 만들어주는 구문 입니다.
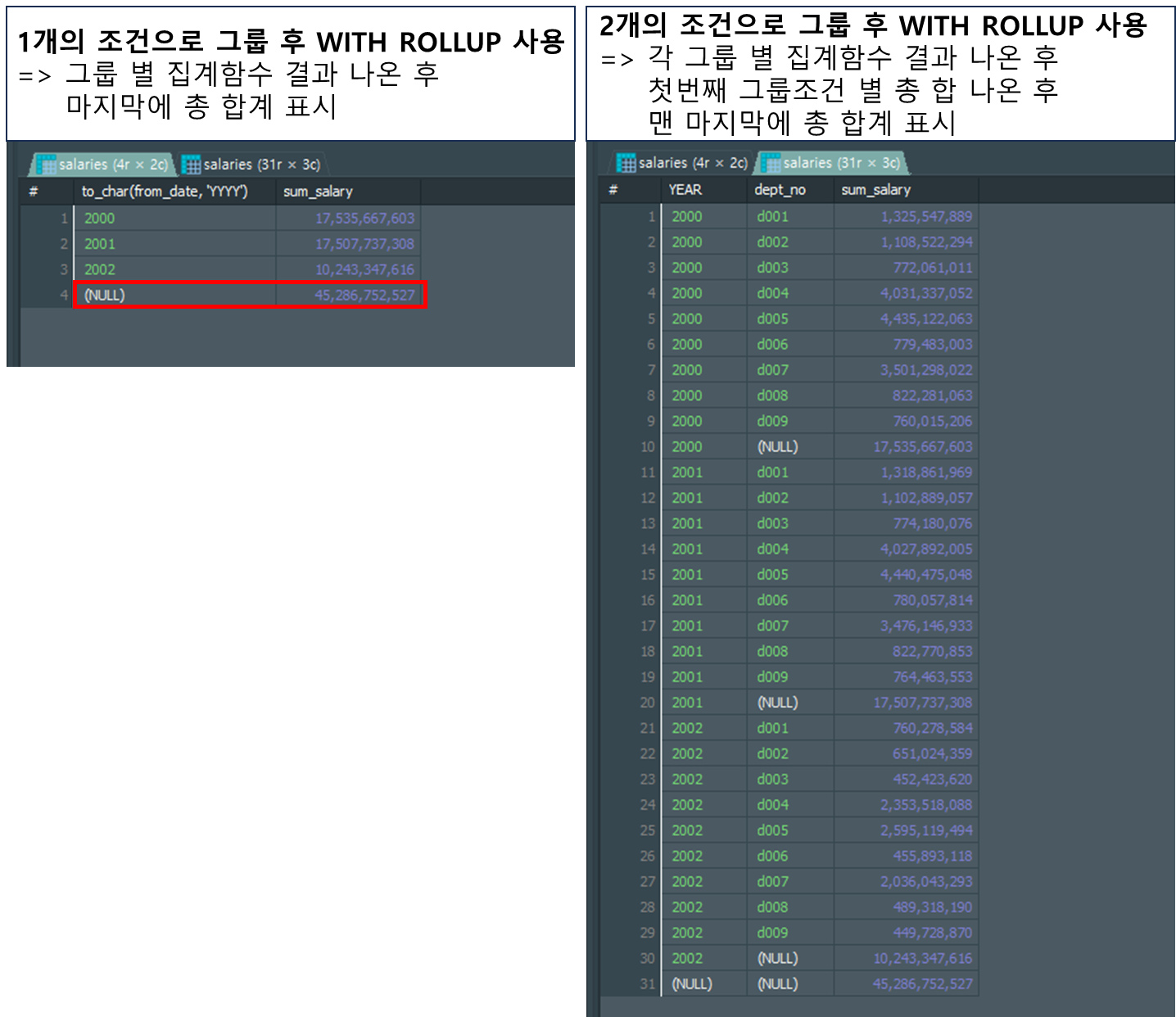
-- 사용법
SELECT 컬럼1, 컬럼2,,,
FROM 테이블명
[WHERE 조건절]
GROUP BY 기준컬럼1, 기준컬럼2,,, WITH ROLLUP
[HAVING 조건절]
[ORDER BY 컬럼,,,]
[LIMIT [시작 인덱스, ] 개수]
;
-- 사용예시
# 1개의 조건으로 그룹 후 WITH ROLLUP 사용
SELECT
to_char(from_date, 'YYYY')
, SUM(salary) AS sum_salary
FROM salaries
WHERE from_date BETWEEN '2000-01-01' AND '2002-12-31'
GROUP BY to_char(from_date, 'YYYY') WITH ROLLUP;
# 2개의 조건으로 그룹 후 WITH ROLLUP 사용
SELECT
to_char(A.from_date, 'YYYY') AS 'YEAR'
, C.dept_no, SUM(A.salary) AS sum_salary
FROM salaries AS A
INNER JOIN ( # dept_emp에서 부서가 여러개인 사원들이 있어서 한 건만 나올 수 있도록 인라인 뷰 작성
SELECT emp_no, dept_no
FROM dept_emp
GROUP BY emp_no
) AS B ON B.emp_no = A.emp_no
INNER JOIN departments AS C ON C.dept_no = B.dept_no
WHERE A.from_date BETWEEN '2000-01-01' AND '2002-12-31'
GROUP BY to_char(A.from_date, 'YYYY'), C.dept_no WITH ROLLUP;💡 실습 : 다차원 피벗 테이블 만들어보기
- 요청사항
salary 테이블 에서 직원번호가 10001 ~ 10020인 직원들의 1990년 ~ 2002년 까지의 연봉 평균 데이터를 주세요
- 풀이
SELECT emp_no , AVG(case YEAR(from_date) when 1990 then salary ELSE 0 END) AS '1990년' , AVG(case YEAR(from_date) when 1991 then salary ELSE 0 END) AS '1991년' , AVG(case YEAR(from_date) when 1992 then salary ELSE 0 END) AS '1992년' , AVG(case YEAR(from_date) when 1993 then salary ELSE 0 END) AS '1993년' , AVG(case YEAR(from_date) when 1994 then salary ELSE 0 END) AS '1994년' , AVG(case YEAR(from_date) when 1995 then salary ELSE 0 END) AS '1995년' , AVG(case YEAR(from_date) when 1996 then salary ELSE 0 END) AS '1996년' , AVG(case YEAR(from_date) when 1997 then salary ELSE 0 END) AS '1997년' , AVG(case YEAR(from_date) when 1998 then salary ELSE 0 END) AS '1998년' , AVG(case YEAR(from_date) when 1999 then salary ELSE 0 END) AS '1999년' , AVG(case YEAR(from_date) when 2000 then salary ELSE 0 END) AS '2000년' , AVG(case YEAR(from_date) when 2001 then salary ELSE 0 END) AS '2001년' , AVG(case YEAR(from_date) when 2002 then salary ELSE 0 END) AS '2002년' FROM salaries WHERE (from_date BETWEEN '1990-01-01' AND '2002-12-31') AND emp_no <= 10020 GROUP BY emp_no WITH ROLLUP ;
- 결과
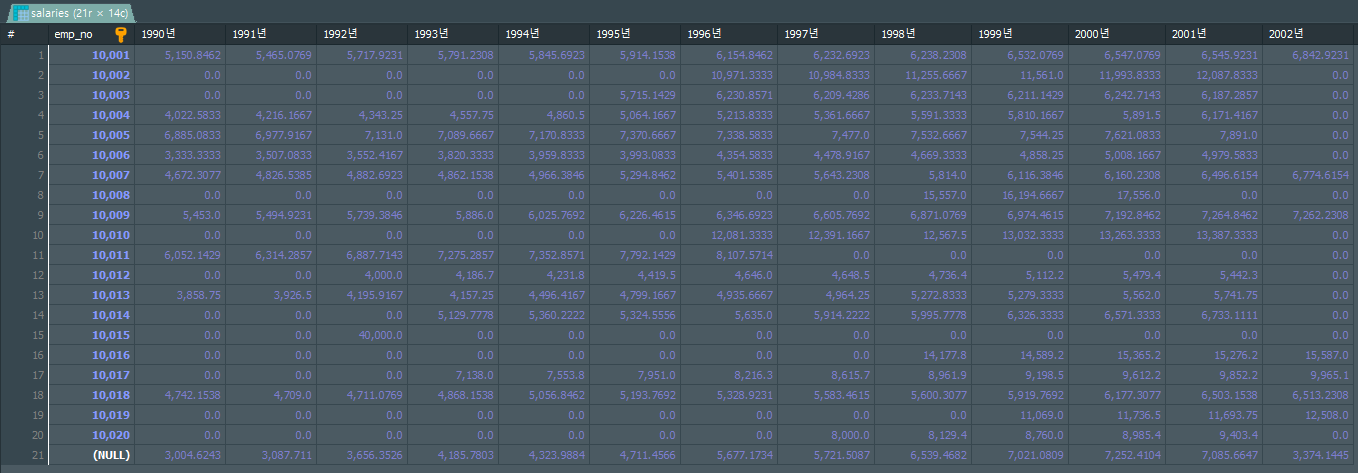
참고
MariaDB로 따라 하며 배우는 SQL프로그래밍 데이터베이스 기초에서 실무까지 - 나익수, 서연경 지음
위 책을 공부하며 작성하고 있습니다!
