
ℹ️ <혼자 공부하는 머신러닝+딥러닝> 책을 읽고 정리한 내용입니다.
혼공학습단을 시작하며 (ft. why ML?)
바야흐로 2022년 신입생 시절, 인공지능이 궁금하다는 이유 하나로 교내 AI 동아리에 참여했다. 당시 python도 제대로 모르는 상태였는데 말이다. 그곳에서 numpy, pandas와의 첫 만남이 시작됐다.
동아리는 스터디 방식으로 운영됐다. numpy, pandas 관련 커리큘럼이 있었고, 일주일마다 그걸 해오고 공유하는 방식이었다. 하지만 아쉽게도 남는 게 거의 없었다. 당시 python 자체도 생소했는데, 거기에 numpy, pandas까지 함께 배우다 보니 이것들을 도구로 인식하기보다는 외워야 할 기능들로 받아들이게 됐다. 결국 스트레스만 쌓이고 그 학기로 스터디를 마무리했다. 그 이후로는 AI와 데이터 분석 쪽에는 관심을 가지지 않았다.
그렇게 3년이 흘렀다. 돌아보면 그 3년간 인공지능의 성장이 참 폭발적이었다. 신입생 때는 GPT 성능이 지금만큼 좋지 않아서 과제를 거의 직접 했는데, 이제는 GPT가 내 일상의 일부가 되어버렸다. 자소서를 쓸 때 퇴고를 맡기고, 코딩할 때는 옆에서 조언해주는 전담 멘토시다. 뿐만 아니라 내 안드로이드 폰의 Gemini와는 심심할 때마다 음성으로 대화를 나누기도 하고, 폰을 쓰다가 궁금한 게 생기면 화면을 그대로 보여주며 질문하곤 한다. 22년에는 정말 상상도 못했던 일들이다.
1학년 경험 이후로 나는 줄곧 웹 개발 분야를 파왔다. 웹 프로젝트를 여러 번 해보고, 네이버 부스트캠프에서 웹 풀스택 과정을 수료했으며, 회사에서 백엔드 인턴도 경험했다.
하지만 25년에 들어서 인공지능 공부는 교양으로라도 해놔야겠다는 생각이 들었다. 계속해서 인공지능과 엮이게 되었기 때문이다. 네이버 부스트캠프에서는 2월 동안 '인공지능 리팩토링'이라는 과정을 진행했다. 내 서비스에 인공지능을 붙여보는 거였는데, 클로바 API도 써보고 Hugging Face에서 모델을 받아 사용해보기도 했다.
더 결정적이었던 건 인턴으로 들어간 곳이 ML 기반 추천 시스템을 개발하는 백엔드 팀이었다는 것이다. 그 팀에서 일할수록 내가 ML 도메인을 얼마나 모르는지 절감했다. 첫 주에 "피쳐가 뭐예요?"라고 물었을 정도니까. (나중에 알았지만 '피쳐'는 이 책 챕터 1에 나오는 아주 기초적이고 많이 쓰이는 개념이었다.)
마침 인턴이 끝나고 9월 복학 전까지 여유 시간이 생겼다. 머신러닝 공부를 해봐야겠다고 마음먹었지만, 어떤 것부터 어떻게 시작해야 할지 막막했다.
그러다 우연히 혼공학습단 모집 홍보를 보게 됐다. <혼공컴운>, <혼공네트>를 읽어본 경험이 있어서 '혼공학습단'이 무엇인지 알고 있었다. 혼공 시리즈를 주차별로 함께 읽어가며 서로 동기부여를 하는 프로그램이다. (14기 모집 링크를 함께 첨부한다.)
이거라면 반강제적으로 ML 공부를 끝까지 해볼 수 있을 것 같았다. 바로 신청했다.
책은 <혼자 공부하는 머신러닝+딥러닝>이며, 6주간 아래 커리큘럼대로 진행된다. 3년 전과는 다르게 이제는 python도 익숙하고, 무엇보다 배우는 목적이 명확하니 열심히 해봐야지!
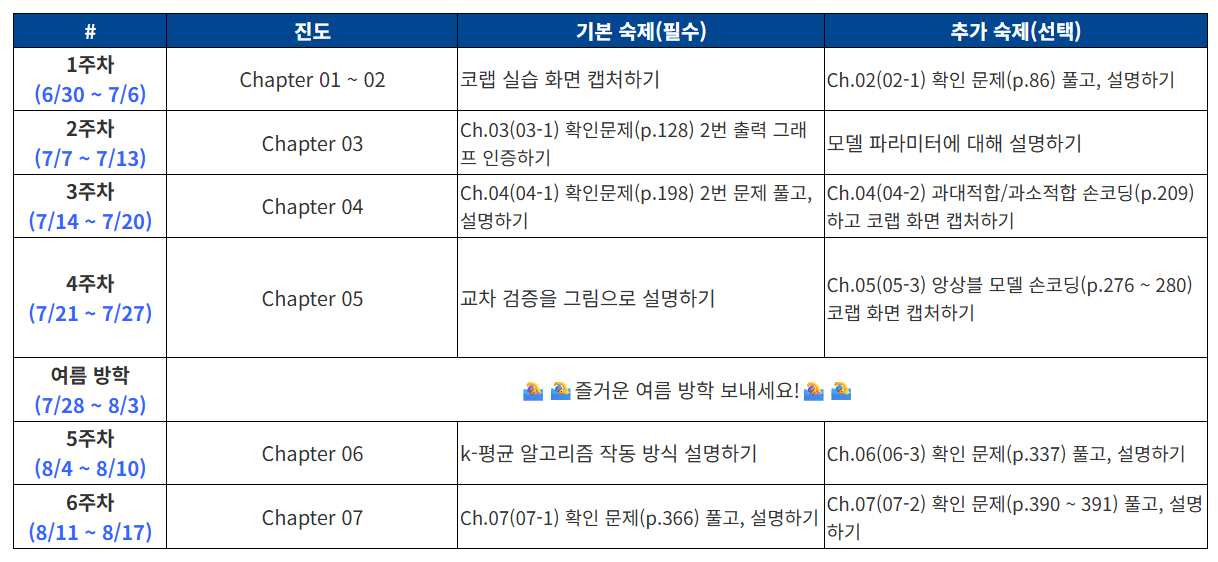
머신러닝의 기초 개념들
본격적으로 책에서 배운 내용들을 정리해본다.
머신러닝과 딥러닝
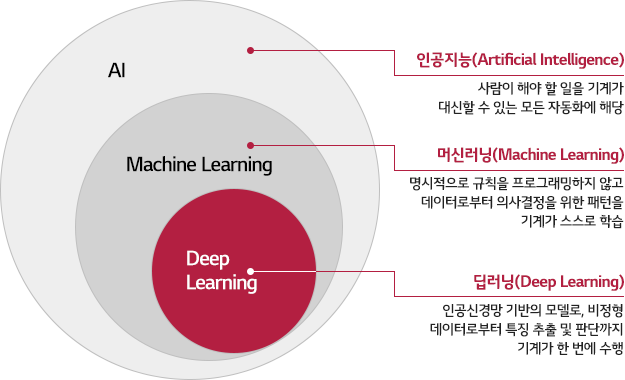
(이미지 출처)
'머신러닝과 딥러닝'이라는 용어를 들으면 어디선가 위와 같은 그림을 봤던 것 같다. AI > ML > DL 이라는 걸 어렴풋이 들어보긴 했으나, 구체적으로 설명하라면 설명하긴 어려웠다. 이번 기회에 확실히 알게 되었는데, 정리하면 아래와 같다.
- 머신러닝: 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 딥러닝: 머신러닝 알고리즘 중에 인공 신경망을 기반으로 한 방법들을 통칭
피쳐(feature)란 무엇인가
내가 인턴으로 들어가서 첫 주에 했던 질문이 '피쳐가 뭐예요?'였다...ㅋㅋ 그래서 더 눈에 들어온 부분이 바로 피쳐에 대한 설명이라 짚고 넘어간다.
피쳐란 한국말로 '특성'이다. 즉, 생선이 있다면 생선의 '길이'가 하나의 피쳐이고 '무게'가 하나의 피쳐이다.
인터넷에 피쳐에 대해서 검색해보면, '테이블의 컬럼이다'라는 말도 종종 나온다. 마치 아래와 같은 표로 정리했을 때, '길이', '무게' 각각이 피쳐이다.
| 길이 | 무게 |
|---|---|
| 25.4 | 242.0 |
| 26.3 | 290.0 |
| 26.5 | 340.0 |
그리고 이 피쳐들이 바로 모델을 훈련시키기 위한 중요한 자산들이다.
실습: 생선 분류 훈련 및 평가
아래와 같이 bream과 smelt라는 생선 정보가 분포해있다. 주황색이 smelt(빙어)이고, 파란색이 bream(도미)이다.
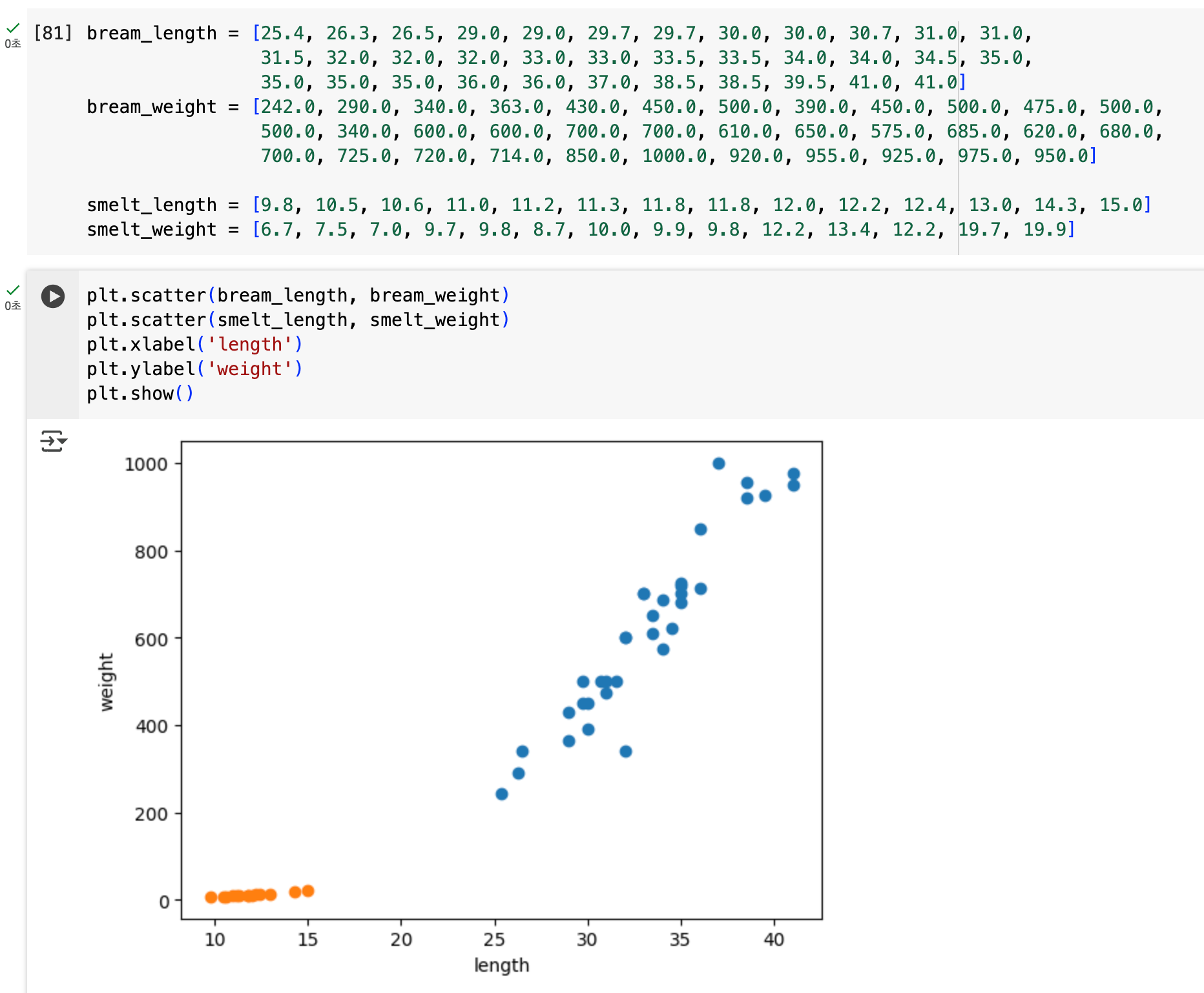
이제 훈련을 시킬 차례이다. K-NN 알고리즘을 사용해 훈련을 진행했다.
K-NN(K-Nearest Neighbors) 알고리즘이란?
어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용하는 알고리즘이다.
근접한 데이터 몇 개를 보고 판단할지는 직접 지정하여 사용할 수 있다.
정답 세트를 만들고, K-NN 알고리즘으로 훈련을 시킨다. 해당 부분에 대한 코드는 아래와 같다.
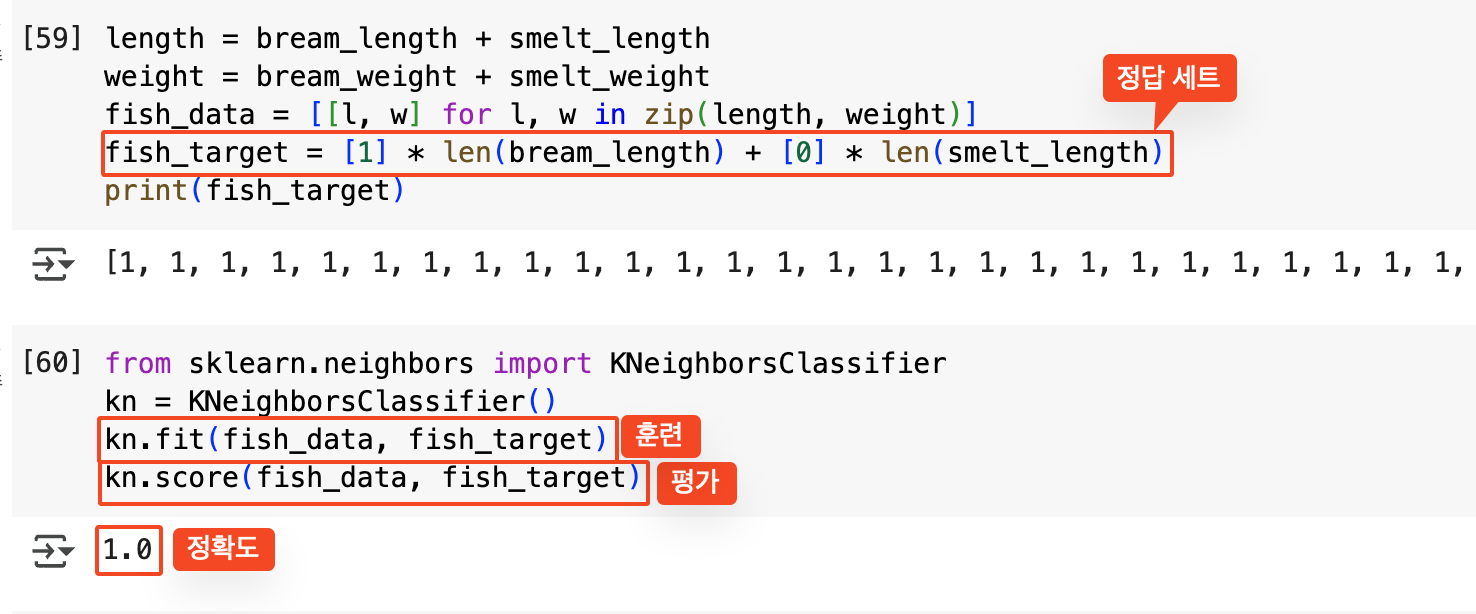
위와 같이 정확도 1.0으로, 모든 정답을 다 맞춘 것을 확인할 수 있다!
그런데 문득 궁금한 점이 생겼다. 훈련에 사용한 데이터로 평가를 했으니 당연히 다 맞춰야하는 게 아닌가?
알아보니, 훈련 데이터로 테스트를 하더라도 항상 100%의 정확도가 나오는 것은 아니라고 한다. 위의 산포도처럼 분포가 잘 구분지어 있는 경우라면 괜찮지만, 만약 같은 피쳐값(길이, 무게)를 가지면서도 다른 클래스에 속하는 데이터가 있다면 애매해질 수 있다고 한다.
진짜 그런지 장난 한 번 쳐봐야겠다. 이상치에 해당하는 값 세 개를 넣어봤다. 아래 산포도를 보면, 주황색 세 개의 점이 애매하게 나와있는 걸 확인할 수 있다.
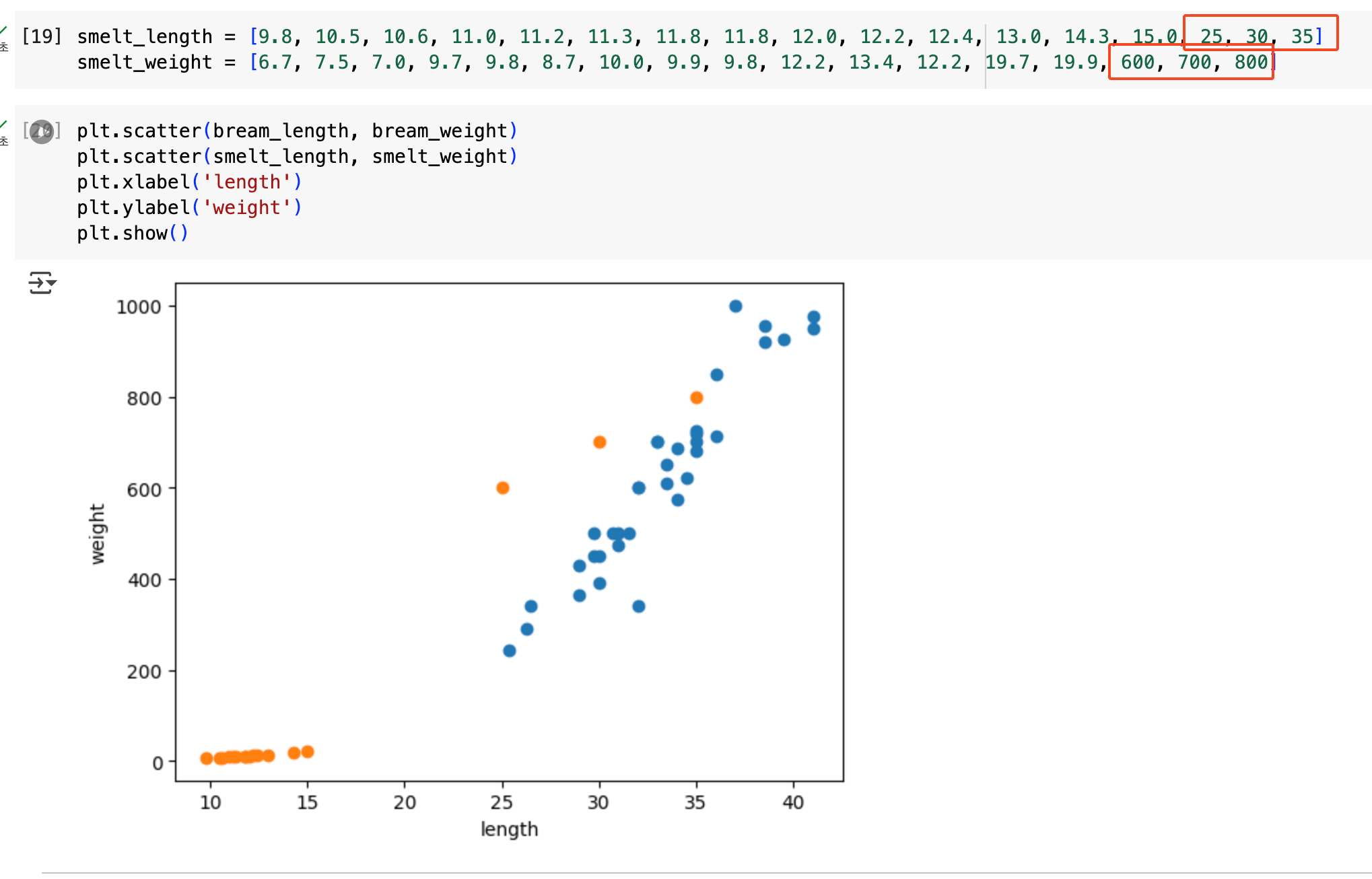
자, 이제 훈련 및 평가를 진행해보자.
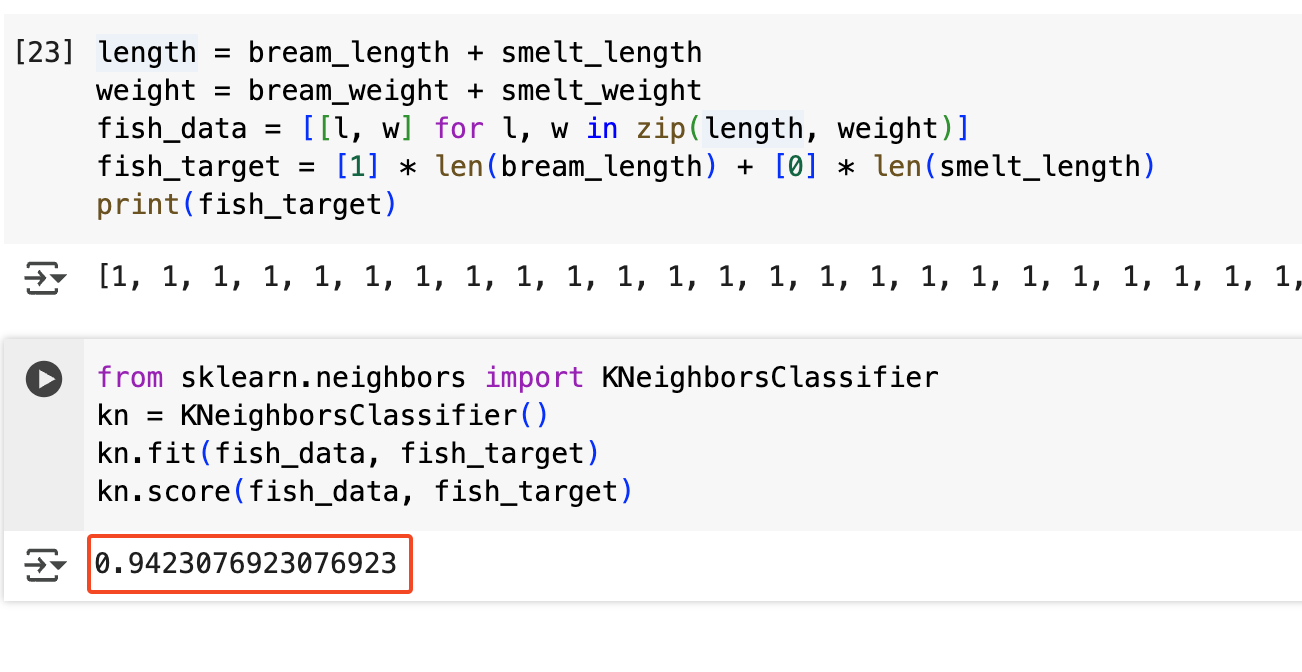
예상대로 훈련했던 데이터 그대로 평가를 진행했는데도 1이 안 나오는 현상을 발견할 수 있다! 52개의 데이터 중 3개(위에서 이상치로서 추가한 값들)에서 답을 틀리게 한 것이다! (49/52=0.9423076923)
K-NN 알고리즘의 매개변수 K값 이해하기
위에서 설명했듯이, K-NN 알고리즘은 특정 점이 들어오면 그 점과 가장 근접한 K개를 찾아 도미인지 방어인지를 결론을 낸다.
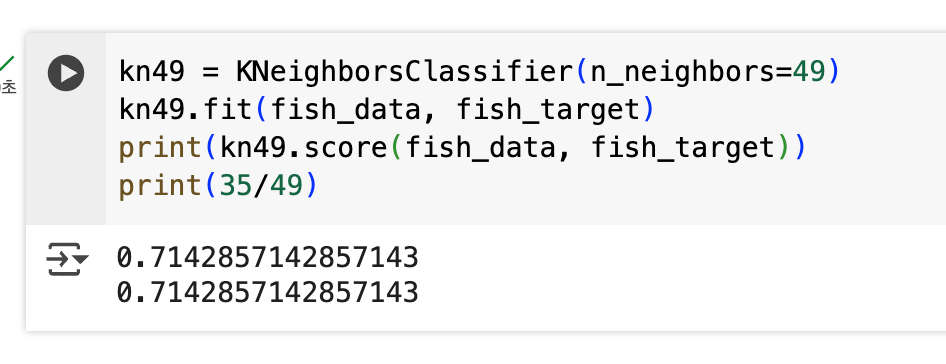
만약 K=49로 설정해버리면 도미가 49개 중 35개이므로 다수로 처리돼 어떤 데이터가 들어와도 항상 도미라는 결론이 나와버린다.
직접 눈으로 확인해보면 알 수 있는데, 아래처럼 K=49로 지정하고 평가해보면 0.714 정도의 정답률이 나온다. 이 값은 35/49의 값과 동일하다. 즉, 모든 데이터에 대해 도미라는 결론을 냈다는 의미이다.
샘플링 편향
하나의 생선 데이터를 샘플(sample)이라고 부른다. 이런 샘플들을 여러 개 모아 훈련 데이터와 테스트 데이터를 만들 수 있다.
상식적으로 훈련하는 데이터와 테스트하는 데이터에는 도미와 빙어가 골고루 섞여있어야 한다. 그렇지 않은 경우, 즉 한 어종으로 치우쳐있는 상황을 '샘플링 편향'이라고 부른다.
샘플링 편향의 예를 살펴보자.
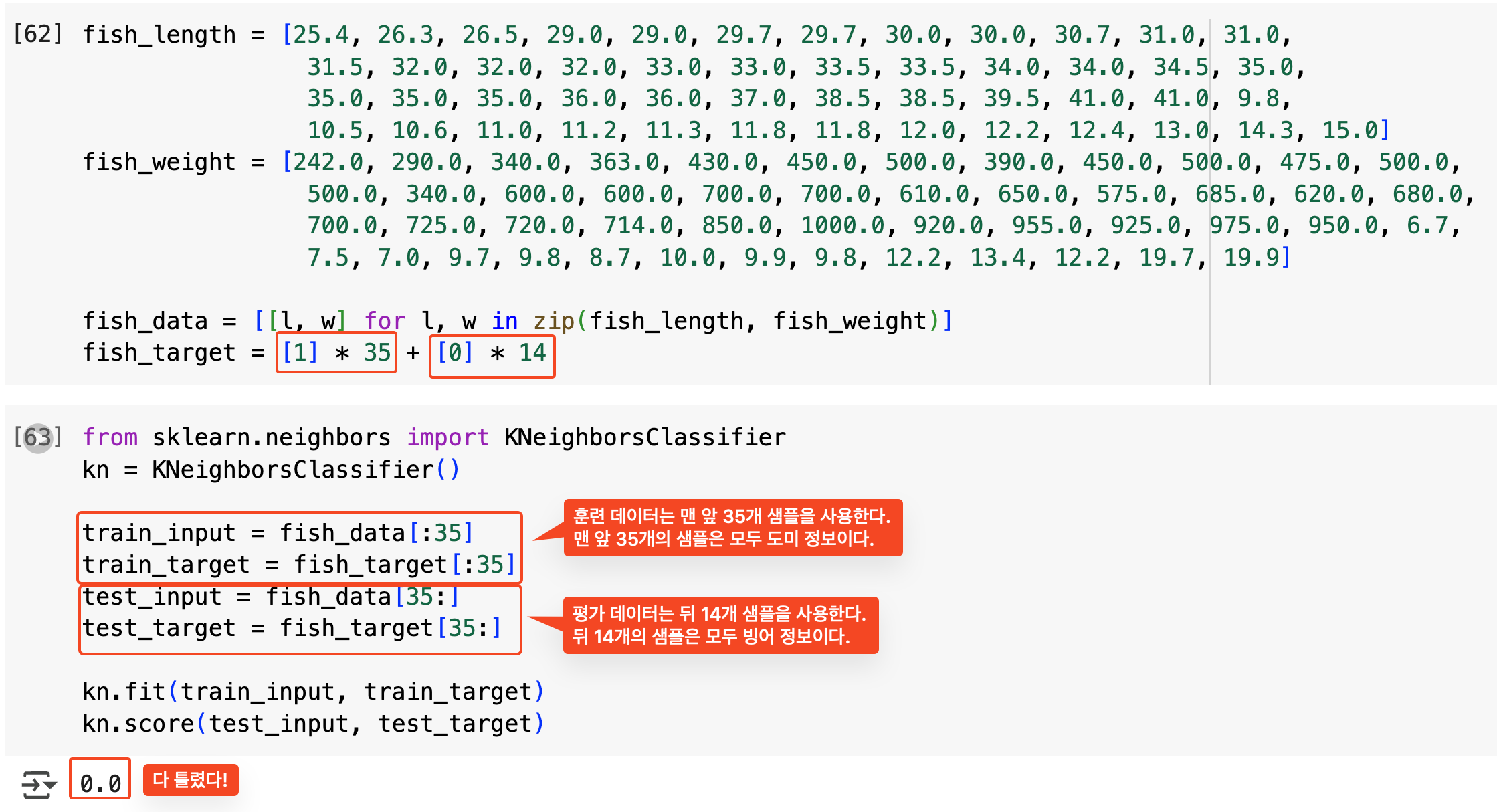
훈련하는 데이터에는 모두 도미 데이터만 넣고, 테스트 데이터에는 빙어 데이터만 넣었다. 그 결과 정확도가 0.0이 나왔다.
그 이유는 훈련 데이터셋에서 빙어 없이 모델 훈련을 했기 때문이다. 그러니 어떤 값이든 도미라고 판단하여 빙어만 있는 테스트 세트에서 정답률이 0이 되고 만 것이다.
numpy로 훈련 세트와 테스트 세트 나누기
아래와 같이 numpy를 사용하면 random shuffle이 가능하다. 이를 통해 앞서 언급한 샘플링 편향을 해결할 수 있다.

그리고 다시 한 번 맨앞 35개를 훈련 세트로, 뒤 14개를 평가 세트로 묶는다. 아래의 산포도에서 파란색이 훈련, 주황색이 평가 세트임을 확인할 수 있다. 골고루 잘 분포되어 있다!
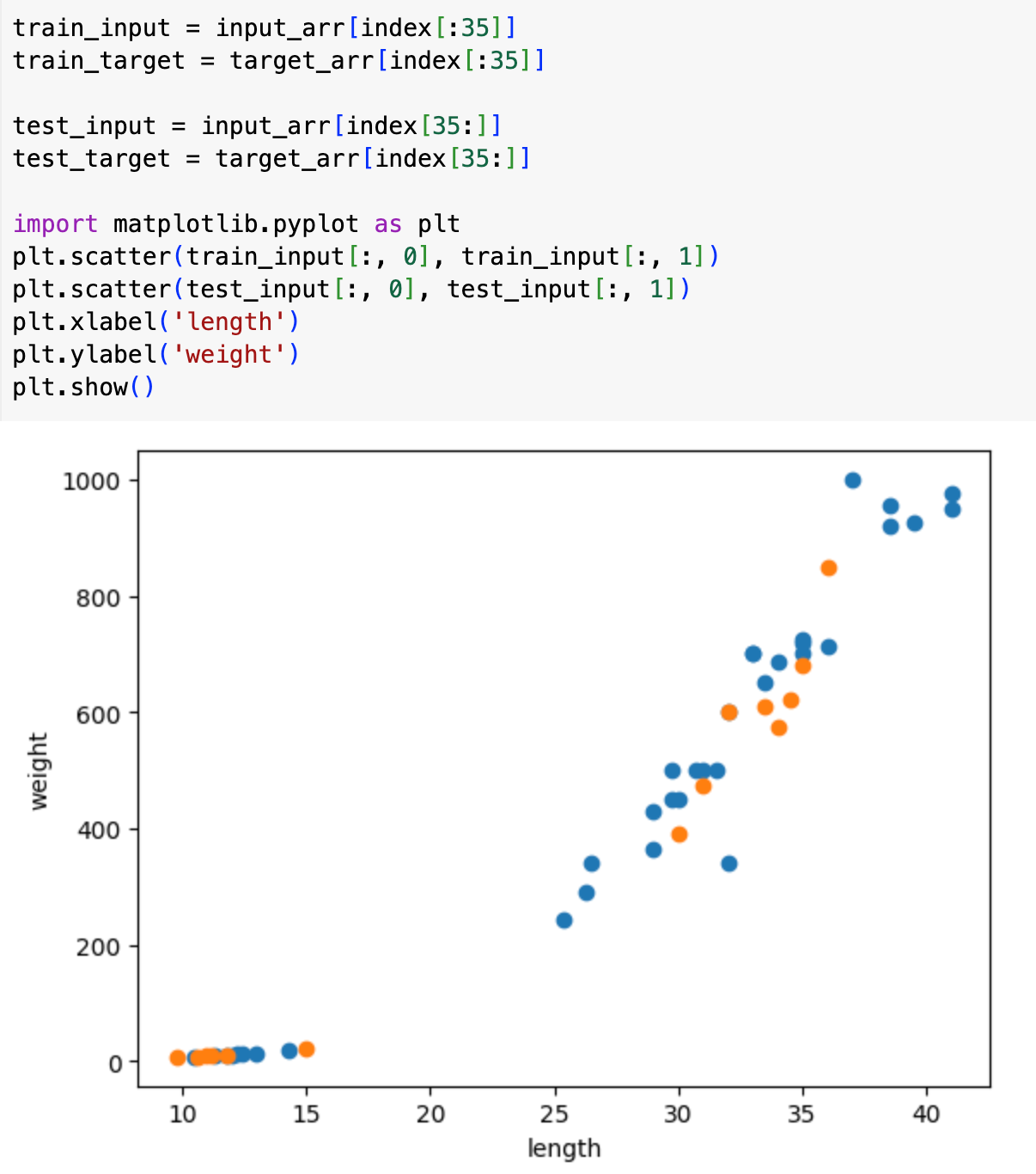
그리고 다시 훈련+평가를 돌리면 좋은 성능을 보여준다!

사이킷런으로 훈련 세트와 테스트 세트 나누기
사이킷런에서 제공하는 train_test_split을 활용하면 더 간단하게 해낼 수 있다.
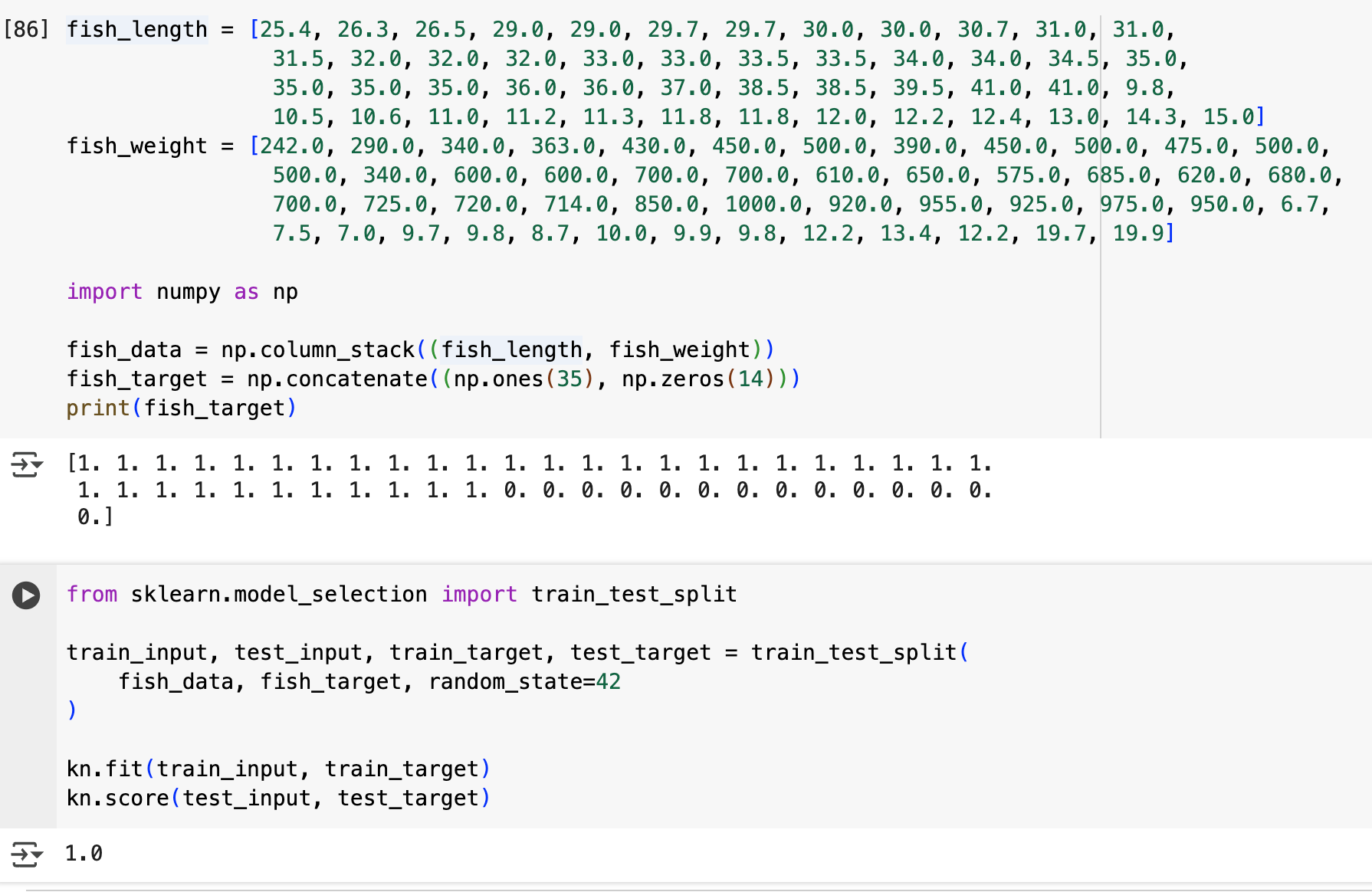
그런데 과연, 이 테스트 세트에 편향이 없을까?

전체 데이터에서의 도미와 빙어가 각각 35개, 14개이므로 2.5:1의 비율을 가지는데, 이 테스트 세트의 도미와 빙어의 비율은 10:3=3.3:1이다. 즉, 약간의 샘플링 편향이 발생했다.
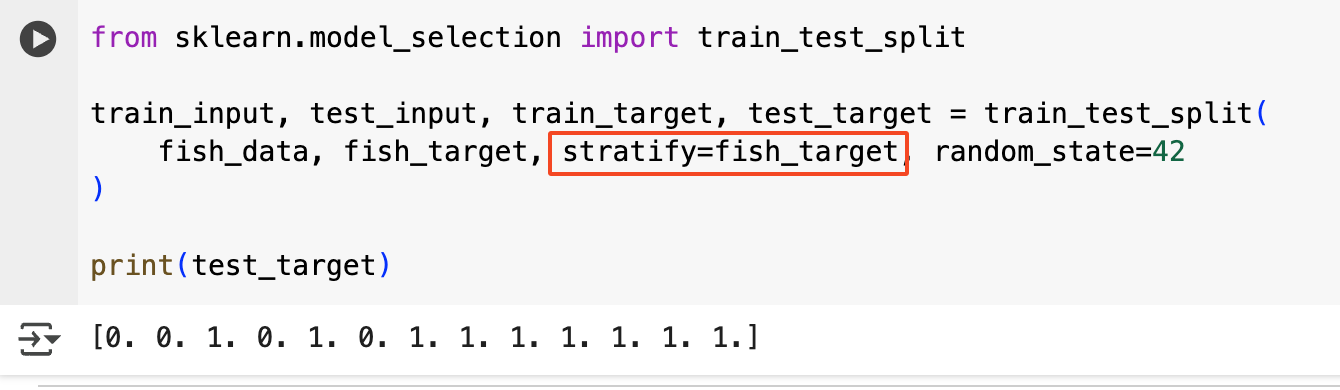
이를 해결하기 위해서 stratify 매개변수에 fish_target를 지정해주면 train_test_split이 비율을 맞춰준다.
데이터 전처리: 표준화의 필요성
기존의 X, Y 축은 각각의 단위가 달랐다. Y축은 한 칸에 200씩올라가는 반면, X축은 한 칸에 5씩이었다.
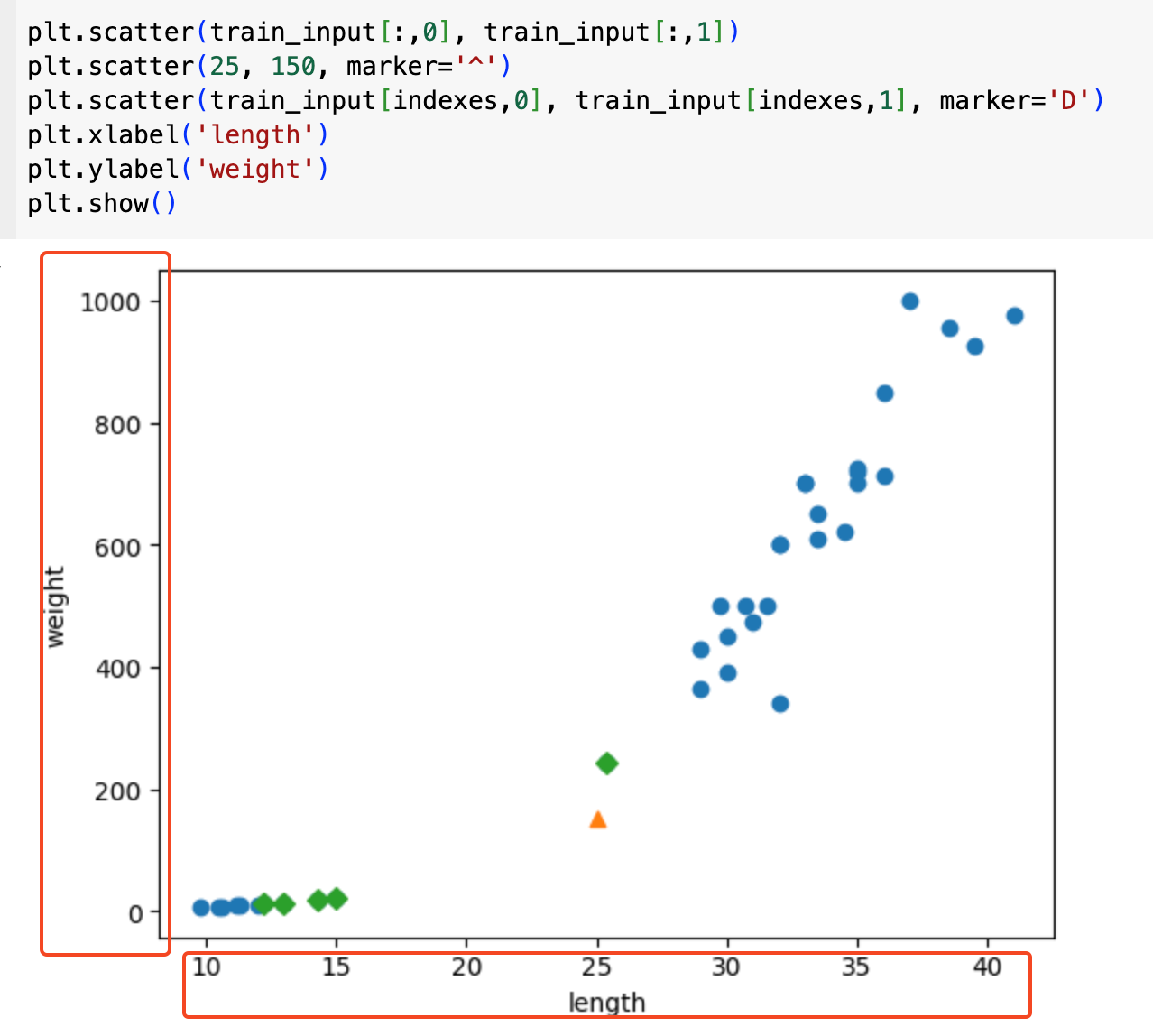
둘 다 1000까지 보이도록 정리해서 확인해보면 아래와 같다. 거의 일직선의 모습을 보이는데, 이는 length값은 거의 무시되고 weight값이 강한 영향을 준다는 의미이다.
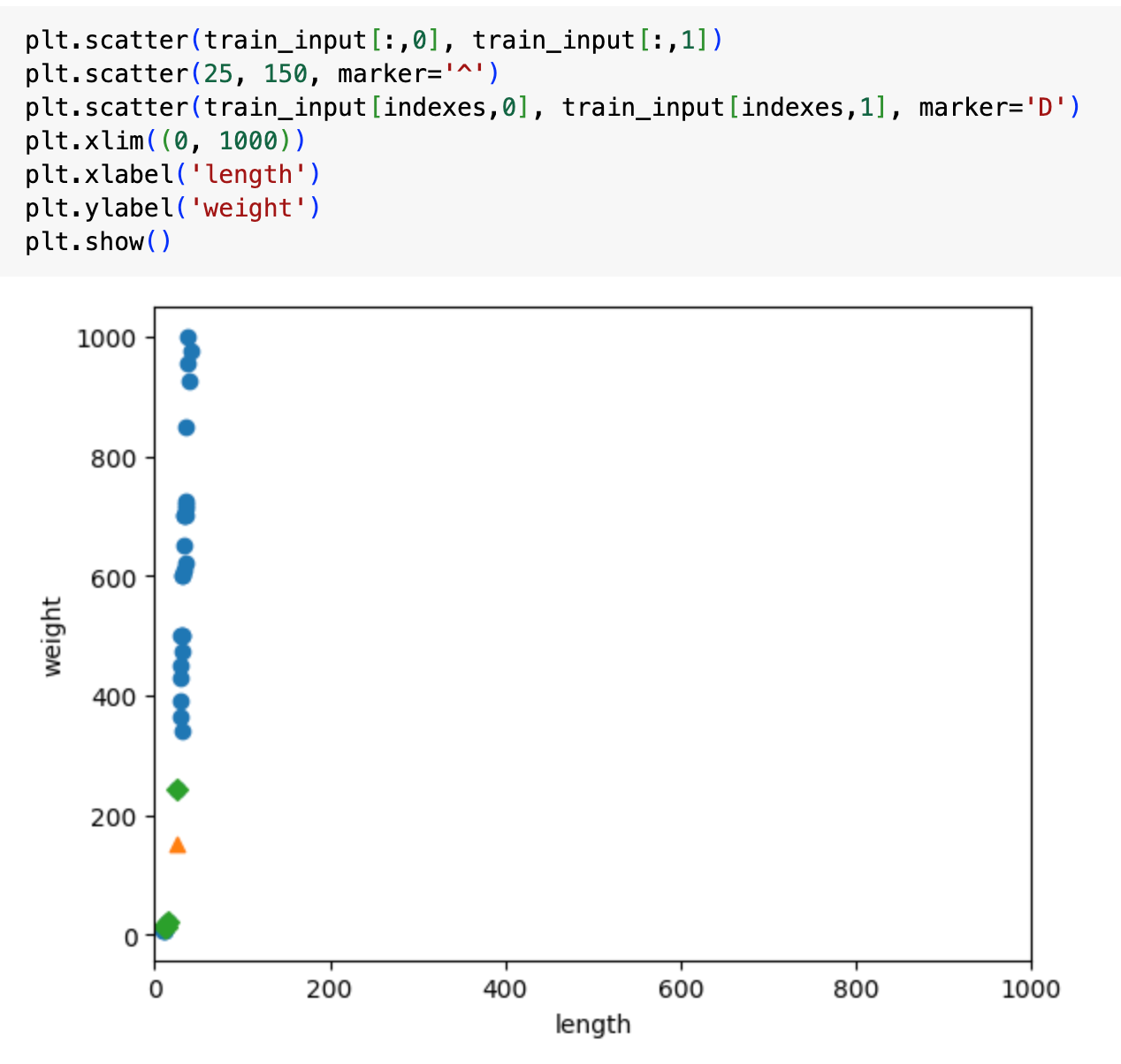
weight과 length가 공평하게 영향을 주도록 하기 위해 기준을 변경할 필요가 있는데, 이를 '데이터 전처리'라고 부른다.
데이터 전처리 방법 중 하나로 표준 점수(z-score)를 구할 수 있다.
- 표준편차: 데이터가 얼마나 분산되어 있는가를 나타내는 지표
- 표준점수: 원점에서 몇 표준편차만큼 떨어져 있는가를 나타내는 값 (z = (x - 평균) / 표준편차)
이는 numpy 함수들을 통해 손쉽게 구할 수 있다.
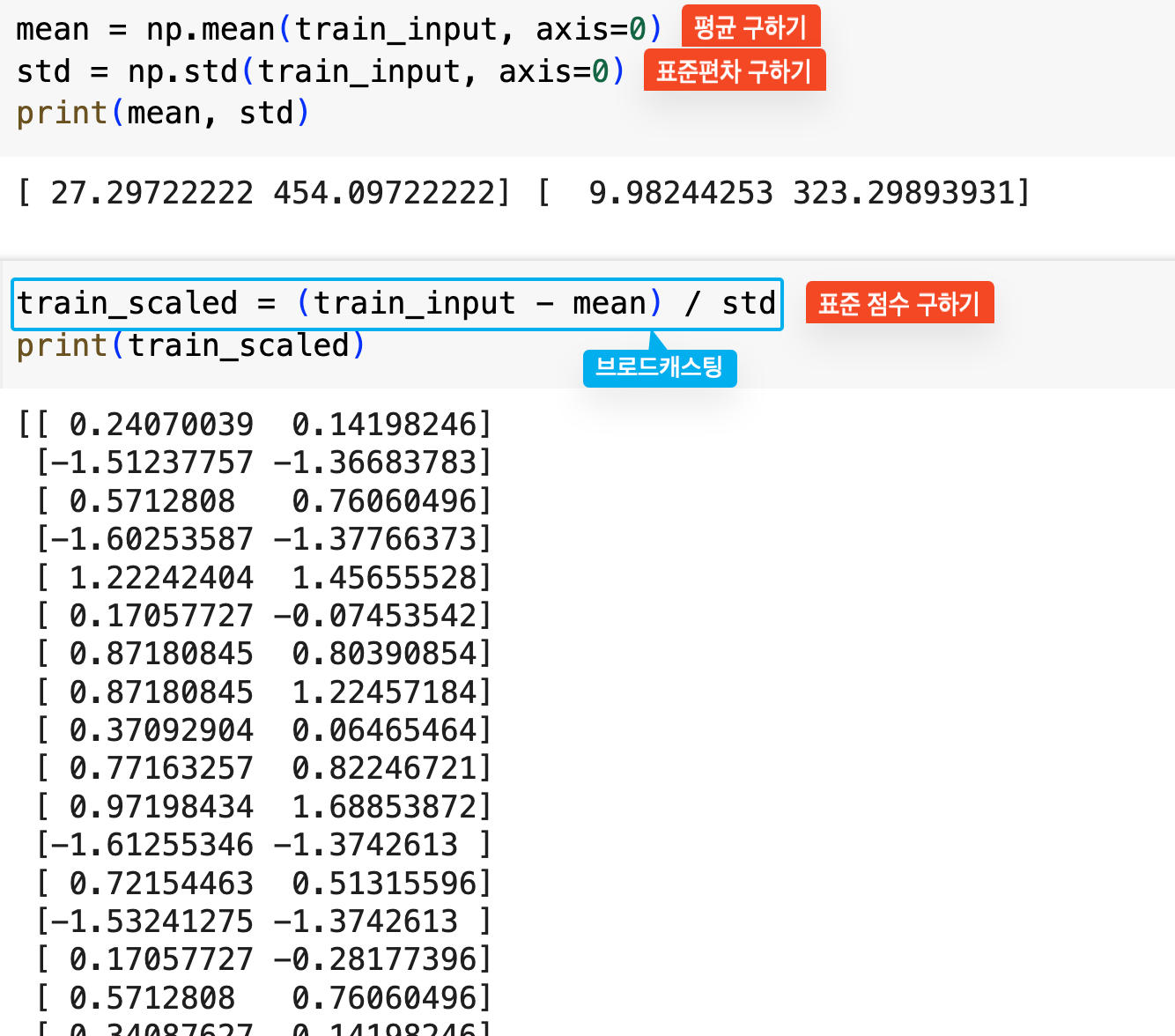
브로드캐스팅
train_input은 넘파이 배열 타입이다. 거기에서-mean을 하면, 상식상 에러가 나야할 것 같다. 2차원 배열(36*2)에서 1차원 배열(2)을 빼는거니까. 넘파이는 똑똑하게 각각의 행에 대해-mean을 해준다. (/std또한 마찬가지로 계산된다.) 이런 방식을 넘파이의 브로드캐스팅이라고 한다.
이렇게 만들어진 train_scaled를 사용하여 이전과 동일하게 모델을 훈련하고 평가해볼 수 있다.
부록: 확인문제 해설
2-1 확인문제에 대한 해설을 추가한다.
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
답) (1) 지도 학습- 지도 학습은 정답이 있는 상황, 비지도 학습은 정답이 없는 상황
- 위의 도미 빙어 예제는 지도 학습의 한 예시이다.
- 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
답) (4) 샘플링 편향- 해설 불필요
- 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
답) (2) 행: 샘플, 열: 특성(피쳐)- 사이킷런을 비롯한 대부분의 머신러닝 라이브러리는 데이터가 행렬 형태로 정리되어 있을 것으로 기대한다. 각 행(row)은 하나의 샘플(데이터 포인트)을 나타내고, 각 열(column)은 하나의 특성(피쳐)을 나타낸다. 예를 들어, 생선 데이터의 경우 각 행은 하나의 생선을, 각 열은 길이와 무게라는 특성을 나타낸다. 이런 구조를 따라야 사이킷런의 함수들이 올바르게 작동한다.
