
1. 개요
장르 키워드 학습을 완료했으니 이제 웹툰 추천을 위한 직접적인 기능을 구현해야 한다. 앞으로의 수행 과정은 다음과 같다.
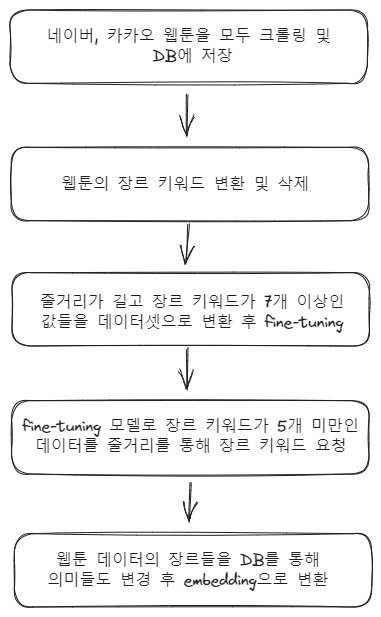
2. 웹툰 크롤링 및 DB에 저장
이미 크롤링 모듈 및 기능은 구현이 되어 있고 그것을 이용해 크롤링 해온 뒤 데이터를 검사 후 저장하는 작업을 구현한다.
async initWebtoon(service: string) {
const browser = await puppeteer.launch({
headless: false,
// args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
const webtoonIdList: string[] = [];
// 플랫폼 로그인
const loginResult = await this.login(page, service);
console.log(loginResult ? "로그인 성공" : "로그인 실패");
// 모든 웹툰 id 크롤링
for (let day of DAY_LIST) {
const dayIdList = await this.crawlWeeklyWebtoonId(page, day, service);
webtoonIdList.push(...dayIdList);
}
const dayIdList = await this.crawlWeeklyWebtoonId(page, "완", service);
webtoonIdList.push(...dayIdList);
console.log("count: ", webtoonIdList.length);
for (let webtoonId of webtoonIdList) {
try {
const webtoon = await this.webtoonService.getWebtoonForIdNoCache(webtoonId);
if (webtoon) {
console.log(`\nId ${webtoonId} is already exist.\n`);
continue;
}
const crawlWebtoon = await this.crawlWebtoonForId(
page,
webtoonId,
service,
);
// 모든 프로퍼티가 크롤링되었는지 확인 후 db에 저장
if (
crawlWebtoon.title &&
crawlWebtoon.author &&
crawlWebtoon.category &&
crawlWebtoon.description &&
crawlWebtoon.episodeLength &&
crawlWebtoon.fanCount &&
crawlWebtoon.genreCount &&
crawlWebtoon.genres &&
crawlWebtoon.thumbnail &&
crawlWebtoon.updateDay
) {
await this.webtoonService.insertWebtoon({
webtoonId,
service,
title: crawlWebtoon.title,
author: crawlWebtoon.author,
category: crawlWebtoon.category,
description: crawlWebtoon.description,
episodeLength: crawlWebtoon.episodeLength,
fanCount: crawlWebtoon.fanCount,
genreCount: crawlWebtoon.genreCount,
genres: crawlWebtoon.genres,
thumbnail: crawlWebtoon.thumbnail,
updateDay: crawlWebtoon.updateDay
});
} else {
console.log(`\nId ${webtoonId} is not crawled...\n`);
}
console.log(crawlWebtoon);
} catch (e) {
console.log(e);
console.log(`\nId ${webtoonId} is not crawled...\n`);
continue;
}
}위의 메서드는 다음과 같은 작업을 한다.
- 월~일 및 완결 웹툰 아이디를 전부 가져온다.
- DB에 해당 웹툰 아이디가 이미 있는지 확인한다.
- 웹툰 아이디가 없다면 상세 데이터를 크롤링한다.
- 크롤링한 웹툰 데이터가 적절한지 확인 후 DB에 저장한다.
그리고 추후에 잘못 불러온 정보나 다시 정보를 업데이트 할 상황이 있다. 예를 들면 웹툰은 주마다 업데이트 되기때문에 에피소드의 개수등을 다시 불러올 필요가 있다. 따라서 다음과 같은 업데이트 메소드를 작성했다.
async updateWebtoonProperty(updateWebtoonPropertyDto: UpdateWebtoonPropertyDto) {
const { service, property } = updateWebtoonPropertyDto;
// 프로퍼티가 올바른지 확인
const browser = await puppeteer.launch({
headless: false,
// args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
const webtoonIdList: string[] = [];
// 플랫폼 로그인
const loginResult = await this.login(page, service);
console.log(loginResult ? "로그인 성공" : "로그인 실패");
// 모든 웹툰 id 크롤링
for (let day of DAY_LIST) {
const dayIdList = await this.crawlWeeklyWebtoonId(page, day, service);
webtoonIdList.push(...dayIdList);
}
const dayIdList = await this.crawlWeeklyWebtoonId(page, "완", service);
webtoonIdList.push(...dayIdList);
// 해당 프로퍼티 데이터만 크롤링 해온다.
for (let webtoonId of webtoonIdList) {
try {
const webtoon = await this.webtoonService.getWebtoonForIdNoCache(webtoonId);
if (!webtoon) {
console.log(`\nId ${webtoonId} is not exist...\n`);
continue;
}
const crawlWebtoon = await this.crawlWebtoonForId(
page,
webtoonId,
service,
{ [property]: true }
);
// 정상적으로 크롤링 됐는지 확인 후 db 업데이트
if (crawlWebtoon[property]) {
await this.webtoonService.updateWebtoonForOption({
webtoonId,
[property]: crawlWebtoon[property]
});
} else {
console.log(`\nId ${webtoonId} is not crawled...\n`);
}
console.log(crawlWebtoon);
} catch (e) {
console.log(`\nId ${webtoonId} is not crawled...\n`);
continue;
}
}
await page.close();
await browser.close();
}문제점
1. 에러 처리
이렇게 대량의 데이터를 크롤링 해오는 경우는 경험이 많지 않다. 그렇기 때문에 이상적인 결과(모든 데이터가 전부 완벽하게 크롤링된다)만을 생각하고 코드를 작성했지만 현실은 그렇지 않다.
크롤링 과정에서 시간이 오래걸려 timeout 에러가 발생해 데이터를 불러오지 못하거나 누실된 데이터를 받아올 수도 있다. 이럴 경우에 에러 처리를 해놓지 않고 계속 완벽한 결과를 위해 코드를 고치게 되서 시간이 굉장히 오래걸리고 해결도 하지 못했다.
예를 들어 timeout에러를 잡기 위해 크롤링 시간제한을 1~2분쯤으로 걸어 놓을경우 작업이 완료되는 시간이 굉장히 오래걸릴 수 있다. 따라서 굳이 저 에러를 완벽히 잡기보다는 에러가 발생했거나 누실된 데이터가 있을때에는 DB에 저장하지 않고 다음 작업으로 넘어가면 된다.
그러면 나중에 DB에 저장되지 않은 아이디만 다시 크롤링하면 되기 때문이다. 이렇게 한다면 불필요한 시간을 많이 아낄수 있다. 따라서 어떤 상황에서는 에러를 완벽히 처리한다는 생각을 버리면 좋을듯하다.
2. 서비스 단에서 에러 던질때 문제
크롤링을 해오면서 도중에 크롤링이 아예 되지 않는 현상이 발생했다.
그 이유는 getWebtoonForId 메서드 자체에서 웹툰 아이디가 DB에 존재하지 않는다면 NotFoundException을 던지기 때문이다. 하지만 나는 에러가 아닌 null값으로 값이 없다는 것을 받아야 했기때문에 발생한 오류이다.
그래서 getWebtoonForIdNoCache라는 서비스단에서의 캐싱과 에러를 빼버린 새로운 메서드를 작성해서 오류를 해결했다.
서비스단에서의 캐싱과 에러는 아주 편하지만 이렇게 불편한 상황도 생기는걸 알게되었다.
참고
오늘은 참고한 문서가 없다 ㅎㅎ..
