논문 리뷰
1.[논문 리뷰] Teacher as a Lenient Expert: Teacher-Agnostic Data-Free Knowledge Distillation
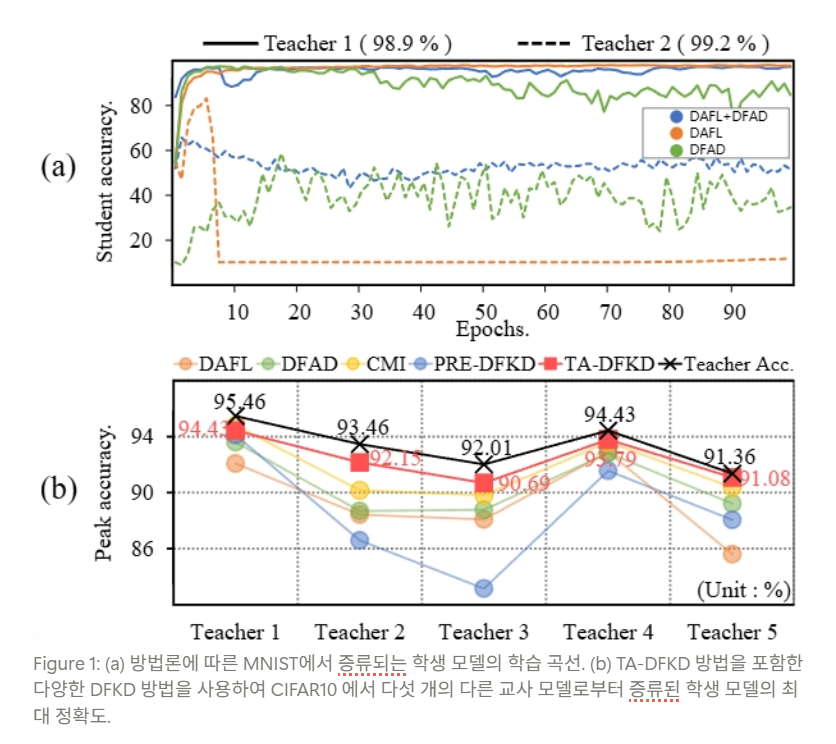
[논문 리뷰] Teacher as a Lenient Expert: Teacher-Agnostic Data-Free Knowledge Distillation
2026년 3월 5일
2.[논문 리뷰] Lossless Token Merging Even Without Fine-Tuning in Vision Transformers
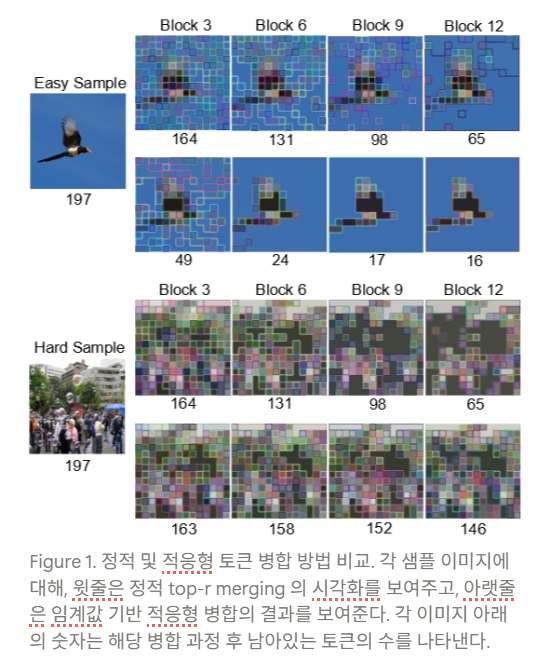
[논문 리뷰] Lossless Token Merging Even Without Fine-Tuning in Vision Transformers
2026년 3월 8일
3.[논문 리뷰]C-CLIP: MULTIMODAL CONTINUAL LEARNING FOR VISION-LANGUAGE MODEL
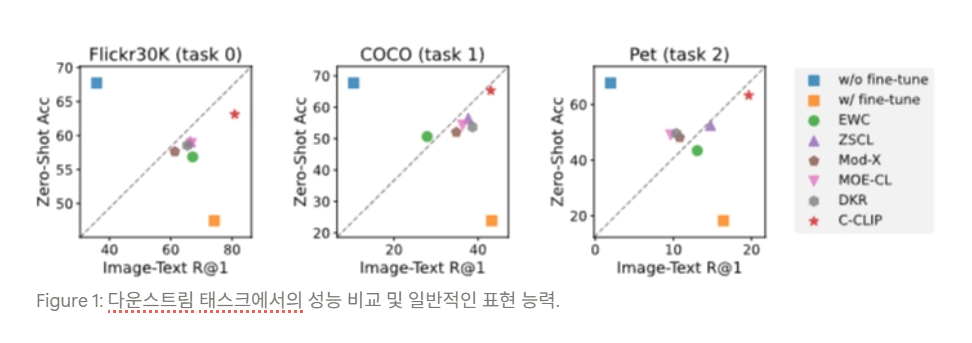
C-CLIP: MULTIMODAL CONTINUAL LEARNING FOR VISION-LANGUAGE MODEL 논문 리뷰
2026년 3월 17일
4.[논문 리뷰] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
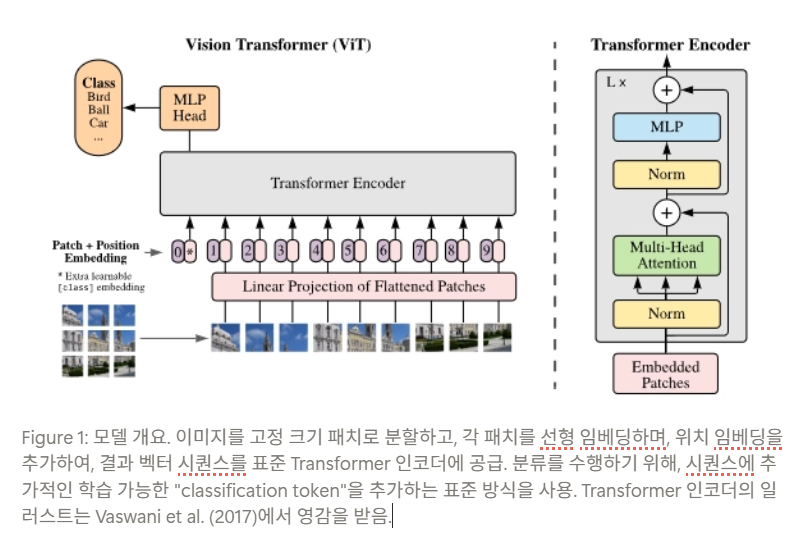
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문 리뷰
2026년 3월 17일
5.[논문 리뷰] Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
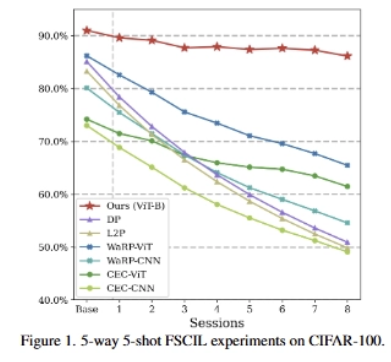
[논문 리뷰] Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
2026년 3월 29일