Abstract
CLIP 같은 멀티모달 사전학습 모델은 대규모 이미지-텍스트 쌍으로 학습되어 일반성은 좋지만, 특정 도메인에서는 성능이 부족할 수 있다
이때 새 도메인 데이터와 과거 데이터를 모두 모아 재학습하면 메모리/시간 비용이 너무 크므로, 과거 지식을 유지하면서 새로운 도메인을 순차적으로 학습하는 continual learning이 중요
기존 Continual Learning 연구 대부분은 Unimodal 설정에 집중했다.
VLM 에서는 단순 정확도뿐만이 아니라 Image-Text 매칭 성능과 기존 Zero-Shot 성능의 forgetting까지 함께 봐야한다고 제시
이를 위해 다양한 도메인의 image-caption 데이터셋으로 벤치마크를 만들고, C-CLIP이라는 방법을 제안한다.
- 새로운 방법론 제시 뿐만 아니라, 무엇을 평가해야 하는가도 새롭게 정의
- 제안 방법론이 forgetting만 줄이는 것이 아니라 새로운 task학습도 강하게 향상 시킴
⇒ 일반 CL연구의 Stability와 Plasticity 사이의 trade-off 에 대한 문제를 겨냥한 논문
1 INTRODUCTION
CLIP은 VQA, clasification, segmentation, detection 등 여러 downstream task에 좋은 일반 respresentation을 제공
하지만, UNSEEN 도메인의 Image-Text 쌍에는 여전히 약함
해결책으로는 domain-specific 데이터로 CLIP을 fine-tuning하는 것이 자연스럽지만, 그렇게 하면 catastrophic forgetting이 발생해 원래 CLIP이 갖고 있던 일반적인 zero-shot 능력과 이전 task의 지식이 무너질 수있음. 또한, 매번 전체 데이터를 모아 재학습하는 것은 비용이 너무 큼
⇒ 어떻게하면 CLIP의 일반 표현을 유지함과 동시에 새로운 도메인에 계속 적응시킬 것인가
firstly
첫 번째 문제는 멀티모달 continual learning이 unimodal continual learning보다 훨씬 복잡하다는 점이다
이미 사전학습 모델이 zero-shot 분류를 꽤 잘하므로, backbone 전체를 크게 바꾸기보다 prompt/adaptor처럼 작은 부분만 조정하는 접근이 많다.
하지만, CLIP 같은 경우 단순한 이미지 분류가 아닌 Image-Text 정렬 자체가 중요한 멀티모달 테스크이기 때문에, 특정 도메인에서 성능이 부족할 경우 vision-encoder와 text-encoder를 함께 조정해야 하므로 문제 자체가 더 어렵다
secondly
두 번째 문제는 평가가 부족하다는 점이다.
기존 일부 연구는 CLIP을 continual setting 에서 사용했지만 주로 image-classification에 대한 정확도나 retrieval 한 측면만 보았다.
하지만 VLM이 현재 task를 잘하는 것뿐만 아니라, 기존에 가진 일반적인 zero-shot 표현 능력도 보존해야 한다고 봄
따라서:
- 학습된 멀티모델 downstream 태스크에서의 retrieval 성능
- Unseen domain에서의 retrieval 성능
- CLIP의 기존 zero-shot classification 성능 유지 여부
가 논문의 벤치마크 설계 철학
third
세 번째 문제는 전통적 regularization 기반 CL 방법의 본질적 한계
EWC, LwF류 방법은 파라미터나 feature space의 변화를 억제해서 forgetting을 줄임.
하지만 그 대가로 새 태스크를 적극적으로 배우는 능력, 즉 plasticity가 감소
논문은 이를 “기존 방법은 forget less because they learn less”라고 해석함
그래서 저자들은 단순히 보수적으로 업데이트를 제한하는 것이 아니라, 멀티모달 표현학습의 성질을 이용해서 이전 지식 보존과 새 지식 학습을 동시에 더 잘하게 만들 수 있는가를 탐구
정리하자면,
- VLCL를 제안
- 이 벤치마크는 image-caption 기반 continual learning을 평가하면서, 동시에 CLIP의 기존 general zero-shot performace도 유지되는지 측정
- C-CLIP이라는 방법론 제안
- multimodal LoRA integration
- forgetting 완화
- contrasive knowledge consolidation (CKC)
- 새 task 학습 강화 + forgetting 완화
- 여러 도메인 image-text 데이터셋에서 SOTA보다 좋은 continual learning 성능
2 RELATED WORK
2.1 CONTINUAL LEARNING
regularizaiton-based methods
- EWC, SL, LwF
- 파라미터 변화나 feature 변화에 penalty를 주어 이전 지식을 유지하게 유도
- 장점
- old data를 저장하지 않아도 됨
- 단점
- new task 학습을 강하게 제한
replay methods
- 이전 데이터 일부를 저장해 재사용하는 방식
- 장점
- forgetting 방지에는 강력
- 단점
- 추가 메모리, 계산량, 프라이버시 문제를 유
architecture-based methods
- 새 태스크마다 모듈을 추가하거나 확장하는 식
- task 수가 늘수록 파라미터가 급격히 커져 실제 배포에는 불리
prompt tuning, prefix tuning 같은 기법은 사전학습 모델 전체를 크게 바꾸지 않으면서 적응하려는 시도
하지만 대부분 unimodal에 초점을 두고 있고, 멀티모달 task를 충분히 다루지 못함
MTIL류는 CLIP을 visual dataset에 순차 적응시키고 zero-shot 성능을 평가하지만, 학습 데이터가 image-label 중심이거나 원래 CLIP의 general zero-shot 능력 손실을 제대로 보지 않는 한계가 있다고 비판
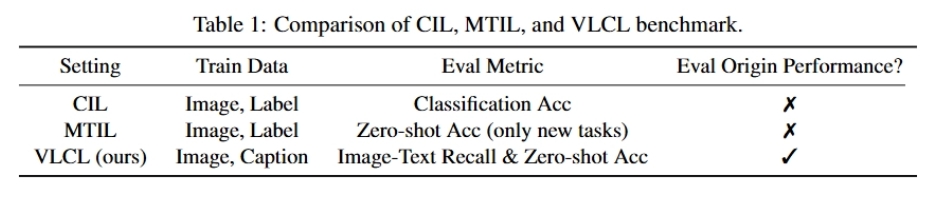
반면 이 논문이 정의한 VLCL은 image-caption 기반이고, retrieval과 origin performance를 함께
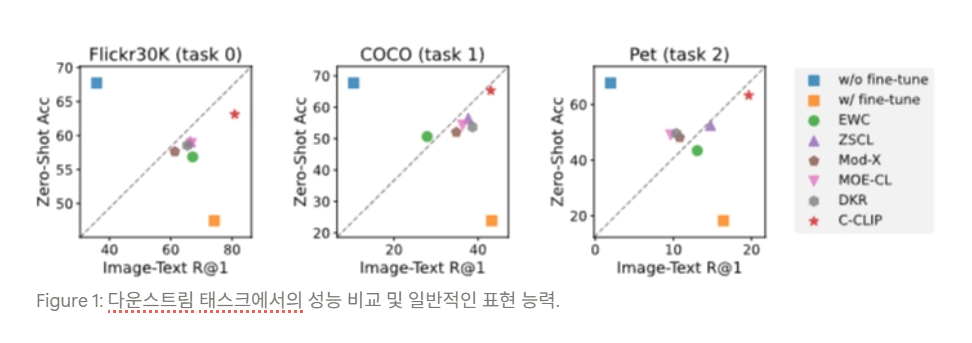
Table 1에서 저자들은 CIL, MTIL, VLCL의 차이를 정리합니다. VLCL만이 train data가 image-caption이며, image-text recall과 zero-shot accuracy를 모두 평가하고, 원래 성능 보존도 평가
2.2 VISUAL LANGUAGE REPRESENTATIONAL LEARNING
CLIP은 이미지 인코더와 텍스트 인코더로 구성되며, paired image-text는 positive, unpaired sample은 negative로 두는 contrastive learning으로 학습 ⇒ 다양한 zero-shot transfer 가능
CLIP은 대규모 데이터로 사전학습되어도 domain-specific image-text pair 정렬에는 약할 수 있음
따라서 현실에서는 새 도메인에 계속 적응해야 하는데, 그 과정에서 원래 general representation을 잃지 않는 것이 핵심 문제가 됨. 즉, 이 논문은 CLIP을 새로 만드는 논문이 아니라, 이미 강한 CLIP을 계속 업데이트할 때 어떻게 망가뜨리지 않을 것인가를 다룸
PROBLEM EFINITION AND BENCHMARK
3.1 수식 기반 문제 정의
시간 순서대로 개의 task가 있고, 각 단계 에서 현재 사용할 수 있는 데이터는 오직 현재 태스크의 image-caption dataset
여기서 는 이미지, 는 그 캡션
모델은 두 인코더로 구성
- 비전 인코더
- 텍스트 인코더
로 이미지와 텍스트를 같은 임베딩 공간 에 매핑
stage 에서의 목표는 현재 데이터 에 대한 loss를 줄이면서, 이전 태스크들 에 대한 성능 저하를 최소화하는 것
subject to
는 slack variable.
이면 j번째 이전 태스크에서 forgetting 발생,
이면 오히려 backward transfer가 일어난 것
⇒ continual learning의 목적을 "망각 최소화"에 한정하지 않고, 현재 학습 + 과거 유지 + 과거 개선까지 포함하는 framing. 이 설계가 뒤의 CKC 아이디어와 직접 연결됨
3.2 VLCL Benchmark
저자들은 세 가지 평가 트랙을 가진 벤치마크를 구성
(1) Multimodal Continual Learning
8개의 image-caption dataset을 순차 학습
- Flickr30K, COCO → 일반 real-world
- Pets, Lexica, Simpsons, WikiArt, Kream, Sketch → 특수 도메인 (AI-generated, 예술, 의류, 스케치 등)
⇒ 태스크 간 분포 차이가 꽤 큰 세팅
(2) Zero-shot Retrieval
훈련에 사용하지 않은 held-out dataset인 HaVG를 사용. 학습한 8개 태스크 외의 미지 도메인에서 retrieval 능력이 유지되는지를 평가
(3) Zero-shot Classification
원래 CLIP의 일반 표현 보존 여부를 확인하기 위해 6개 분류 데이터셋에서 zero-shot accuracy 측정
- ImageNet, CIFAR-100, Flowers, DTD, Food101, StanfordCars
⇒ 저자들의 핵심 주장: 이전 CLIP CL 연구들이 이 origin generalization retention을 충분히 평가하지 않았다는 점
3.3 Evaluation Metric
Multimodal CL
8개 태스크 전부 학습 후 각 데이터셋에서 Recall@1 계산
- I2T R@1: 이미지 넣었을 때 맞는 캡션이 top-1에 오는지
- T2I R@1: 텍스트 넣었을 때 맞는 이미지가 top-1에 오는지
Zero-shot Retrieval
미사용 HaVG에서 I2T R@1 측정. continual fine-tuning이 특정 도메인에만 과적합되어 미지 도메인 retrieval을 망가뜨리는지 확인
Zero-shot Classification
각 단계에서 zero-shot classification accuracy 측정, 마지막에 PD (Performance Degradation) 계산
⇒ PD가 작을수록 원래 CLIP의 general knowledge를 잘 보존한 것
4 THE PROPOSED METHOD: C-CLIP
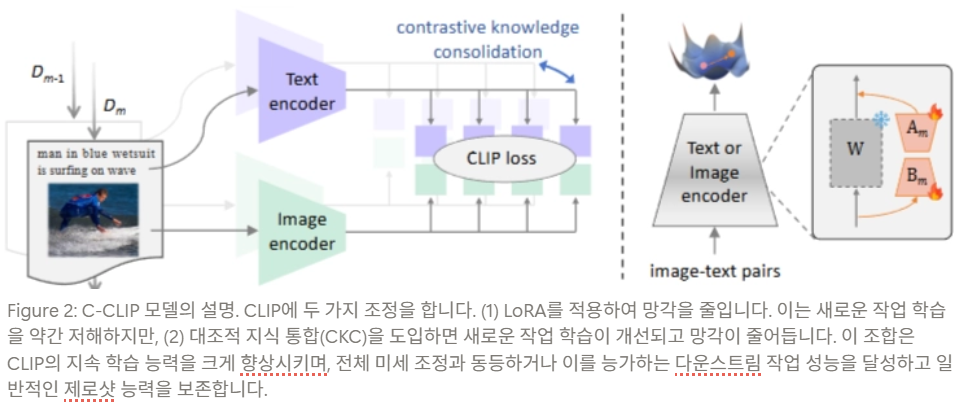
저자들은 continual learning의 목적을 두 축으로 나눔
- old task forgetting 완화 → LoRA integration
- new task learning 강화 → CKC (Contrastive Knowledge Consolidation)
4.1 LoRA Integration for Forgetting Mitigation
기본 구조
LoRA는 원래 가중치 행렬 전체를 직접 업데이트하지 않고, 저랭크 분해된 작은 보정항만 학습하는 방법. 논문은 vision encoder와 text encoder 모두에 LoRA 적용
Continual setting에서의 운용
- stage 에서 이전 파라미터 은 고정하고, 새로 붙인 LoRA 파라미터만 학습
- inference 시 task ID가 없으므로 태스크별 LoRA를 선택적으로 쓰는 건 불가능
- 각 stage가 끝날 때 현재 LoRA를 backbone에 integrate
는 integration coefficient. 실험에서는 사용
⇒ LoRA를 단순 효율화 도구가 아니라, forgetting mitigation mechanism으로 재해석
Theoretical Analysis
깊은 수학이라기보다 "왜 LoRA가 regularization과 비슷한 역할을 하는가"에 대한 설명
활성함수가 bounded이고 Lipschitz continuous이며 입력/가중치 노름이 bounded라면, MLP는 가중치에 대해 Lipschitz continuous
⇒ feature drift를 줄이고 싶으면 parameter drift를 줄여도 비슷한 효과.
LoRA는 구조적으로 전체 파라미터를 크게 움직이지 않고 저랭크 방향만 열어주는 방법이므로, 이 목적에 부합한다는 논리
엄밀한 최적성 보장은 아니고, "LoRA가 왜 forgetting 방지에 적합한 inductive bias인지"를 설명하는 정당화
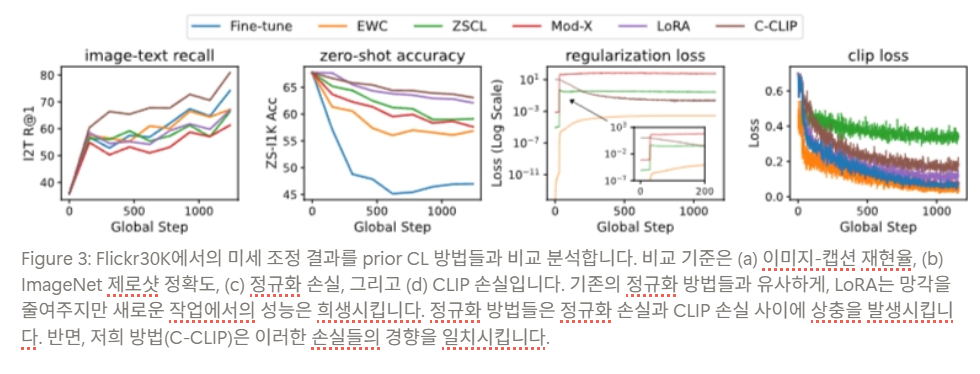
Empirical Verification (Figure 3)
- LoRA는 다른 regularization처럼 zero-shot forgetting을 줄이는 효과가 있음
- 하지만 그 대가로 현재 downstream task 성능은 full fine-tuning보다 낮아짐
- ⇒ LoRA alone도 여전히 stability-plasticity trade-off 안에 있음
기존 방법은 old space에 너무 맞추려다 보니, 새 도메인에서의 contrastive alignment 학습과 충돌.
반면 C-CLIP은 CKC 덕분에 이 충돌을 완화
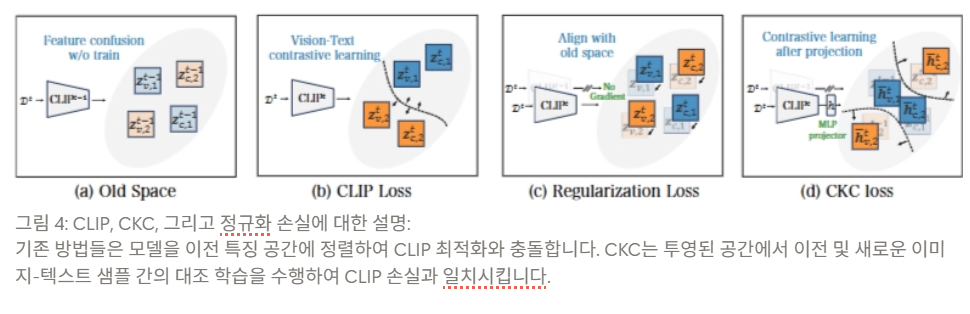
4.2 Contrastive Knowledge Consolidation (CKC) for Learning Enhancement
LoRA만 쓰면 forgetting은 줄지만 새 태스크 학습이 약해짐. 기존 방법들은 결국 "새 모델을 옛 feature space에 맞추는 것"에 가깝기 때문.
저자들은 단순 정렬이 아닌 old model에서 더 잘 배울 수 있도록 하는 방향으로 전환
CKC의 두 가지 핵심 아이디어
1. Projector 도입
- vision/text encoder 뒤에 projector 를 둠
- old space와 new space를 완전히 동일하게 강제하지 않고, projected 공간에서 학습
- 과거 지식과의 연결은 유지하면서 새 태스크를 위한 유연성 확보
- ⇒ plasticity를 높이는 역할
- Old projected features를 contrastive supervision으로 사용
- 현재 샘플의 old model feature → positive target
- 다른 샘플들의 old model feature → negative
- 즉, 새 표현은 "자기 자신의 과거 표현"과는 가깝고, "다른 샘플들의 과거 표현"과는 멀어지도록 학습
⇒ 이것이 CKC
CKC Loss 수식
보조 변수:
현재 모델의 image/text feature를 projector 통과 후 concat → normalize, 이전 모델의 image/text feature를 concat → normalize해서 사용
기존 regularization과의 핵심 차이
- 기존 regularization: "현재 feature가 이전 feature와 너무 멀어지지 마라" → pointwise constraint
- CKC: "현재 feature가 자기 과거 feature와는 가깝고, 다른 샘플들의 과거 feature와는 멀어지도록 분별적으로 배워라" → representation structure 전체를 contrastive하게 보존
⇒ 단순 feature drift 방지가 아니라, old space가 가진 **semantic relation을 supervision으로 활용**. 저자들이 "just aligning with old model"이 아니라 "learning better from old model"이라고 표현한 이유
Total Training Objective
- : 현재 태스크 자체를 잘 학습하기 위한 원래의 멀티모달 contrastive 목적
- : 이전 모델의 표현 구조를 teacher처럼 활용해 forgetting 완화 + representation continuity 유지
⇒ 기존 regularization은 CLIP loss와 충돌하는 경우가 많았음, CKC는 contrastive 형태로 CLIP 학습과 objective 형태가 더 잘 맞음
5 EXPERIMENTS
기본 설정
- 백본: CLIP ViT-B/16 (pretrained zero-shot ImageNet-1K acc: 67.73%)
- 8x NVIDIA 4090 GPU, batch size 1024, 해상도 224x224, 각 데이터셋 40 epoch
- LR: , 5-epoch warmup + cosine decay
- LoRA rank: 16
- Optimizer: AdamW (), weight decay 0.2
- text/image encoder LR을 다르게 설정 (예: COCO에서 image , text )
- 비교 대상: EWC, ZSCL, Mod-X, MOE-CL, DKR / prompt 기반: L2P, CPE-CLIP
5.1 Main Results
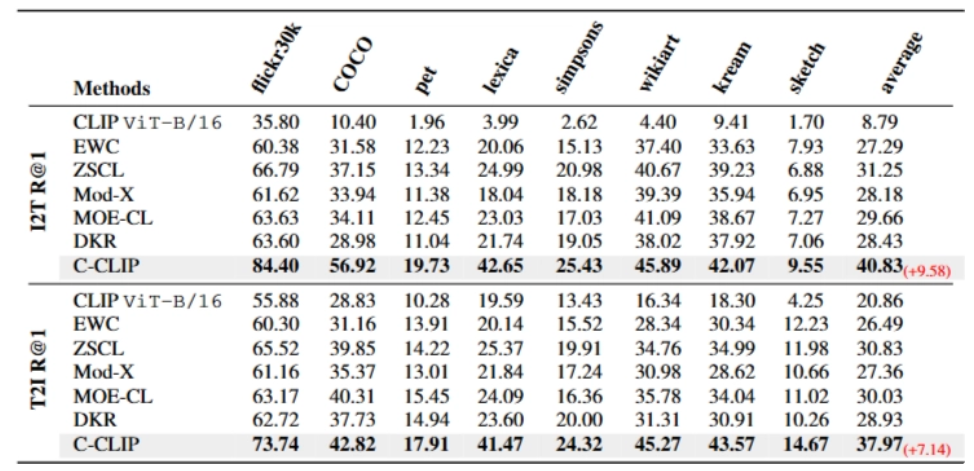
5.1.1 Trained datasets에서의 Retrieval 성능
5.1.2 Unseen dataset에서의 Retrieval 성능
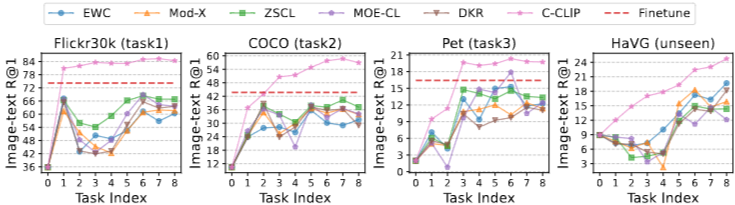
HaVG 결과: 일부 baseline은 task-specific 도메인(특히 AI-generated)에 fine-tuning되면 real-world 데이터에서 불안정해지는 반면, C-CLIP은 unseen retrieval에서도 좋은 추세
⇒ continual fine-tuning이 특정 도메인 적응만 잘하고 general retrieval을 망가뜨리면 실사용성이 떨어지는데, C-CLIP은 representation collapse 없이 범용성도 유지
5.1.3 Zero-shot Classification 유지
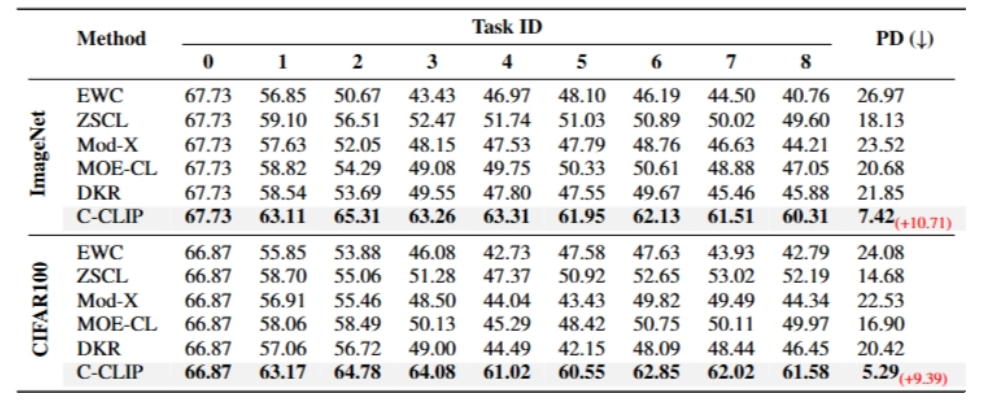
⇒ C-CLIP이 가장 적게 잊음. baseline 최강 대비 ImageNet PD 10.71 낮음
두 태스크만 학습 후에도 ImageNet zero-shot이 67.7% → 65.1% 수준으로만 하락 (full fine-tuning은 ~25%까지 떨어짐)
⇒ C-CLIP은 단순 retrieval 전용 튜닝이 아니라 CLIP의 general zero-shot semantics를 꽤 잘 보존
5.2 Ablation Study and Further Analysis
5.2.1 Component별 기여
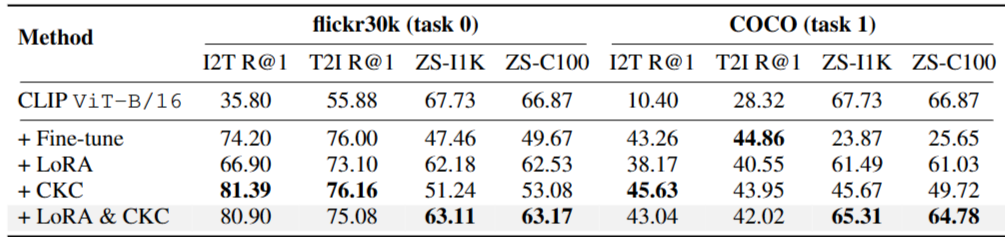
- LoRA만: forgetting 줄지만 새 태스크 retrieval 하락
- CKC만: 새 태스크 retrieval 크게 상승, forgetting 억제는 LoRA만큼은 아님
- LoRA + CKC: 두 장점 결합. retrieval도 강하고 zero-shot 유지도 강함
⇒ C-CLIP의 성능은 **"안정성 역할의 LoRA + 학습강화 역할의 CKC"라는 분업 구조** 덕분
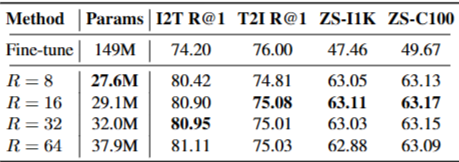
5.2.2 LoRA Rank 영향
5.2.3 Learning Rate Analysis
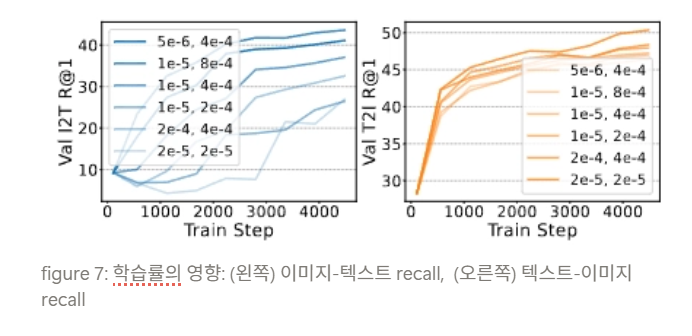
- image encoder와 text encoder의 LR을 동일하게 두면 I2T 성능 저하 가능
- text encoder LR을 더 크게 두는 것이 중요 (COCO: image , text )
⇒ CLIP fine-tuning에서 텍스트 쪽이 도메인 적응에 더 민감하게 작동할 수 있다 라고 주장
5.2.4 Regularization Loss vs CKC
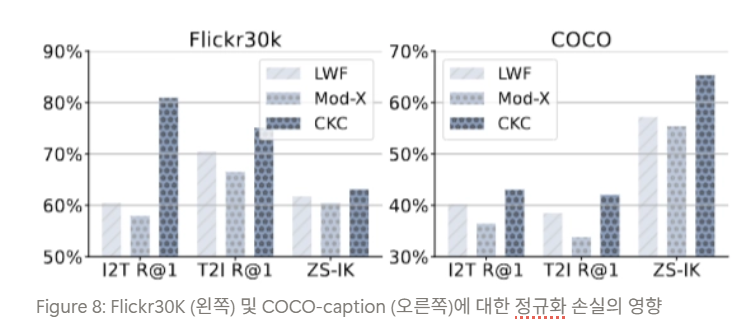
- EWC/LwF/Mod-X/LoRA류 regularization은 모두 feature space 변화량을 줄이는 방향 → 유사한 효과
- LoRA와 결합 시 새 태스크 학습이 여전히 제한됨
- CKC는 LoRA와 훨씬 잘 결합됨
⇒ CKC는 단순 constraint가 아니라 old model을 teacher-like contrastive target으로 쓰는 representation-learning objective ⇒ CLIP과 궁합이 좋음
5.2.6 LoRA vs Prompt-tuning
- Prompt tuning: backbone을 거의 안 건드리니 원래 CLIP 지식 보존에는 유리
- 하지만 새 태스크를 강하게 배우고 오래 유지하는 데는 약함
⇒ 멀티모달 retrieval CL에서는 보수적 접근보다 LoRA + CKC가 더 효과적
6 CONCLUSION
논문의 주요 기여 3가지:
-
VLM의 continual learning은 기존 unimodal CL과 다르게 봐야 함
-
VLCL benchmark처럼 retrieval + unseen retrieval + origin zero-shot을 함께 보는 평가가 필요
-
C-CLIP은 LoRA integration으로 forgetting 완화, CKC로 새 태스크 학습 강화하여 기존 SOTA 대비 우수한 성능
⇒ CLIP을 계속 배워야 한다면, 정규화로 꽉 묶지 말고, 작은 파라미터 이동으로 안정성 확보 + old representation을 contrastive teacher처럼 활용해서 새 태스크도 강하게 배우게 하자
