
1. 개요
이번에는 크롤링한 웹툰들의 장르 키워드를 바탕으로 플랫폼 간 장르 키워드 통일 및 장르 키워드 학습을 진행할려고 한다.
2. genre 모델과 모듈
장르 키워드를 통일, 학습에 앞서 데이터를 저장할 공간이 따로 필요해 Genres 테이블을 생성해준다. Sequelize는 모델을 추가만 해주면 데이터베이스에 테이블을 추가한다.
Genre 테이블에는 키워드, 서비스, 뜻, embedding벡터 값, 변환될 키워드 이렇게 5가지 컬럼을 가지도록 설계했다.
- Genre Model
import { Column, DataType, Model, Table } from "sequelize-typescript";
@Table
export class Genre extends Model {
@Column({ type: DataType.STRING, allowNull: false, unique: true})
keyword: string;
@Column({ type: DataType.STRING, allowNull: false})
service: string;
@Column({ type: DataType.TEXT, allowNull: false})
description: string;
@Column({ type: DataType.TEXT, allowNull: true })
embVector: string;
@Column({ type: DataType.STRING, allowNull: true })
transformed: string;
}- Genre Module
import { Module } from '@nestjs/common';
import { GenreController } from './genre.controller';
import { GenreService } from './genre.service';
import { WebtoonModule } from 'src/webtoon/webtoon.module';
import { OpenaiModule } from 'src/openai/openai.module';
import { GenreProvider } from 'src/custom-provider/model.provider';
@Module({
imports: [WebtoonModule, OpenaiModule],
controllers: [GenreController],
providers: [GenreService, GenreProvider]
})
export class GenreModule {}- Genre Service
import { Inject, Injectable } from '@nestjs/common';
import { OpenaiService } from 'src/openai/openai.service';
import { WebtoonService } from 'src/webtoon/webtoon.service';
import * as fs from "fs";
import * as path from "path";
import { GENRE_FOLDER } from 'src/constatns/genre.constants';
import { Genre } from 'src/sequelize/entity/genre.model';
import { ChatCompletionMessageParam } from 'openai/resources';
import { CreateGenreDto, GetGenreDto, UpdateGenreDto } from 'src/dto/genre.dto';
@Injectable()
export class GenreService {
constructor(
@Inject("GENRE") private genreModel: typeof Genre,
private readonly webtoonService: WebtoonService,
private readonly openaiService: OpenaiService
) {}
// keyword와 service를 통해 장르 불러오기
async getGenre(getGenreDto: GetGenreDto): Promise<Genre> {
const genre = await this.genreModel.findOne({
where: { ...getGenreDto },
});
return genre;
}
// 새로운 장르를 데이터베이스에 저장
async createGenre(createGenreDto: CreateGenreDto) {
const genre = await this.getGenre({
keyword: createGenreDto.keyword,
service: createGenreDto.service
});
if (genre) return;
await this.genreModel.create({
...createGenreDto
});
};
// 장르의 변환된 데이터만만 데이터베이스 업데이트
async updateGenre(updateGenreDto: UpdateGenreDto) {
const { keyword, service } = updateGenreDto;
const genre = await this.getGenre({
keyword: updateGenreDto.keyword,
service: updateGenreDto.service
});
if (genre) return;
await this.genreModel.update({
...updateGenreDto
}, {
where: { keyword, service }
});
}- Genre DTO
import { IsOptional, IsString } from "class-validator";
export class GetGenreDto {
@IsString()
keyword: string;
@IsString()
service: string;
}
export class CreateGenreDto {
@IsString()
keyword: string;
@IsString()
service: string;
@IsString()
description: string;
@IsOptional()
@IsString()
embVector?: string;
@IsOptional()
@IsString()
transformed?: string;
}
export class UpdateGenreDto {
@IsString()
keyword: string;
@IsString()
service: string;
@IsOptional()
@IsString()
description?: string;
@IsOptional()
@IsString()
embVector?: string;
@IsOptional()
@IsString()
transformed?: string;
}
3. 장르 키워드 학습
먼저, 크롤링한 데이터를 바탕으로 각 플랫폼의 키워드를 json파일로 정리했다. 카카오페이지의 장르 키워드는 약 400개 네이버웹툰의 장르 키워드는 약 100개 정도 였으며 두 플랫폼 간 겹치는 키워드가 약 20~30개 정도 였다.
장르를 기반으로 추천하는 로직을 최종적으로 구현하기 위해서는 장르를 통해 해당 웹툰의 내용을 최대한 추측할수 있어야 하기 때문에 장르 키워드의 내용이 훨씬 더 풍부한 카카오페이지를 기준으로 키워드 통일을 진행하기로 결정했다.
시작하기에 앞서 키워드 통일 방법을 두가지 정도 간략하게 설계했다.
첫번째, 임베딩을 통한 방법이다.
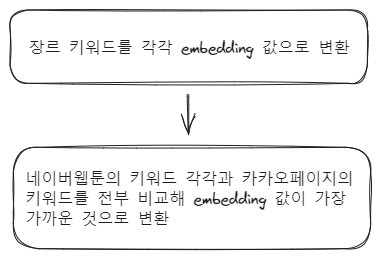
임베딩(embedding)이란? 문자열을 수치로 벡터화 시킨후에 그 벡터간의 거리를 구해서 유사도를 구하는 방식
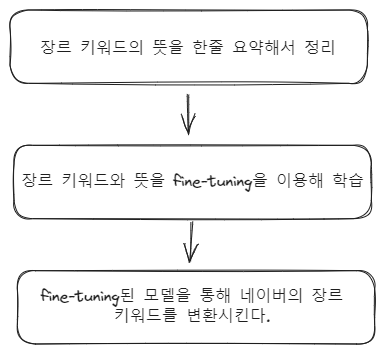
두번째, 미세조정을 통한 방법이다.
첫번째 방법이 훨씬 간단하고 저렴하기에 먼저 실행했다. 하지만 처참하게 실패했다. 그 이유는 장르 키워드들은 너무 길이가 짧은 단어들이기 때문에 embedding으로 유사한 단어를 구하기 너무 어려운 까닭이다.
물론 chatgpt의 결과는 항상 확실하지 않기 때문에 수정을 거쳐야 하지만 거의 절반이상의 단어가 너무 상관없는 단어들로 변환되서 첫번째 방법은 실패로 끝났다.
따라서, 두번째 방법으로 넘어가 글을 이어간다.
- 장르 키워드의 의미 저장하기
먼저 각 키워드를 그 의미와 함께 데이터베이스에 저장해야 한다. 여기서는 만들어놓은 openai모듈의 create completion 메서드를 사용했다. chatGPT에게 의미를 알려달라고 요청한 후 그것을 저장하는 것이다.
async getKeywordDescription(keyword: string): Promise<string> {
const prompt: ChatCompletionMessageParam[] = [
{ role: "system", "content": "너는 단어의 뜻을 물어보면 뜻을 1줄이내로 만화, 웹툰등에서 나오는 의미로 단어의 뜻을 요약해주는 사전이야."},
{ role: "user", "content": `${keyword}의 뜻을 1줄 이내로 자세하게 알려줘`},
];
const description = await this.openaiService.create_3_5_Completion(
null,
prompt,
0.2,
150
)
return description;
}일정한 형식으로 대답을 원하기 때문에 temperature를 0.2로, 내용이 너무 길면 시간도 오래 걸리고 비용도 커지므로 토큰의 수도 150토큰으로 제한을 두었다.
그리고 당연하게도 chatGPT의 결과이기 때문에 100% 신뢰하는 것보다 한번 수정을 거쳐야한다. 따라서 데이터베이스에 저장하면서 동시에 txt파일로 저장해 내가 한번 필터링한 후 업데이트까지 해야 작업이 끝난다. 코드는 다음과 같다.
// 키워드 뜻과 함께 데이터베이스 저장 및 txt파일 추출
async initKeyword(service: string) {
const filePath = path.join(GENRE_FOLDER, `${service}Genre.json`);
const writePath = path.join(GENRE_FOLDER, `${service}Genre.txt`);
const keywords: string[] = require(filePath);
let initContent = "";
for (let keyword of keywords) {
const genre = await this.getGenre({ keyword, service });
if (genre) continue;
const description = await this.getKeywordDescription(keyword);
const content = `${keyword}\n##\n${description}\n#######\n`;
initContent += content;
console.log(content);
await fs.writeFileSync(writePath, initContent, { encoding: "utf-8" });
await this.createGenre({ keyword, service, description });
}
await fs.writeFileSync(writePath, initContent, { encoding: "utf-8" });
}// 수정된 txt파일을 바탕으로 뜻 업데이트
async updateDescription(service: string): Promise<void> {
// 수정된 파일에서 장르 및 의미 읽어오기
const filePath = path.join(GENRE_FOLDER, `${service}Genre.txt`);
const readContent = await fs.readFileSync(filePath, { encoding: "utf-8" });
let contents = readContent
.toString()
.replaceAll("\r\n", "")
.replaceAll("\n", "")
.replaceAll(".", "")
.split("#######");
contents = contents.slice(0, contents.length-1);
// 읽어온 데이터로 db 업데이트 하기
const genreDescription: { [genre: string]: string } = {};
for (let content of contents) {
const keyword = content.split("##")[0];
const description = content.split("##")[1];
genreDescription[keyword] = description;
// 새로 추가된 키워드는 db에 저장하기
const genre = await this.getGenre({ keyword });
if (!genre) {
await this.createGenre({
keyword,
service,
description
});
continue;
}
await this.updateGenre({ keyword, service, description });
}
// 읽어온 데이터에서 삭제된 장르는 db에서 삭제하기
const genres = await this.getAllGenre();
for (let genre of genres) {
if (genre.keyword in genreDescription) {
continue;
} else {
await this.deleteGenre({ keyword: genre.keyword });
}
}
}위 과정을 자세하게 표현하면 다음과 같다.
-
initKeyword 메서드를 통해 카카오 장르 키워드의 뜻을 chatGPT에게 요청하고 db 및 텍스트 파일에 저장한다.
-
텍스트 파일을 직접 보고 의미가 잘못된 부분을 수정하고 필요없는 키워드는 삭제한다.
-
updateDescription 메서드를 통해서 수정한 파일의 내용을 db에 업데이트한다.
- 장르 키워드 학습시키기
이제 다음으로 해야할 것은 db에 저장된 카카오 장르 키워드 데이터를 지난 포스트에 구현했던 OpenaiModule을 통해 미세조정하는 것이다.
먼저, 카카오 키워드 데이터를 형식에 맞게 jsonl파일로 저장한다.
async createKeywordFineTuningPrompt(service: string) {
const genres = await this.getAllGenre(service);
let jsonlData = "";
for (let genre of genres) {
const systemMessage = `너는 웹툰의 장르 키워드와 그 뜻을 알고있는 전문가야.`;
const userMessage = `장르 키워드 "${genre.keyword}"의 뜻이 뭐야?`;
const assistMessage = genre.description;
const messagesData: ChatCompletionMessageParam[] = [
{ role: "system", content: systemMessage },
{ role: "user", content: userMessage },
{ role: "assistant", content: assistMessage }
];
const messages = { messages: messagesData };
jsonlData += JSON.stringify(messages) + "\n";
}
const writePath = path.join(OPENAI_JSONL_FOLDER_PATH, "keywordDescription.jsonl");
fs.writeFileSync(writePath, jsonlData, { encoding: "utf-8" });
}다음으로 jsonl파일을 업로드 한다.

업로드가 완료되면 다음과 같이 status가 processed로 바뀐다.
마지막으로 파일이 업로드가 완료되면 미세조정을 시작한다.

다음과 같이 status가 succeded로 바뀌면 완료되었음을 의미한다.
미세조정 작업의 상태를 api 요청을 통해서 확인할 수도 있지만 OpenAI 공식 사이트에서 미세조정 목록을 지원한다. 여기서 상태를 확인하는 것이 훨씬 편리하다.
4. 학습 결과
기본 모델인 gpt-3.5-turbo 모델과 미세조정된 모델의 차이를 보기 위해서 다음 포스트에서 장르 통일에 들어갈 네이버 장르 키워드를 5개의 결과를 비교해봤다.
- 헌터물
기본모델

미세조정 모델

- 서스펜스
기본모델

미세조정 모델

- 음식&요리
기본모델

미세조정 모델

- 차원이동
기본모델

미세조정 모델

- 계략여주
기본모델

미세조정 모델

결과를 비교하면서 미세조정된 모델을 다음과 같은 장점이 있었다.
1. 응답 시간이 훨씬 빠르다
미세조정된 모델은 약 1~2초 기본모델은 10~20초가 소요되었다.
2. 웹툰의 장르 키워드로서 적절한 뜻을 주었다.
계략여주, 차원이동 등은 결과 차이가 심한데 미세조정된 모델이 웹툰의 장르 키워드 측면에서 훨씬 정확하다.
문제점
1. chatGPT는 100% 정확하지 않다.
chatGPT의 처음 장르 키워드 뜻을 요청하고 텍스트 파일을 수정할 때 틀린 단어가 정말 많았다. 때문에 systemMessage를 바꿔서 그나마 적절한 뜻이 나오도록 하고 뜻이 틀린 단어들을 수정해주었다. 항상 chatGPT에게 요청을 한다면 그 결과를 확인하고 인간을 통한 필터링 작업이 필요하다.
2. 미세조정을 해도 정확한 단어를 기억하지 못한다.
다음 포스트에서 작업할 장르 통일을 위한 두번째 설계 과정은 다음과 같다.
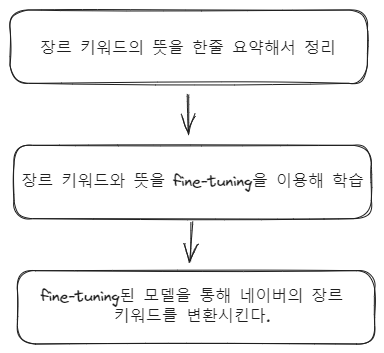
따라서 미세조정이 끝난 뒤, 다음과 같은 과정을 진행해 보았다.
-
네이버 장르 키워드(변환필요)를 미세조정된 모델에게 뜻을 요청한다.
ex) 직업드라마의 뜻을 알려줘 -
네이버 장르 키워드의 뜻을 다시 미세조정 모델에게 요청한다.
ex) ~~~ 이 뜻을 장르 키워드로 바꿔줘 -
미세조정 모델이 알려준 키워드가 카카오 장르 키워드에 존재하는지 확인한다.
위 과정을 진행한 결과, 1번은 잘 작동했지만 2번에서 미세조정 모델은 자신이 학습한 단어가 아닌 다른 단어들도 결과로 도출했다.
ex) 오피스물 -> 직장물(학습한 카카오 키워드에 존재하지 않음..)
즉 미세조정 모델은 키워드와 그 뜻을 학습했지만 그것을 100% 정확하게 다시 돌려주지는 않는다. 따라서 2번의 설계 과정을 다음과 같이 변경했다.
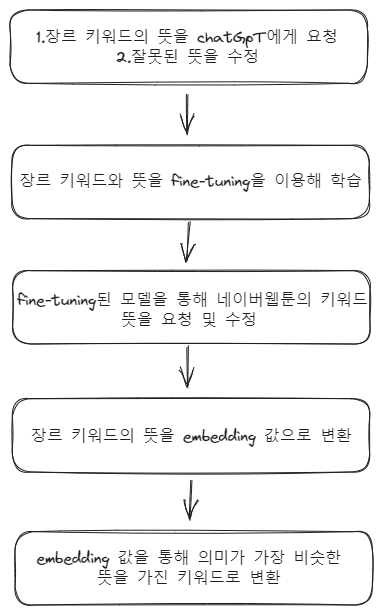
1번 설계 과정에서 이용했던 embedding을 다시 적용했다.
1번 과정에서 실패한 이유는 장르 키워드만 embedding 값으로 변환해서 비교하기에는 키워드가 너무 짧아서였다.
하지만 이제는 미세조정 모델을 통해 카카오 키워드는 물론 네이버 키워드 모두 뜻을 도출해내었다. 때문에 뜻끼리 embedding을 비교하면 더 유의미한 결과가 나올거라 예상했기 때문에 설계과정을 위와 같이 변경한 것이다.
참고
https://platform.openai.com/docs/guides/fine-tuning - openai 공식 문서
https://lsjsj92.tistory.com/657 - embedding 사용 블로그
