
1. 개요
지난 포스트에서 카카오페이지의 장르와 그 의미를 chatGPT에게 학습시켰다.
이번에는 학습된 미세조정 모델을 통해 네이버 장르 키워드의 뜻을 요청하고 한번의 수정을 거친 뒤에 카카오, 네이버 모든 장르 키워들의 의미를 embedding을 통해 벡터화 시킨다.
그리고 벡터간의 거리를 통해서 장르 키워드의 의미가 얼마나 유사한지를 계산해서 가장 적절한 변환을 이뤄낸다. 물론 여기서도 챗지피티에 의한 결과이기 때문에 직접 검사하는 과정을 거쳐야 한다.
2. 장르 키워드 통일
먼저 지난번과 동일하게 다음과 같은 과정을 거친다.
-
네이버 장르 키워드의 뜻을 미세조정된 모델에게 요청한다.
-
요청 받은 키워드와 의미를 검사하고 수정한다.
-
수정된 데이터를 db에 업데이트한다.
그리고 이제 저번에 문제점을 발견했을때 해결을 위해 설계한 방법을 확인한다.
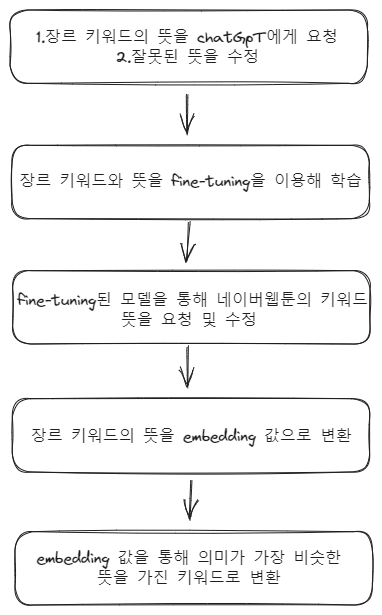
- 장르 키워드의 뜻을 embedding 변환
async updateEmbedding(service: string) {
const genres = await this.getAllGenre(service);
for (let genre of genres) {
const { keyword, service, description } = genre;
const embVector = await this.openaiService.createEmbedding(description);
const embVectorText = await JSON.stringify(embVector);
await this.updateGenre({
keyword,
service,
embVector: embVectorText,
});
}
}OpenaiService를 활용하여 키워드의 뜻을 embedding 변환 후 db에 저장한다.
- embedding 벡터를 통해 가장 유사한 의미의 키워드로 변환
async updateTransform(
service: string,
referService: string,
): Promise<{ [keyword: string]: string }> {
const genres = await this.getAllGenre(service);
const referGenres = await this.getAllGenre(referService);
let result: { [keyword: string]: string } = {};
// embVector 유사도의 최댓값을 구함
for (let genre of genres) {
let maxSimilarity = -1;
let similarKeyword = "";
for (let referGenre of referGenres) {
const embVector: number[] = await JSON.parse(genre.embVector);
const referEmbVector: number[] = await JSON.parse(referGenre.embVector);
const similarity = await this.openaiService.calcSimilarityFromEmbedding(
embVector,
referEmbVector,
);
if (similarity && maxSimilarity < similarity) {
maxSimilarity = similarity;
similarKeyword = referGenre.keyword;
}
}
// db 업데이트
if (similarKeyword) {
await this.updateGenre({
keyword: genre.keyword,
service: genre.service,
transformed: similarKeyword,
});
result[genre.keyword] = similarKeyword;
}
}
return result;
}
위의 과정을 진행한 결과는 다음과 같았다.
{
...
"청춘로맨스": "궁정로맨스",
"캠퍼스로맨스": "캠퍼스물",
"오피스로맨스": "오피스물",
"동아리": "학원",
"혐관로맨스": "쌍방삽질",
"고자극로맨스": "궁정로맨스",
"아이돌연애": "연상연하",
"4차원": "사차원",
"야구": "스포츠",
"2030연애": "연상연하",
"격투기": "격투",
"계략여주": "계략남",
"선결혼후연애": "맞선관계",
"무해한": "잔잔한",
"걸크러시": "걸크러쉬",
"히어로": "영웅/신화",
...
}발전한 점
1. 다양한 설계와 문제해결
리팩토링 전에는 이 과정을 거치지 않고 네이버 키워드를 카카오 키워드에 하나하나 대조해가며 스스로 바꾸었다. 하지만 그것은 너무 시간이 오래걸리고 재사용성도 없었다.
하지만 이번에는 미세조정을 통해 이 과정을 구현하며 미세조정 데이터를 준비하면서 chatGPT가 예상과 완전 다른 결과를 도출하거나 3.5번전에서 시스템 메세지를 어떻게 더 효율적으로 입력하는지 등 많은 시행과 착오 끝에 더 나은 방향으로 문제를 해결해 나갔다.
그리고 이번에 미세조정한 모델은 장르 키워드의 의미를 잘 알고 있기 때문에 추후에 웹툰의 줄거리를 바탕으로 장르 키워드를 추천할때 재사용할 수 있을 가능성도 열려있기에 좋은 시도로 생각한다.
참고
