Official implementation for "TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables" (NeurIPS 2024)
Timexer는 시계열 작업을 효율적으로 처리하기 위한 경량 라이브러리입니다.
본 글에서는 Timexer의 코드 구조와 동작 원리를 중심으로 리뷰합니다.
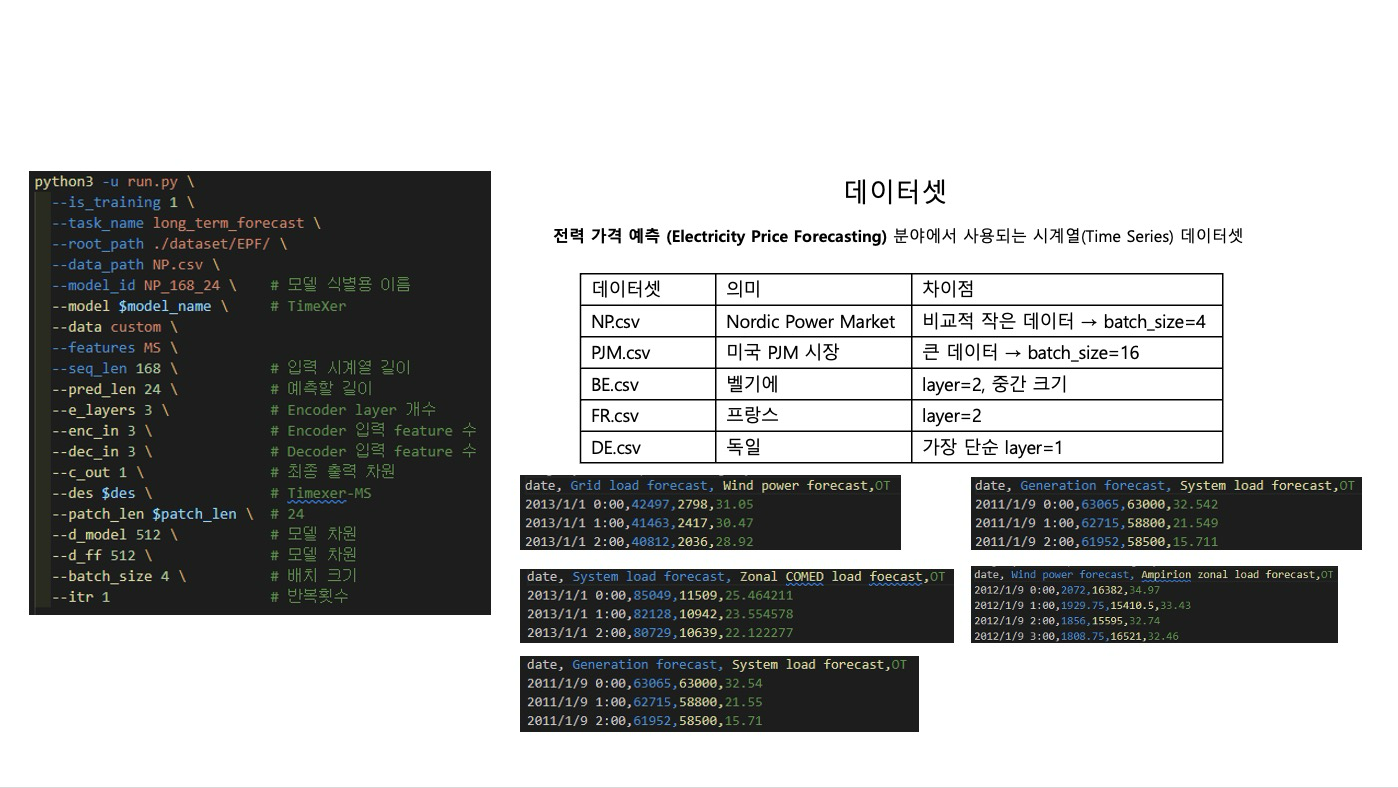
데이터는 코드에서 제공한 데이터(NP.csv, PJM.csv, BE.csv,FR.csv, DE.csv)로 진행했습니다.


Model code
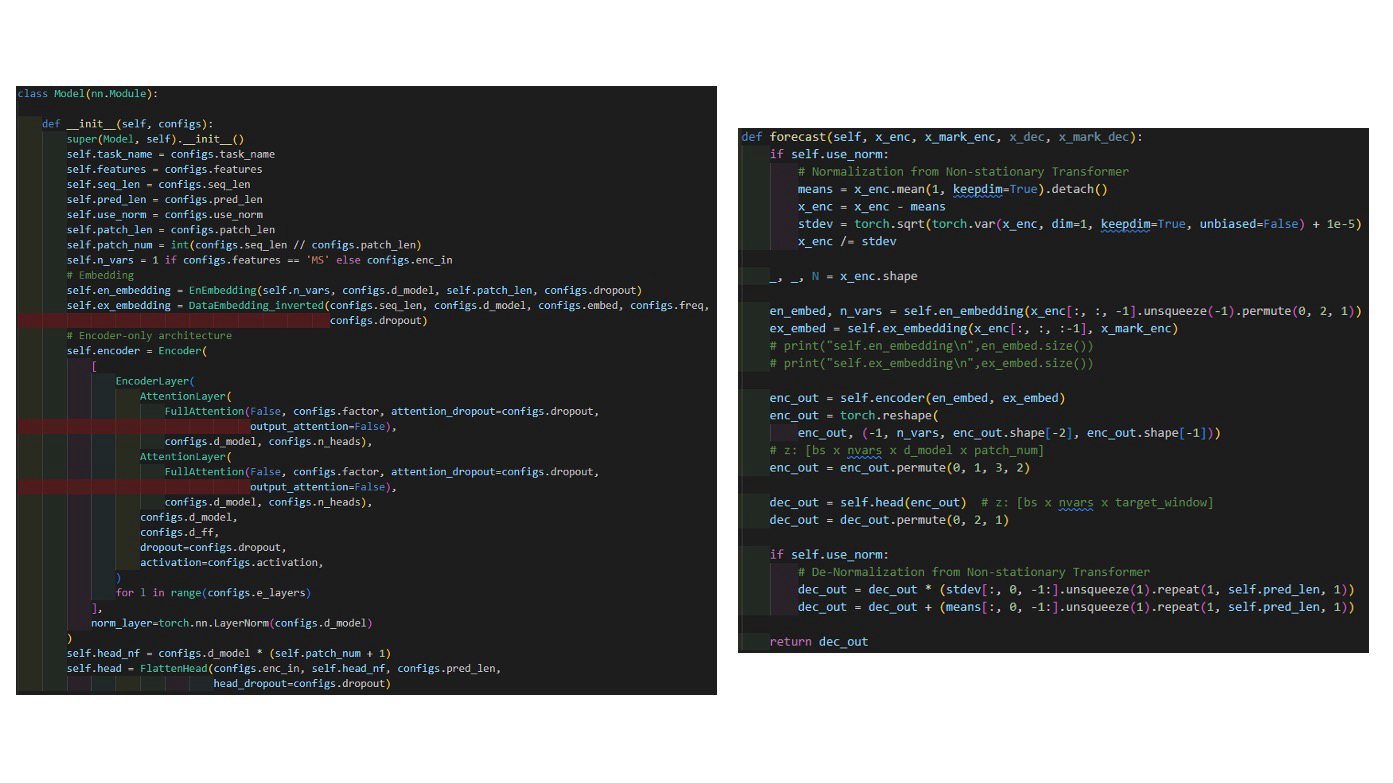
class Model(nn.Module):
def __init__(self, configs):
super(Model, self).__init__()
self.task_name = configs.task_name
self.features = configs.features
self.seq_len = configs.seq_len
self.pred_len = configs.pred_len
self.use_norm = configs.use_norm
self.patch_len = configs.patch_len
self.patch_num = int(configs.seq_len // configs.patch_len)
self.n_vars = 1 if configs.features == 'MS' else configs.enc_in
# Embedding
self.en_embedding = EnEmbedding(self.n_vars, configs.d_model, self.patch_len, configs.dropout)
self.ex_embedding = DataEmbedding_inverted(configs.seq_len, configs.d_model, configs.embed, configs.freq,
configs.dropout)
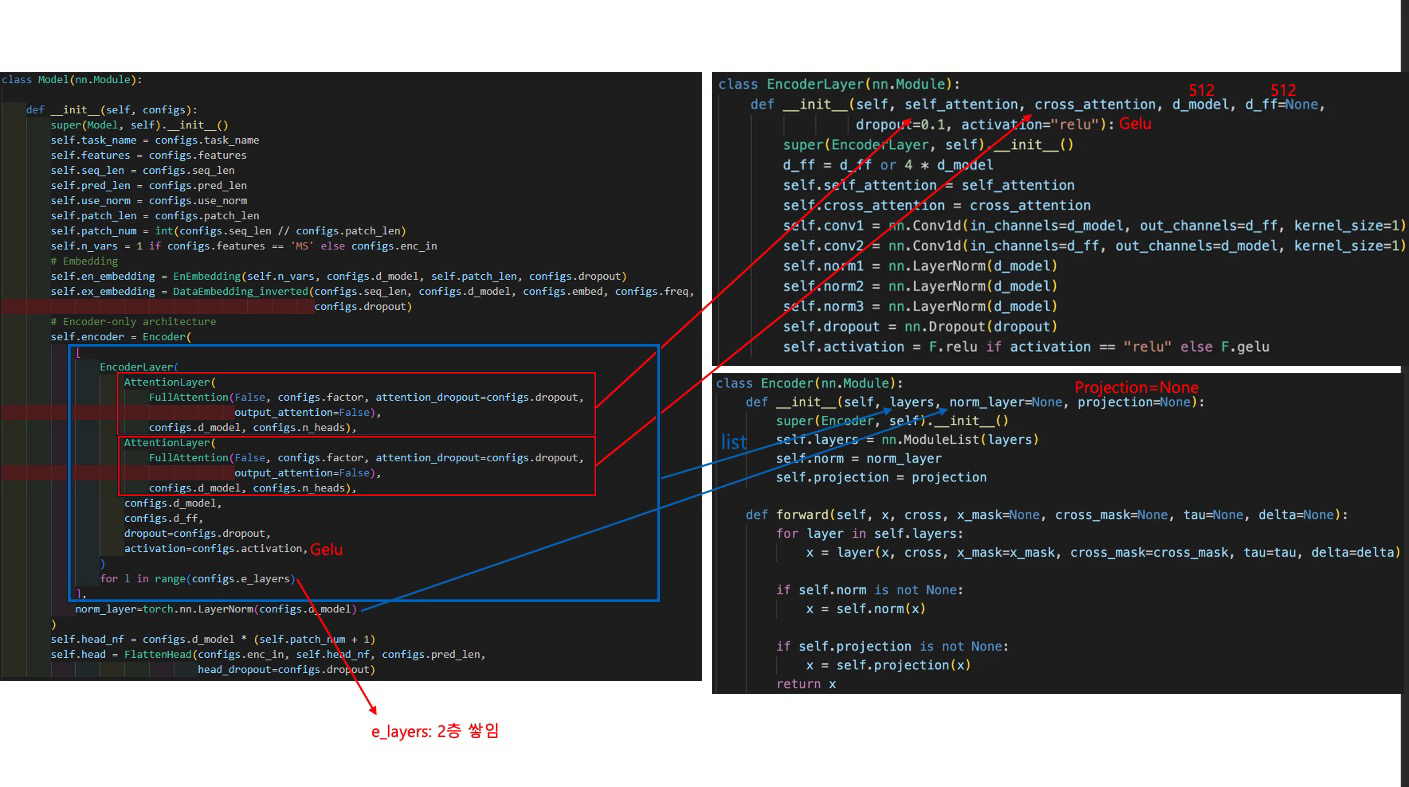
# Encoder-only architecture
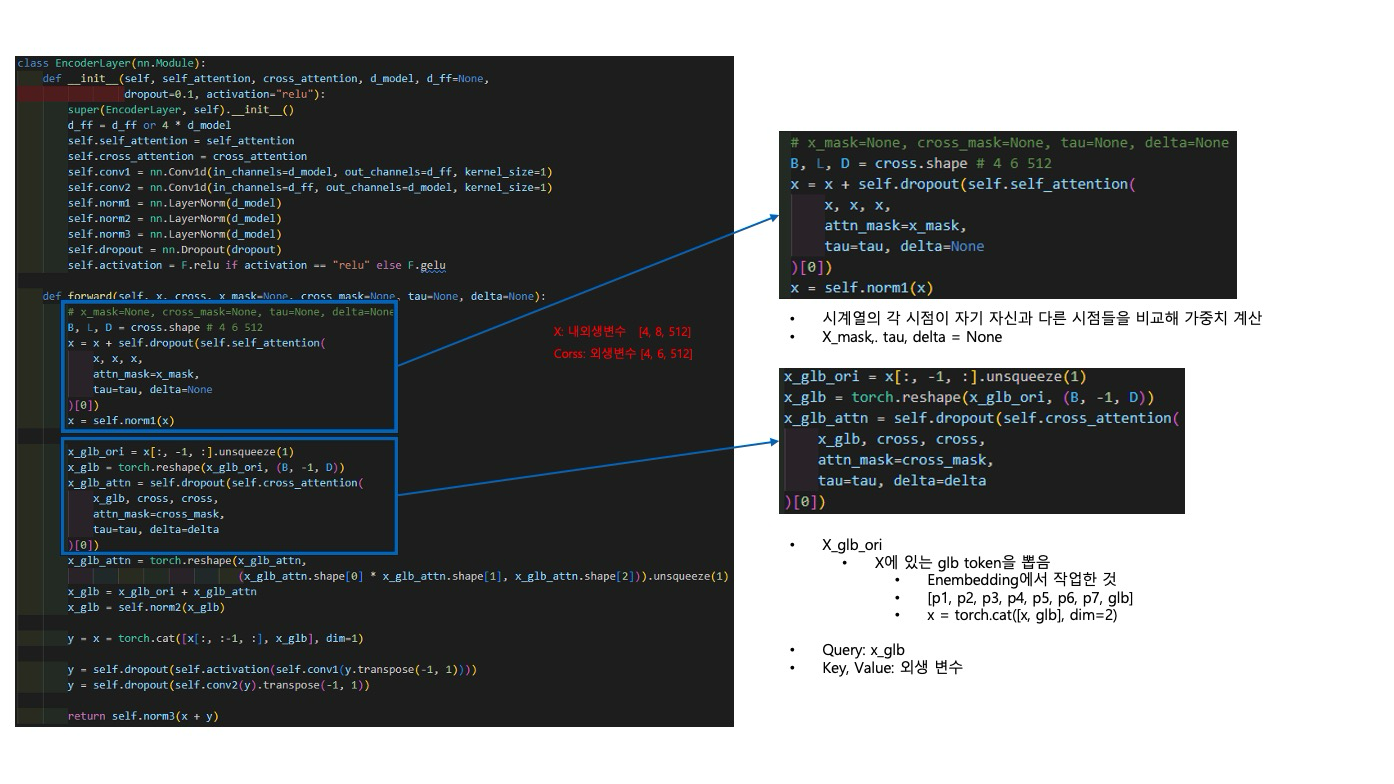
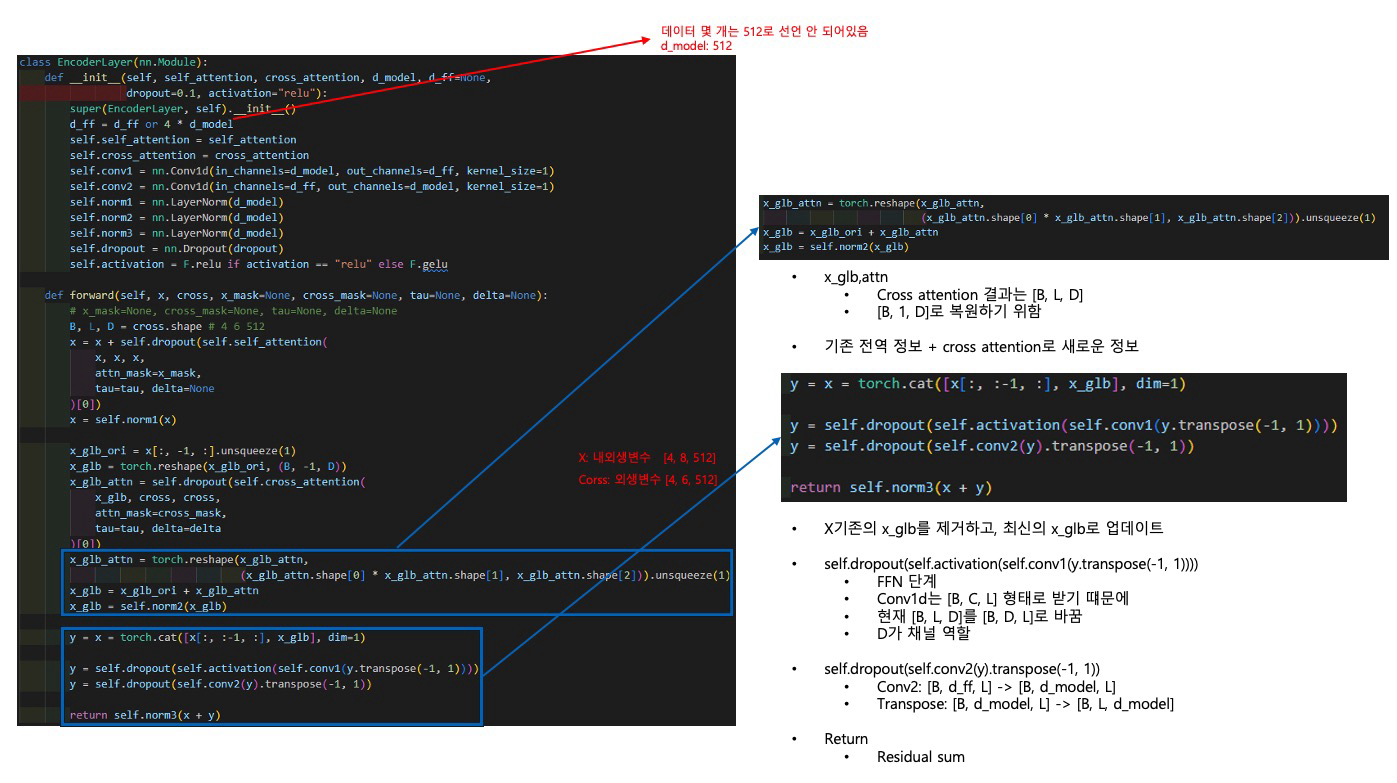
self.encoder = Encoder(
[
EncoderLayer(
AttentionLayer(
FullAttention(False, configs.factor, attention_dropout=configs.dropout,
output_attention=False),
configs.d_model, configs.n_heads),
AttentionLayer(
FullAttention(False, configs.factor, attention_dropout=configs.dropout,
output_attention=False),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
dropout=configs.dropout,
activation=configs.activation,
)
for l in range(configs.e_layers)
],
norm_layer=torch.nn.LayerNorm(configs.d_model)
)
self.head_nf = configs.d_model * (self.patch_num + 1)
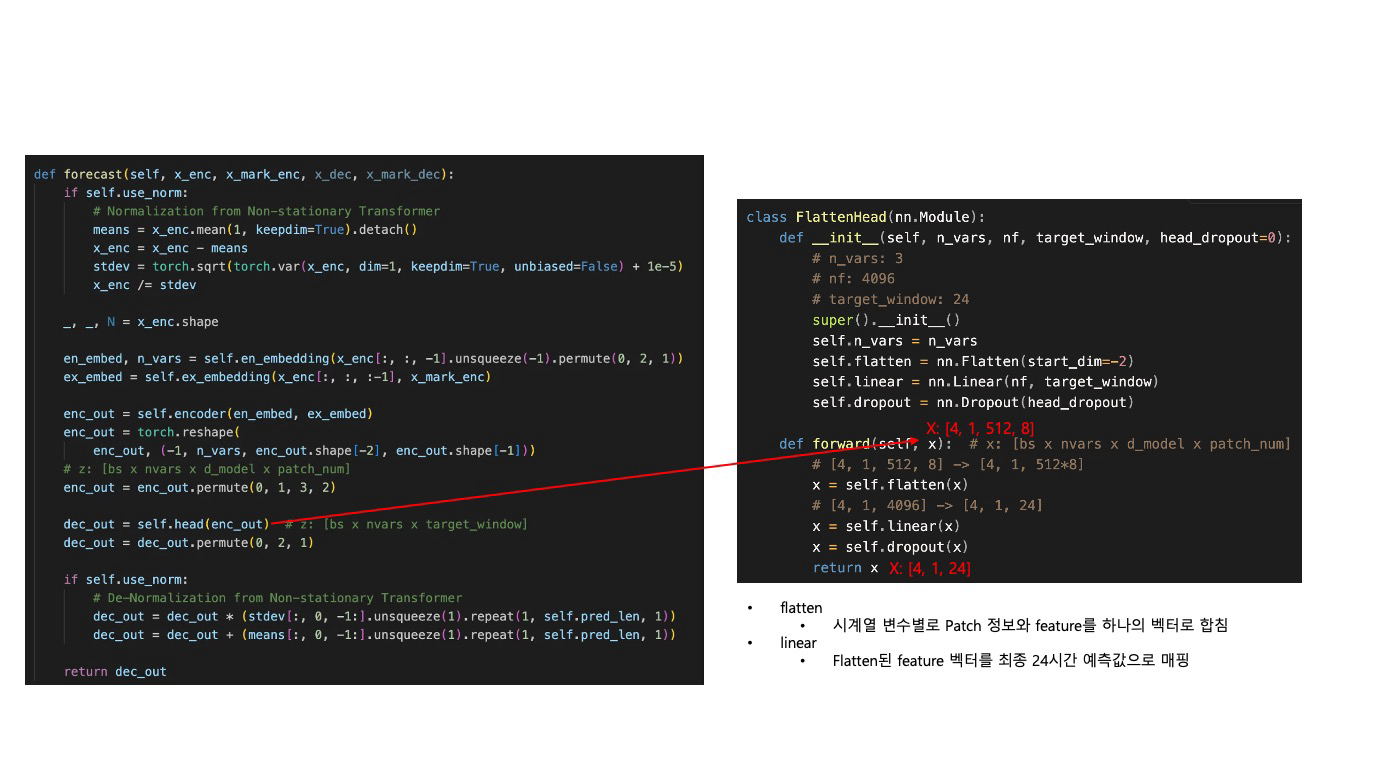
self.head = FlattenHead(configs.enc_in, self.head_nf, configs.pred_len,
head_dropout=configs.dropout)
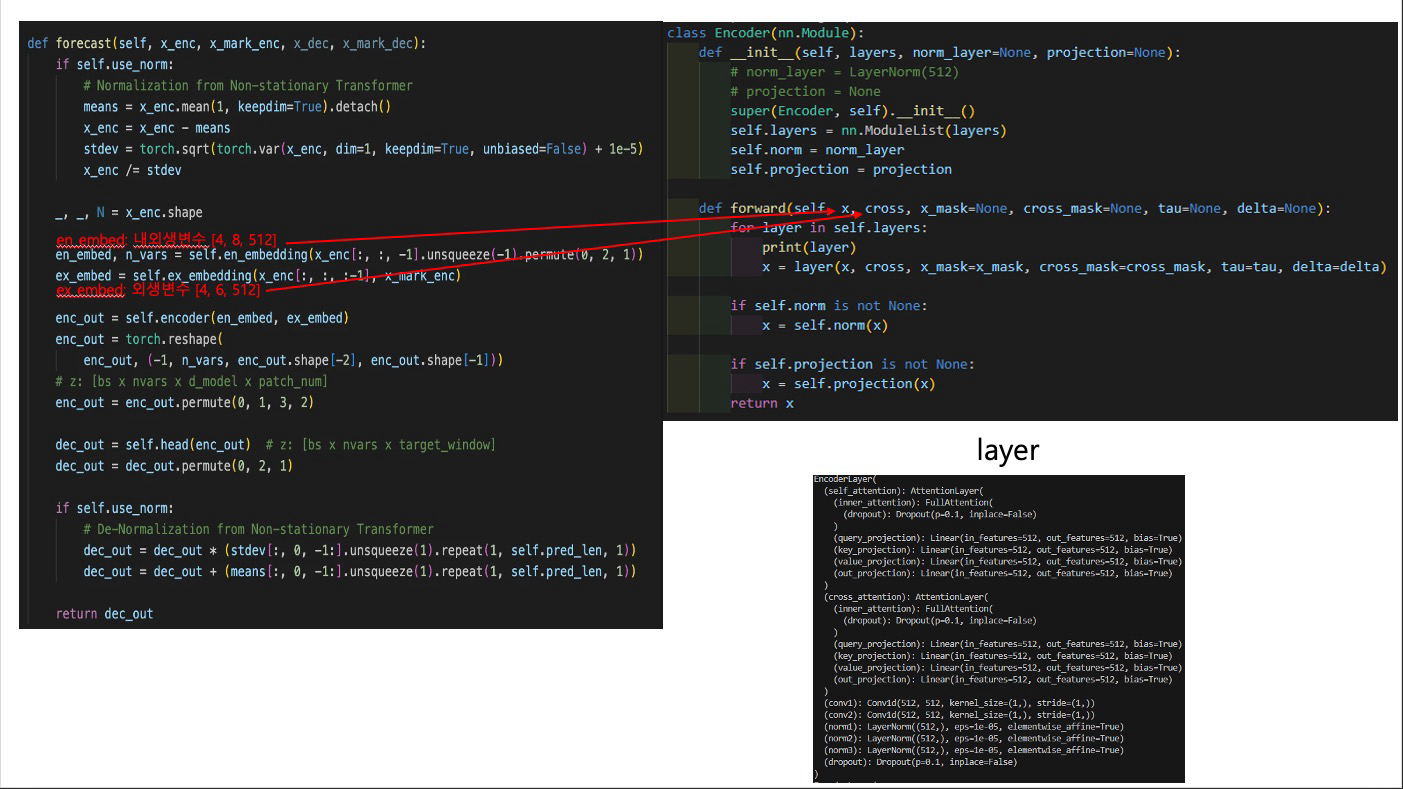
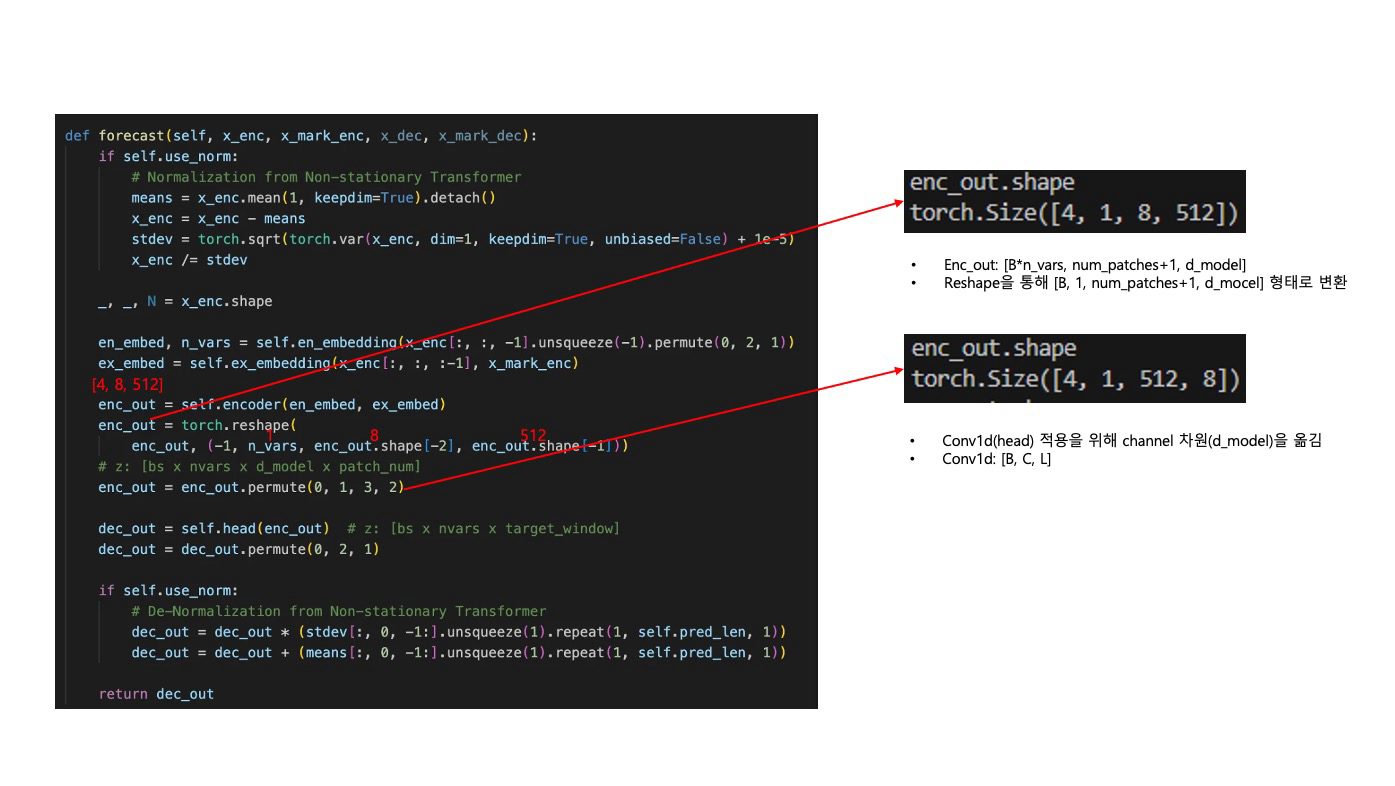
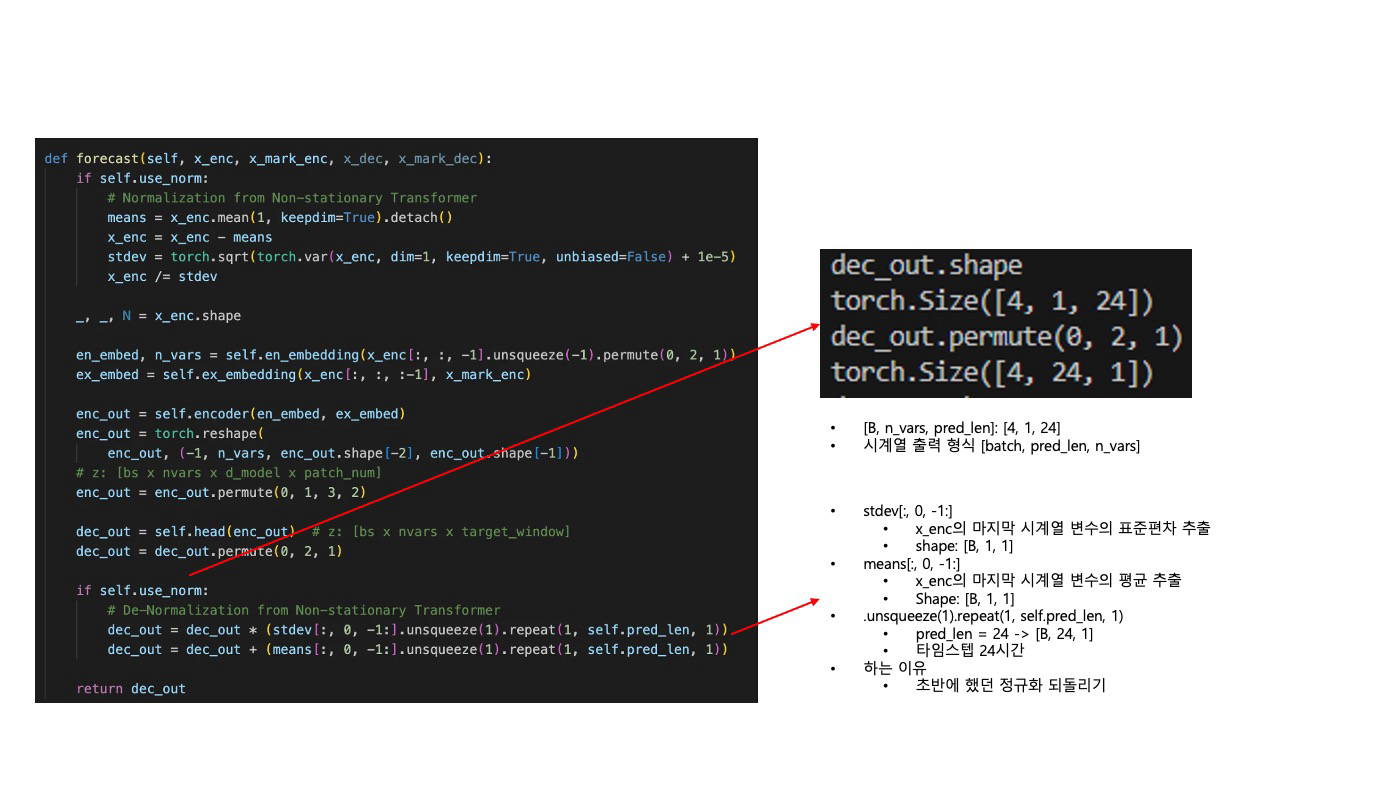
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
if self.use_norm:
# Normalization from Non-stationary Transformer
means = x_enc.mean(1, keepdim=True).detach()
x_enc = x_enc - means
stdev = torch.sqrt(torch.var(x_enc, dim=1, keepdim=True, unbiased=False) + 1e-5)
x_enc /= stdev
_, _, N = x_enc.shape
en_embed, n_vars = self.en_embedding(x_enc[:, :, -1].unsqueeze(-1).permute(0, 2, 1))
ex_embed = self.ex_embedding(x_enc[:, :, :-1], x_mark_enc)
enc_out = self.encoder(en_embed, ex_embed)
enc_out = torch.reshape(
enc_out, (-1, n_vars, enc_out.shape[-2], enc_out.shape[-1]))
# z: [bs x nvars x d_model x patch_num]
enc_out = enc_out.permute(0, 1, 3, 2)
dec_out = self.head(enc_out) # z: [bs x nvars x target_window]
dec_out = dec_out.permute(0, 2, 1)
if self.use_norm:
# De-Normalization from Non-stationary Transformer
dec_out = dec_out * (stdev[:, 0, -1:].unsqueeze(1).repeat(1, self.pred_len, 1))
dec_out = dec_out + (means[:, 0, -1:].unsqueeze(1).repeat(1, self.pred_len, 1))
return dec_out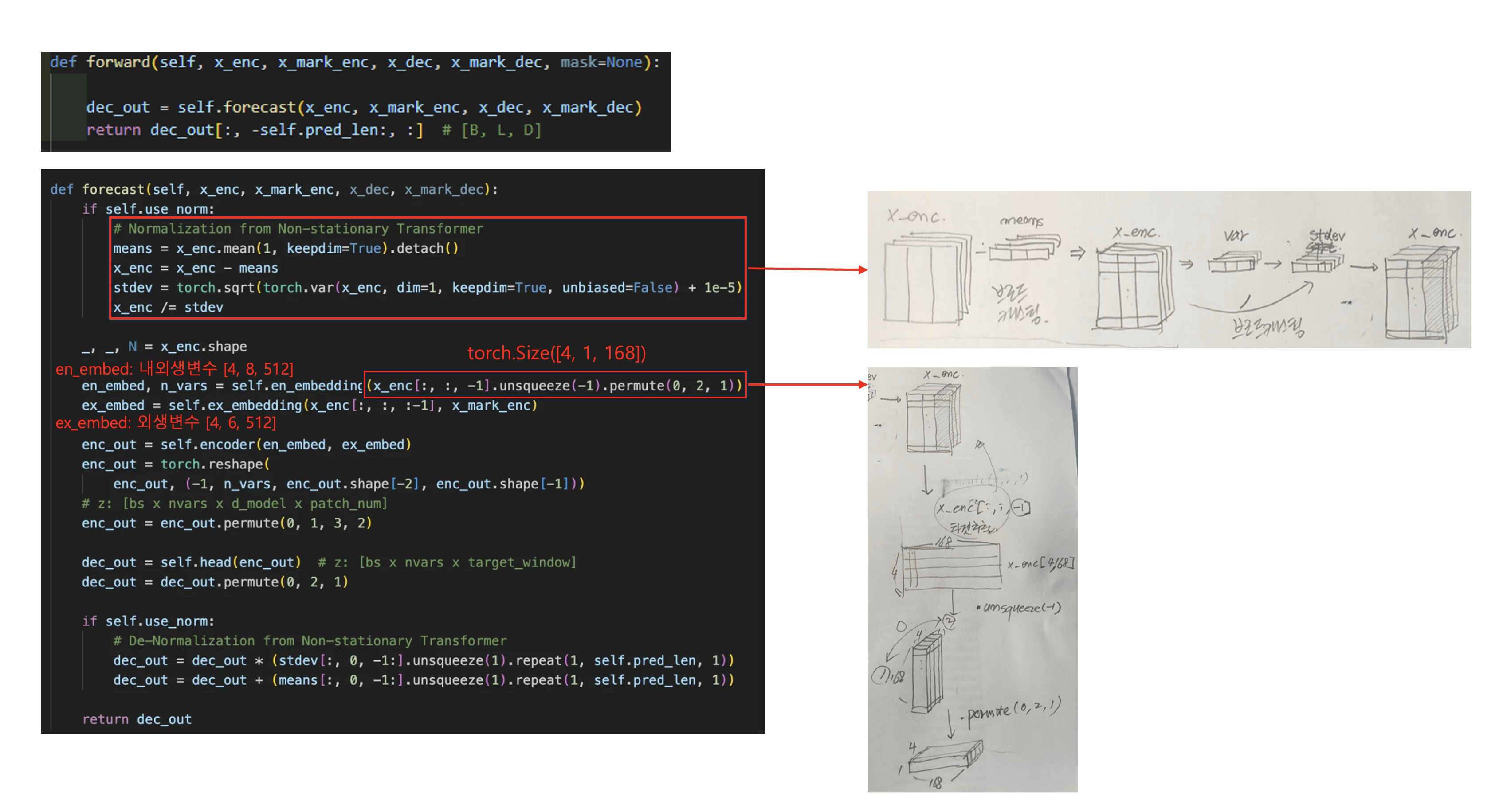

AI is my life