1. 초기화
=> Xievier initialization
=> He's initialization

2. Vanishing Greadient
=> ReLu

3. Overfitting
=> dropout
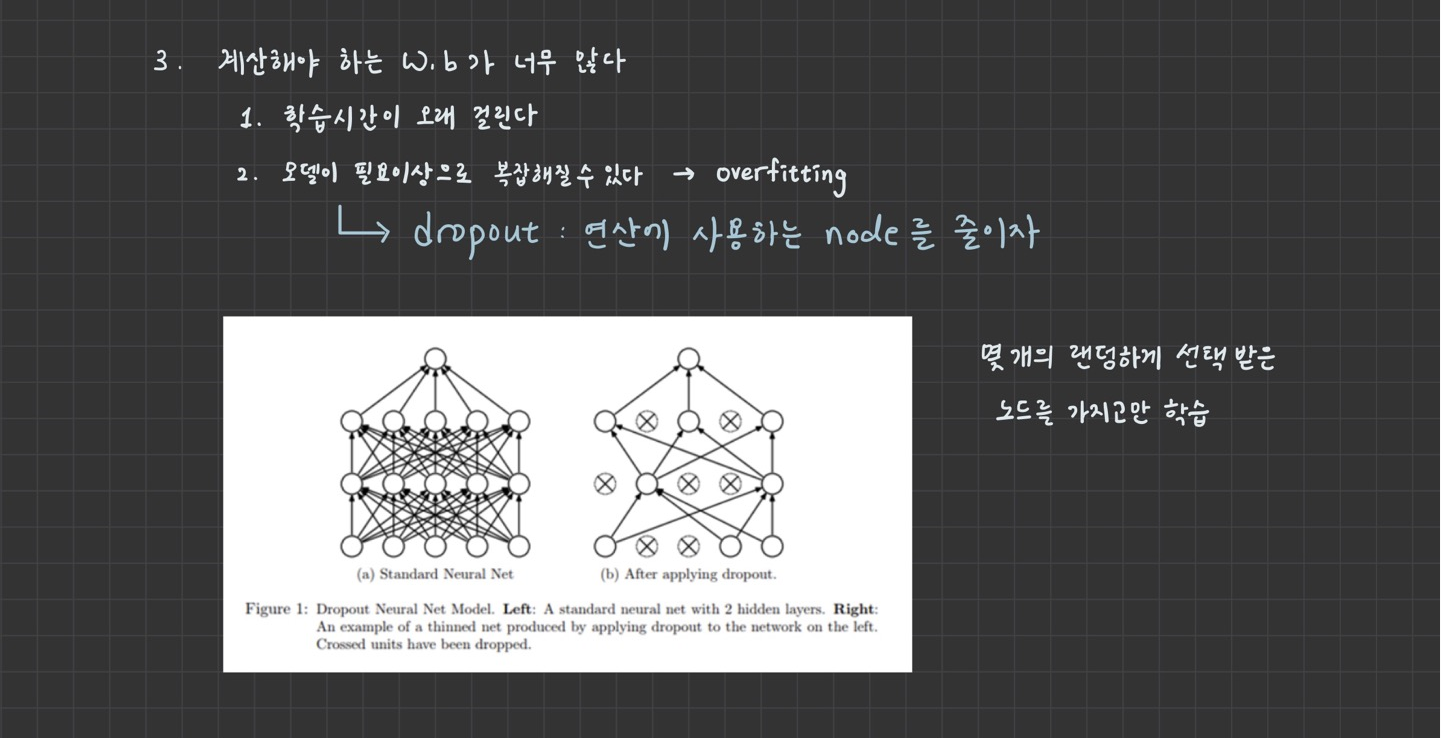
구현
데이터 전처리
MNIST
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
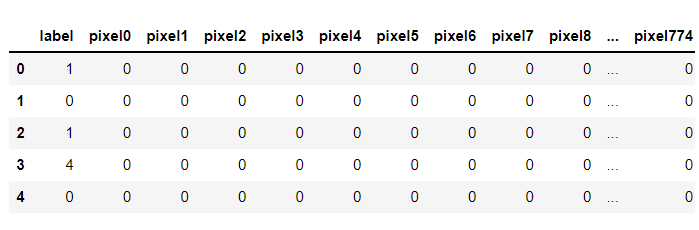
df = pd.read_csv('../data/mnist/train.csv')
display(df.head())
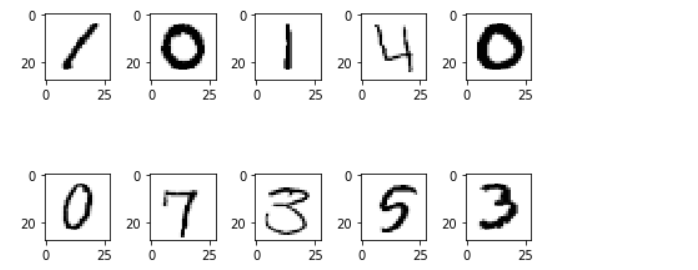
img_data = df.drop('label', axis=1, inplace=False).values
figure = plt.figure()
ax_arr = []
for n in range(10):
ax_arr.append(figure.add_subplot(2,5,n+1))
ax_arr[n].imshow(img_data[n].reshape(28,28),
cmap='Greys',
interpolation='nearest')
plt.tight_layout()
plt.show()
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3,
random_state=1,
stratify=df['label'])
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
sess = tf.Session()
onehot_train_t_data = sess.run(tf.one_hot(train_t_data, depth=10))
onehot_test_t_data = sess.run(tf.one_hot(test_t_data, depth=10))
1. Multinomial Classification
모델 생성 및 학습
Deep Learning과 비교하기 위함
X = tf.placeholder(shape=[None,784], dtype=tf.float32)
T = tf.placeholder(shape=[None,10], dtype=tf.float32)
W = tf.Variable(tf.random.normal([784,10]))
b = tf.Variable(tf.random.normal([10]))
logit = tf.matmul(X,W) + b
H = tf.nn.softmax(logit)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logit,
labels=T))
train = tf.train.GradientDescentOptimizer(learning_rate=1e-1).minimize(loss)
sess.run(tf.global_variables_initializer())
for step in range(5000):
tmp, loss_val = sess.run([train, loss],
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
if step % 500 == 0:
print('loss 값 : {}'.format(loss_val))

성능평가
tf.argmax() : 최대값의 index
tf.equal() : 비교 (true, false로 나옴)
tf.cast() : 새로운 자료형으로 변환
predict = tf.argmax(H,1)
correct = tf.equal(predict, tf.argmax(T,1))
accuracy = tf.reduce_mean(tf.cast(correct, dtype=tf.float32))
train_result = sess.run(accuracy,
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
print('train data 정확도 : {}'.format(train_result))
result = sess.run(accuracy,
feed_dict={X:norm_test_x_data,
T:onehot_test_t_data})
print('test data 정확도 : {}'.format(result))
=> underfitting
2. Neural Network으로 Multinomial Classification
모델 생성 및 학습
Weight 초기화, activation 변경, dropout 제외
hidden layer 추가
X = tf.placeholder(shape=[None,784], dtype=tf.float32)
T = tf.placeholder(shape=[None,10], dtype=tf.float32)
W2 = tf.Variable(tf.random.normal([784,256]))
b2 = tf.Variable(tf.random.normal([256]))
layer2 = tf.sigmoid(tf.matmul(X,W2) + b2)
W3 = tf.Variable(tf.random.normal([256,128]))
b3 = tf.Variable(tf.random.normal([128]))
layer3 = tf.sigmoid(tf.matmul(layer2,W3) + b3)
W4 = tf.Variable(tf.random.normal([128,10]))
b4 = tf.Variable(tf.random.normal([10]))
logit = tf.matmul(layer3,W4) + b4
H = tf.nn.softmax(logit)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logit,
labels=T))
train = tf.train.GradientDescentOptimizer(learning_rate=1e-1).minimize(loss)
sess.run(tf.global_variables_initializer())
for step in range(1000):
tmp, loss_val = sess.run([train, loss],
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
if step % 100 == 0:
print('loss 값 : {}'.format(loss_val))

성능평가
predict = tf.argmax(H,1)
correct = tf.equal(predict, tf.argmax(T,1))
accuracy = tf.reduce_mean(tf.cast(correct, dtype=tf.float32))
train_result = sess.run(accuracy,
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
print('train data 정확도 : {}'.format(train_result))
result = sess.run(accuracy,
feed_dict={X:norm_test_x_data,
T:onehot_test_t_data})
print('test data 정확도 : {}'.format(result))
3. Deep Learning으로 Multinomial Classification
모델 생성 및 학습
Weight 초기화 => Xavier
activation 변경 => ReLu
dropout
X = tf.placeholder(shape=[None,784], dtype=tf.float32)
T = tf.placeholder(shape=[None,10], dtype=tf.float32)
W2 = tf.get_variable('W2', shape=[784,256],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random.normal([256]))
_layer2 = tf.nn.relu(tf.matmul(X,W2) + b2)
layer2 = tf.nn.dropout(_layer2, rate=0.3)
W3 = tf.get_variable('W3', shape=[256,128],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random.normal([128]))
_layer3 = tf.nn.relu(tf.matmul(layer2,W3) + b3)
layer3 = tf.nn.dropout(_layer3, rate=0.3)
W4 = tf.get_variable('W4', shape=[128,10],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random.normal([10]))
logit = tf.matmul(layer3,W4) + b4
H = tf.nn.softmax(logit)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logit,
labels=T))
train = tf.train.GradientDescentOptimizer(learning_rate=1e-1).minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(5000):
tmp, loss_val = sess.run([train, loss],
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
if step % 500 == 0:
print('loss 값: {}'.format(loss_val))

성능평가
predict = tf.argmax(H,1)
correct = tf.equal(predict, tf.argmax(T,1))
accuracy = tf.reduce_mean(tf.cast(correct, dtype=tf.float32))
train_result = sess.run(accuracy,
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
print('train data 정확도 : {}'.format(train_result))
result = sess.run(accuracy,
feed_dict={X:norm_test_x_data,
T:onehot_test_t_data})
print('test data 정확도 : {}'.format(result))
train data 정확도
일반 multinomial (5000epoch) : 0.8786394596099854
neural network (1000epoch) : 0.7911564707756042
deep learning (1000epoch) :
deep learning (5000epoch) : 0.9740476012229919
test data 정확도
# 일반 multinomial (5000epoch) : 0.8709523677825928
# neural network (1000epoch) : 0.7667460441589355
# deep learning (1000epoch) :
# deep learning (5000epoch) : 0.9535714387893677

