
1. 개요
장르 키워드가 5개 미만인 "로판" 카테고리의 웹툰 약 300개를 미세조정 모델을 이용해 장르 키워드를 요청해 저장했다.
이번에는 웹툰의 장르 및 줄거리를 embedding을 통해 벡터로 변환 후 DB에 저장을 시켜주고 유사도를 통해 가장 비슷한 웹툰을 찾는 테스트까지 진행한다.
2. 장르 및 줄거리 embedding
이전에 단어 학습 과정에서 임베딩을 할때 실패했던 요인은 너무 짧은 문자열은 임베딩에 적합하지 않다는 것이였다.
따라서, 줄거리가 아닌 장르 키워드는 너무 짧은 단어이기에 Genre 테이블을 통해 장르의 뜻으로 바꿔서 임베딩 과정을 적용한다.
또한, DB에는 문자열 형태로 저장을 하기 떄문에 임베딩 벡터들은 JSON을 통해 문자열로 변환 후 DB에 저장한다.
- 장르
async initWebtoonGenreEMB(initRecommendGenreOptionDto: InitRecommendGenreOptionDto) {
// 조건에 맞는 웹툰 불러오기
const webtoons = await this.webtoonService.getAllWebtoonForOption({
...initRecommendGenreOptionDto,
});
for (let webtoon of webtoons) {
const genres = JSON.parse(webtoon.genres);
let genreText = "";
// 모든 장르에 대해 장르의 뜻을 문자열로 합치기
for (let genre of genres) {
const genre_ = await this.genreService.getGenre({ keyword: genre });
if (genre_) {
const description = genre_.description;
genreText += ( description || "" ) + "\n\n";
}
}
// 장르 임베딩 벡터를 생성후 문자열로 변환
const embVector = JSON.stringify(await this.openaiService.createEmbedding(genreText));
// DB업데이트
await this.webtoonService.updateWebtoonForOption({
webtoonId: webtoon.webtoonId,
embVector,
});
}
}- 줄거리
async initWebtoonDescriptionEMB(initRecommendGenreOptionDto: InitRecommendGenreOptionDto) {
// 조건에 맞는 웹툰 불러오기
const webtoons = await this.webtoonService.getAllWebtoonForOption({
...initRecommendGenreOptionDto,
});
for (let webtoon of webtoons) {
const { webtoonId, description } = webtoon;
// 줄거리 임베딩 벡터를 생성후 문자열로 변환
const embVectorDescription = JSON.stringify(await this.openaiService.createEmbedding(description));
// DB업데이트
await this.webtoonService.updateWebtoonForOption({
webtoonId,
embVectorDescription,
});
}
}- 결과 확인

위와 같이 결과 값은 잘 저장되었지만 혹시나 도중에 저장이 안되거나 null값이 있을수 있기때문에 전체 개수도 체크해준다.
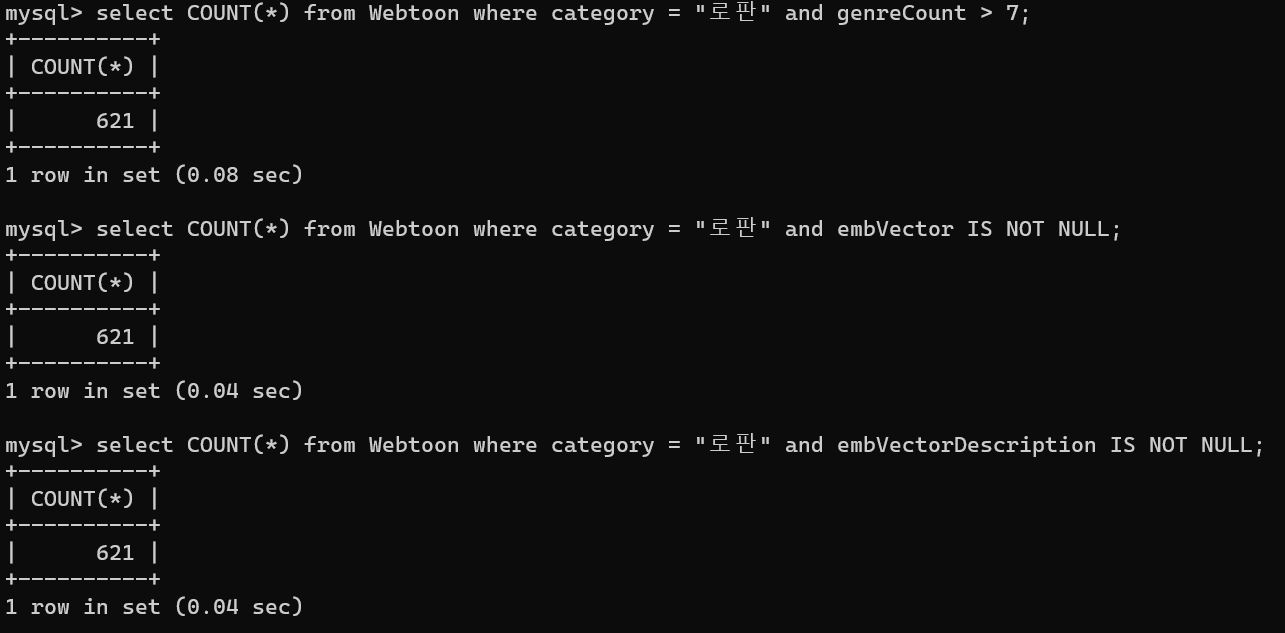
다행히 개수가 621개로 동일하기에 모두 알맞게 반영되었다.
3. 비슷한 웹툰 추천
이제 마지막으로 장르의 유사도를 통해 웹툰을 정렬해주는 기능을 구현한다. 상세한 로직은 다음과 같다.
- 요청된 장르들을 GenreService를 통해 장르 뜻으로 변환
- 장르의 뜻을 embedding을 통해 벡터로 변환
- similarityComapre에 { id: 유사도 } 형태로 웹툰마다 embedding벡터를 비교한 유사도를 저장
- similarityComapre에 저장된 유사도를 통해 웹툰 배열 정렬(내림차순)
- 결과 반환
async createRecommendWebtoon(createRecommendWebtoonDto: CreateRecommendWebtoonDto): Promise<Webtoon[]> {
const { category, genres } = createRecommendWebtoonDto;
let genreText = "";
// 모든 장르에 대해 장르의 뜻을 문자열로 합치기
for (let genre of genres) {
const genre_ = await this.genreService.getGenre({ keyword: genre });
if (genre_) {
const description = genre_.description;
genreText += ( description || "" ) + "\n\n";
}
}
// 장르 임베딩 벡터를 생성후 문자열로 변환
const InputEmbVector = await this.openaiService.createEmbedding(genreText);
// 카테고리에 해당하는 웹툰 전부 불러오기
const webtoons = await this.webtoonService.getAllWebtoonForOption({ category });
// { id: 유사도 }의 형태의 객체 리터럴
const similarityComapre: { [id: string]: number } = {};
for (let webtoon of webtoons) {
if (webtoon.embVector) {
similarityComapre[webtoon.webtoonId] =
await this.openaiService.calcSimilarityFromEmbedding(
InputEmbVector,
JSON.parse(webtoon.embVector),
);
}
}
// similarityComapre를 통해 요청된 장르와 웹툰들 장르의 유사도를 비교하며 정렬
webtoons.sort((a, b) => {
return similarityComapre[b.webtoonId] - similarityComapre[a.webtoonId];
});
return webtoons;
}결과는 다음과 같이 실행된다.

문제점
- Response 시간 지연
웹툰 유사도 정렬 후 반환을 할때 응답하는데까지 시간이 10초가량 발생했다.
하지만 createRecommendWebtoon메서드는 알고리즘상 O(n^2) 이상의 시간복잡도가 들어가는 알고리즘이 포함되어 있지도 않으며 포함되더라도 데이터의 개수(N)가 1000이 넘지 않기에 10초라는 시간은 발생할 수 없다.
로그를 찍으면서 알아낸 것은 실제로 메서드가 기능을 다 하는데 발생하는 시간은 0.5초도 걸리지 않으며 데이터를 반환하는데 약 10초라는 시간이 발생했다.
이유는 반환하는 데이터가 너무 길다는 것이였다. 클라이언트와 서버는 결국 문자열 형태로 데이터를 요청하고 응답하는데 Webtoon 모델을 그대로 반환해버리면 너무 많은 문자열들이 한번에 반환되기에 시간이 오래걸리는 것이였다.
- 해결
해결방법은 간단하다. 반환하는 데이터가 너무 길어서 발생한 문제이기에 데이터를 짧게 만들어 주는 것이 해결방법이다. 즉 가장 중요한 데이터인 webtoonId만을 반환하기로 헀다.
async createRecommendWebtoon(createRecommendWebtoonDto: CreateRecommendWebtoonDto): Promise<string[]> {
...
// 웹툰의 id를 반환 (응답 시간 단축)
return webtoons.map((webtoon) => webtoon.webtoonId);
}- 결과
응답 시간 단축: 10초 -> 0.5초
