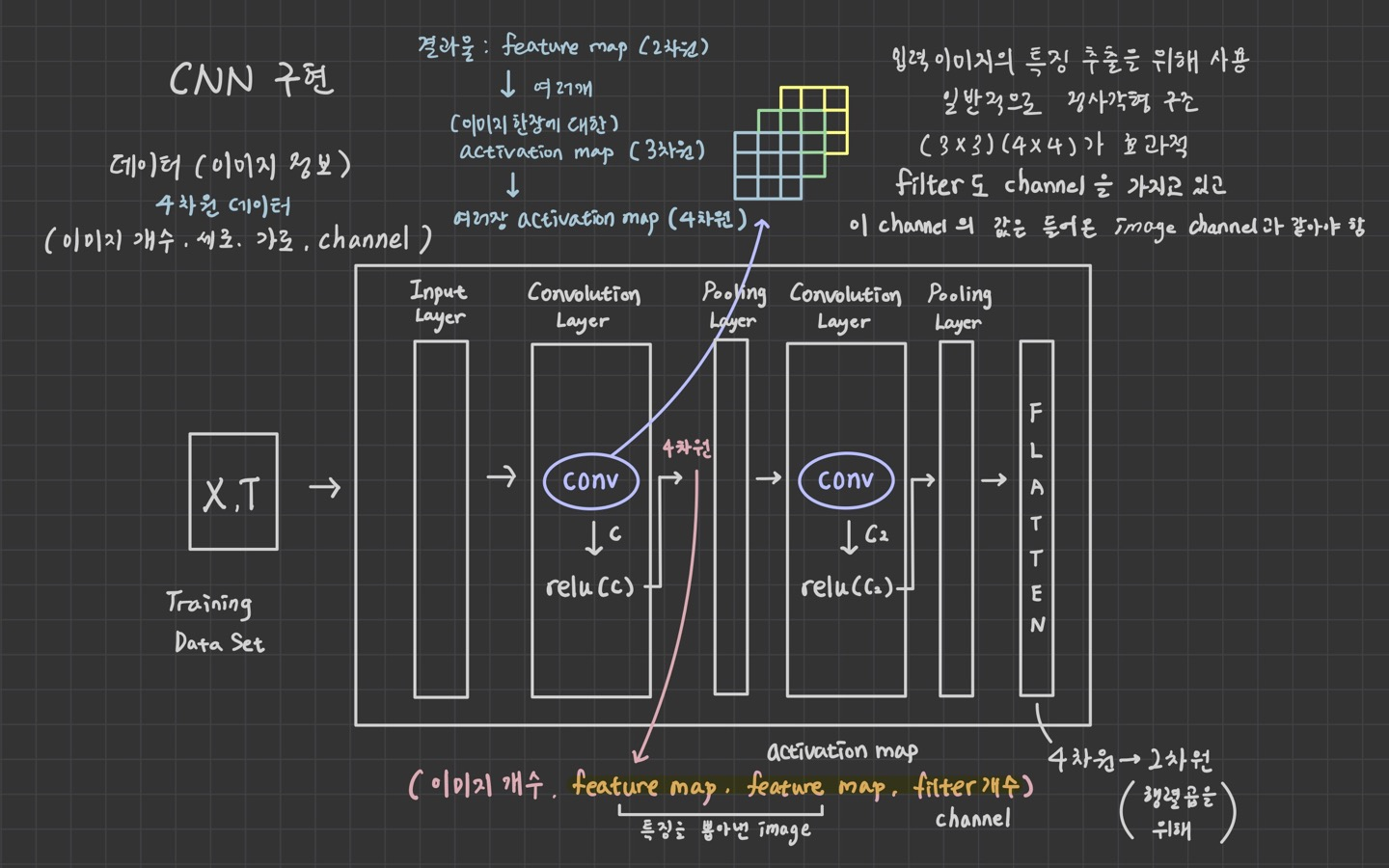
1. channel이 3인 입력 데이터를 convolution 연산
import numpy as np
import tensorflow as tf
image = np.array([[[[1, 2, 3],
[1, 2, 3],
[1, 2, 3]],
[[1, 2, 3],
[1, 2, 3],
[1, 2, 3]],
[[1, 2, 3],
[1, 2, 3],
[1, 2, 3]]]], dtype=np.float64)
print(image.shape)
weight = np.array([[[[1,2],
[1,2],
[1,2]],
[[1,2],
[1,2],
[1,2]]],
[[[1,2],
[1,2],
[1,2]],
[[1,2],
[1,2],
[1,2]]]], dtype=np.float64)
print(weight.shape)
conv2d = tf.nn.conv2d(image,
weight,
strides=[1,1,1,1],
padding='VALID')
sess = tf.Session()
result=sess.run(conv2d)
print(result)

2. channel이 3인 이미지 데이터를 convolution 연산
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
figure = plt.figure()
ax1 = figure.add_subplot(1,3,1)
ax2 = figure.add_subplot(1,3,2)
ax3 = figure.add_subplot(1,3,3)
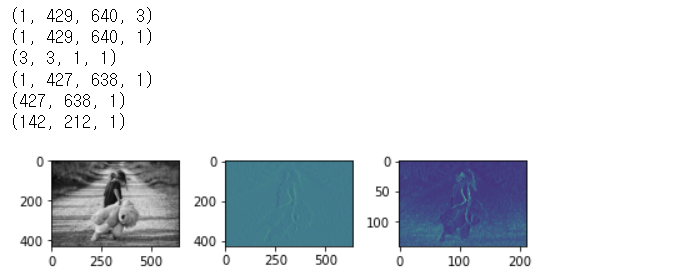
ori_image = img.imread('../images/girl-teddy.jpg')
ax1.imshow(ori_image)
input_image = ori_image.reshape((1,) + ori_image.shape)
print(input_image.shape)
input_image = input_image.astype(np.float32)
channel_1_input_image = input_image[:,:,:,0:1]
print(channel_1_input_image.shape)
weight = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
print(weight.shape)
conv2d = tf.nn.conv2d(channel_1_input_image,
weight,
strides=[1,1,1,1],
padding='VALID')
sess = tf.Session()
result = sess.run(conv2d)
print(result.shape)
t_img = result[0,:,:,:]
print(t_img.shape)
ax2.imshow(t_img)
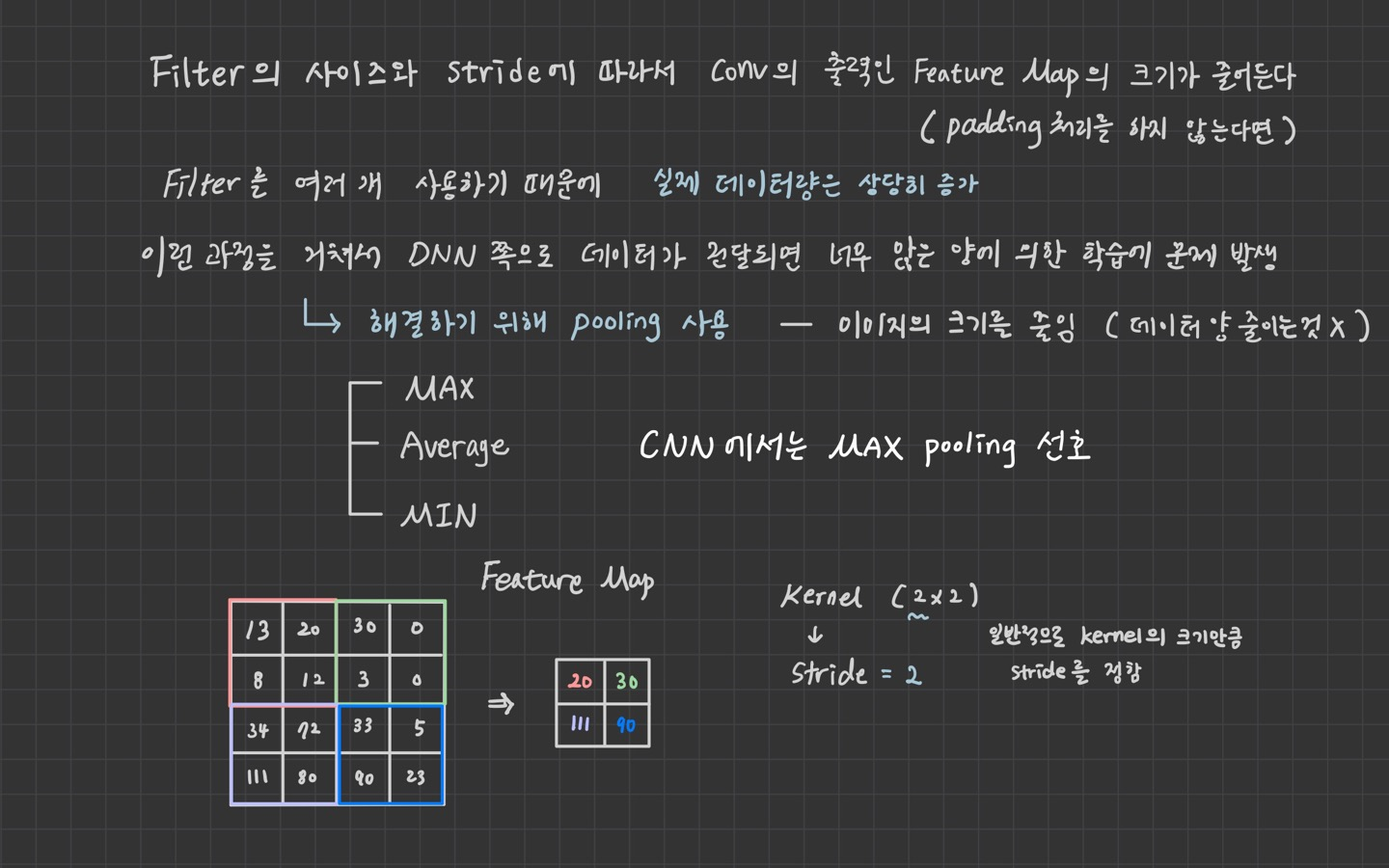
pooling_result = tf.nn.max_pool(result,
ksize=[1,3,3,1],
strides=[1,3,3,1],
padding='VALID')
pool_img = sess.run(pooling_result)
pool_img = pool_img[0,:,:,:]
print(pool_img.shape)
ax3.imshow(pool_img)
plt.tight_layout()
plt.show()
3. MNIST 예제로 convolution 연산과 pooling 작업
%reset
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
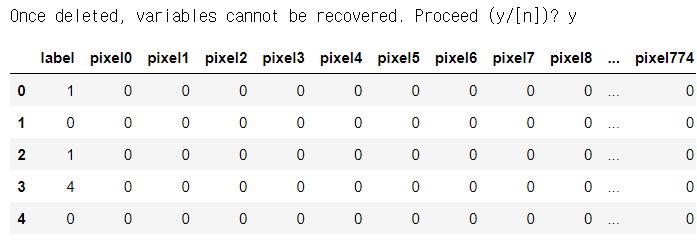
df = pd.read_csv('../data/mnist/train.csv')
display(df.head())
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
tf.reset_default_graph()
df = pd.read_csv('../data/mnist/train.csv')
train_x_data , test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3,
random_state=1,
stratify=df['label'])
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
sess = tf.Session()
onehot_train_t_data = sess.run(tf.one_hot(train_t_data, depth=10))
onehot_test_t_data = sess.run(tf.one_hot(test_t_data, depth=10))
X = tf.placeholder(shape=[None,784], dtype=tf.float32)
T = tf.placeholder(shape=[None,10], dtype=tf.float32)
x_img = tf.reshape(X, [-1,28,28,1])
W2 = tf.Variable(tf.random.normal([3,3,1,32]))
L1 = tf.nn.conv2d(x_img, W2, strides=[1,1,1,1], padding='SAME')
L1 = tf.nn.relu(L1)
print('L1의 결과 데이터 shape : {}'.format(L1.shape))
L1 = tf.nn.max_pool(L1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
print('L1의 pooling 결과 데이터 shape : {}'.format(L1.shape))
W3 = tf.Variable(tf.random.normal([3,3,32,64]))
L2 = tf.nn.conv2d(L1, W3, strides=[1,1,1,1], padding='SAME')
L2 = tf.nn.relu(L2)
print('L1의 결과 데이터 shape : {}'.format(L2.shape))
L2 = tf.nn.max_pool(L2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
print('L2의 pooling 결과 데이터 shape : {}'.format(L2.shape))
L2 = tf.reshape(L2, [-1,7*7*64])
W4 = tf.get_variable('W4', shape=[7*7*64, 256],
initializer=tf.contrib.layers.variance_scaling_initializer())
b4 = tf.Variable(tf.random.normal([256]))
_layer3 = tf.matmul(L2, W4) + b4
layer3 = tf.nn.relu(_layer3)
layer3 = tf.nn.dropout(layer3, rate=0.3)
W5 = tf.get_variable('W5', shape=[256, 10],
initializer=tf.contrib.layers.variance_scaling_initializer())
b5 = tf.Variable(tf.random.normal([10]))
logit = tf.matmul(layer3, W5) + b5
H =tf.nn.softmax(logit)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logit,
labels=T))
train = tf.train.GradientDescentOptimizer(learning_rate=1e-3).minimize(loss)
sess.run(tf.global_variables_initializer())
for step in range(200):
tmp, loss_val = sess.run([train, loss],
feed_dict={X:norm_train_x_data,
T:onehot_train_t_data})
if step % 20 == 0:
print('loss value: {}'.format(loss_val))
