Timexer는 attention 메커니즘을 활용하여 데이터 간의 관계를 학습합니다.
이에 따라, attention의 원리를 복습하고 이해도를 높이기 위해 Timexer 코드 리뷰를 진행합니다.
리뷰할 코드
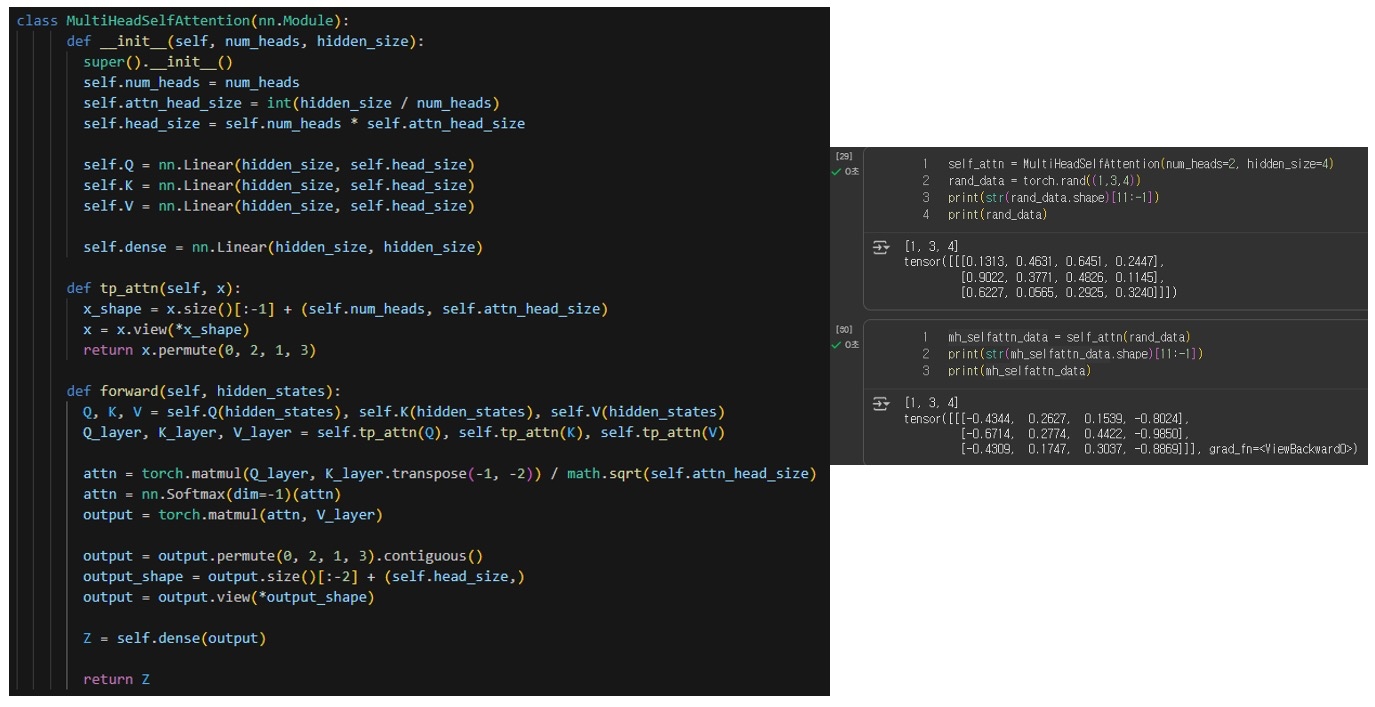
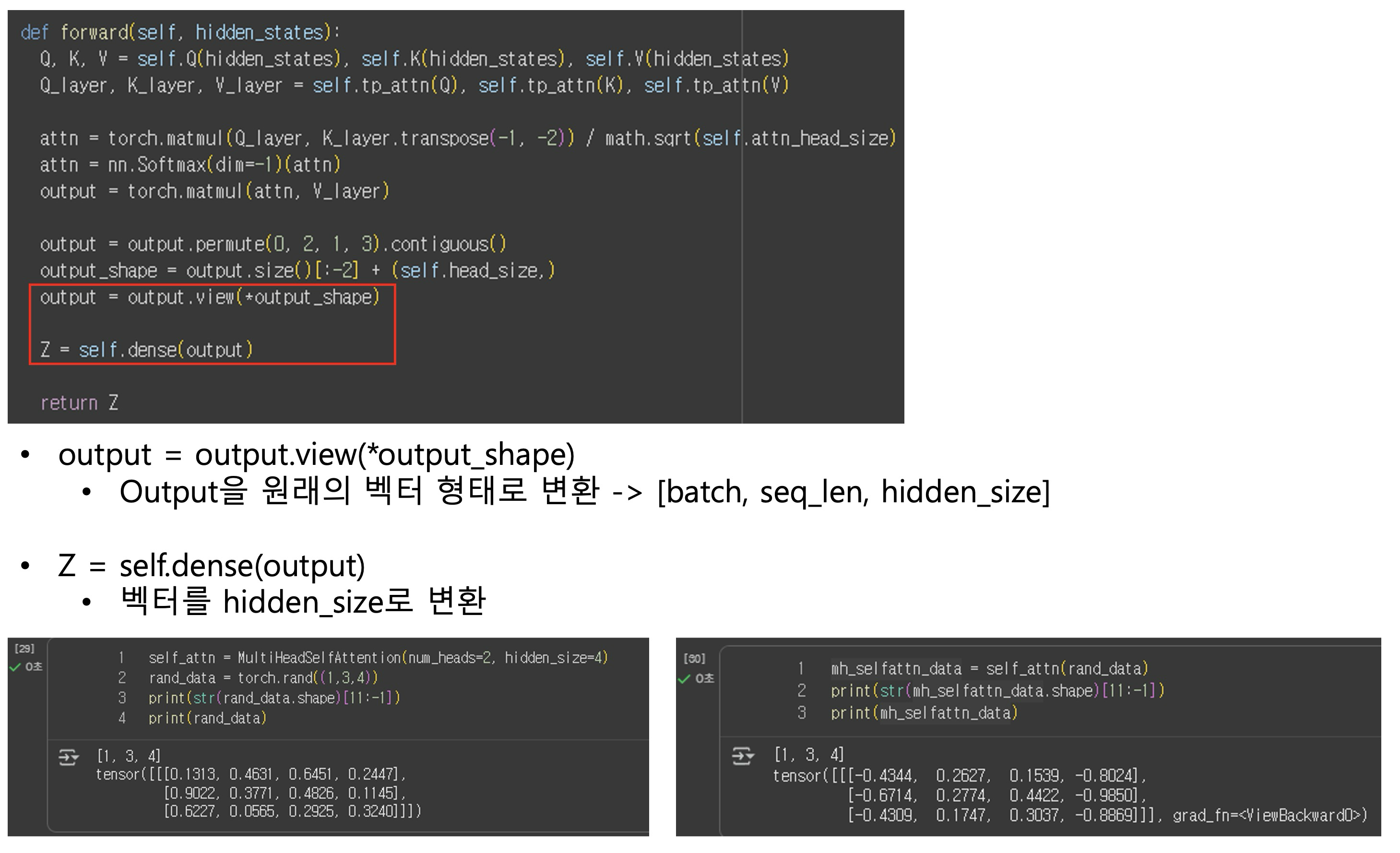
hidden_size를 num_heads로 나누어 각 head가 처리할 차원 수를 결정합니다.
즉, 각 head는 전체 hidden 차원의 일부분(hidden_size / num_heads)만을 담당하여 병렬로 attention 연산을 수행합니다.
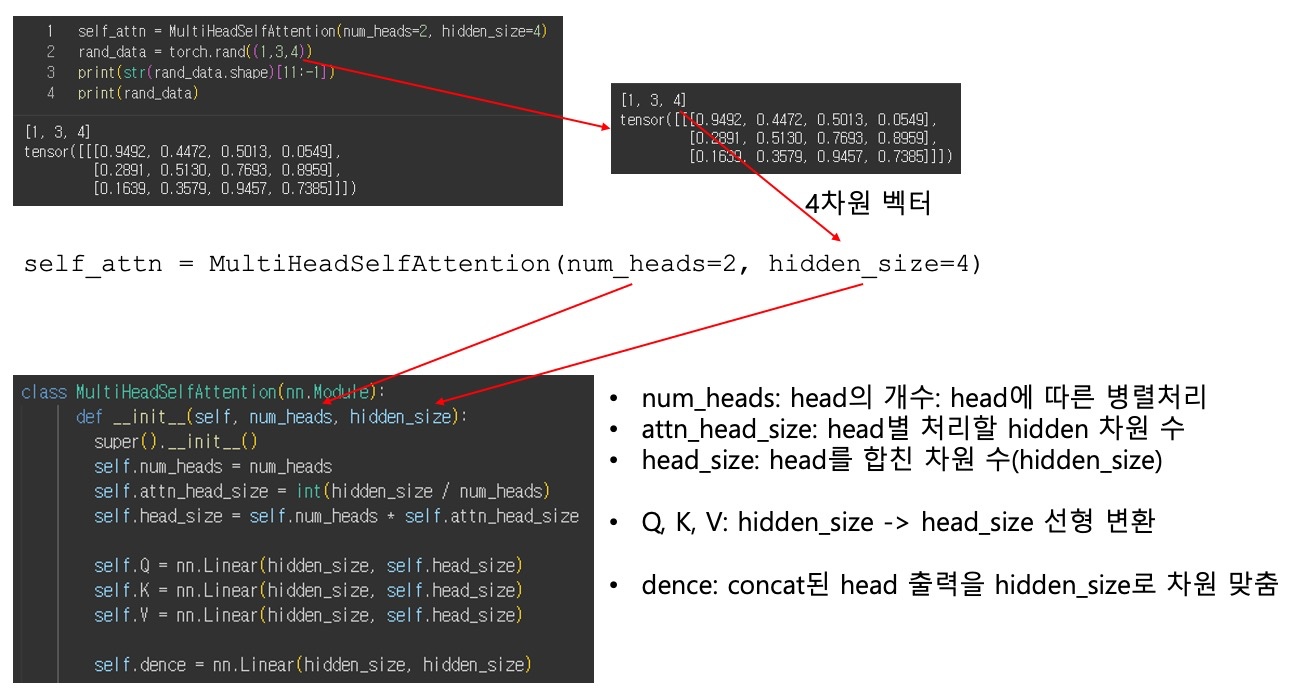
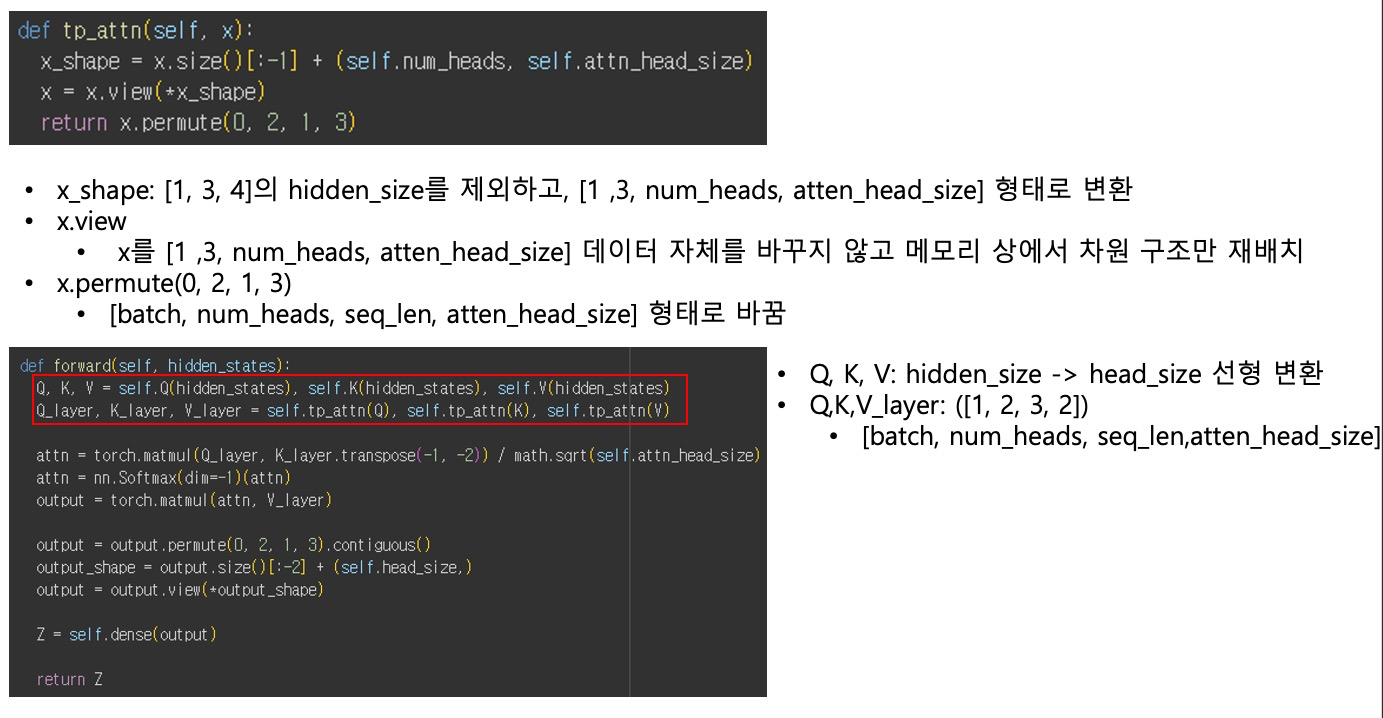
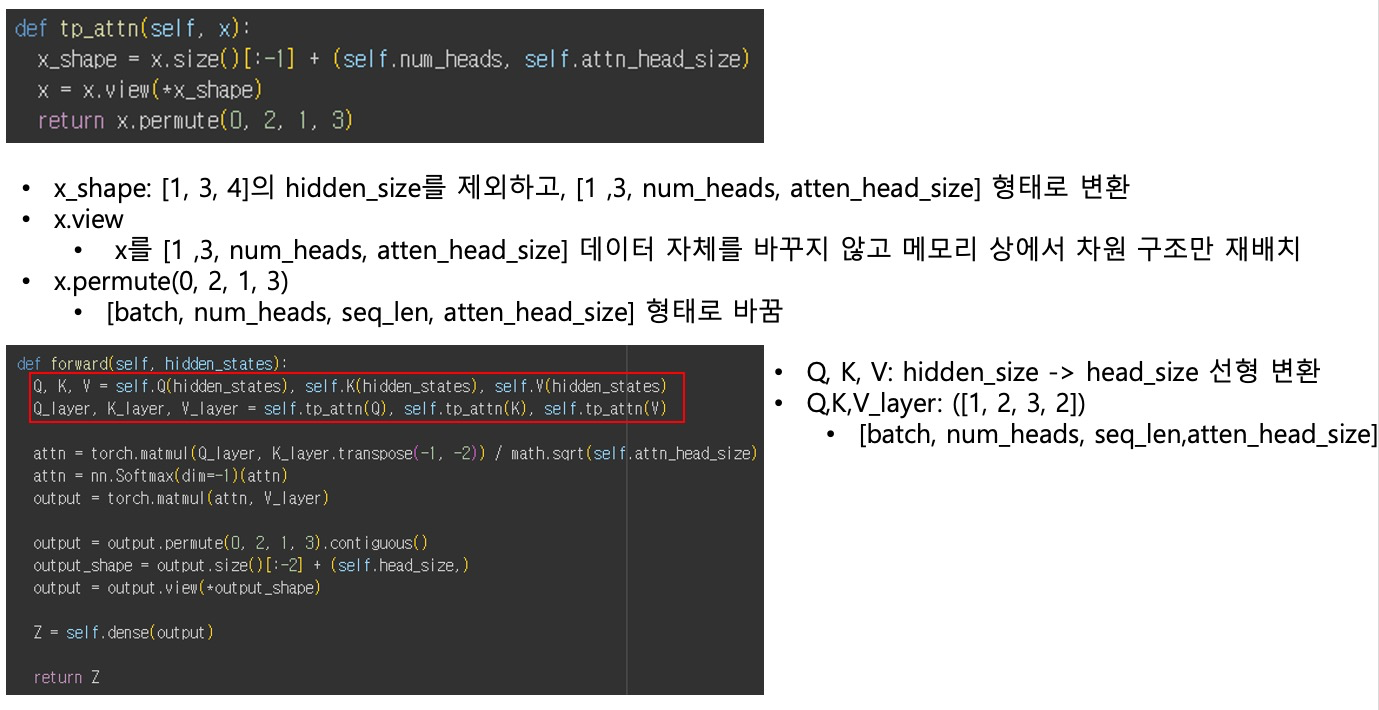
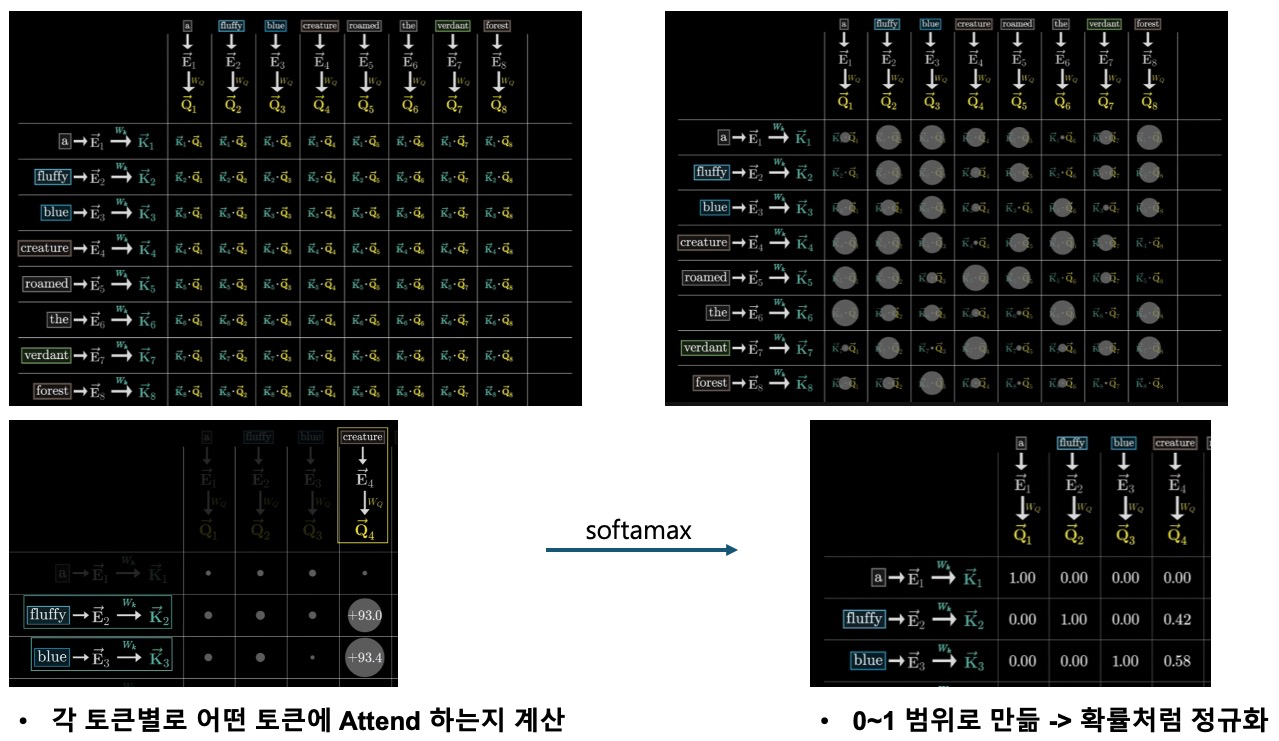
Attention 핵심 연산 – softmax(QKᵀ / sqrt(attn_head_size))
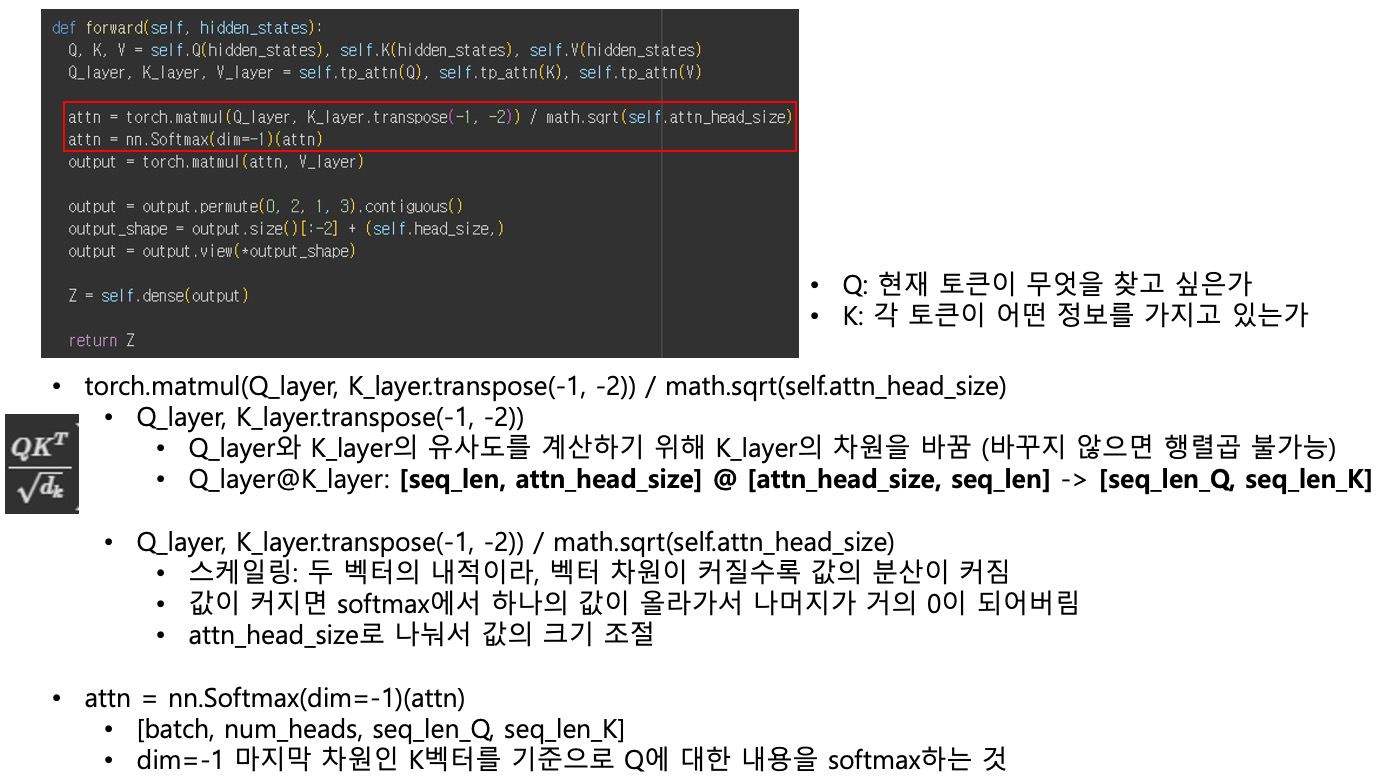
softmax(QKᵀ / sqrt(attn_head_size)) 과정
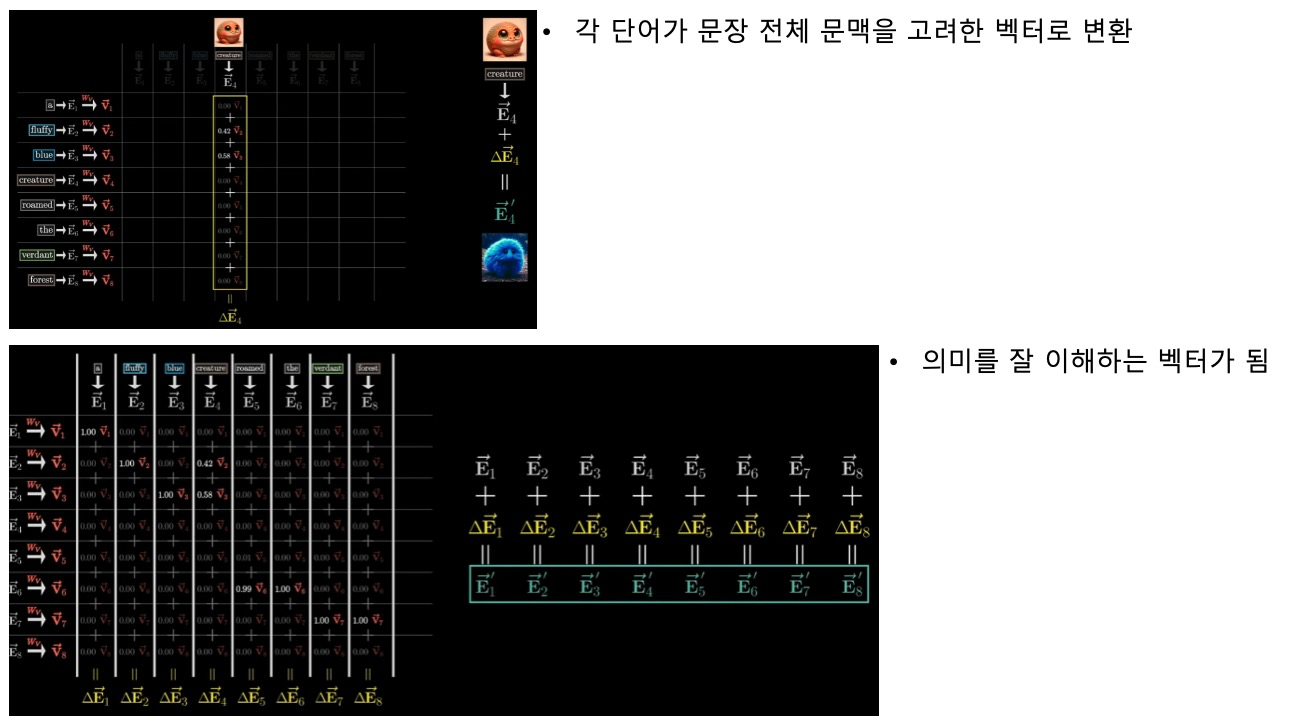
Attention 결과 계산 - torch.matmul(attn, V_layer)
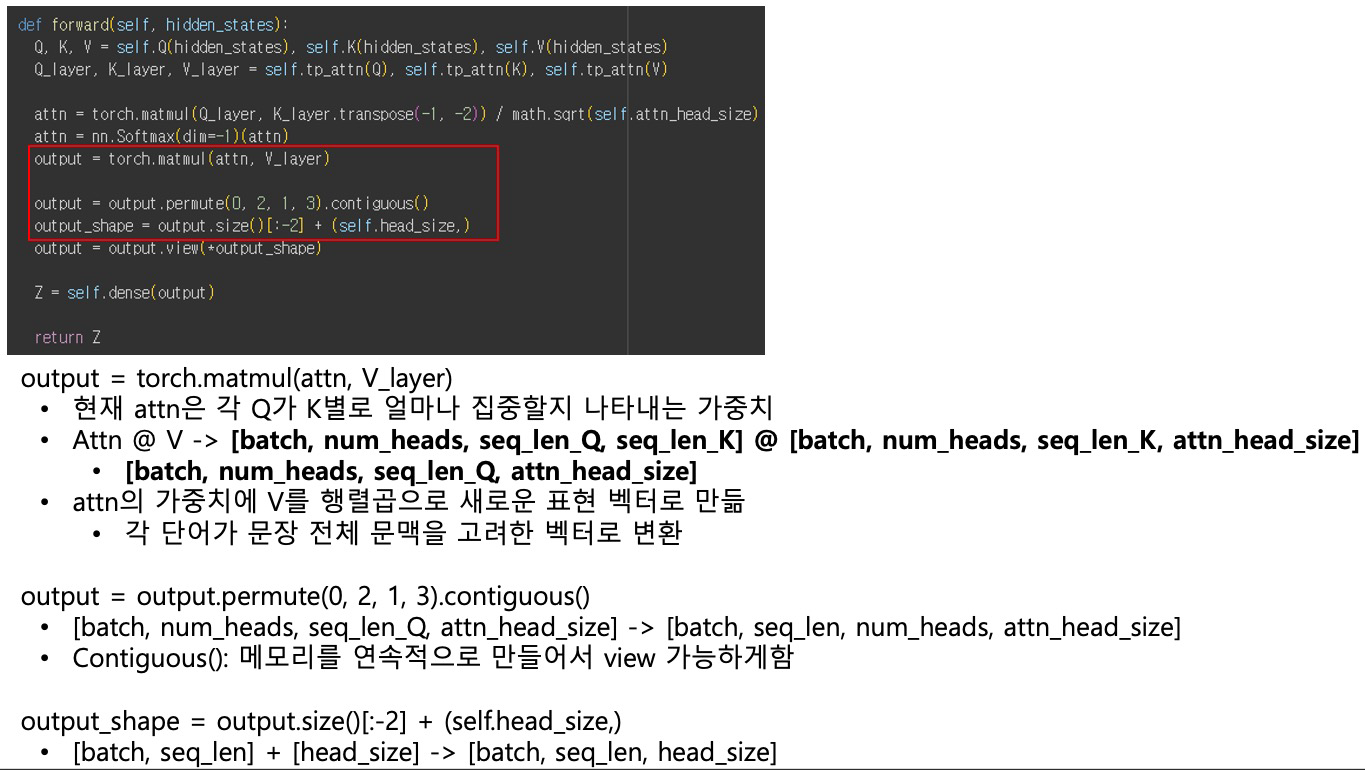
torch.matmul(attn, V_layer) 과정
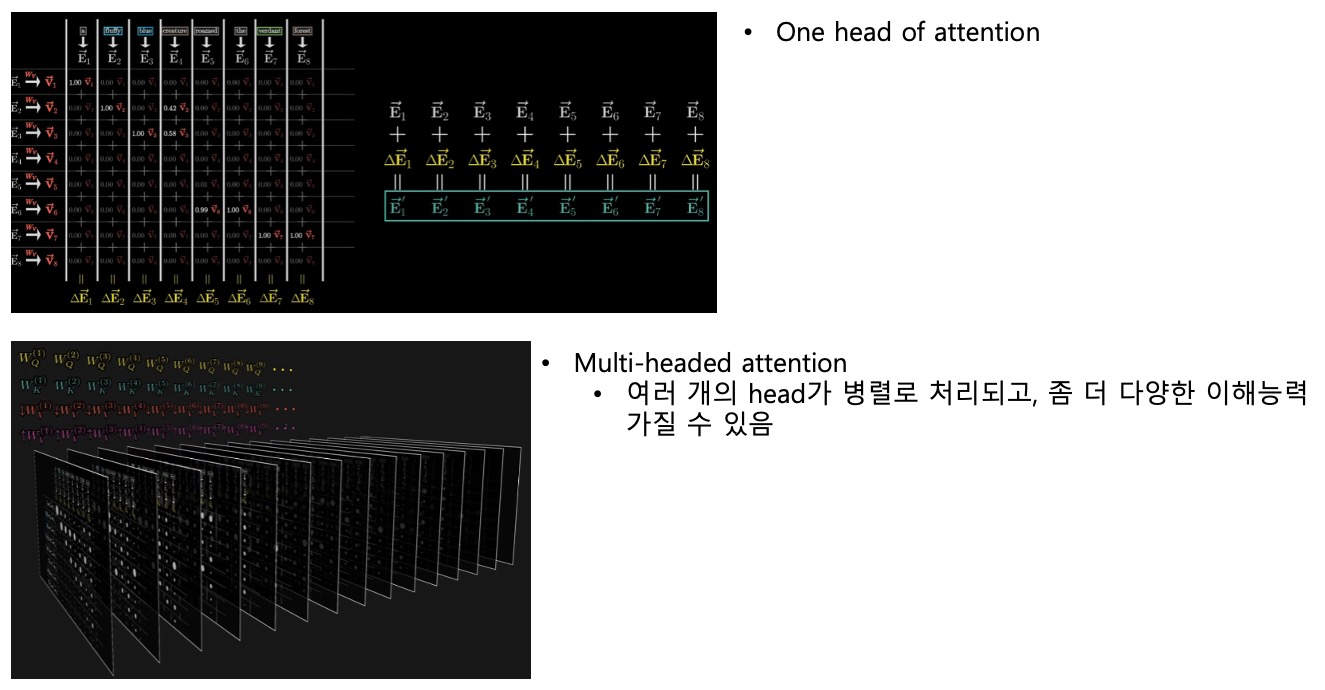
one head vs multi headed
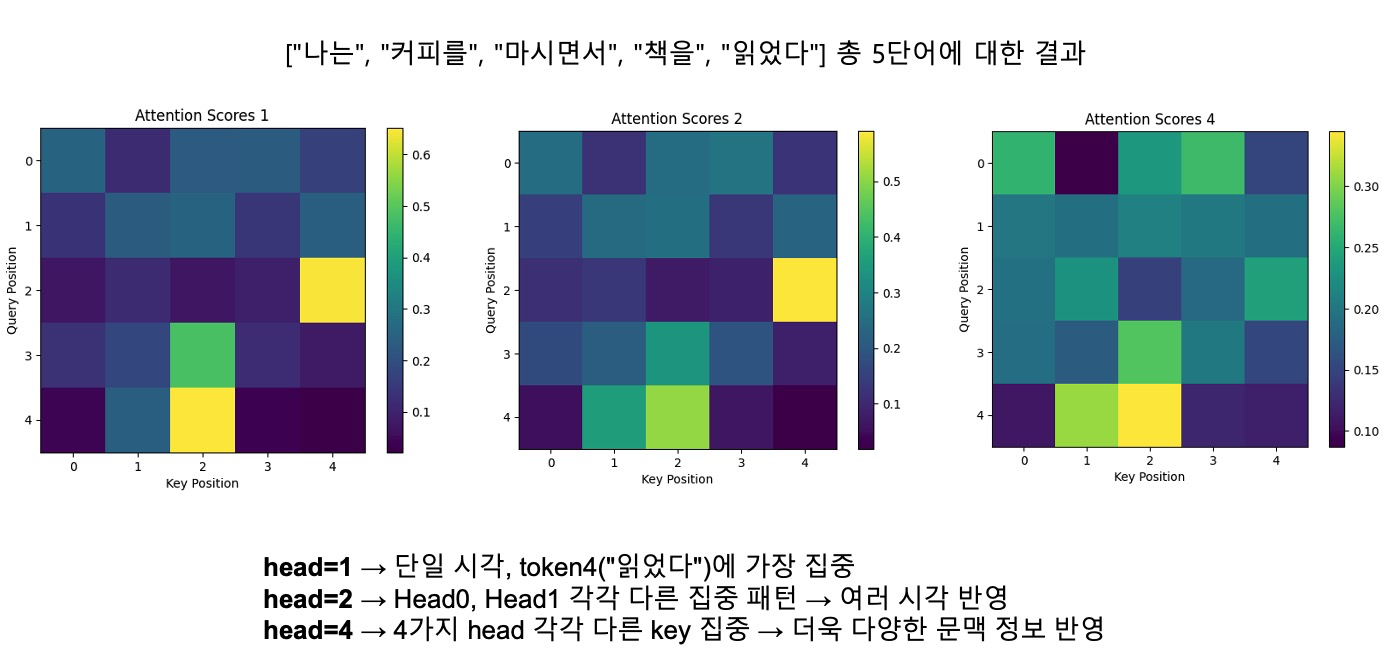
결과

AI is my life