- Our results strongly suggest that larger models will continue to perform better, and will also be much more sample efficient than has been previously appreciated.
- Big models may be more important than big data.
- Paper: Scaling Laws for Neural Language Models
- OpenAI, 2020
- 본격적인 LLM 시대 돌입에 대한 근거를 제시한 논문
Larger modelswill continue to performbetter
- 논문의 Summary 부분만 정리함. 각 항목 별 자세한 내용은 논문의 각 Section 참조
1. Introduction
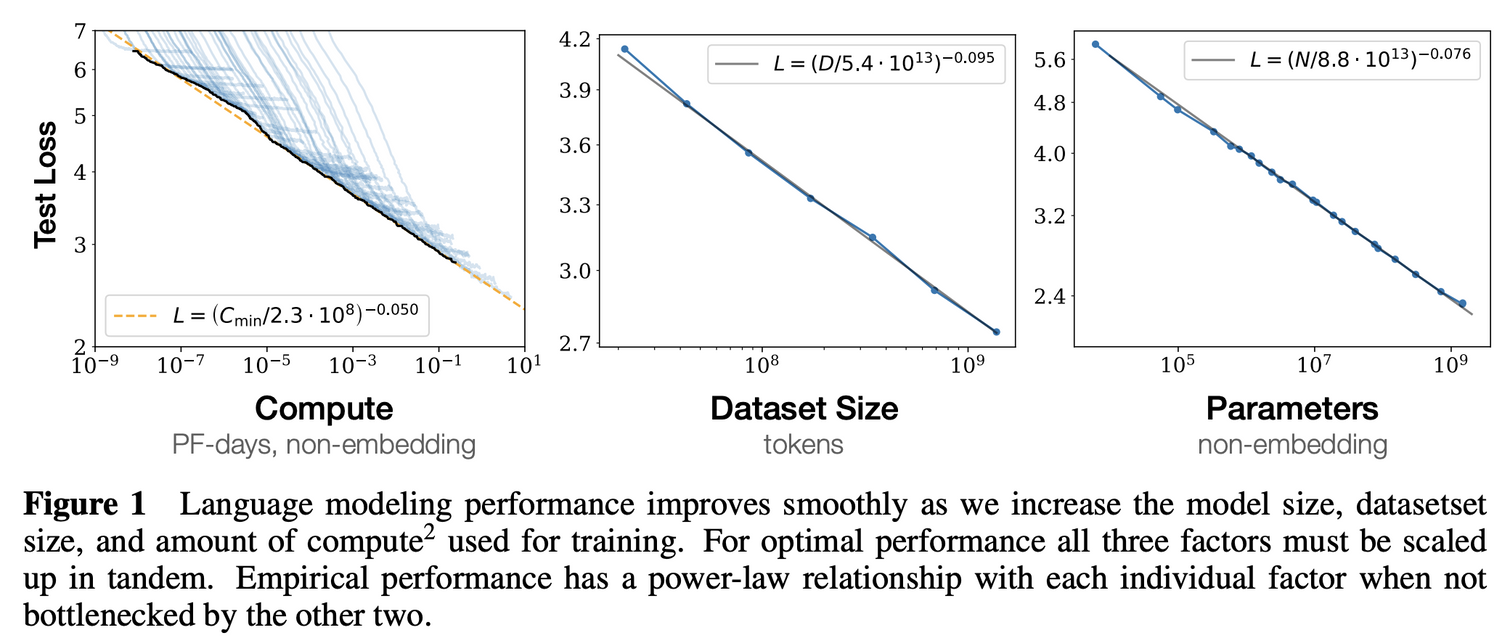
Empirical scaling lawsfor language model performance- Language model 에서의 scaling laws 를
N, D, C의 3개 factor 관점에서 수식화하여 정리parameters N,size of dataset D,amount of compute C
- 이 논문에서 측정하는 model performance 는
cross-entropy loss에 대한 performance 를 의미함
2. Summary
📌 [Summary]
- These results show that language modeling performance improves smoothly and predictably as we appropriately scale up model size, data, and compute.
- We expect that larger language models will perform better and be more sample efficient than current models.
2.1 Performance depends strongly on scale, weakly on model shape
- 학습 시 Language model 의 scale 을 결정짓는 3개의 factor 를 정의하였음
- parameters N, size of dataset D, amount of compute C
- Model performance 는 3 요소의 scale 에 가장 디펜던트 하고, depth 나 width 와 같은 모델의 shape 요소는 그 영향력이 약함
2.2 Smooth power laws
- Performance 는 다른 2개의 factor 에서 bottleneck 걸리지 않는 조건 하에 power law 를 따름
- 즉, N, D, C 각각의 요소는 다른 2개의 요소가 제한되지 않는다면 six orders 이상의 power law 를 따름 (지수 축으로 표현했을 때 linear 한 형태)
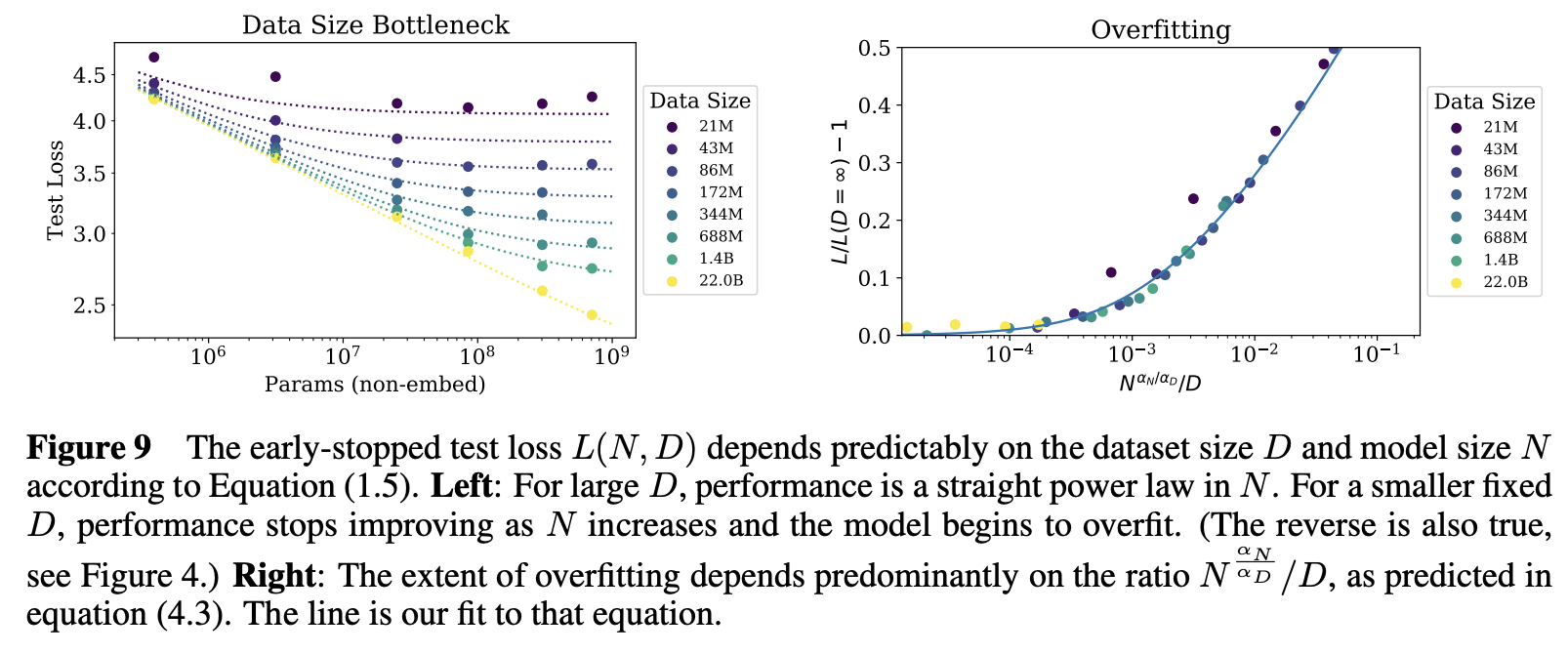
2.3 Universality of overfitting
- parameters N 혹은 size of dataset D 중 하나가 fixed 된다면, performance 는 정체됨
- 즉, performance 가 penalty 없이 scale up 하기 위해서는 N, D 가 함께 증가해야 함
- performance penalty 는 아래와 같은 수식으로 정의할 수 있음
- 수식에 의하면, 모델 사이즈가 8배 커지면 데이터는 최소한 5배 커져야 penalty 없이 performance 가 증가함
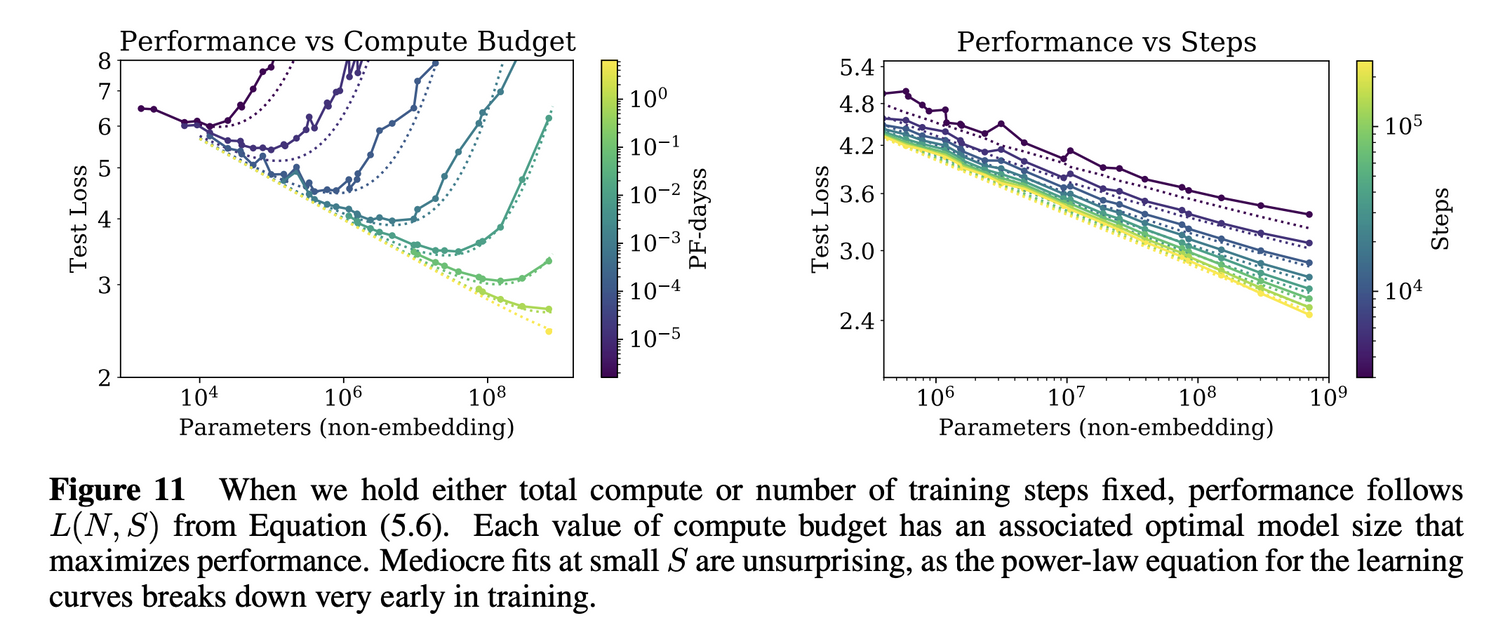
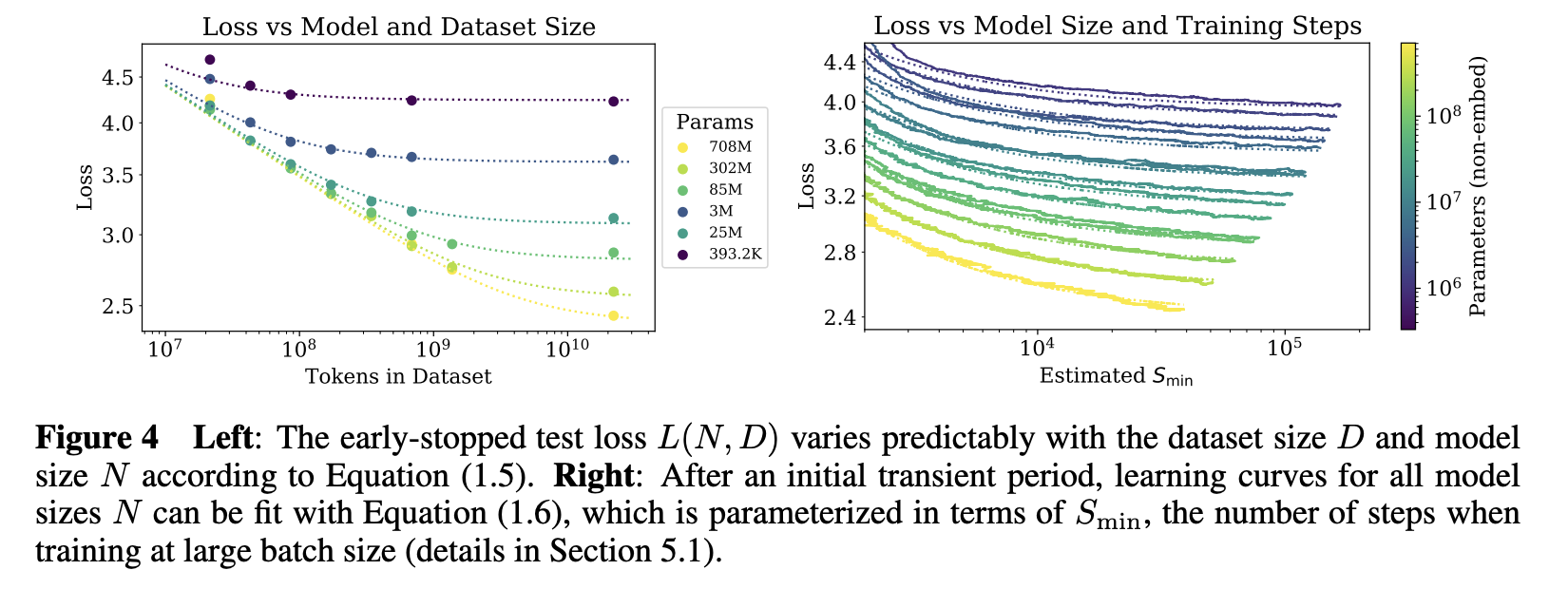
2.4 Universality of training
- Training Curve 는 대략적으로 model size 에 관계 없이 power laws 형태로 예측이 가능함
- Extrapolating 하면 끝까지 학습했을 때 대략적으로 도달하게 될 loss 에 대하여 예측이 가능
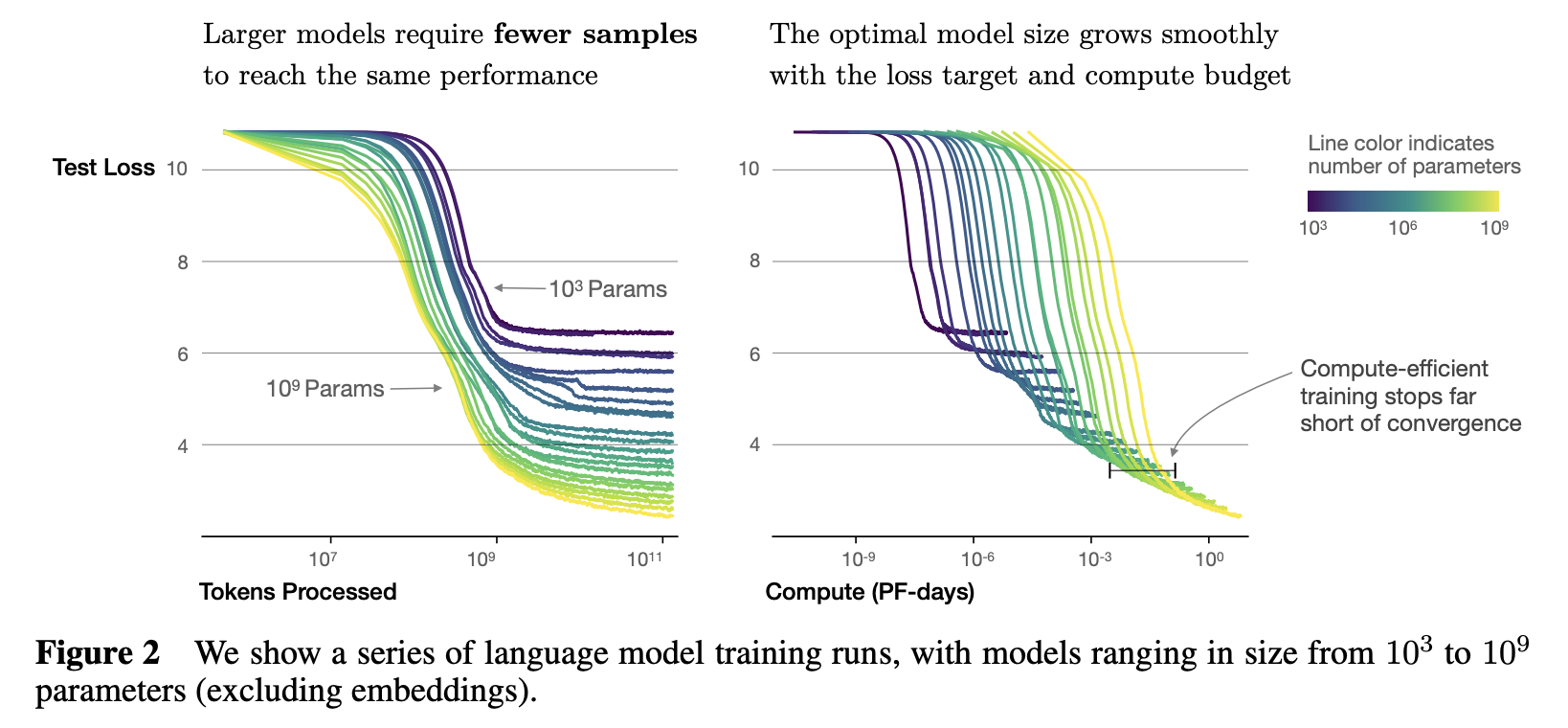
2.5 Sample efficiency
- Large model 은 small model 보다 더욱 sample-efficient 하여, 더 적은 optimization steps 과 더 적은 data points 를 사용하더라도 같은 level 의 performance 에 도달할 수 있음
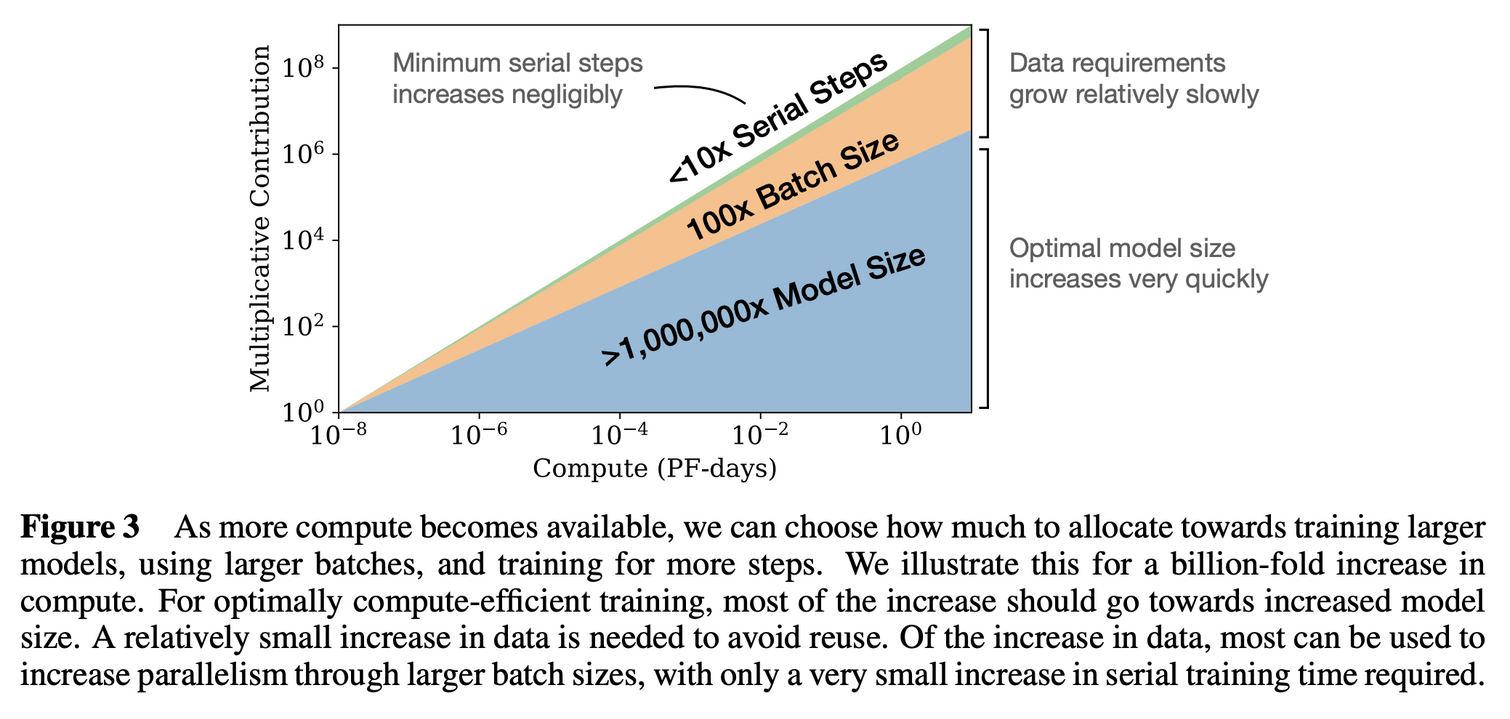
2.6 Convergence is inefficient
- Compute budget 에 따른 성능에 영향을 미치는 요인들의 비중 그래프
- Model Size > Batch Size > Steps 순으로 요인의 영향이 큼
- 내가 한정된 computing power 를 가지고 있을 때, 어떠한 비율로 리소스를 분배해야 효율적일지 예측할 수 있음
2.7 Optimal batch size
- The ideal batch size for training is roughly a power of the loss only

ML/DL Engineer 입니다. 유용한 정보들을 기록해두려 합니다.