https://arxiv.org/pdf/2505.15160
Abstract
Vision Transformer(ViT)는 컴퓨터 비전 분야에서 표준 아키텍쳐로 자리 잡았지만, 거대한 크기로 인한 Computational Overhead를 유발
Token Compression 기법은 이러한 문제를 해결하기 위해 많은 주목을 받고 있지만, 정보 손실이 문제
정보 손실을 해결하고 추가적인 성능개선을 위해 fine-tuning 하는 경우가 다수
본 논문에서는 fine-tuning의 필요성을 없애면서도 경쟁력 있는 성능을 유지하며, 적은 손실 토큰 병합을 보장하는 새로운 방법인 Adaptive Token Merging (ATM) 을 제안
- 본 논문의 3가지 주요 기여
- layer별 adaptive한 token merging 개수
- similarity 뿐아니라 merging size 까지 고려한 token matching 기법 도입
- Batch-Adaptive Merging 도입
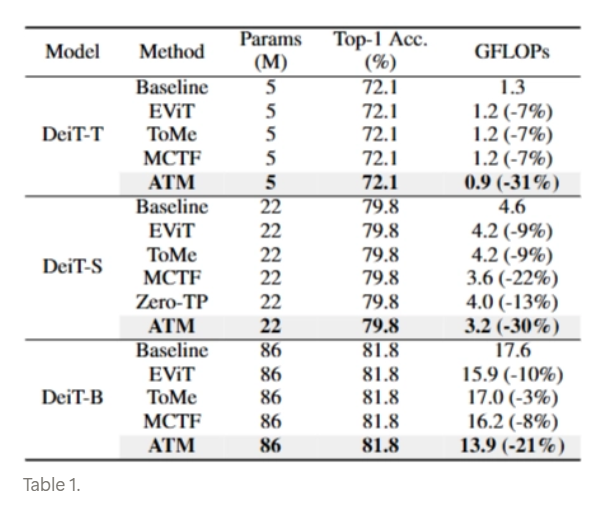
본 논문의 ATM은 DeiT-T 및 DeiT-S 모델에 대해 기존 방법 대비 정확도 저하 없이 FLOPs를 30% 이상 감소했다고 보고됨
Introduction
Vision Transformer(ViT)는 광범위한 시각 인식 task에서 SOTA 달성
하지만 크기가 너무 거대하여, 긴 학습 시간과 높은 계산 비용 수반
다양한 모델 압축 기법이 ViT 자체의 크기를 줄이려고 시도했지만, 그 경우 사전 지식을 잃을 수 있으며 성능 복구를 위한 추가 학습 단계가 요구 될 수 있음
이에 따라, 최근에는 추론 과정에서 동적으로 입력 토큰 수를 줄이는 것을 목표로 하는 Token Compression 이라는 대안이 등장
Token Compression은 모델 아키텍쳐를 변경할 필요 없이, ViT의 계산 효율성을 효과적으로 향상 시킴
초기 접근 방식은 Token Pruning으로 CLS 토큰의 Attention 점수와 같은 Heuristic 기준에 따라 중요하지 않은 토큰을 식별하고 Pruning 하는것을 목표로 함
Pruning의 정보 손실을 완화하기 위해, 덜 중요한 토큰을 완전히 폐기하는 대신 유사한 토큰 쌍을 병합하는데 초점을 맞춘 Token Merging이 유망한 해결책으로 연구 됨.
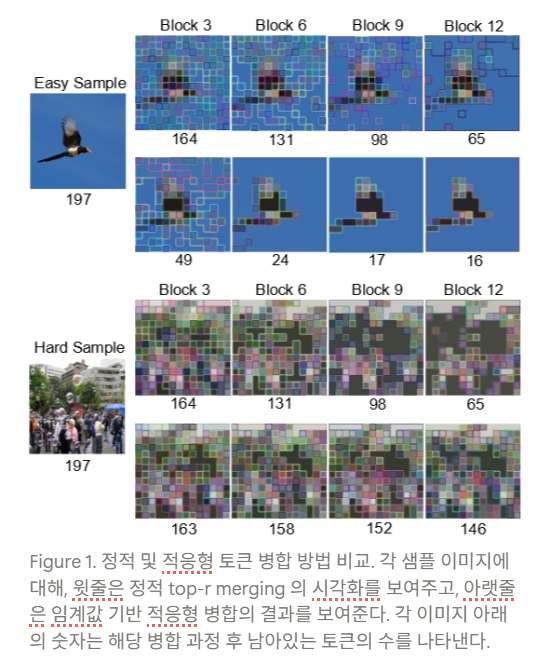
기존 Token Merging 방식은 각 layer 및 각 Instance에 대해 뱡합할 token의 개수가 고정되어 있었음
ex. Top-r Token merging
이는 쉬운 샘플의 경우 과소 병합되고, 어려운 샘플의 경우 과대 병합되는 결과를 초래
이 경우 비효율적이거나 과도한 Token reduce로 이어져 값비싼 후처리(fine-tuning)을 필요로 하기도 함
본 본문에서는 fine-tuning이 필요없는 Adaptive Token Merging (ATM)을 제안함으로써,
Token Merging에서 fine-tung을 완전히 제거하면서도 높은 성능을 보장
- 본 논문의 3가지 주요 기여
- 고정된 수의 쌍 병합 대신, instace와 layer 전반에 걸친 적응적 개수에 따른 토큰 병합을 제안
- 최종 layer에 대해 크기 구별 토큰 매칭을 도입
- 실용적인 배치 추론을 위해 batch-processing 시나리오에서 Token compression을 가능하게 하는 batch-adaptive merging을 통합
Related Works
Efficient Vision Transformers
- ViT의 성능을 유지하며 효율성을 향상시키기 위한 연구가 광범위하게 진행되어옴
- Weight Pruning, Knowledge distillation 등 과 같은 다양한 Compression 기법
- Token compression은 모델 아키텍처를 변경하지 않고 입력 이미지 토큰 수를 줄여 추론 속도를 가속화하는 또 다른 효과적은 접근 방식으로 부상
Token Compression
- Token pruning
- 주로 CLS 토큰의 어텐션 점수 또는 추가적인 학습 가능한 파라미터를 사용하여 중요하지 않은 토큰을 구별
- Token merging
- 토큰 쌍 간의 다양성 또는 유사성을 고려하여 하나의 대표로 요약될 수 있는 토큰을 식별
- 최근에는 pruning과 merging을 결합하거나 유사성, 정보성, 병합 크기와 같은 다중 기준에 기반하여 토큰을 선택
- 이러한 방법들은 추가적인 사후 훈련의 도움 없이는 상당한 성능 저하를 겪음
Training-Free Token Compression
Token compression 분야에서 몇몇 접근 방식은 모델 아키텍처와 토큰 자체만을 활용하여 추가적인 fine-tuning의 필요성을 제거하려고 시도함
- ATS
- CLS 토큰의 어텐션 점수와 value vector norms을 기반으로 중요도 점수를 얻은 후 역변환 샘플링을 사용하여 토큰을 pruning
- ToME
- 각 레이어에 대하여 가장 유사한 상위 r개의 토큰 쌍을 단순히 병합
- MCTF
- 병합할 토큰 쌍을 선택하기 위해 다중 기준을 고려
- Zero-TP
- 어텐션 행렬을 사용하여 중요도 및 유사도 기반 지표를 통해 pruning
Adaptive Token Merging
Preliminaries
Token Reduction in ViT
ViT 아케텍처에서, 여러 토큰 블록이 순차적으로 쌓이고 입력 토큰 ∈ 는 순차적으로 쌓인 토큰 블록을 통해 처리 됨.
여기서 ∈ [ 1, L ]은 블록 인덱스, L은 총 블록수, N은 토큰 수, D는 각 토큰의 차원
각 블록 내에서, 입력 은 다음과 같이 처리
Attn 에서는 N이 지수적으로, MLP에서는 N 의 계산 비용이 선형적으로 증가하므로, token compression의 목표는 이 N의 비용을 최소화 하는 것
Baseline Token Merging
- 기존 토큰 병합의 공통 수행 절차
- 토큰 그룹 분할: 각 레이어의 토큰을 교차 할당 ( alternating token assignment ) 방식을 통해 동일한 크기의 두 그룹으로 나눔.
- 이분 매칭 수행: 분할된 레이어 내에서 유사한 토큰 쌍을 병합하기 위해 이분 매칭 ( bipartite matching ) 절차를 적용함.
- 이분 매칭의 장점
- 토큰 가지치기 ( token pruning ) 에 비해 상대적으로 정보 손실 ( information loss ) 이 적은 것으로 보고됨.
- 기존 방식의 한계점 (정적 접근)
- 고정된 병합 개수: 모든 기존 방법들은 레이어 및 이미지 전반에 걸쳐 미리 정의된 고정된 개수 ( predefined number ) 의 토큰 쌍만을 병합하는 정적 ( static ) 접근 방식을 취함.
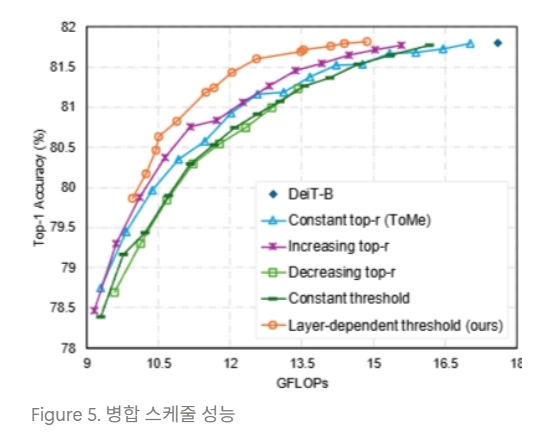
- 문제 발생: 이러한 정적 방식으로 인해 이미지의 특성이나 레이어 깊이를 반영하지 못하여, 과대 병합 ( over-merging ) 또는 과소 병합 ( under-merging ) 문제가 필연적으로 발생함 (Figure 1 참조)
Threshold-Based Adaptive Token Merging
- ATM (Adaptive Token Merging) 제안 배경
- 기존의 정적 병합 ( static merging ) 방식이 가진 한계를 극복하기 위해 ATM 을 제안함.
- 이미지 단위 ( image-wise ) 와 레이어 단위 ( layer-wise ) 의 적응을 모두 고려하여 설계됨.
- 기본 전략: 임계값 기반 병합 (Threshold-Based Merging)
- 가장 높은 유사도를 가진 고정된 개수의 쌍을 병합하는 기존 방식에서 벗어남.
- 각 레이어에 설정된 임계값 을 기준으로, 실제로 충분히 유사한 토큰 쌍만을 선택하여 병합함.
- 이를 통해 이미지 특징의 복잡성에 따라 토큰 축소 ( token reduction ) 정도를 효과적으로 제어함 (Figure 1 참조).
- 임계값 설정의 중요성 및 단일 임계값의 한계
- 정보 손실 ( information loss ) 을 최소화하려면 임계값을 적절히 설정하는 것이 핵심임.
- 모든 레이어에 단일 임계값을 전역적으로 일괄 적용하는 것은 극단적이고 쉬운 해결책이지만, 이어지는 경험적 연구 ( empirical study ) 분석에 따르면 만족스러운 성능을 달성할 가능성이 낮음.
Layer-Wise Impact on Information Loss
- 정보 손실 측정 방법
- 실제 예측에 최종 CLS 토큰만 사용되는 DeiT-S 모델의 특성을 고려함.
- 원본 CLS 토큰의 값을 압축 모델이 생성해야 할 이상적인 결과로 간주함.
- 특정 레이어에서만 병합을 수행한 후, 원본 CLS 토큰과 변경된 CLS 토큰 사이의 코사인 거리 ( cosine distance ) 를 측정하여 병합으로 인해 발생하는 정보 손실의 정도를 정량화함.
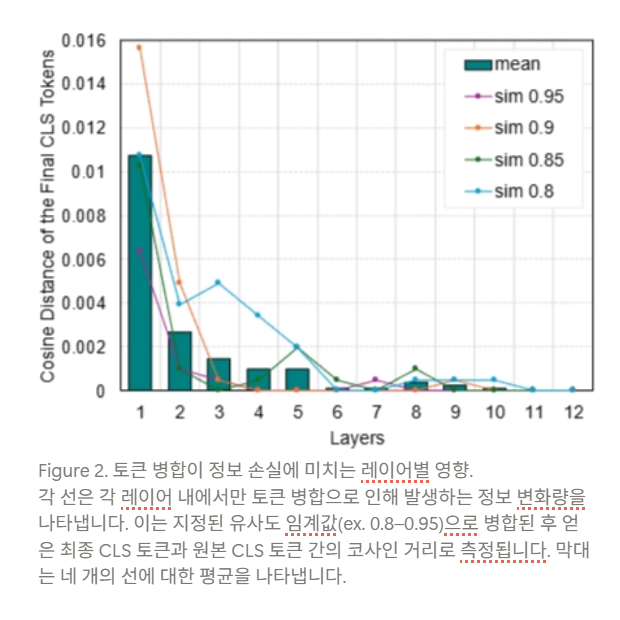
- 실험 관찰 결과 (Figure 2)
- 다양한 유사도 임계값 ( 0.8–0.95 ) 으로 레이어별 병합을 수행했을 때 발생하는 최종 CLS 토큰의 정보 손실을 분석함.
- 레이어가 최종 출력에서 멀어질수록 ( 즉, 초기 레이어일수록 ) 정보 손실이 기하급수적으로 증가하는 것이 관찰됨.
- 원인 분석 및 결론
- 병합으로 인한 정보 손실이 최종 레이어보다 초기 레이어에서 훨씬 더 크게 누적되기 때문임.
- 결과적으로, 초기 레이어에서 특정 임계값을 통한 토큰 축소를 진행하면, 최종 레이어에 동일한 임계값을 사용할 때보다 정보 손실량이 상당히 커짐.
- 이는 레이어 간 토큰 병합으로 인한 정보 손실에 차이가 존재하므로, 모든 레이어에 일정한 ( constant ) 임계값을 적용하는 것이 최적이 아님 ( suboptimal ) 을 시사함.
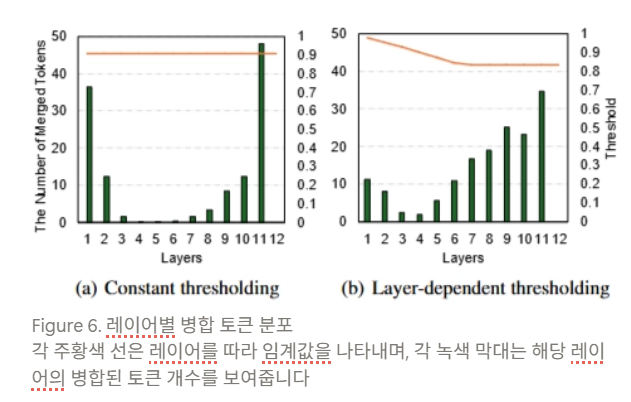
Layer-Dependent Thresholding
- 제안 배경 및 기본 전략
- 앞선 분석을 바탕으로, 서로 다른 레이어에 걸쳐 유사도 임계값을 적절히 조정하기 위한 레이어 의존적 임계값 설정 ( layer-dependent thresholding ) 방식을 제안함.
- 기본적으로 초기 레이어 에서는 더 높은 임계값으로 시작하고, 최종 레이어 에 가까워질수록 임계값을 점진적으로 감소시킴.
- 임계값 감소 함수 (Decreasing Function)
- Figure 2의 지수적 곡선 ( exponential curve ) 에 영감을 받아, 특정 레이어 에 대한 임계값 의 감소 함수를 다음과 같이 설계함.
- : 초기 임계값 ( initial threshold value )
- : 임계값의 감소 속도 ( rate of threshold decay ) 를 제어함
- : 임계값의 하한선 ( lower bound ).
Size-Distinctive Token Matching
- 적응형 임계값 설정 방식을 통해 정보 손실을 크게 줄일 수 있으나, 임계값이 점진적으로 감소하는 전략 특성상 최종 레이어 에서는 초기 레이어에 비해 덜 유사한 토큰들이 병합되는 현상이 불가피
- 또한, 최종 레이어에 남아있는 토큰들은 이미 이전 레이어들을 거치며 여러 토큰들과 누적 병합된 상태
- 따라서 동일한 레이어에서 동일한 유사도를 가진 토큰들을 병합하더라도, 누적된 병합 토큰의 수에 따라 발생하는 정보 손실량은 크게 달라질 수 있음
Definition 1 (Merging Size)
토큰 의 병합 크기 는 다음과 같이 정의됨
- 가 병합된 적 없는 원본 토큰인 경우,
- 가 다른 토큰들의 병합으로 생성된 경우, 를 구성하기 위해 병합된 모든 토큰 들의 병합 크기 의 합
Definition 2 (Merging Error)
단일 병합 연산에서 발생하는 정보 손실량을 정량화한 지표
- 병합 크기가 각각 와 인 정규화된 두 토큰 벡터 와 가 주어졌을 때, 병합된 토큰 는 두 토큰의 가중 평균 으로 계산됨
- 이때 병합 오차 은 다음과 같이 정의됨
- 여기서 은 두 토큰 벡터 간의 코사인 거리를 나타냅니다.
- 이 오차 지표는 이전 레이어부터 누적된 정확한 정보 손실을 계산하는 대신, 해당 시점의 단일 병합 연산에서 발생하는 손실에 집중함
- 각 토큰이 자신의 병합 크기만큼 복제되어 있다고 간주하여 총 불일치량을 정량화 한다
Theorem 1
는 두 토큰의 병합 크기와 코사인 거리에 의해 다음과 같은 범위를 가진다
이 정리에 따르면, 병합되는 토큰 간의 유사도가 동일하더라도 병합 크기 조합에 따라 오차가 극적으로 달라지며, 이를 3가지 사례로 분석할 수 있음
- 사례 1 (Small + Small)
- 인 원본 토큰 간의 병합
- 병합 오차는 최대 와 동일하여 손실이 미미하며, 이는 주로 초기 레이어에서 관찰됨
- 사례 2 (Small + Large)
- 처럼 크기 차이가 큰 경우
- 수식에 의해 값이 크게 증가하지 않으므로, 병합 오차는 에서 사이로 제한되어 여전히 코사인 거리에 의해 지배됨
- 사례 3 (Large + Large)
- 처럼 병합 크기가 모두 큰 경우
- 병합 오차는 최소 , 최대 가 되어, 다른 사례들에 비해 수십 배에서 수백 배 더 큰 심각한 정보 손실을 초래한다
Size-Distinctive Token Matching
Theorem 1의 수학적 분석을 바탕으로, 최종 레이어의 정보 손실을 최소화하기 위해 제안된 새로운 이분 매칭 방식
- 동작 원리
- 기존의 교차 할당 ( alternate grouping ) 방식을 대체
- 레이어 내의 토큰들을 병합 크기를 기준으로 먼저 정렬
- 그 후 정렬된 그룹을 정확히 반으로 나누어, 병합 크기가 작은 토큰 그룹과 큰 토큰 그룹으로 완전히 분리
- 효과
- 이 분할 매칭 방식을 통해 병합 크기가 큰 토큰들끼리 매칭되는 ( Large + Large ) 상황을 원천적으로 배제
- 결과적으로 최종 레이어에서 발생할 수 있는 증폭된 병합 오차와 심각한 정보 손실을 효과적으로 최소화한다.

Batch-Adaptive Merging
- 이미지마다 병합되는 토큰 수가 다를 경우, 다수의 이미지를 병렬로 처리하는 배치 추론 ( batched inference ) 이 불가능 해짐
- 기존의 정적 방식들이 고정된 개수의 토큰만 병합했던 이유가 여기에 있음
- ATM 은 다수의 이미지를 동시에 처리하는 실용적인 연산 효율성을 유지하면서도, 적응형 토큰 축소의 이점을 취하기 위해 배치 적응형 병합 을 도입
병합 개수 산출 공식
- 특정 배치 에 대하여, 레이어 에서 축소(병합)할 토큰 쌍의 개수 은 다음과 같이 적응적으로 산출됨
- : 배치 내 전체 이미지의 수.
- : 배치 내 특정 이미지 의 레이어 에 위치한 두 토큰 인덱스 와 에 해당하는 벡터 간의 코사인 유사도.
- : 비교 대상이 되는 두 토큰 그룹 간의 매칭 인덱스 쌍 의 집합.
- : EQ 1에 의해 산출된 해당 레이어의 임계값.
공식의 의미
- 지시 함수 를 통해 임계값 을 넘는 (즉, 충분히 유사한) 토큰 쌍의 수를 배치 내 모든 이미지에 대해 합산한 후, 배치 크기 로 나누어 평균을 구한다
- 결과적으로 배치 전체를 기준으로 해당 레이어에서 평균적으로 몇 개의 토큰이 임계값을 충족하는지에 따라 병합할 개수 이 동적으로 결정된다
overall Process
- 매칭 전략 선택
- 현재 연산 중인 레이어의 깊이에 따라 그룹화 및 매칭 전략을 분기
- 초기 레이어에서는 교차 할당 기반의 매칭 ( alternate matching )
- 최종 레이어 부근에서는 크기 구별 매칭 ( size-distinctive matching )
- 유사 토큰 쌍 식별
- 레이어 의존적 임계값 을 적용하여 유사도가 임계값을 넘는 토큰 쌍들을 찾음
- 배치 병합 개수 결정
- 앞서 설명한 배치 적응형 병합 공식을 통해 해당 레이어에서 병합할 최종 토큰 쌍의 개수 을 계산
- 토큰 병합 수행
- 산출된 개수만큼 토큰 쌍을 병합하여 새로운 토큰 벡터로 대체
Experiments
본 섹션에서는 ATM의 성능에 대한 상세한 연구를 제시
특히, 학습이 필요 없는(training-free)시나리오에 초점을 맞춤
Alternate Matching vs Size-Distinctive Matching

분기레이어 정의
- 분기 레이어 깊이는 ATM 구조 내에서 교차 매칭과 크기 구별 매칭 중 어느 전략을 적용할지 결정하는 경계선을 의미
- 수식에서 (단, ) 는 교차 매칭이 적용되는 마지막 레이어의 인덱스를 나타냄
실험 결과 및 관찰 (Table 3 기반)
- ATM 은 동적으로 병합 개수를 조절하는 적응적(adaptive) 특성을 가지므로, 설정 값에 따라 모델의 최종 연산량(FLOPs)이 달라짐
최적의 성능
- 크기 구별 매칭을 전체 레이어 깊이 중 대략 마지막 1/4 구간 에 적용했을 때 가장 우수한 성능이 도출
- 전략 미사용 시 성능 하락: 와 같이 모델의 끝까지 교차 매칭만 사용하고 크기 구별 매칭을 배제할 경우 성능이 저하됨
- 전략 조기 적용 시 부작용: 과 같이 크기 구별 매칭을 처음부터 너무 일찍 시작하면 성능이 하락할 뿐만 아니라 연산량(FLOPs)도 상대적으로 증가. 이는 초기 레이어 단계에서는 병합 크기(merging size)가 정보 손실에 미치는 영향력이 작다는 앞선 분석(3.3절)을 실험적으로 뒷받침 함
최종 설정
- 위와 같은 실험적 관찰을 근거로, 논문은 모든 실험 환경에서 분기 레이어 깊이를 전체 레이어의 약 3/4 지점 으로 고정하여 설정
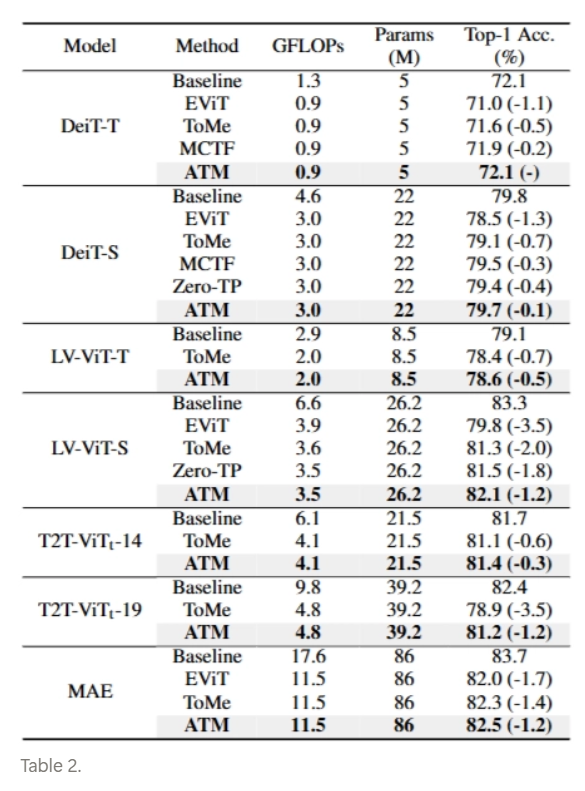
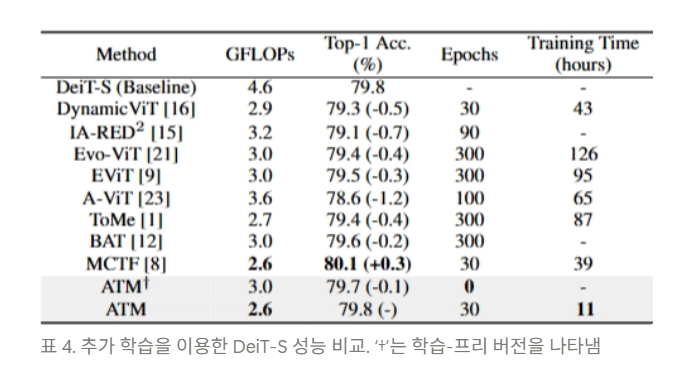
Performance Comparison with Extra Training
Conclusion
본 연구에서는 추가 학습 없이 손실 없는 중복 토큰 감소를 위해 설계된 새로운 방법인 ATM을 소개
- 개별 이미지의 특성에 적응하는 임계값 기반 병합 접근 방식을 활용 및 레이어 전반에 걸쳐 동적인 임계값 조정
- 크기 구별 토큰 매칭 전략 적용
- 배치 적응형 병합(batch-adaptive merging)을 지원
