https://arxiv.org/pdf/2402.12406
Abstract
DFKD(Data-Free Knowledge Distillation)은 원본 데이터를 사용하지 않고 생성기(gengerator)의 도움을 받아 사전 학습된 지식을 학생 모델(student model)로 증류하는 것을 목표로 한다.
이러한 Data-free 시나리오에서는 검증 데이터를 사용할 수 없기에 DFKD의 안정적인 성능 달성이 필수적이다.
기존 DFKD 방법론들은 다양한 teacher 모델에 상당히 만감하고, 잘 훈련된 teacher 모델을 사용하더라도 때때로 치명적인 distillation 실패를 보인다.
또한, DFKD의 생성기가 class-prior(클래스 사전 확률), adversarial losses(적대적 손실)을 모두 최소화하는 전략(기존의 대표적인 전략)을 사용하여 항상 정확하면서도 다양한 샘플을 생성한다고 보장할 수는 없다.
- class-prior 의 문제점
- 생성된 샘플의 다양성을 감소시킴
- teacher 모델에 따라 예상치 못한 저품질 샘플을 생성
따라서 본 논문은 teacher 모델에 관계 없이 더 강력하고 안정적인 성능을 목표로 하는 TA-DFKD(Teacher-Agnosticism Data-Free Knowledge Distillation)을 제안한다.
- 아이디어
- 생성기를 제한하지 않는다
- 샘플을 평가할때 teacher 모델에 엄격한 감독자(supervisor)역할을 강요하는 대신, 관대한 전문가(Lenient expert)역할을 부여한다.
=> 다양한 샘플을 생성하는 능력에 제약을 가하지 않으면서, teacher 모델에 의해 검증된 깨끗한 샘플만을 선택하게 한다.
Introduction
- DKFD
- teacher모델을 학습하는 데 사용되는 데이터 샘플을 필요로 하는 기존 KD 방법론들의 한계를 극복하게 위해 등장
- 원본 데이터 샘플을 사용하지 않고 생성기의 도움을 통해 사전 학습된 지식을 증류하는 것을 목표로 함
- Generator
- teacher 모델을 기반으로 학습되어 증류 과정에서 원본 샘플의 대체물인 합성 샘플을 생성
=> distillation 효과를 정확하게 평가하는 것을 불가능 하게 만드는 검증 데이터의 부재는 DFKD의 주요 Challenge
- teacher 모델을 기반으로 학습되어 증류 과정에서 원본 샘플의 대체물인 합성 샘플을 생성
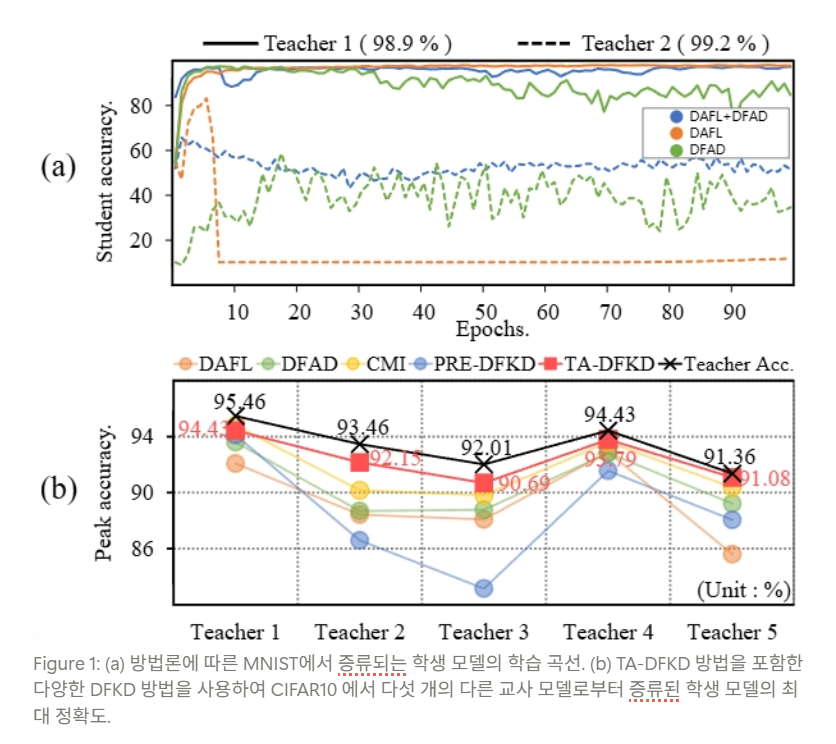
같은 Teacher 모델을 사용했음에도 distillation이 실패하는 이유
-
실제 데이터 매니폴드 밖에서의 결정 경계(Decision Boundary) 불일치
- 성능이 95%로 동일한 여러 Teacher 모델들은 실제 데이터 이 입력되었을 때 올바른 정답을 출력하도록 최적화되어 있음
- DFKD의 생성자는 처음에 의미 없는 랜덤 노이즈 에서 출발하여 가짜 데이터 를 합성
- 이 노이즈 공간은 Teacher 모델이 한 번도 학습한 적 없는 데이터 분포 밖(Out-of-Distribution)의 빈 영역
- 동일한 성능의 모델이라도, 이 '빈 공간'에 형성된 결정 경계는 가중치 초기화나 학습 순서에 따라 모델마다 완전히 무작위하고 다르게 형성되어 있음
-
적대적 함정(Adversarial Trap)과 Mode Collapse 발생
- 기존 방법론(DAFL 등)은 생성자에게 "모든 클래스에 대해 Teacher 가 100% 확신하는 이미지를 균등하게 만들어라"라고 엄격한 손실 함수(Strict supervision)를 강제
- 생성자는 복잡하고 정교한 실제 이미지를 모방하는 대신, 손실 함수를 가장 빠르게 최소화할 수 있는 지름길을 찾는다. 즉, 특정 Teacher 모델의 빈 공간 결정 경계 중 가장 왜곡된 부분을 파고들어, 사람 눈에는 단순한 노이즈 픽셀이지만 Teacher 만 특정 클래스로 강하게 착각하는 적대적 샘플(Adversarial Example)을 만들어 냄
- 생성자는 해당 Teacher 를 가장 쉽게 속일 수 있는 몇 가지 노이즈 패턴만을 찾아내어 똑같은 쓰레기 이미지만 반복적으로 생성하게 됨. 이것이 생성 모델의 전형적인 Mode Collapse.
-
Student 모델의 성능 폭락 (Catastrophic Failure)
- 결과적으로 생성자가 합성한 데이터는 해당 Teacher 모델 고유의 '버그(결함)' 집합체가 됨.
- Student 모델은 이 비정상적인 데이터를 입력받아 Teacher 의 예측값을 모방하도록 학습.
- 결국 Student 는 실제 유의미한 시각적 특징(Feature)이 아닌 특정 Teacher 의 취약점 구조만을 학습하게 되므로, 정작 실제 평가 데이터 세트가 입력되면 전혀 예측을 수행하지 못하고 성능이 폭락하게 됨
⇒ 빈 공간의 결정 경계가 우연히 완만한 Teacher 모델을 만나면 생성자가 비교적 정상적인 이미지를 합성하여 성능이 유지되지만, 결정 경계가 뾰족하고 복잡한 Teacher 모델을 만나면 즉시 Mode Collapse 에 빠져 전체 학습이 망가지게 됨. 이것이 Teacher 모델 간에 극심한 성능 편차가 발생하는 근본 원인
따라서 DFKD 방법은 어떤 teacher 모델이 증류되든 안정적이고 강력한성능을 보장하는 것이 중요
⇒ 이를 위해 최신(SOTA) DFKD 방법들은 생성기의 손실함수로 class prior, adversarial, representation loss를 사용
- class prior
- DAFL(Chen et al. 2019)에서 처음 소개
- Teacher 모델이 특정 클래스로 분류할 수 있는 정확한 샘플을 생성하는것이 목표
- adversarial
- DFAD(Fang et al. 2019), ZSKT(Micaelli and Storkey 2019)에서 제안
- Teacher와 Student모델 간의 출력 불일치를 최대화하는 어려운 샘플을 생성하여 생성된 샘플의 다양성을 향상시키는 것이 목표
- representation loss
- 교사 모델에 대해 실제 데이터의 특징 수준 정보를 학습하는게 목표
기존의 DFKD 방법들은 서로 다른 교사 모델에 매우 민감.
잘 학습된 고성능 teacher 모델을 사용하더라도 치명적인 증류 실패를 일으킬 수 있음
Teacher2의 정확도가 Teacher1 의 정확도 보다 높음에도 불구하고, DAFL, DFAD 모두 Teacher 2의 지식을 증류하는데 실패
DAFL + DFAD 와 같은 혼합 접근 방식도 성공적인 해결책이 아닐 수 있음
Teacher 1, Teacher2 간에 훈련 전략 또한 차이가 없음
원인
- generator 때문
DAFL(class-prior loss)
- class-prior는 샘플 품질을 개선하기 위한 것
- 하지만 생성기가 쉬운 샘플에만 집중하도록 유도하는 경향이 있음
- 극단적인 경우, 모든 샘플을 특정 클래스로 잘못 분류(그림 a 참고)
DAFD(adversarial loss)
- 더 어려운 샘플을 생성하는데 효과적
- 다양할 수도 있지만, 어떤 클래스와도 관련이 없는 비현실적인 샘플이 생성될 수도 있음
DAFL + DAFD
- 합성 샘플의 높은 품질과 다양성을 모두 달성하기 위해 두 기법을 결합
- 정확성을 위한 손실과 다양성을 위한 손실 사이의 최적점을 보장받지 못함
본 논문에서는 class-prior의 필요성을 재검토
샘플의 품질을 향상시키기 위한 class-prior이 없이 훈련될 때 더 다양한 샘플을 자유롭게 생성 가능
심지어 aversarial loss없이 class-prior loss 만 사용했을시에도 생성기가 저품질 샘플을 생성하는 것을 발견
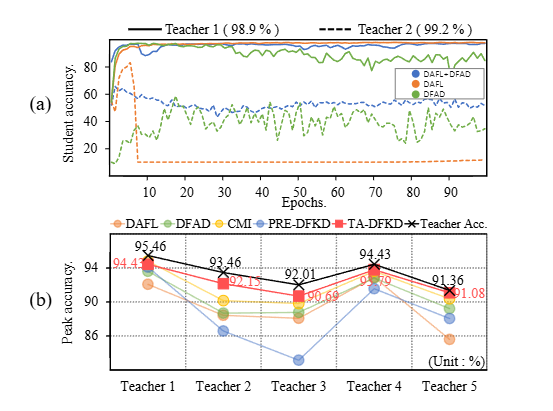
⇒ teacher 모델에 유연한 전문가 역할을 부여하여하는 TA-DFKD를 제안
- 생성기가 더 넓은 샘플 공간을 탐색하여 더 높은 다양성을 제공할 수 있도록 class-prior제거
- 합성 샘플의 높은 정확성을 위해 teacher모델을 전문가로 활용하여 합성 샘플의 품질을 평가, 예상치 못한 저품질 샘플 폐기
노이즈 레이블로부터 학습하는 기존 연구들(Song et al. 2020)에서 영감을 받아,
Gaussian Mixture Model을 사용하여 teacher 모델에 의해 충분히 정확하다고 확인된 레이블을 가진 생성된 샘플만을 선택하는 샘플 선택 방법을 설계
Gaussian Mixture Model 이란?
1 . 노이즈 레이블 학습 ( Learning from Noisy Labels , LNL ) 의 배경
- 딥러닝 모델은 데이터의 패턴을 매우 잘 학습하지만 , 동시에 잘못된 라벨 ( Noise ) 까지도 암기 ( Memorization ) 해버리는 특성이 있음 기존 연구들은 모델이 학습 초기에는 깨끗한 데이터를 먼저 학습하고 , 나중에 노이즈를 학습한다는 ' Small-loss Trick ' 에 주목
- Small-loss Trick : 학습 초기 , 손실 값 ( Loss ) 이 낮은 샘플은 정확한 라벨을 가질 확률이 높고 , 손실 값이 높은 샘플은 노이즈일 확률이 높다는 가설
2 . Gaussian Mixture Model ( GMM ) 을 이용한 샘플 선택
- Song et al. ( 2020 ) 이 정리한 방법론 중 핵심은 , 모델이 계산한 각 샘플의 손실 값을 바탕으로 ' 깨끗한 샘플 ' 과 ' 노이즈 샘플 ' 을 통계적으로 분리하는 것 .
여기서 GMM 이 사용 됨
- 작동 원리
-
손실 값 수집 : 데이터셋의 모든 샘플에 대해 현재 모델의 손실 값 Loss 를 계산
-
이봉 분포 ( Bimodal Distribution ) 가정 : 손실 값의 분포가 두 개의 가우시안 분포 ( 깨끗한 샘플의 낮은 손실 분포 + 노이즈 샘플의 높은 손실 분포 ) 로 이루어져 있다고 가정
-
GMM Fitting : 전체 손실 값 분포에 대해 2 개의 컴포넌트를 가진 GMM 을 학습시킴
-
확률적 선택 : 특정 샘플의 손실 값이 ' 낮은 손실 분포 ( Clean Component ) ' 에 속할 후험 확률 ( Posterior Probability ) 을 계산.
이 확률이 일정 임계치 이상인 샘플만을 ' 충분히 정확한 레이블 ' 로 판단하여 학습에 사용
-
3 . 문맥에서의 의미 해석
- Teacher 모델 활용 : 기존 연구에서는 학습 중인 모델 자신의 손실 값을 사용했다면 , 여기서는 Teacher 모델 이 생성된 샘플에 대해 부여한 점수나 손실 값을 기준으로 삼음
- 생성된 샘플 선택 : 생성기 ( Generator ) 가 만든 데이터 중 , Teacher 모델 이 보기에 레이블과 내용이 일치한다고 판단되는 ( 즉 , 손실이 낮거나 신뢰도가 높은 ) 샘플만을 GMM 으로 걸러내어 학습 데이터로 정제
Related Works
- 무작위 노이즈 이미지를 직접 최적화 (Nayak et al. 2019)
- 사전 훈련된 모델에서 추출한 생성기를 사용하는 것 (Yoo et al. 2019, Chen et al. 2019)
-
DAFL (Chen et al. 2019)
- class-prior loss 를 사용하여 teacher model에 의해 잘 예측될 만큼 정확한 샘플을 생성하도록 강제
- feature map의 활성화 값(activation values)을 최대화하는 것을 목표로 하는 activation이라고 불리는 representation loss를 제안
-
ADI (Yin et al. 2020)
- BNS라고 불리는 또다른 representation loss는 teacher 모델에 저장된 batch normalization 계층의 통계랑을 제약
-
DFAD(Fang et al. 2019)와 ZSKT(Micaelli and Storkey 2019)
- GAN 모델에서 영감을 받아 adversarial loss를 채택
- teacher 와 student 간의 불일치를 최대화하는 어려운 샘플을 생성하는 것이 목표
- 다양한 지식 학습을 가능하게 해주지만, teacher의 범주에 속하지 않는 비현실적인 샘플을 생성할 수 도 있음
-
CuDFKD(Li et al. 2023)와 AdaDFQ(Qian et al. 2023)
- student 모델이 teacher 모델의 지식을 점진적으로 학습할 수 있도록 적응형 학습을 제안
-
ABD(Hong et al. 2023)
- 신뢰할 수 없는 교사 모델 시나리오를 다룸
-
MB/PRE-DFKD(Binici et al. 2022
- 적대적 학습으로 인해 학생 모델에서 발생하는 바람직하지 않은 망각에 주목
- 메모리 뱅크 또는 추가 생성 모델의 사용을 제안
-
MAD(Do et al. 2022)
- 생성자 업데이트를 위해 지수 이동 평균(exponential moving average)을 사용하는 것을 제안
-
META-DFKD(Patel, Mopuri, and Qiu 2023)
- 메타 학습(meta-learning)을 생성자 학습 과정에 통합
Learning from Noisy Labels
인기 있는 벤치마크 데이터셋은 DNN에서 올바른 label을 가정하지만, 실제 데이터 labeling은 noise label을 초래 할 수 있음
- learning from noisy labels (LNL) (Song et al. 2020),
- DNN이 노이즈 라벨이 있는 데이터에 과적합되는 것을 방지
- 대표적으로 깨끗한 샘플과 노이즈 레이블이 있는 샘플 간의 차이를 모델링하여 깨끗한 샘플을 식별하는 샘플 선택
- 더 간단하게는 작은 loss를 갖는 샘플을 선택
- using a pretrained model (Jiang et al. 2018) and training dual models (Malach and ShalevShwartz 2017; Hanet al. 2018; Yu et al. 2019; Li, Socher, and Hoi 2020
- pretrained 모델을 사용하거나 dual 모델을 학습시켜 깨끗한 샘플에 대해 더 나은 결정을 내림
본 논문에서는 DivideMix(Li, Socher, and Hoi 2020)에서 소개된 가우시안 혼합 모델(Gaussian Mixture Model)을 사용
논문의 목표가 사전 학습된 교사 모델에 대한 고품질 샘플 선택이기 때문
Methodology
Framework of Generator-Based DFKD
표준 생성자 기반 DFKD 프레임워크에서는 3가지 네트워크를 고려
= 사전학습된 교사모델
= 학생 모델
= 생성자
DFKD의 궁긍적인 목표는 일반 KD와 동일
단, 실제데이터 대신 생성자를 사용하여 임의의 벡터 로 부터 가짜 샘플 을 생성하고, 이 합성 샘플을 와 에 공급하여 증류 손실을 최소화 함
증류 손실
여기서 는 두 모델 출력 간의 거리
는 보통 가우시안 분포인
를 학습하기 위한 효과적인 손실 함수
= Class prior loss
= Adversarial loss
= Represenation loss
⇒ class prior로 teacher model과 fit한 데이터를 생성하면서, 가장 적대적인 데이터를 생성해 다양성을 확보하면서, 생성된 이미지의 내부 특징(Feature)이 실제 데이터의 통계치와 유사하게 해라
DFKD의 최종목표는 와 과 같은 목적함수를 통해 와 를 동시에 학습하는 것
Revisiting Class-Prior in DFKD
= 분포 에서 샘플링한 노이즈 를 생성자 에 넣어서 나온 데이터 를 Teacher모델(frozen) 에 넣어 확률값을 구하고, 가 의도한 정답인 와 cross-entropy로 구한 손실의 평균값
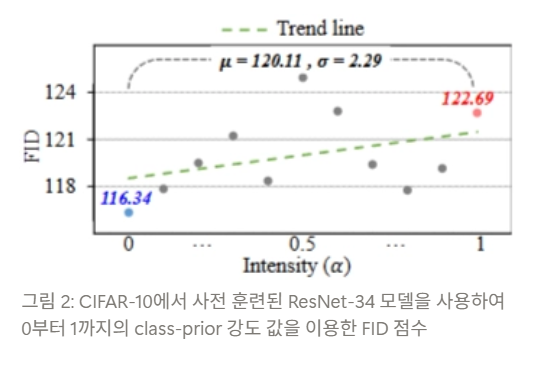
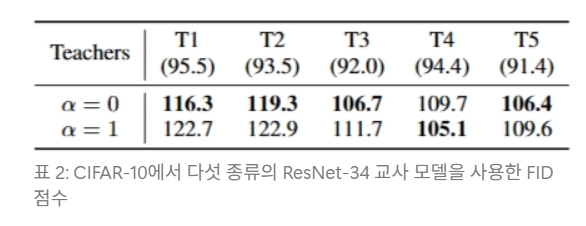
- FID 란?
- Frechet Inception Distance (FID) 점수
- 생성된 이미지의 품질과 다양성을 측정하는 지표
- FID 점수가 낮을수록 생성된 샘플이 더 다양하고 현실적
- 이 그림에서 class-prior의 손실의 강도가 강해질수록 FID 점수가 높아지는 경향이 있음 ⇒ class-prior가 생성된 샘플의 다양성을 감소시킴

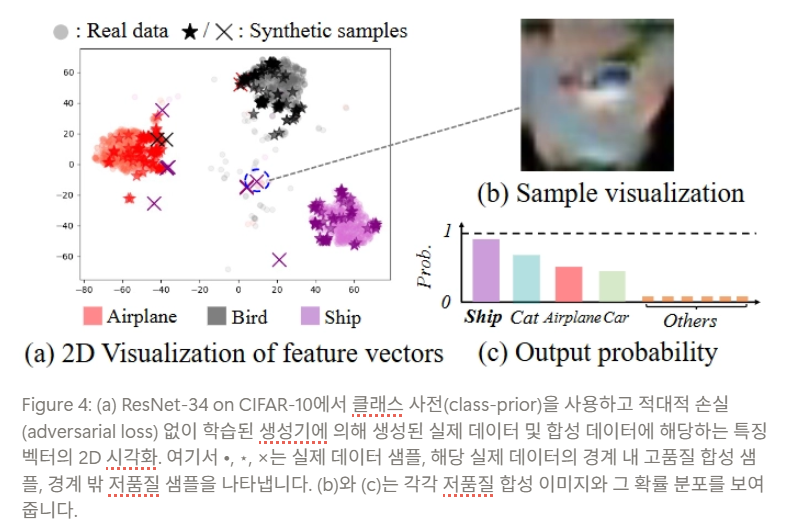
- Lower Sample Diversity
- Incomplete Quality Control
Proposed Method
- 제거
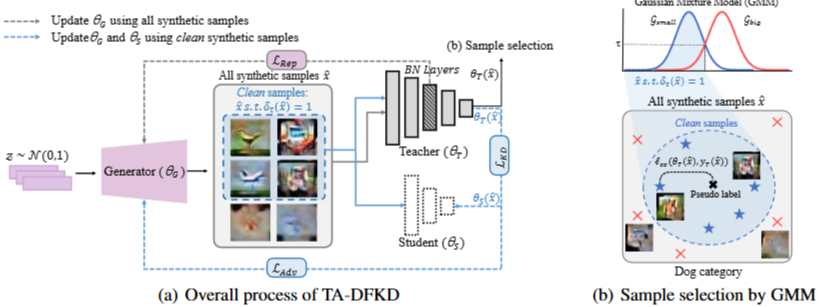
를 최소화하는 것은 를 사용한 teacher과 student 모델 출력 간의 불일치를 최대화 하는 것
⇒ generator가 더 어려운 샘플을 생성하도록 유도
⇒ 가짜 이미지 가 실제 데이터의 통계 를 따르면서도 , 적절한 변화량 을 갖고 , 비정상적으로 튀는 값 이 없도록 하라
⇒ 생성된 이미지 을 교사 모델에 통과시켰을 때 얻어지는 모든 레이어의 평균과 분산 값이 , 교사 모델이 기존에 학습하며 저장해둔 실제 데이터의 평균 및 분산 값과 얼마나 다른지 계산하여 합산
⇒ 교사 모델 ( Teacher ) 이 실제 데이터를 보았을 때 나타내는 높은 확신도 ( Confidence ) 를 생성기 ( Generator ) 가 만든 가짜 데이터에 대해서도 동일하게 출력하도록 강제하는 것
⇒ 교사 모델이 충분히 확신하는 ( 손실이 작은 ) 이미지일 확률이 기준치 보다 높으면 1 ( 합격 ) , 아니면 0 ( 불합격 ) 처리
- s.t. = 영어 such that 의 약어, 수학이나 집합 기호에서 " ~ 라는 조건을 만족하는 " 또는 " ~ 라는 조건하에 " 라는 뜻으로 사용
- : 최종적으로 선택된 이미지 샘플 들의 집합
⇒ 분포에서 샘플링된 노이즈 로부터 생성된 이미지들 중, 품질 검사 에서 합격 점수를 받은 샘플들만 모아놓은 부분 집합
본 실험에서는 를 0.5로 설정
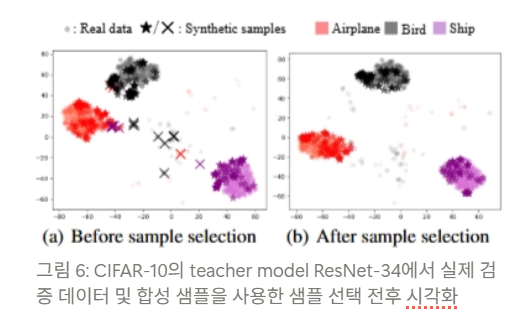
그림 6: CIFAR-10의 teacher model ResNet-34에서 실제 검증 데이터 및 합성 샘플을 사용한 샘플 선택 전후 시각화
생성자 학습 loss
최종 KD loss
Experiments
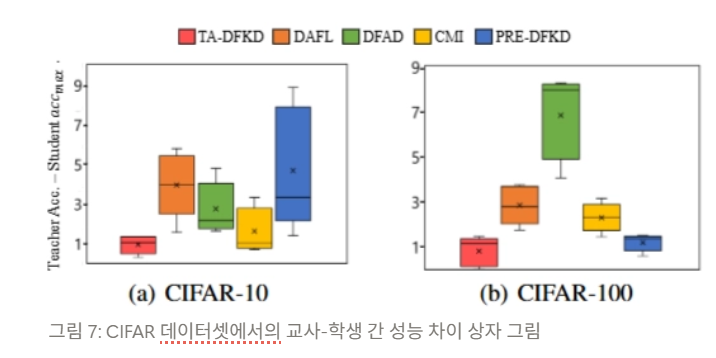
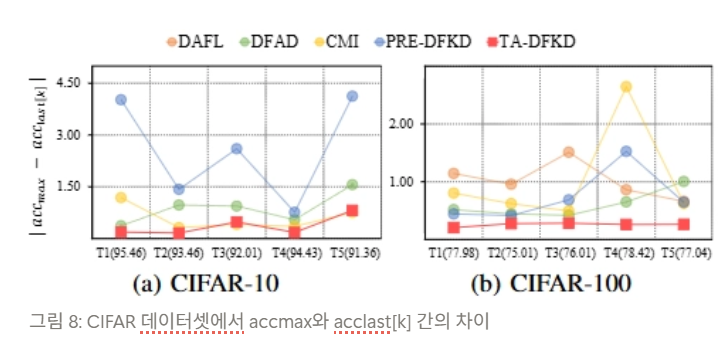
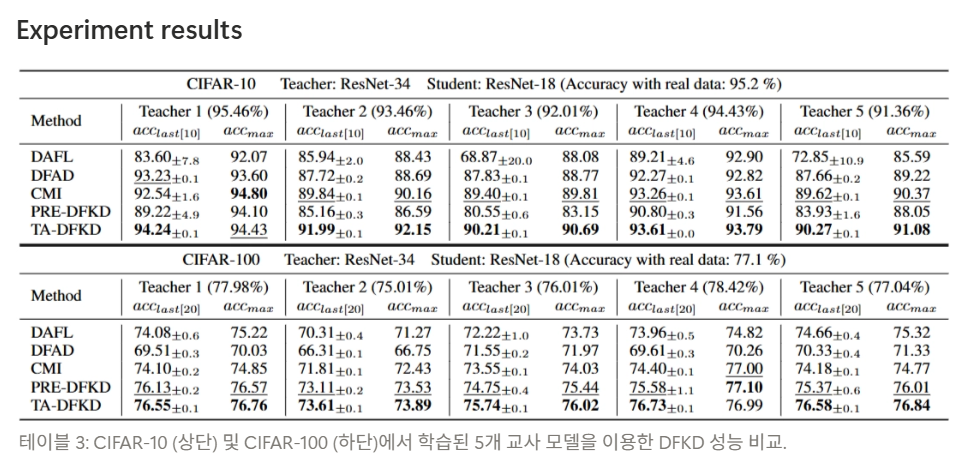
Experiment results
Ablation study
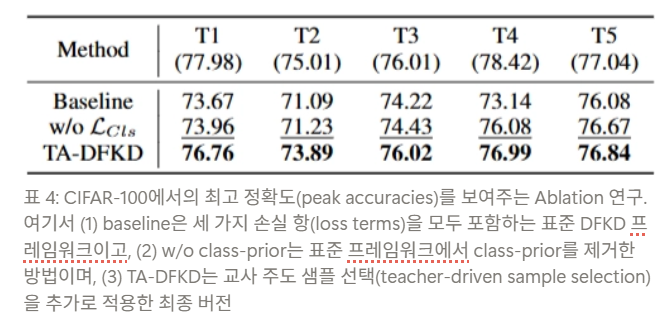
결과는 논문의 두 가지 주장을 명확하게 확인시켜 줌
- class-prior는 제거하는 것이 더 좋지만,
- 샘플 선택 방법으로 샘플 품질을 제어하지 않고 class-prior를 제거하는 것만으로는 성능을 더 향상시키기에 충분하지 않음
Conclusion
- 본 논문은 DFKD 방법론에서 일반적으로 채택되는 세 가지 손실 항에 초점을 맞춰 Teacher-Agnostic DFKD에 대한 최초의 연구를 수행
- 본 논문의 연구 결과는 class-prior 제약을 샘플 선택 방식으로 대체함으로써 향샹된 품질 제어를 달성할 수 있음을 강력하게 시사
- 실험에서 TA-DFKD는 다양한 teacher model에 걸쳐 주목할 만한 robustness와 stability를 입증
- 본 연구가 사전 데이터 샘플에 접근할 수 없는 지식 증류 시나리오에 대한 실용적인 해결책을 제공하며, teacher-agnostic DFKD문제의 시작을 알리고 해당 분야의 추가 연구를 위한 유망한 방향을 제시하기를 희망
