Mixed Precision 이란?
- 처리 속도를 높이기 위한 FP16 과 정확도 유지를 위한 FP 32 를 섞어서 학습하는 방법
0. References
- Paper: Link
- ICLR 2018, Baidu, NVIDIA
- NVIDIA 기술 블로그
- 참고한 한국어 블로그
1. Introduction
- Baidu, NVIDIA, ICLR 2018
- 최근 대부분의 LLM 학습 시 기본으로 사용되고 있음
- FP32: Single Precision, FP16: Half Precision
- FP16 사용 시 필수로 고려하는 테크닉
- FP16 사용하면 메모리, 계산량 측면에서 2배 이득 (OOM 일 때 유용, 혹은 Batch Size 늘리고 싶을 때 유용)
2. Floating Point
- 기본적으로 우리가 실수를 표현하는 데 사용하는 방식은 FP32 방식임
- 그 중 제일 많이 쓰는 방식은 1 (부호) + 8 (지수 - exponent) + 23 (가수 - fraction) = 총 32
- 메모리, 계산량을 줄이기 위해서 FP16 을 사용하는 방향을 고려하게 됨
- 메모리, 계산량 측면에서 이득이 있지만 실수를 표현할 수 있는 범위가 줄어들게 됨
- 값이 너무 큰 경우나, 너무 작은 경우에 문제가 발생할 수 있음
- 주로
gradient 값이 매우 작은 경우에 문제가 발생
3. Mixed Precision Training
3.1 Problem
-
FP32 로 진행하면 학습이 잘 되던 것이 FP16 으로 했을 때 발산하는 현상이 발생
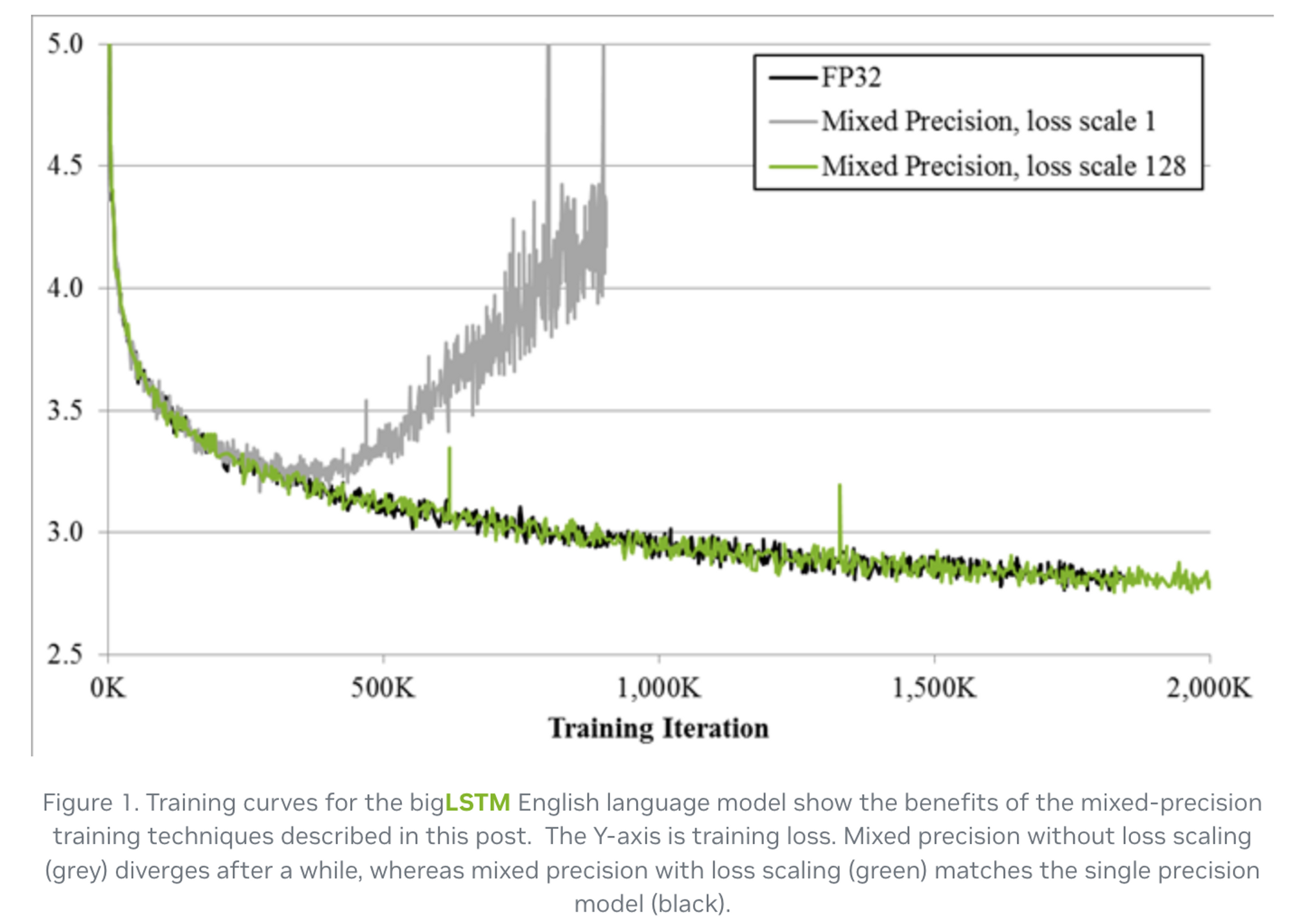
-
학습에 관여하는 Tensor 는 4가지로 나눌 수 있는데,
- activations
- activation gradients
- weights
- weight gradients
-
이 중 FP16 으로 변경하여 학습을 진행할 때, weights 와 weight gradients 는 FP16 범위 내에 잘 들어오는 편이었다고 함
-
문제가 생기는 activation gradients 의 경우, 굉장히 크기가 작은 일부 값들이 관측되었고, FP16 으로 표현할 수 있는 범위를 넘어서면서 강제적으로 0이 되어버리는 현상이 발생함 (
underflow) -
아래 그래프에서 빨간선 보다 왼쪽에 해당하는 케이스들이 become zero in FP16
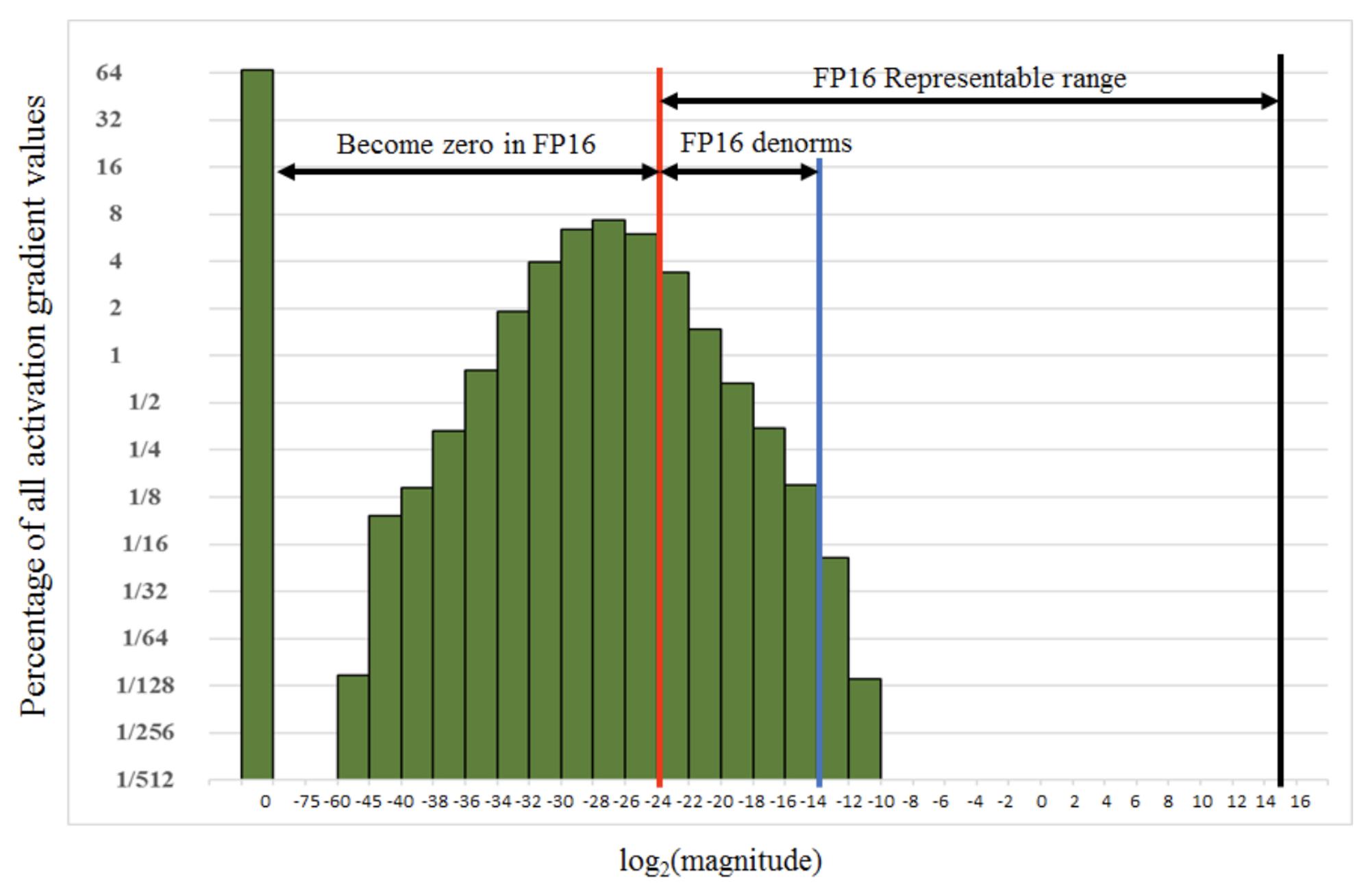
3.2 Solution
- 가장 간단하게 생각할 수 있는 방법은,
- 값이 작은 것이 문제이니, gradients 에 큰 수를 곱하여 값들을 오른쪽으로 shift 해보자!
- 간단하게 8 (scaling factor) 를 곱하여 실험을 돌려보니 SSD 가 학습이 잘 된다는 것을 발견
상세 Procedure
FP32 값은 저장하는 상태로, FP16 값을 이용하여 forward/backward 진행 (+ scale factor). FP16 결과로 얻은 gradients 를 기반으로 FP32 weights 업데이트
- Make an FP16 copy of the weights
- Forward propagate using FP16 weights and activations
- Multiply the resulting loss by the scale factor S
- Backward propagate using FP16 weights, activations, and their gradients
- Multiply the weight gradients by 1/S
- Optionally process the weight gradients (gradient clipping, weight decay, etc.)
- Update the master copy of weights in FP32
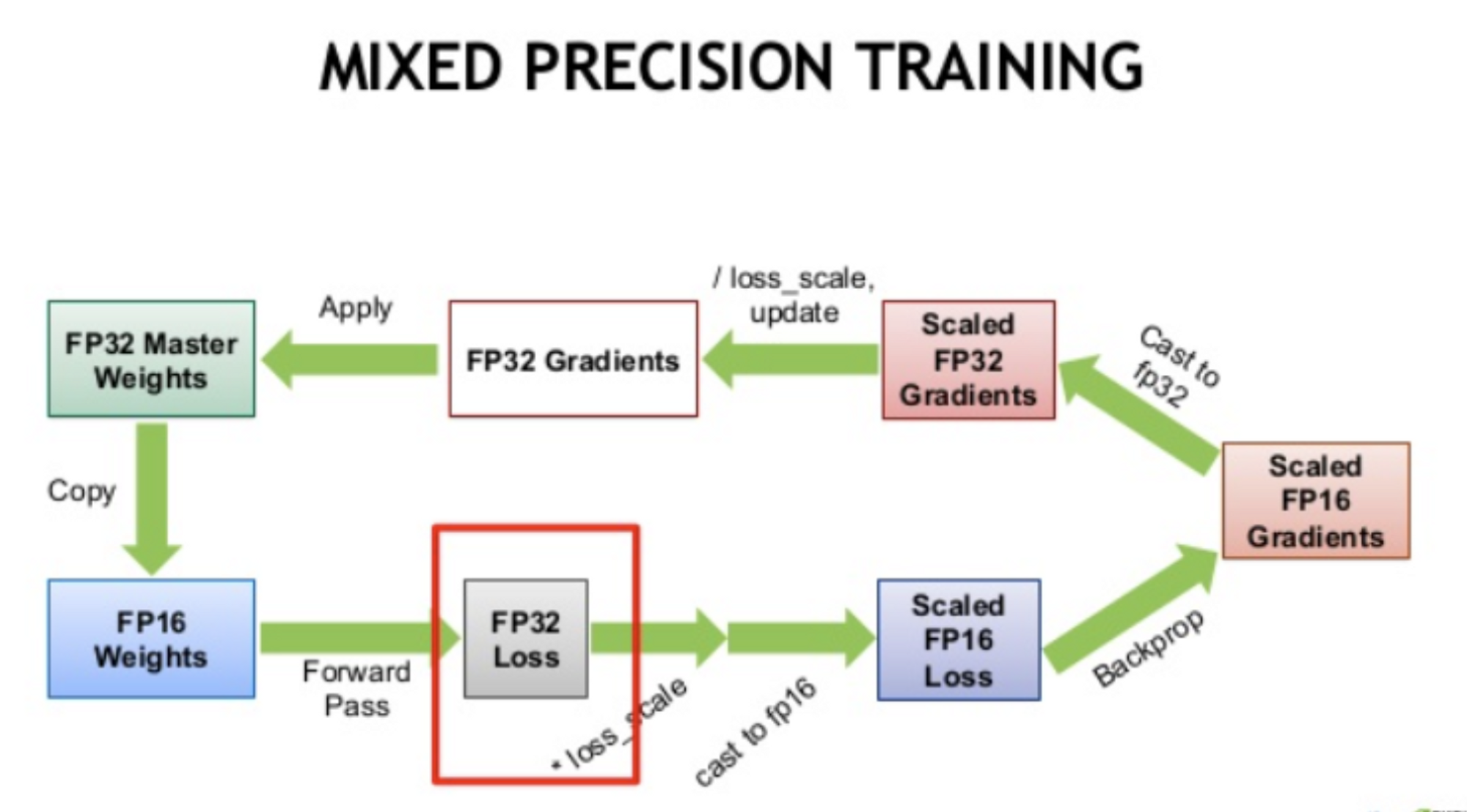
- Update the master copy of weights in FP32
4. Results
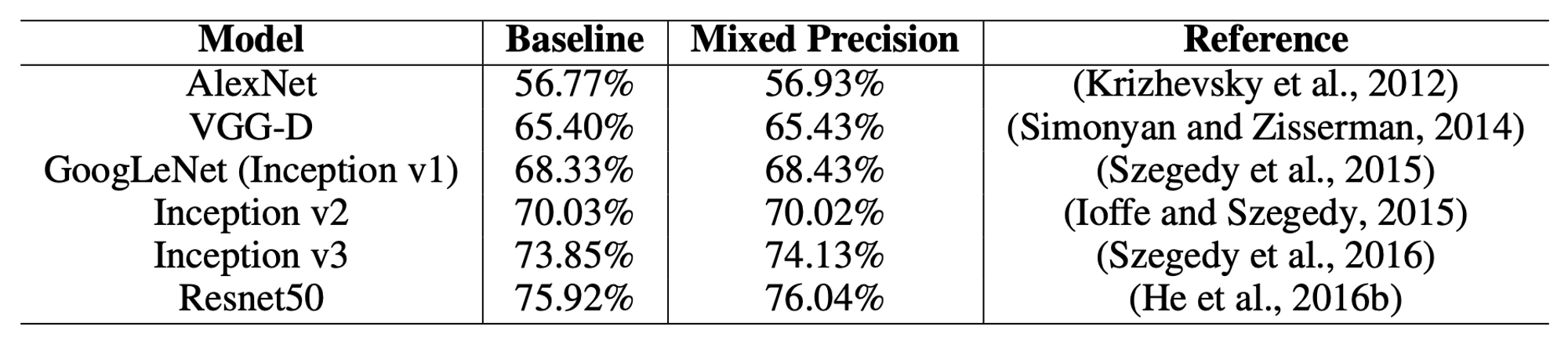
- 다양한 Task 에 대하여 실험 진행
- CLS 경우 Acc 거의 유지, SDD 경우는 발산하던 것이 잡힘
- 메모리는 대략 2배 정도 절감, 수렴을 향한 속도는 2 ~ 4배 정도 향상

5. Sample code
- GradScaler() 사용
- 코드 인용: https://github.com/hoya012/automatic-mixed-precision-tutorials-pytorch
""" define loss scaler for automatic mixed precision """
# Creates a GradScaler once at the beginning of training.
scaler = torch.cuda.amp.GradScaler()
for batch_idx, (inputs, labels) in enumerate(data_loader):
optimizer.zero_grad()
with torch.cuda.amp.autocast():
# Casts operations to mixed precision
outputs = model(inputs)
loss = criterion(outputs, labels)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(self.optimizer)
# Updates the scale for next iteration
scaler.update()
ML/DL Engineer 입니다. 유용한 정보들을 기록해두려 합니다.