import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/colab/mnist/train.csv')
display(df.head())
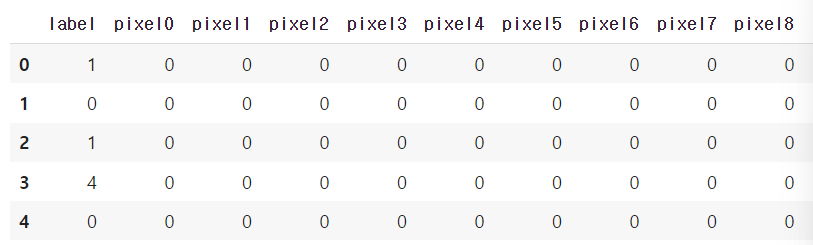
1. 데이터 전처리
train_x_data, test_x_data, train_t_data, test_t_data = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3,
random_state=1,
stratify=df['label'])
scaler = MinMaxScaler()
scaler.fit(train_x_data)
norm_train_x_data = scaler.transform(train_x_data)
norm_test_x_data = scaler.transform(test_x_data)
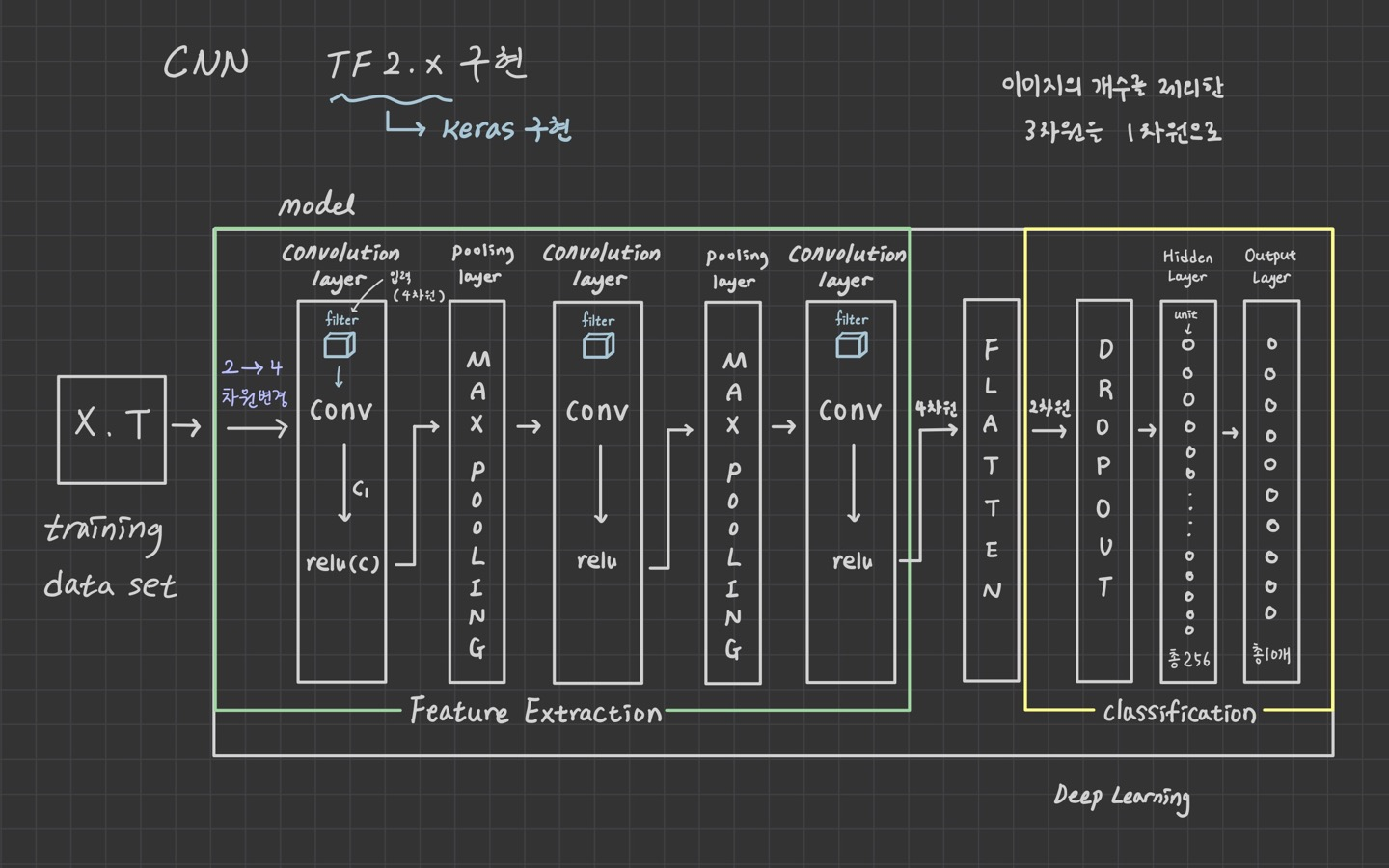
2. model 구현
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(28,28,1),
padding='valid',
strides=(1,1)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu',
padding='valid',
strides=(1,1)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu',
padding='valid',
strides=(1,1)))
model.add(Flatten())
model.add(Dropout(rate=0.5))
model.add(Dense(units=256,
activation='relu'))
model.add(Dense(units=10,
activation='softmax'))
print(model.summary())

3. model 실행 옵션
model.compile(optimizer=Adam(learning_rate=1e-3),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
4. model 학습
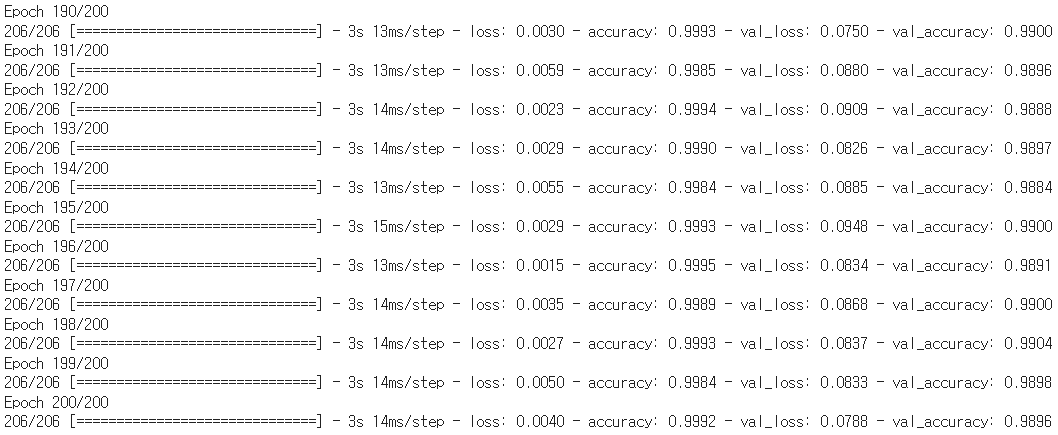
history = model.fit(norm_train_x_data.reshape(-1,28,28,1),
train_t_data,
epochs=200,
batch_size=100,
verbose=1,
validation_split=0.3)
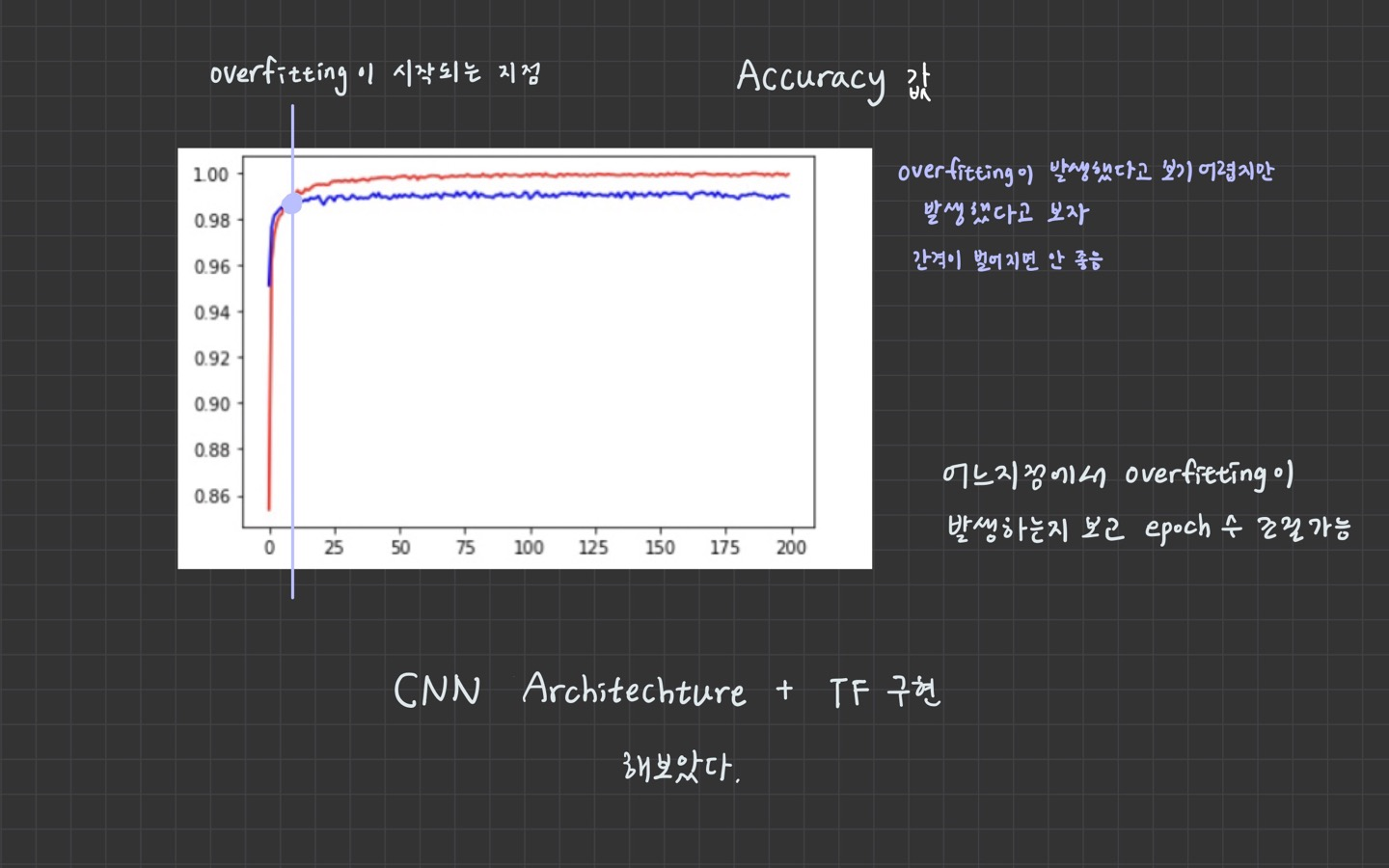
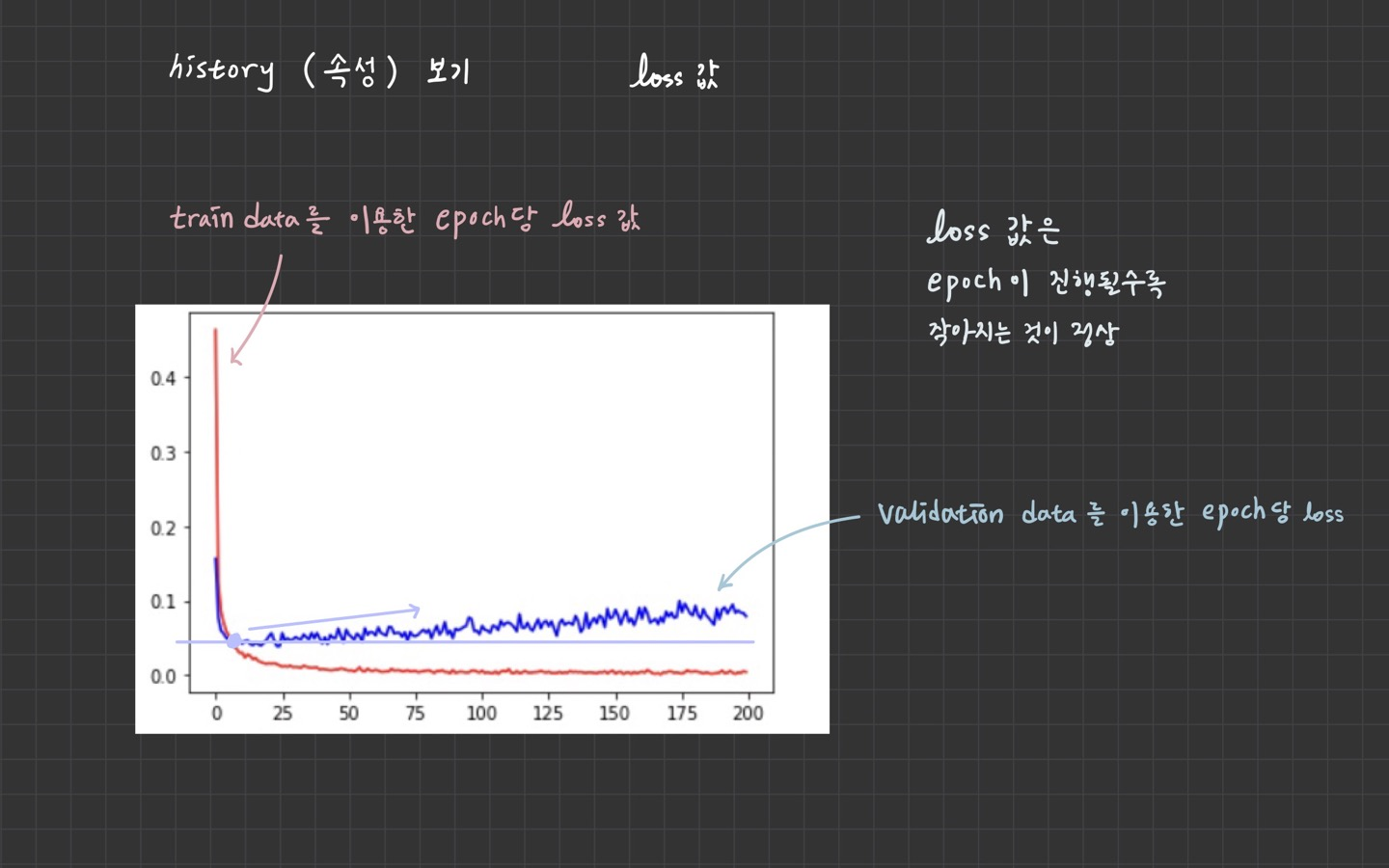
5. History 객체
epoch마다 loss, accuracy, val_loss, val_accuracy가 저장되어 있다.
=> 그래프를 그릴 수 있다.
print(type(history))
print(history.history.keys())
plt.plot(history.history['accuracy'], color='r')
plt.plot(history.history['val_accuracy'], color='b')
plt.show()
4.1 model 저장
model.save('/content/drive/MyDrive/colab/mnist_model_save/my_mnist_model.h5')
model evaluation (평가)
model.evaluate(norm_test_x_data.reshape(-1,28,28,1), test_t_data)
저장된 model load 성능평가 진행
from tensorflow.keras.models import load_model
new_model = load_model('/content/drive/MyDrive/colab/mnist_model_save/my_mnist_model.h5')
new_model.evaluate(norm_test_x_data.reshape(-1,28,28,1), test_t_data)
4.2 checkpoint 저장 및 평가
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint_path = '/content/drive/MyDrive/colab/mnist_model_save/cp-{epoch:04d}.ckpt'
cp_callback = ModelCheckpoint(checkpoint_path,
save_weights_only=True,
period=5,
verbose=1)
es = EarlyStopping(monitor='val_loss',
min_delta=0.001,
patience=5,
verbose=1,
mode='auto',
restore_best_weights=True)
history = model.fit(norm_train_x_data.reshape(-1,28,28,1),
train_t_data,
epochs=50,
batch_size=100,
verbose=1,
validation_split=0.3,
callbacks=[cp_callback, es])

문제가 있어서 멈춘 것인지 학습이 다 되어서 멈춘 것인지 확인해야 함

