- Paper: https://arxiv.org/abs/2203.15556
- DeepMind, NeurIPS 2022
- Scaling Laws 관점에서 Compute-Optimal Model 제안
- FLOPs budget 이 고정되었을 때, optimal 한 model size 와 training tokens 간의 관계가 존재함:
Gopher->Chinchilla- 기존 Kaplan 의 Scaling Laws 결과와 달리 모델 퍼포먼스를 위한 model size 와 training tokens 와의 관계는 거의 1:1 의 weight 를 가짐 (기존: 0.73:0.27 로 model size 가 가장 영향력이 큼)
- 즉, Kaplan 의 Scaling Laws 기반으로 학습된 현재의 LLM 모델들은 대부분 undertrained 되었음
- 논문의 주요 실험 결과 및 기본적인 Contribution 위주로 작성
- 자세한 실험 결과는 작성하지 않음. 논문 참고
1. Introduction
- Transformer 구조의 LM 에서 주어진 compute budget (
FLOPs로 표현) 에 대한 optimal model size 와 tokens 간의 관계에 대한 실험 연구- Kaplan et al. (2020) 에서 제안한 Scaling Laws 에 의하면 model size 가 성능 향상에 제일 큰 영향을 주기 때문에 size 만 과도하게 키웠고, 그 결과 현재 LLM 들은 상당히 undertrained 되었음
- 정해진 compute budget 내에서 model size 와 tokens 간의 관계를 찾기 위해 수 많은 실험을 진행 (약 400여개의 LM)
- model size (params): 70M ~ 16B
- tokens: 5B ~ 500B
- Compute-optimal training 제안
- Given a fixed FLOPs budget, how should one trade-off model size and the number of training tokens?
- The final pre-training loss L(N, D) 모델링
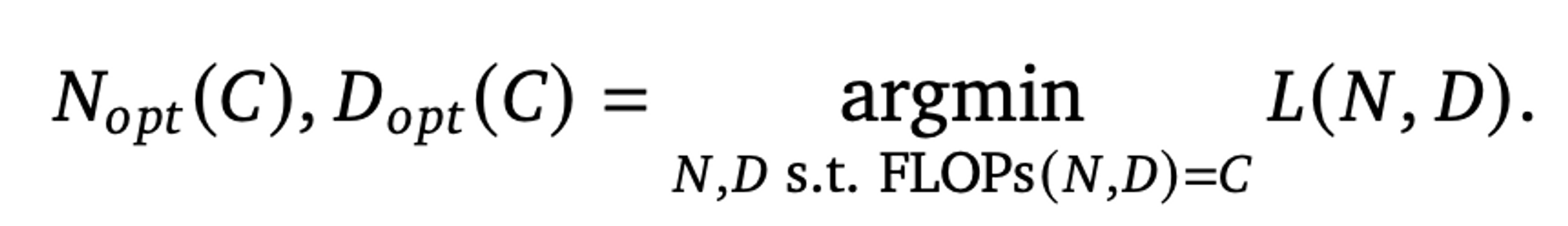
- 이전에 DeepMind 에서 공개한 LLM
Gopher에 사용된 compute budget 으로부터, Gopher 의 optimal model 은 현재보다 4배 더 작고, 4배 더 많은 tokens 를 사용해야 한다는 것을 예측함 - 아래 그래프를 보면
Megatron-Turing NLG,Gopher,GPT-3모델은 모두 논문에서 제안하는 Scaling Laws 그래프 (직선) 에서 벗어나 있음- 즉, 각 모델의 optimal 한 size, tokens 를 위해서는 더 많은 질 좋은 tokens 를 사용하거나, model size 를 더 줄여야함 (undertrained)
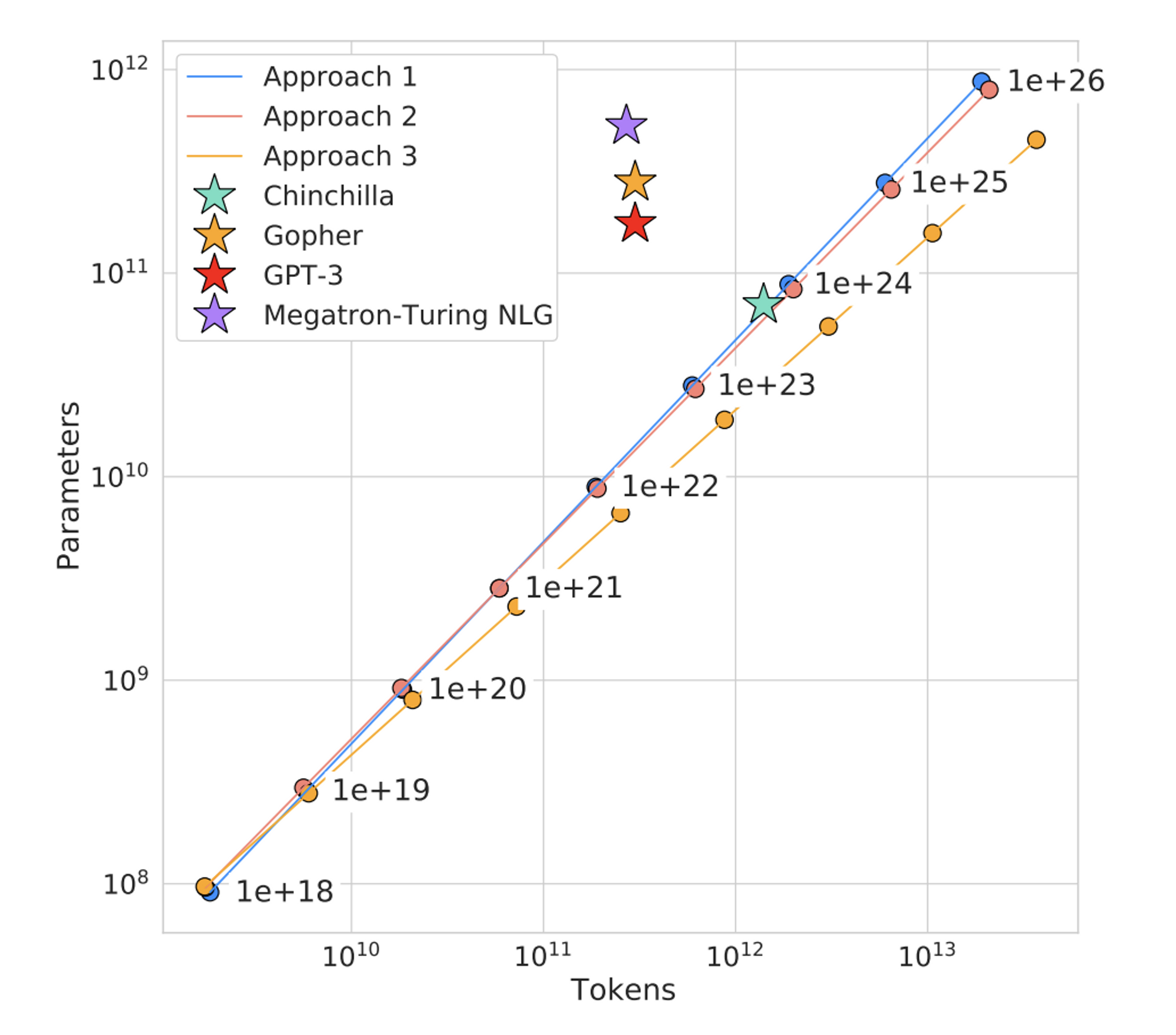
- 이를 기반으로
Chinchilla라는 모델을 새로 학습하여 제안- Gopher (280B) 와 동일한 compute budget 에 대하여 70B params, 4x more data (training tokens) 사용하여 더 좋은 성능을 달성함
- MMLU benchmark 에 대하여 67.5% 로 SOTA 달성

2. Modelling the scaling behavior
-
최근 Large models 에 대한 Scaling behavior 에 대한 실험 연구 중 Kaplan et al. (2020) 는 처음으로 model size 와 loss 에 대한 예측 가능한 관계에 대해 보여주었음
1) Our results strongly suggest that larger models will continue to perform better, and will also be much more sample efficient than has been previously appreciated.
2) Big models may be more important than big data. -
그렇다면 왜 Kaplan 의 연구와 다른 결론이 나온 것일까?
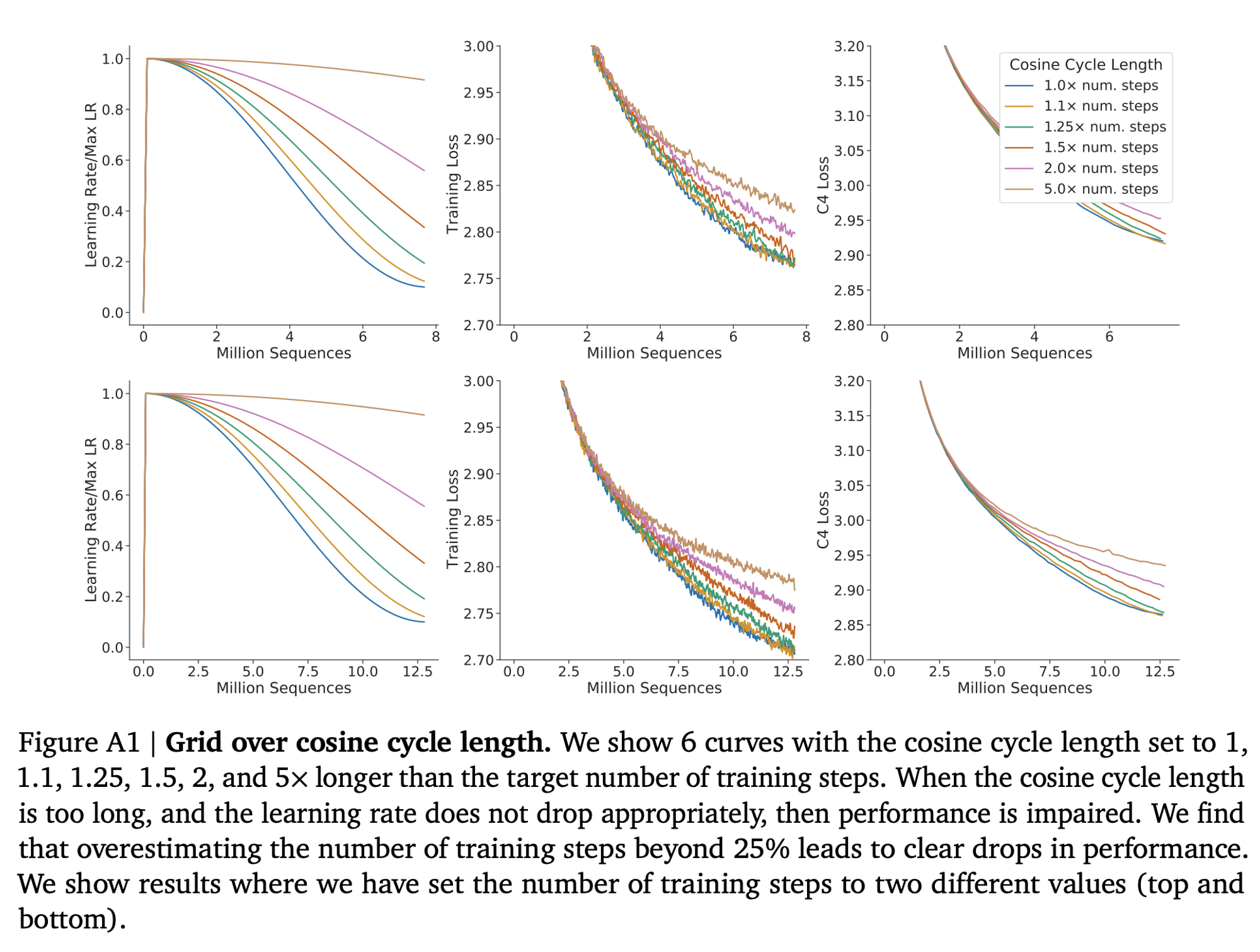
- Kaplan 연구의 저자들은 실험에 사용한 모든 모델에 대하여 fixed number of training tokens 와 learning rate schedule 을 사용하였음
- 실제 실험을 해보니 model size 와는 별개로
training tokens수에 맞는 적절한 learning rate schedule 을 셋팅해주어야 최적 final loss 에 도달한다는 것을 발견 - 즉, Kaplan 연구 처럼 130B 의 tokens 에 대한 고정된 cosine schedule 을 사용하는 경우, 130B tokens 보다 적은 데이터를 사용한 모델일 때에는 데이터에 의한 학습 효과를 과소평가하게 됨 (learning rate decay 효과 감소)
- 이는 compute budget 이 증가함에 따라 model size 가 data size 보다 빠르게 증가해야 한다는 결론이 나오게 됨
- 본 논문에서는 tokens 수에 맞는 cosine length 를 설정하였다고 함
- 또한, training steps 의 25% 이상을 length 로 잡게되면 성능 하락이 있다고 주장
- 실제 실험을 해보니 model size 와는 별개로
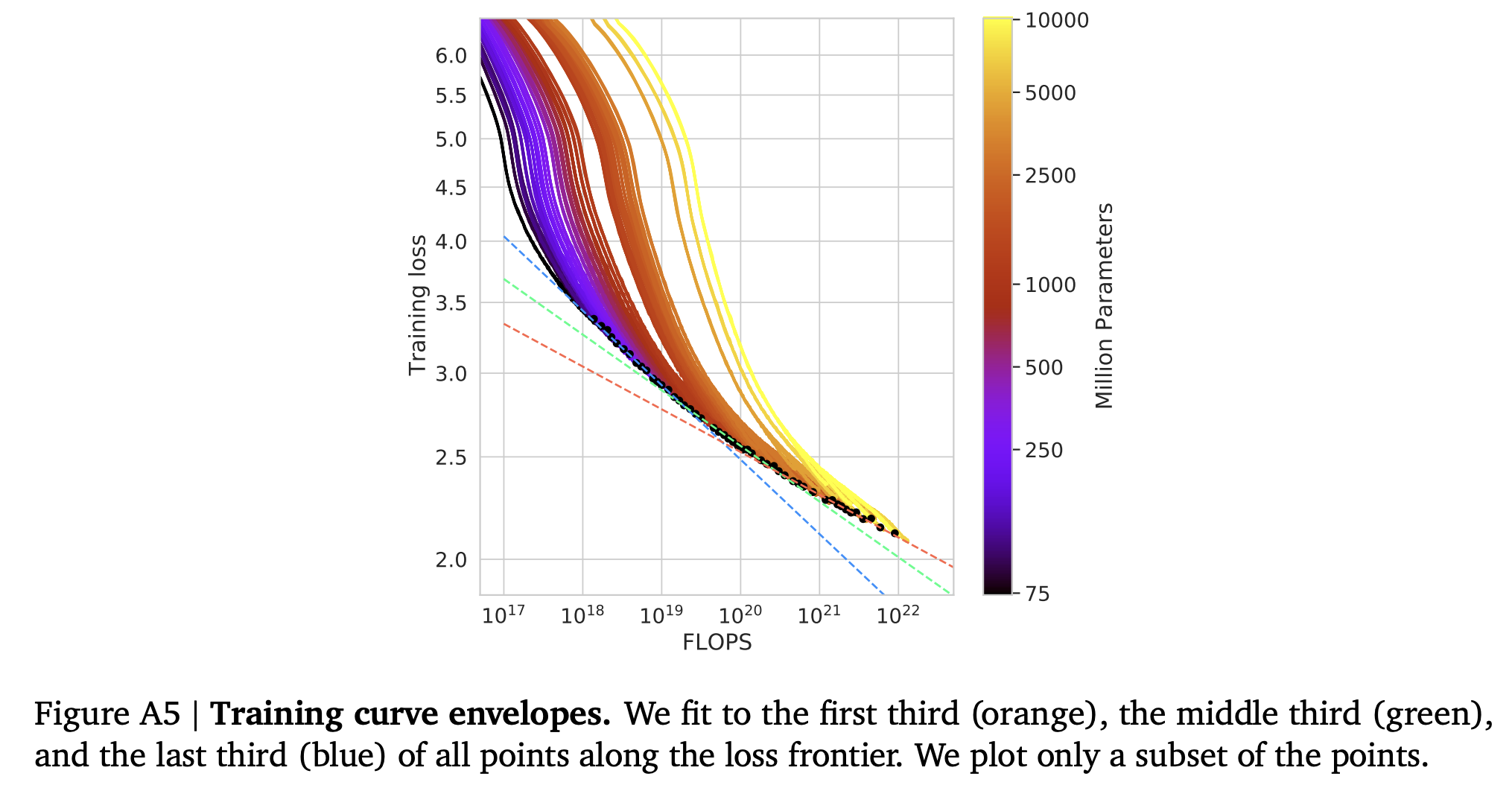
- Chinchilla 저자들은 16B 까지의 모델들을 실험하였는데, 모델 크기에 따른
FLOP-loss간 그래프에서 약간의 곡선이 발생한다는 것을 발견함- 이는 많은 경우 100M 이하의 모델을 실험한 Kaplan 의 연구 모델 구간에서는 선형으로 보이는 그래프가 model size 가 커짐에 따라 곡선의 형태로 영향을 받게된다는 것을 의미
- 이는 매우 작은 모델의 예측은 큰 모델의 예측과 다른 결과로 이어질 수 있음
3. Estimating the optimal prarmeter/training tokens allocation
- Fixed FLOPs budget 에 대하여, model size 와 학습 tokens 와의 trade-off 관계를 밝히기 위해 서로 다른 3가지 approaches 를 제시
3.1 Approach 1: Fix model sizes and vary number of training tokens
- 4개의 서로 다른 training sequences 에 대하여 fixed family of models 에 대한 training steps 수를 변화시키며 관찰
- 이 approach 로 부터, 주어진 FLOPs 에 대한 도달하는 minimum loss 을 바로 추정할 수 있었음
- 파라미터 수 N 개인 서로 다른 4개의 모델을 학습하고, range 가 16x 인 horizon 에 대하여 learning rate 를 10x 의 factor 로 감소시킴
- 각각의 FLOPs 에 대하여, 가장 낮은 loss 를 달성하는 모델을 선택 (
minimum over training curves) 하여 smooth and interpolation- FLOPs
C에 대한 가장 효율적인 model sizeN과 number of training tokensD를 얻음 - 아래 그래프를 보면 optimal model size 와 optimal number of training tokens 는 각각 FLOPs 에 대하여 대략적인 선형 관계를 가짐
- , 각각의 비례 관계는 그 계수가 , 이라는 결과를 얻음
- FLOPs
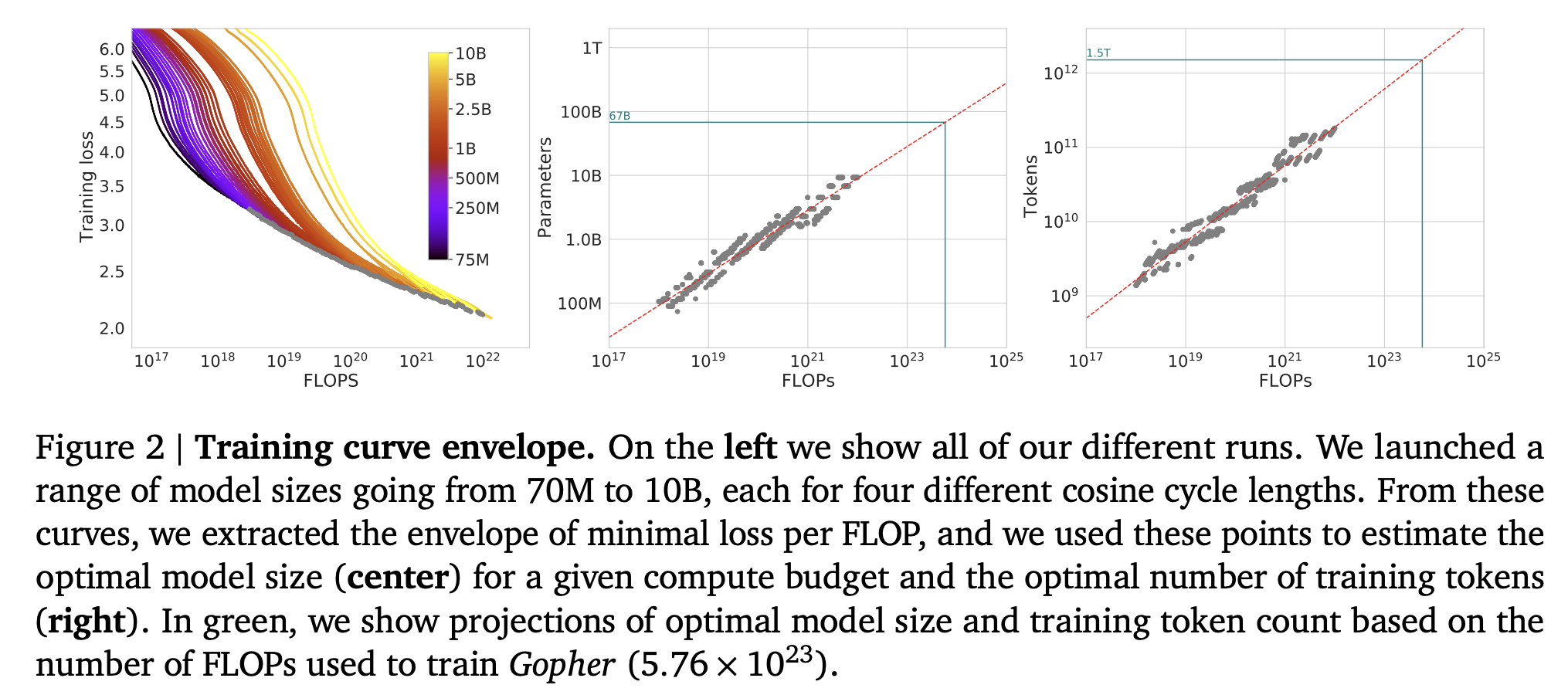
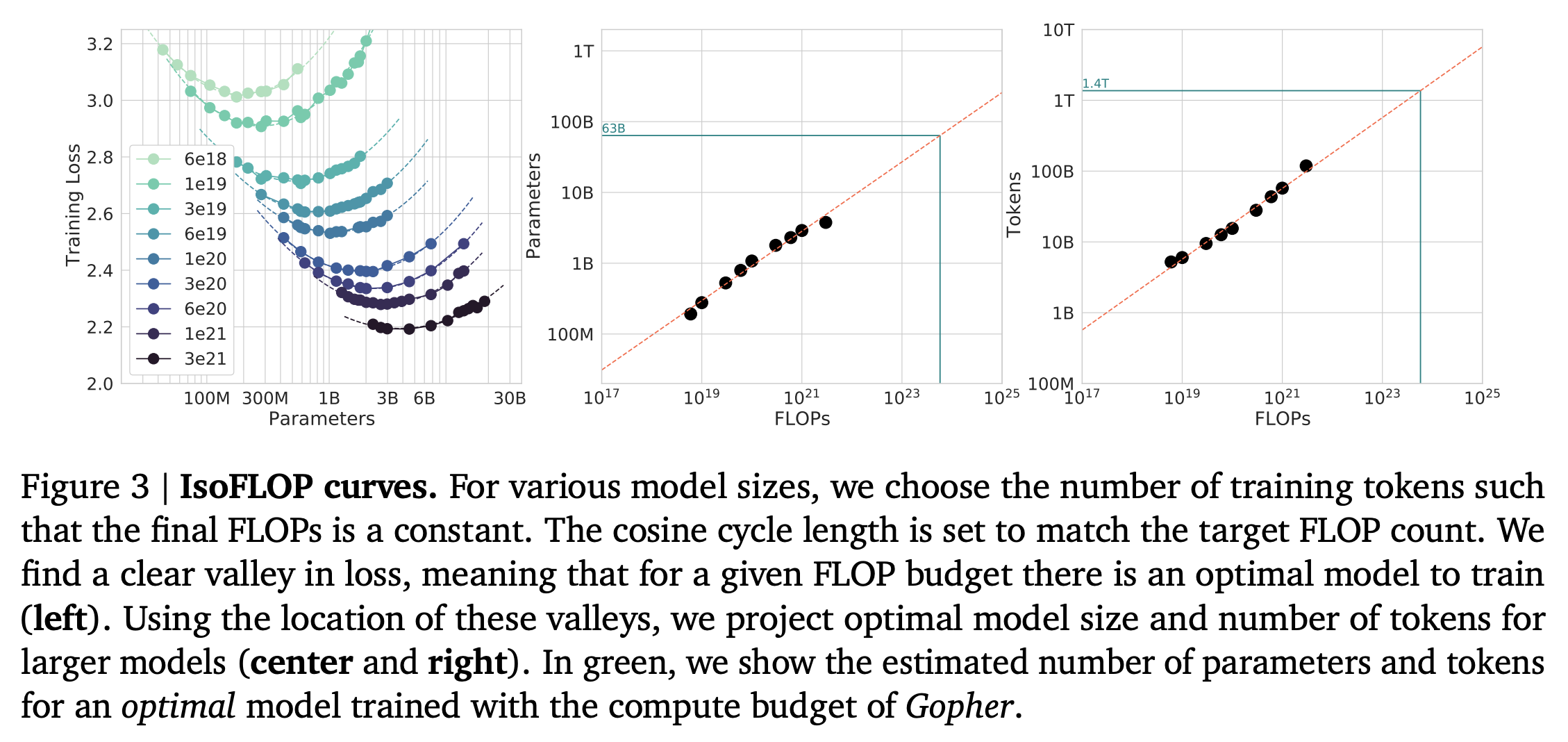
3.2 Approach 2: IsoFLOP profiles
- 고정된 9개의 서로 다른 training FLOP counts ( ~ FLOPs) 에 대하여 model size 를 다양하게 바꾸어서 최종 training loss 를 고려, FLOPs 에 맞는 적절한 model size 를 찾는 것이 목적
- For a given FLOP budget, what is the optimal parameter count?
- Tokens 수에 맞게 cosine schedule length 를 설정하였음
- 아래 그래프를 보면, parameters 의 값에 따라 명확하게 valley 형태의 loss 가 발생하였고 (9개 FLOP 케이스 모두), 이는 주어진 FLOP budget 에 대한 optimal model 이 존재한다는 것을 의미함
- 이를 바탕으로 FLOPs 에 대한 optimal parameters, tokens 를 찾을 수 있음
- , 각각의 비례 관계는 그 계수가 , 이라는 결과를 얻음
3.3 Approach 3: Fitting a parametric loss function
- Approach 1 & 2 에서 얻은 실험적 final losses 들로부터 parametric function 을 모델링
- 첫 번째 term: 주어진 data distribution 에서 ideal generative process 로부터 얻을 수 있는 값으로, natural text 에 대한 entropy 에 대응한다고 볼 수 있음
- 두 번째 term: N 개의 파라미터를 가진 transformer 는 완벽하게 학습되었을 때 ideal 에 비해 이 term 만큼 underperforms 된 것이라고 볼 수 있음 (ideal 구조가 아니므로)
- 세 번째 term: transformer 가 dataset distribution 전체에서 sample 된 데이터를 가지고, 유한한 optimisation steps 수 만큼 학습하는 데에 따른 수렴하지 않는 정도
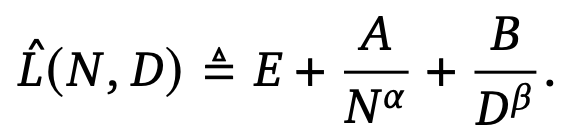
- Model fitting: predicted 값과 L-BFGS algorithm 을 사용하여 관측된 log loss 값 간의 Huber loss 를 최소화하는 방향으로 ) 값을 추정하였다고 함
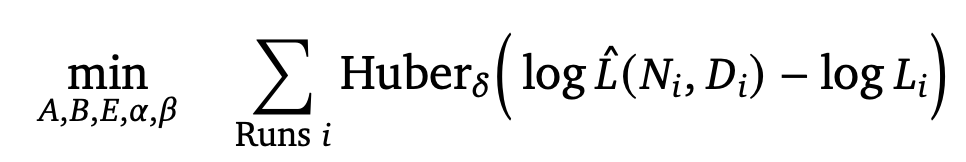
- Efficient frontier: parametric loss 를 최소화하는 방향으로 , 값을 추정할 수 있었음 (constraint at Kaplan et al. (2020))

- 아래 그래프를 보면 FLOPs 와 model size 간의 관계를 isoFLOPs 와 함께 표시하였는데 (left), efficient frontier 의 경우 (
blue line: the closed-form efficient computational frontier), curve 가 각각의 iso-loss 경계선의 가장 작은 FLOPs 일 때를 지나간다는 것을 알 수 있음- , 각각의 비례 관계는 그 계수가 , 이라는 결과를 얻음
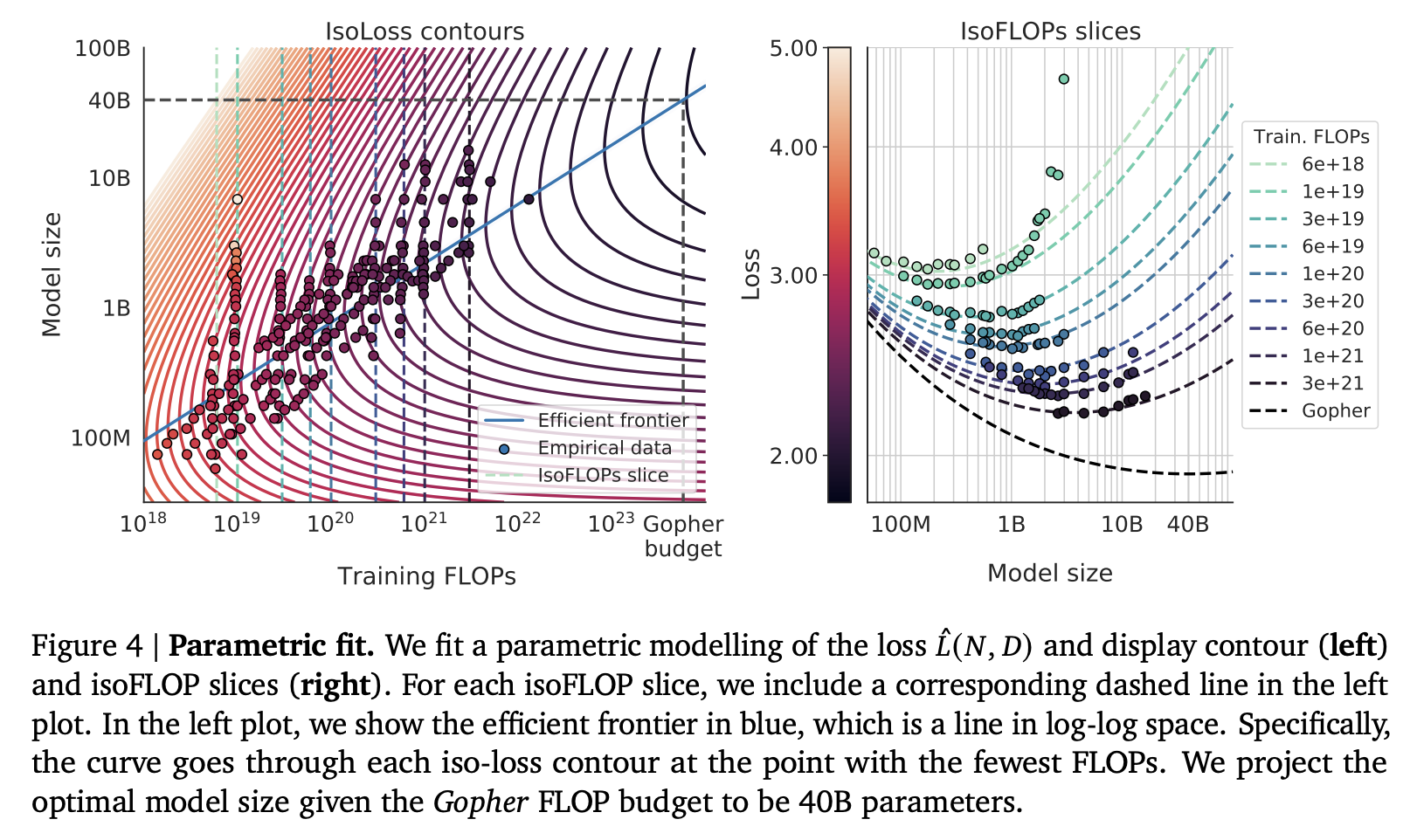
3.4 Optimal model scaling
- 3개의 approach 를 바탕으로, 각각 다른 방법론과 다른 학습 모델을 가지고 접근하더라도 유사한 optimal scaling 결론을 얻을 수 있었음
- All three approaches suggest that as compute budget increases, model size and the amount of training data should be increased in approximately equal proportions.
- 각각의 approach 를 하나의 table 로 정리하면 (아래 table), 각 approach 는 모두 비슷한 비율로 model size 와 tokens 수를 가져가야 한다고 결론 내릴 수 있으며, 이는 model size 를 performance 의 더 중요한 factor 로 여겼던 기존 연구 Kaplan et al. (2020) 결과와 크게 다름
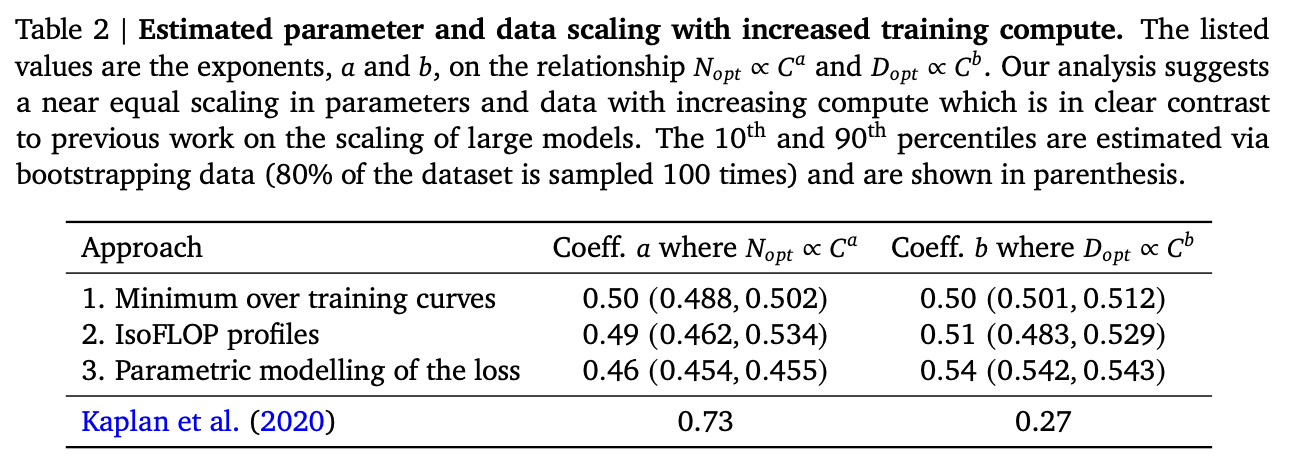
- Optimal training FLOPs and training tokens for various model sizes
- 이를 기반으로 Gopher 와 유사한 compute budget 을 갖는 compute-optimal model 인
Chinchilla제안
- 이를 기반으로 Gopher 와 유사한 compute budget 을 갖는 compute-optimal model 인

ML/DL Engineer 입니다. 유용한 정보들을 기록해두려 합니다.
안녕하세요.
친칠라 공부하다 방문했습니다. 정리해주신 덕분에 빠르게 이해가 갔어요 👍
추후에 블로그 리뷰 시 참고 출처로 이 포스팅을 남겨도 될까요?