
순위 함수
순위 함수는 결과셋을 바탕으로 특정기준으로 데이터의 순위를 매겨주는 함수 입니다.
순위 함수, 랭크 함수, 윈도우 함수라고도 부릅니다.
ROW_NUMBER()RANK()DENSE_RACK()NTILE()PERCENT_RANK()CUME_DIST()LEAD()FIRST_VALUE(),LAST_VALUE()
대표적으로 위 종류가 있으며, 해당 함수 모두 사용 시 OVER()절과 함께 사용된다는 특징이 있습니다.
ROW_NUMBER() / RANK() / DENSE_RANK()
값 개별에 대해 순위를 매겨주는 함수들 입니다.
-- 사용법
# ROW_NUMBER()
ROW_NUMBER() OVER([PARTITION BY 그룹기준열] ORDER BY 순위기준열 {ASC/DESC})
# RANK()
RANK() OVER([PARTITION BY 그룹기준열] ORDER BY 순위기준열 {ASC/DESC})
# DENSE_RANK()
DENSE_RANK() OVER([PARTITION BY 그룹기준열] ORDER BY 순위기준열 {ASC/DESC})
-- 사용 예시
SELECT
CONCAT(MONTH(from_date),'월') AS mon
, emp_no, salary
, ROW_NUMBER() OVER(PARTITION BY MONTH(from_date) ORDER BY salary desc) AS 'row_number'
, RANK() OVER(PARTITION BY MONTH(from_date) ORDER BY salary desc) AS 'rank'
, DENSE_RANK() OVER(PARTITION BY MONTH(from_date) ORDER BY salary desc) AS 'dense_rank'
FROM salaries
WHERE (from_date >= '2002-01-01')
ORDER BY MONTH(from_date) ASC, salary DESC
;PARTITION BY 그룹기준열: 작성한 컬럼의 데이터 기준으로 데이터를 그룹화 합니다. (생략하면 전체 기준으로 순위매김)ORDER BY 순위기준열 [정렬조건]: 작성한 컬럼의 정렬조건 기준으로 순위를 산정합니다.
동률 값에 대한 순위 지정 방식의 차이점이 있으며 이외에는 동일합니다.
- ROW_NUMBER()
랭킹 매길 때 같은 값이 있어도 그냥 1,2,3순으로 쭉 매긴다는 특징이 있습니다.
1위 : 10 점
2위 : 8점
3위 : 8점
4위 : 8점
5위 : 5점- RANK()
랭킹 매길 때 같은 값이 있으면 같은 순위로 매기고 그 동률의 개수만큼 순위를 빼고 다음 순위 매깁니다.
1위 : 10 점
2위 : 8점
2위 : 8점
2위 : 8점
5위 : 5점- DENSE_RANK()
랭킹 매길 때 같은 값이 있으면 같은 순위로 매기고 해당 순위 이어서 다음 순위 매깁니다.
1위 : 10 점
2위 : 8점
2위 : 8점
2위 : 8점
3위 : 5점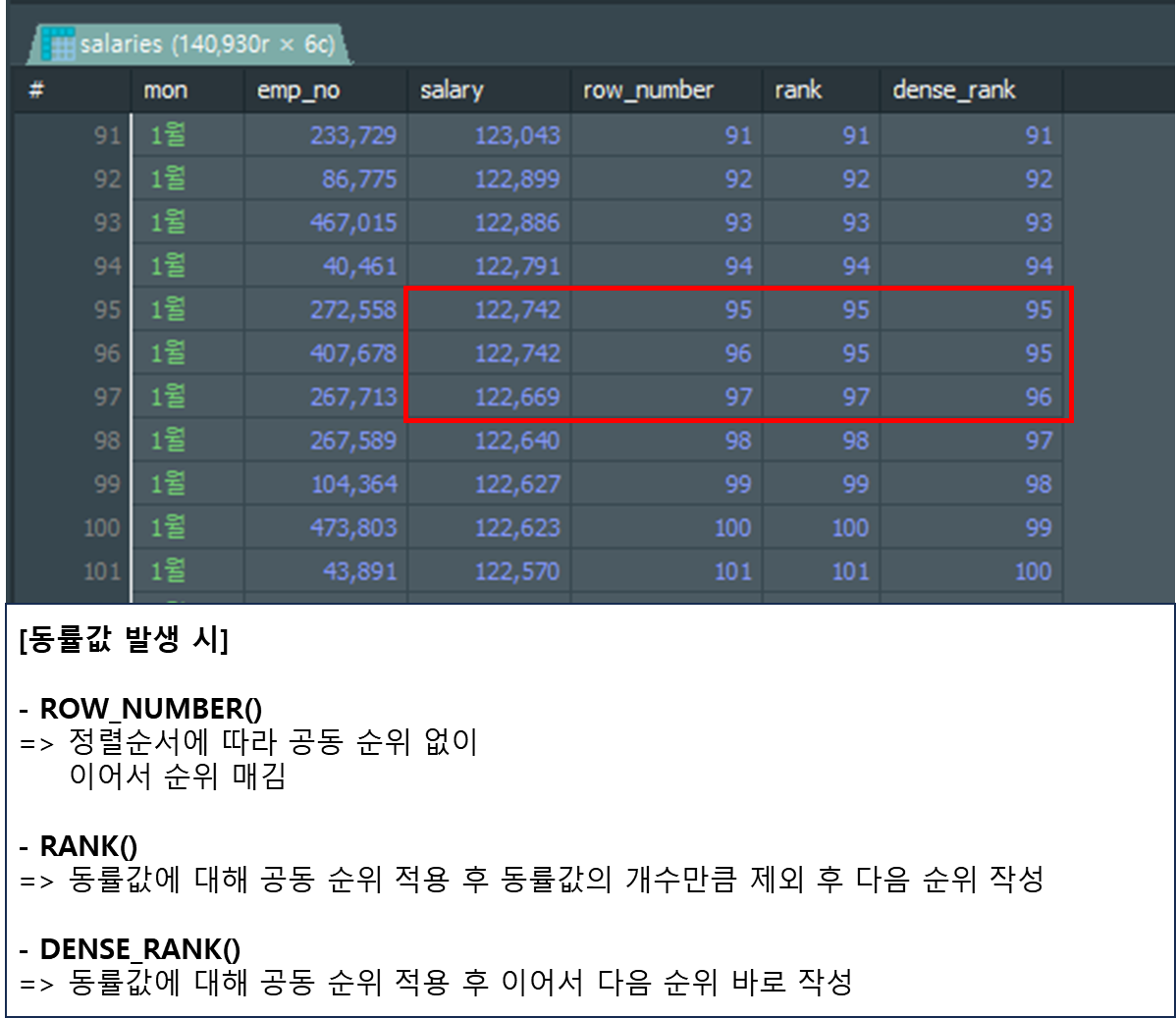
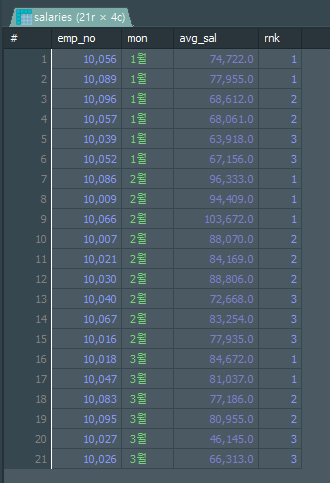
NTILE()
순위 그룹을 나눠서 해당 값의 어떤 순위 그룹에 들어있는지를 반환해주는 함수입니다.
-- 사용법
NTILE(그룹 개수) OVER([PARTITION BY 그룹기준열] ORDER BY 순위기준열 {ASC/DESC})
-- 사용예시
SELECT
emp_no
, CONCAT(MONTH(from_date), '월') AS mon
, AVG(salary) AS avg_sal
, NTILE(3)
OVER(PARTITION BY MONTH(from_date) ORDER BY AVG(salary) DESC) AS rnk
FROM salaries
WHERE (from_date BETWEEN '2002-01-01' AND '2002-03-31') && (emp_no < 10100)
GROUP BY MONTH(from_date), emp_no
ORDER BY MONTH(from_date), rnk ASC
;PERCENT_RANK() / CUME_DIST()
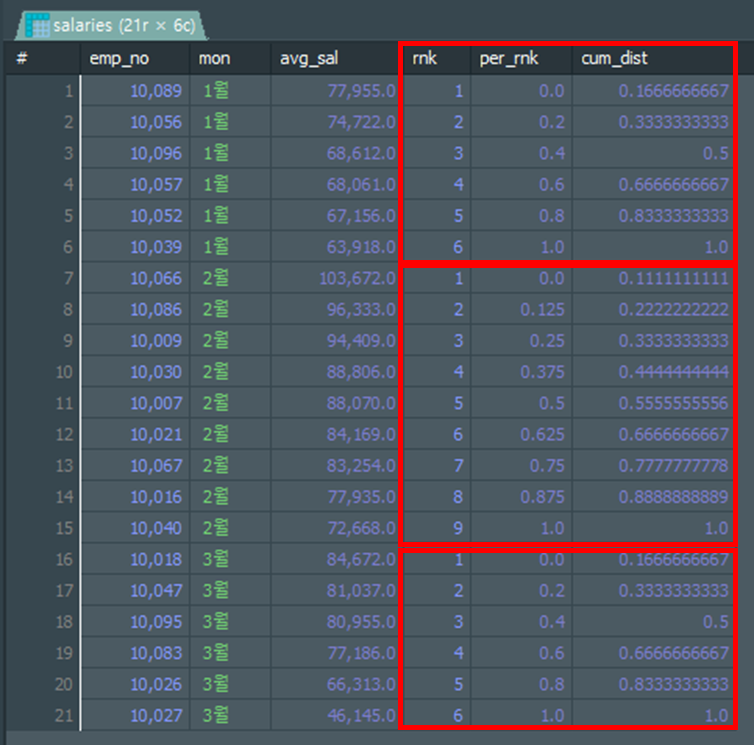
각 개별 순위를 매긴 후 해당 순위의 백분위를 구하는 함수입니다.
PERCENT_RANK()
입력한 기준의 순위에서 해당 값이 위치하는 상대 순위 백분율을 출력 합니다.
(현재순위 - 1) / (전체행수 -1)CUME_DIST()
입력한 기준의 순위에서 해당 값이 위치하는 누적 분포 백분율을 출력 합니다.
(현재순위) / (전체행수)
-- 사용법
# PERCENT_RANK()
PERCENT_RANK() OVER([PARTITION BY 그룹기준열] ORDER BY 순위기준열 {ASC/DESC})
# CUME_DIST()
CUME_DIST() OVER([PARTITION BY 그룹기준열] ORDER BY 순위기준열 {ASC/DESC})
-- 사용예시
SELECT
emp_no
, CONCAT(MONTH(from_date), '월') AS mon
, AVG(salary) AS avg_sal
, RANK() OVER(PARTITION BY MONTH(from_date) ORDER BY AVG(salary) DESC) AS rnk
, PERCENT_RANK() OVER(PARTITION BY MONTH(from_date) ORDER BY AVG(salary) DESC) AS per_rnk
, CUME_DIST() OVER(PARTITION BY MONTH(from_date) ORDER BY AVG(salary) DESC) AS cum_dist
FROM salaries
WHERE (from_date BETWEEN '2002-01-01' AND '2002-03-31') && (emp_no < 10100)
GROUP BY MONTH(from_date), emp_no
ORDER BY MONTH(from_date), rnk ASC
;LEAD()
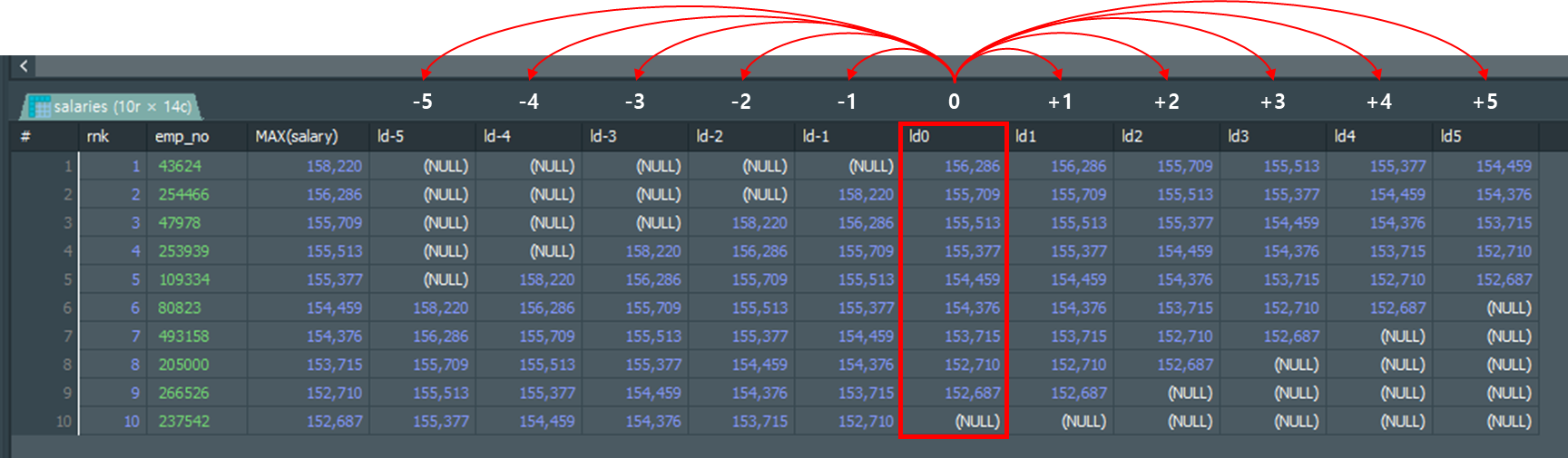
인자로 입력된 기준열 기준으로 입력된 오프셋만큼 거리의 행의 해당 열 값을 반환합니다.
(음수 : 위로 이동 / 양수 : 아래로 이동)
-- 사용법
LEAD(기준열[, 오프셋]) OVER(ORDER BY 순위기준열 {ASC/DESC})
-- 사용예시
SELECT
ROW_NUMBER() OVER(ORDER BY MAX(salary) DESC) AS rnk
, CONVERT(emp_no,VARCHAR(20)) AS emp_no
, MAX(salary)
, LEAD(MAX(salary), -5) OVER(ORDER BY MAX(salary) DESC) AS 'ld-5'
, LEAD(MAX(salary), -4) OVER(ORDER BY MAX(salary) DESC) AS 'ld-4'
, LEAD(MAX(salary), -3) OVER(ORDER BY MAX(salary) DESC) AS 'ld-3'
, LEAD(MAX(salary), -2) OVER(ORDER BY MAX(salary) DESC) AS 'ld-2'
, LEAD(MAX(salary), -1) OVER(ORDER BY MAX(salary) DESC) AS 'ld-1'
, LEAD(MAX(salary)) OVER(ORDER BY MAX(salary) DESC) AS 'ld0'
, LEAD(MAX(salary), 1) OVER(ORDER BY MAX(salary) DESC) AS 'ld1'
, LEAD(MAX(salary), 2) OVER(ORDER BY MAX(salary) DESC) AS 'ld2'
, LEAD(MAX(salary), 3) OVER(ORDER BY MAX(salary) DESC) AS 'ld3'
, LEAD(MAX(salary), 4) OVER(ORDER BY MAX(salary) DESC) AS 'ld4'
, LEAD(MAX(salary), 5) OVER(ORDER BY MAX(salary) DESC) AS 'ld5'
FROM salaries
GROUP BY emp_no
HAVING MAX(salary) BETWEEN 152687 AND 158220
ORDER BY rnk ASC
LIMIT 10
;FIRST_VALUE() / LAST_VALUE()
특정 기준으로 순위를 매긴 결과셋에서 첫번째 값(FIRST_VALUE()), 마지막 값(LAST_VALUE())를 반환해주는 함수 입니다.
FIRST_VALUE():OVER(ORDER BY)에 작성한 정렬순서에서 가장 첫번째 행을 반환 합니다.LAST_VALUE():OVER(ORDER BY)에 작성한 정렬순서에서 해당 행까지 정렬을 한 상태에서 마지막 행을 반환합니다.
즉, FIRST_VALUE() 정렬순선 상 항상 첫번째 행을 반환하기 때문에 항상 그 값이 같지만, LAST_VALUE()의 경우 현재 처리중인 행까지만 정렬한 상태에서 마지막 행을 반환하기 때문에 각 행마다 마지막 행으로 반환되는 값이 다를 수 있습니다.
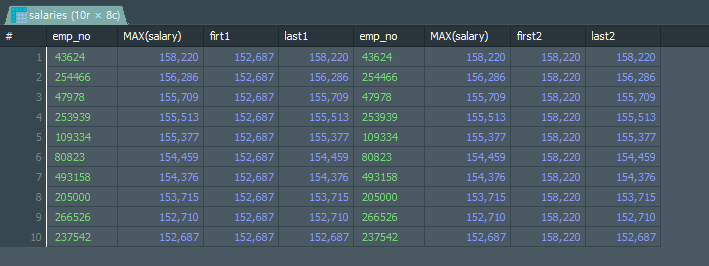
-- 사용법
# FIRST_VALUE()
FIRST_VALUE(기준열) OVER(ORDER BY 순위기준열 {ASC/DESC})
# LAST_VALUE()
LAST_VALUE(기준열) OVER(ORDER BY 순위기준열 {ASC/DESC})
-- 사용예시
SELECT
ROW_NUMBER() OVER(ORDER BY MAX(salary) ASC) AS rnk1
, CONVERT(emp_no,VARCHAR(20)) AS emp_no
, MAX(salary)
, FIRST_VALUE(MAX(salary)) OVER(ORDER BY MAX(salary) ASC) AS firt1
, LAST_VALUE(MAX(salary)) OVER(ORDER BY MAX(salary) ASC) AS last1
, ROW_NUMBER() OVER(ORDER BY MAX(salary) DESC) AS rnk1
, CONVERT(emp_no,VARCHAR(20)) AS emp_no
, MAX(salary)
, FIRST_VALUE(MAX(salary)) OVER(ORDER BY MAX(salary) DESC) AS first2
, LAST_VALUE(MAX(salary)) OVER(ORDER BY MAX(salary) DESC) AS last2
FROM salaries
GROUP BY emp_no
HAVING MAX(salary) BETWEEN 152687 AND 158220
ORDER BY MAX(salary) DESC
LIMIT 10
;참고
MariaDB로 따라 하며 배우는 SQL프로그래밍 데이터베이스 기초에서 실무까지 - 나익수, 서연경 지음
위 책을 공부하며 작성하고 있습니다!

블로그 이전 했습니다. 아래 블로그 아이콘(🏠) 눌러서 놀러오세요