ℹ️ <혼자 공부하는 머신러닝+딥러닝> 책을 읽고 정리한 내용입니다.
결정 트리
머신 러닝 모델은 블랙박스로 느껴진다. 이를테면 로지스틱 회귀에서도 각 피쳐에 대한 가중치(a,b,c) 등이 어떻게 나왔는가를 묻는다면, 그건 모델이 학습하면서 결정한 계수다, 라는 말 밖엔 못 한다. (수학 식을 설명한다고 해서 그 질문을 한 비전문가를 납득시키긴 어려울거다.)
이에 비해 결정 트리는 비교적 비전문가에게도 설명하기 쉬운 모델을 만든다.
결정 트리는 마치 스무고개 같은 느낌이다.
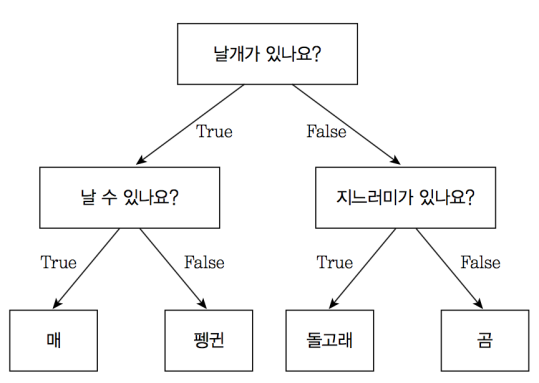
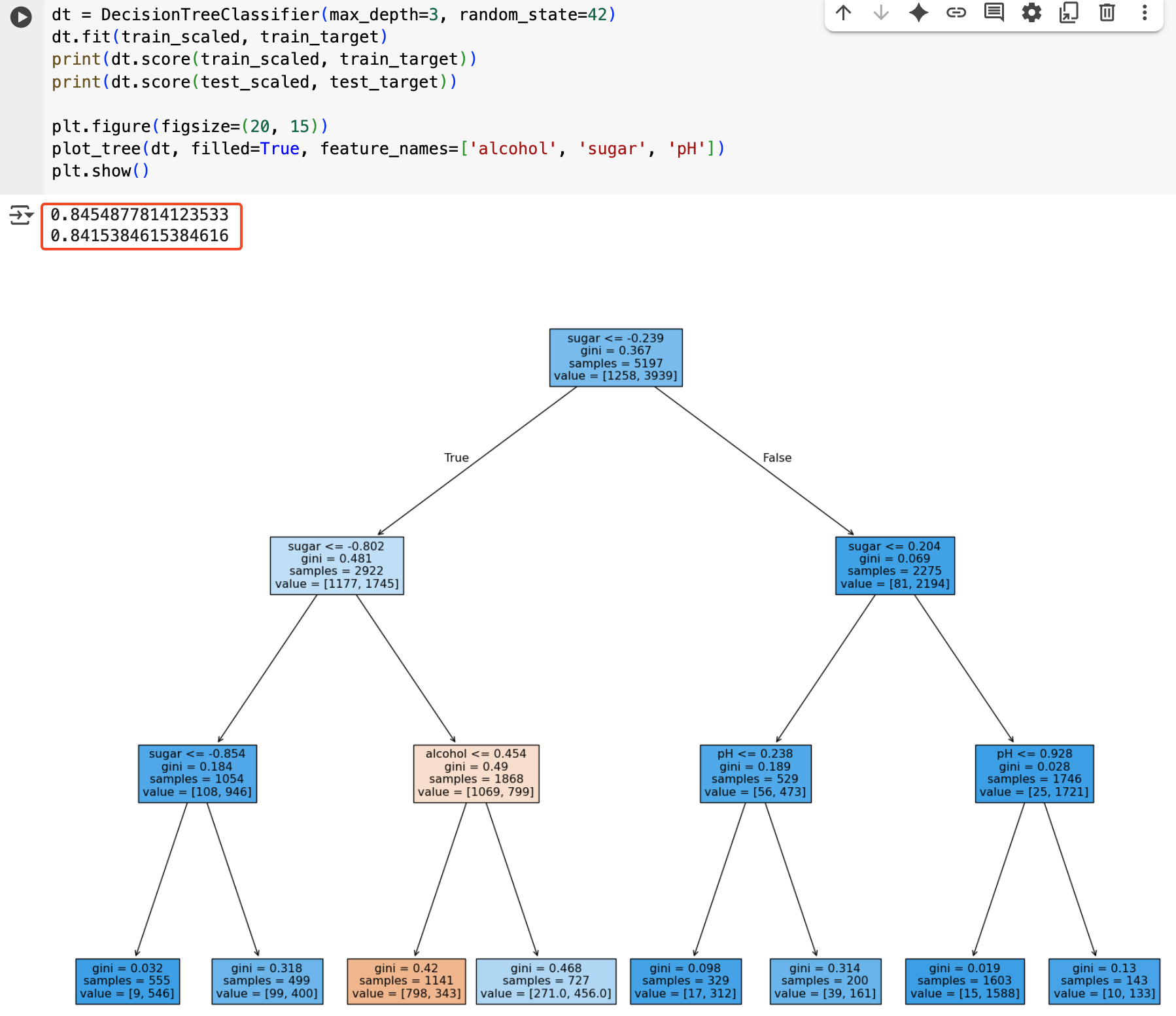
실제로 코드로 구현해보면 아래와 같은 모양이 나온다

트리에 어떤 내용이 있는지 좀 더 자세히 살펴보면 아래와 같다
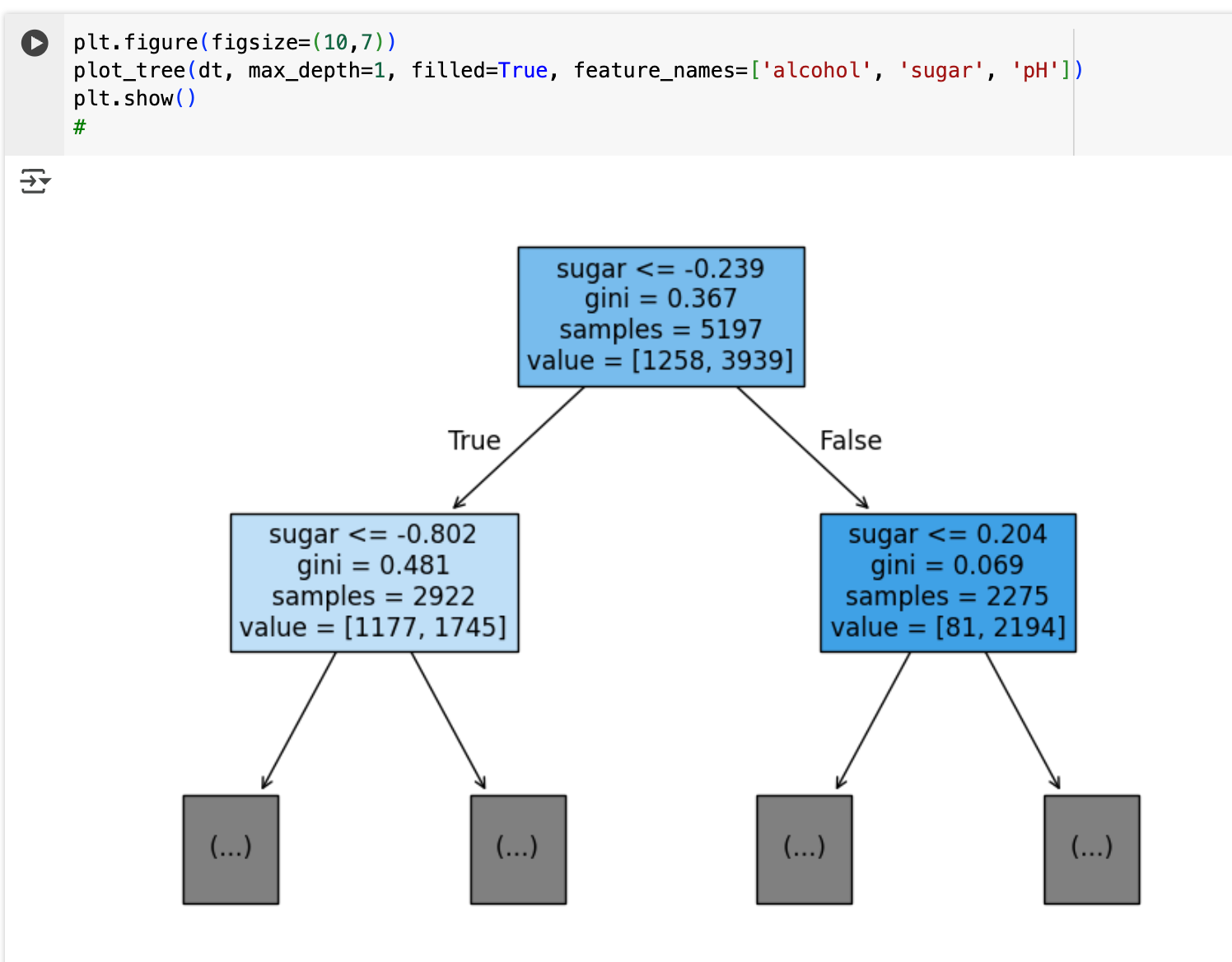
sugar <= .0239를 기준으로 왼쪽과 오른쪽으로 나뉜다.
왼쪽은 sugar값이 .0239 이하인 그룹, 오른쪽은 초과인 그룹이다. 그 비율은 value=[1258, 3939]에 나와있는데, .0239 이하인 그룹이 1258개인 것이고, 초과인 그룹이 3939개라는 의미이다.
그럼 해당 노드가 레드와인 클래스인지 화이트와인 클래스인지는 어떻게 알 수 있을까? 각 노드에서 가장 많은 개수를 가진 클래스가 해당 노드의 예측 클래스가 된다. 위의 예제에서 샘플 5197개 중 레드와인이 1258개, 화이트와인이 3939개인 상황이므로, 화이트 와인 클래스 노드가 된다.
지니 불순도
위 트리를 분석해보면, gini라는 값이 있다. 이건 뭘까?
gini는 '지니 불순도' 값을 의미한다.
지니 불순도는 노드의 불순정도를 측정하는 지표로, 쉽게 말해 한 노드에 서로 다른 클래스들이 얼마나 섞여 있는지를 나타내는 값이다.
지니 불순도의 의미는 아래와 같다.
- 0에 가까울수록: 노드가 순수함 (한 클래스만 있거나 압도적으로 많음)
- 0.5에 가까울수록: 노드가 불순함 (여러 클래스가 비슷한 비율로 섞여 있음)
불순도 값은 이 공식으로 계산된다: Gini = 1 - Σ(pi)² (pi는 각 클래스 i가 해당 노드에서 차지하는 비율이다.)
직접 계산해보자. 위 트리에서 루트 노드를 보면 value=[1258, 3939]라고 되어 있다.
- 전체 샘플 수: 1258 + 3939 = 5197
- 클래스 0(레드와인) 비율: p₀ = 1258/5197 ≈ 0.242
- 클래스 1(화이트와인) 비율: p₁ = 3939/5197 ≈ 0.758
지니 불순도 = 1 - (0.242² + 0.758²) = 1 - (0.058 + 0.575) = 0.367
이로써 루트 노드의 gini=0.367을 이해할 수 있게 되었다.
실제로 결정 트리는 각 분할에서 지니 불순도를 최대한 감소시키는 방향으로 나눈다. 분할 후 지니 불순도가 크게 줄어들수록 좋은 분할이며, 이렇게 해서 점점 더 순수한 노드를 만들어간다. 최종적으로 리프 노드에서는 한 클래스가 압도적으로 많은 상태로 만드는 것이 목표이다.
가지치기
위의 방식으로 결정 트리 기반 훈련을 진행한 결과, 테스트 값이 아직 한참 못 미치는 걸 볼 수 있다. 이러한 상황을 '일반화가 잘 안 되었다'고 한다.
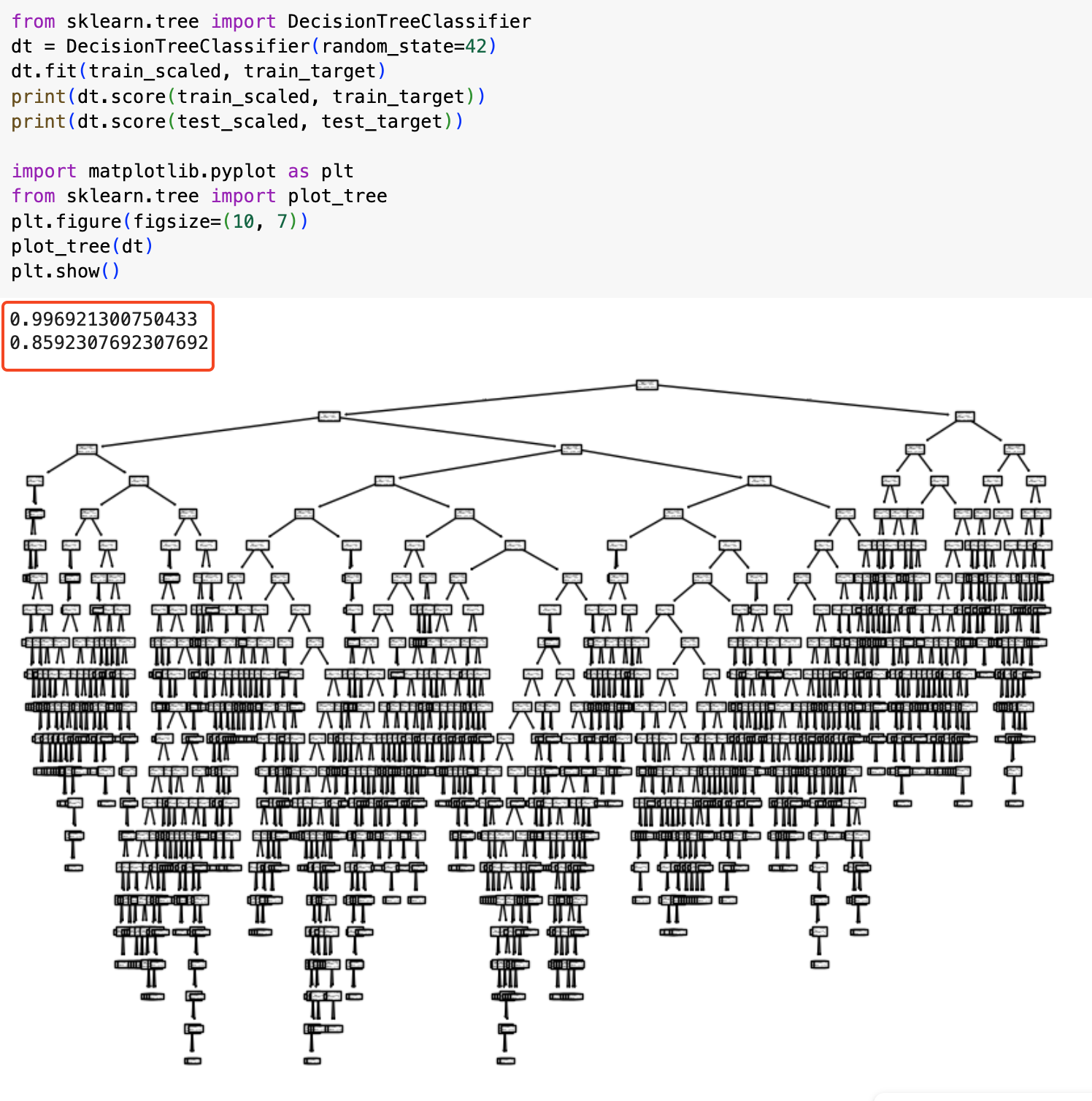
가지치기를 통해 결정 트리에서 자라날 수 있는 트리의 최대 깊이를 지정해볼 수 있다.
아래 코드는 max_depth=3으로 최대 길이를 설정한 결과이다.
나름 잘 훈련과 테스트 평가 수치가 비슷하게 나오는 걸 알 수 있다.
교차 검증
최적의 모델을 찾기 위해 다양한 모델을 만들고 각각을 테스트 세트로 평가하여 가장 높은 점수를 얻은 모델을 선택하려는 시도는 일반적인 접근 방식이다.
하지만 이 과정이 반복될수록, 선택된 모델은 결국 테스트 세트에만 너무 잘 맞는 결과를 낳을 수 있다. 이는 우리가 테스트 세트의 결과를 보고 더 좋은 모델을 '선택'하는 과정 자체가, 마치 테스트 세트에 대한 간접적인 '학습'처럼 작용하여 특정 테스트 세트의 패턴이나 노이즈에 과도하게 최적화되기 때문이다. 즉, 모델의 진정한 일반화 성능을 왜곡할 수 있다.
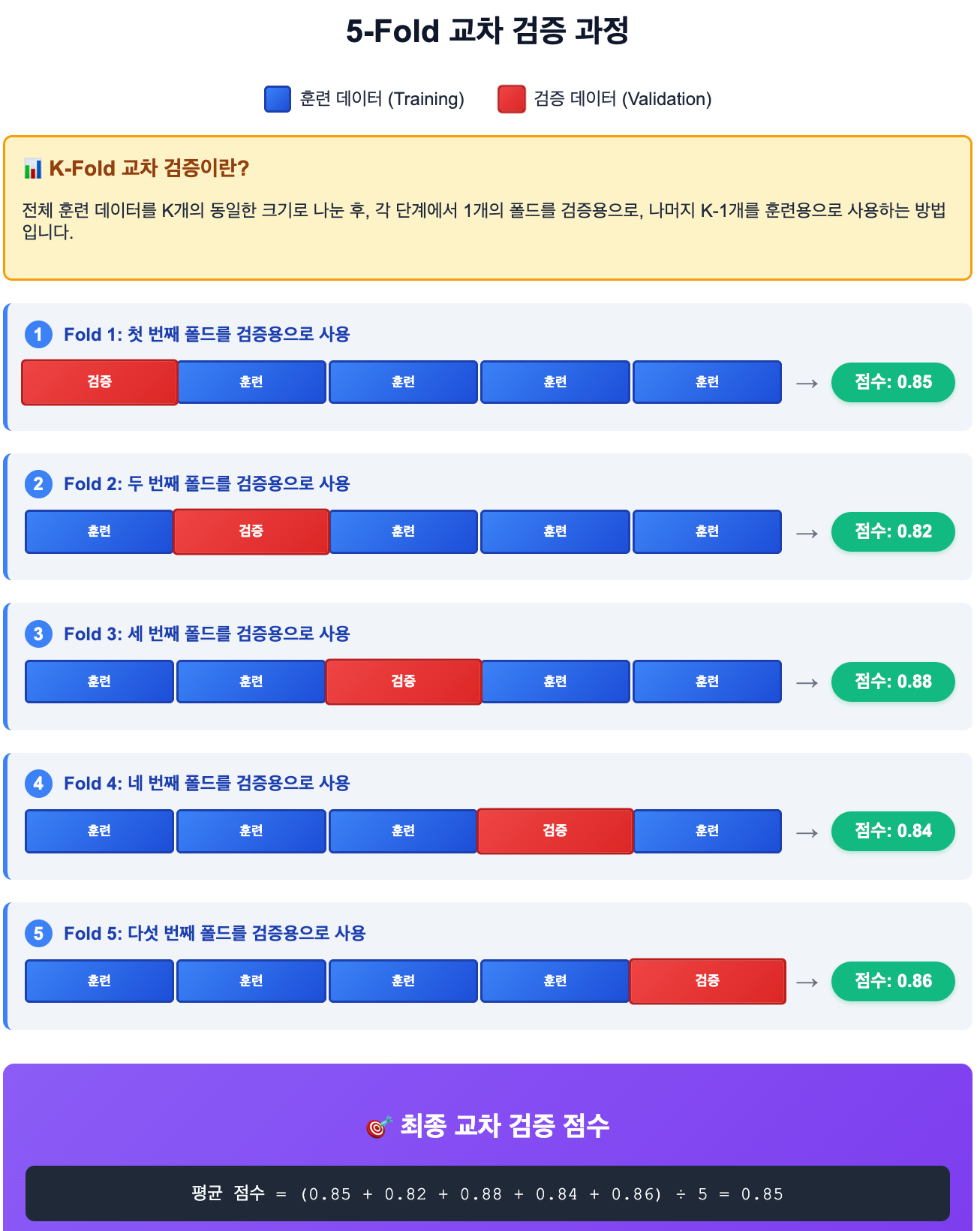
이러한 문제를 해결하기 위해 '교차 검증' 기법을 활용해볼 수 있다. 교차 검증은 훈련 데이터를 여러 부분으로 나누어 모델을 훈련하고 평가하는 과정을 반복함으로써, 특정 데이터셋에 과적합되는 위험을 줄이고 모델의 성능을 더욱 견고하게 측정하는 방법이다.
교차 검증은 훈련 세트의 일부를 검증 세트로 만들어 점수를 내는 방식을 여러 번 반복한다. 최종적으로는 검증 세트 점수의 평균을 도출한다.
그 중에서도 K-Fold 교차 검증 방식이 대표적이다. 다음은 5-Fold 교차 검증 방식에 대한 예시이다.
하이퍼파라미터 튜닝
용어부터 잡고 넘어가자
- 모델 파라미터: 머신러닝 모델이 학습하는 파라미터
- 하이퍼파라미터: 모델이 학습할 수 없어서 사용자가 직접 지정해야하는 파라미터
이러한 하이퍼파라미터를 튜닝하는 작업은 매개변수를 조금씩 바꿔가며 모델을 훈련하고 교차 검증을 수행하여 진행된다.
만약 매개변수가 많아진다면 상황은 조금 더 복잡해진다. 아마 이런식이 되지 않을까
for i in (매개변수 A후보):
for j in (매개변수B 후보):
for k in (매개변수C 후보):
# ... 이런식으로 모든 경우를 탐색해 최적의 매개변수 조합 찾기사이킷런의 GridSearchCV 클래스를 활용하면 편리하게 이 일을 해낼 수 있다.
과정은 아래와 같다.
1. 탐색할 매개변수를 지정한다.
2. 훈련 세트에서 그리드 서치를 수행하여 최상의 평균 검증 점수가 나오는 매개변수 조합을 찾는다.
3. 그리드 서치는 최상의 매개변수에서 (교차 검증에 사용한 훈련 세트가 아니라) 전체 훈련 세트를 사용해 최종 모델을 훈련한다.
이 방식은 한 가지 아쉬운 점이 있는데, '탐색할 매개변수 집합'을 어떻게 만드느냐가 애매할 수 있다는 점이다. 하지만 휴먼으로서 그 적정 선이 짐작가지 않을 수 있다.
이런 상황에선 '랜덤 서치'를 사용할 수 있다. 랜덤 서치에서는 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률분포 객체를 전달한다.
트리의 앙상블
정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 '앙상블 학습'이다.
정형 데이터란?
- 어떠한 구조로 되어 있다는 의미. csv, db, exel 등에 정리하기 쉬움
- 반대로 어떠한 구조로 정리하기 어려운 데이터를 '비정형 데이터'라고 한다.
- 글 같은 텍스트 데이터, 디지털 카메라로 찍은 사진, 음악 등이 모두 비정형 데이터이다.
참고로, 이런 비정형 데이터는 규칙성을 찾기 어려워 전통적인 머신러닝 방법으로는 모델을 만들기 까다롭다. 이러한 비정형 데이터는 '신경망 알고리즘'을 사용하면 굿.
그렇다면 '앙상블 학습'이라는 게 구체적으로 무엇인가?
'앙상블'이라는 단어는 원래 '합창단'이나 '총체', '조화'를 의미하는 프랑스어에서 유래했다고 한다. 여러 악기가 모여 조화로운 음악을 만들 듯, 앙상블 학습은 단 하나의 모델을 사용하는 대신, 여러 개의 머신러닝 모델을 만들고 이 모델들의 예측을 종합하여 최종 결정을 내리는 방법이다.
랜덤 포레스트
랜덤 포레스트라는 이름에서 유추해보자
- 랜덤: 랜덤하게 무언갈 만든다
- 포레스트: 숲. 나무의 집합
다시 말해 결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만드는 방법이다.
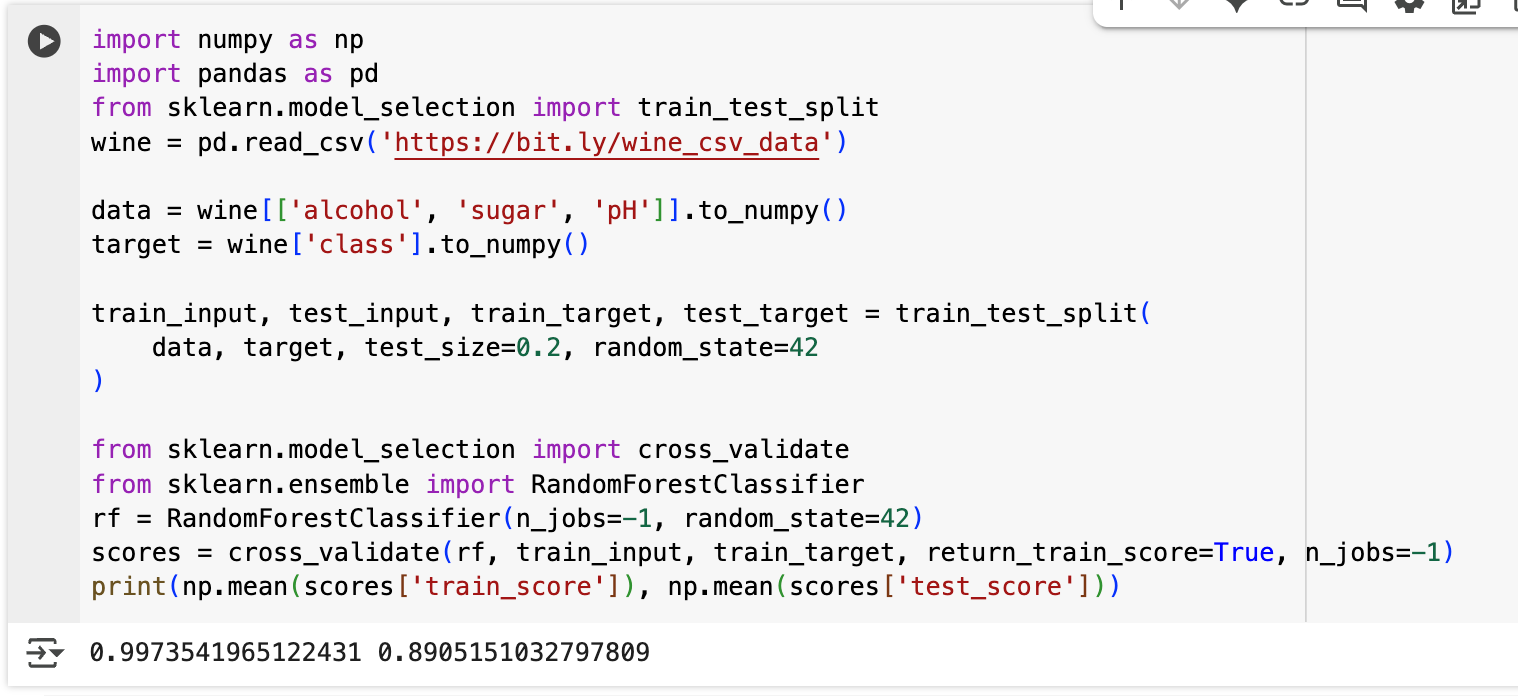
사이킷런의 랜덤 포레스트 동작 방식은 다음과 같다.
- 훈련 데이터로 1000개의 샘플이 있는 경우, 중복하여 1000개의 샘플을 랜덤으로 뽑는다. 이렇게 만들어진 샘플을 '부트스트랩 샘플'이라고 한다.
- 부트스트랩 샘플을 기반으로 결정 트리를 훈련한다.
- 또한 트리 내부에서도 노드를 분할할 때 '루트 특성 개수' 만큼을 랜덤하게 선택하여 사용한다.
- 사이킷런의 랜덤 포레스트는 기본적으로 100개의 결정 트리를 이러한 방식으로 훈련한다.
이 모델을 평가할 아주 좋은 방법이 있는데, 바로 OOB 샘플을 활용하는 것이다.
OOB(Out Of Bag) 샘플이란, RandomForestClassifier가 중복을 허용한 부트스트랩을 만들어 결정 트리를 훈련하는 과정에서 부트 스트랩 샘플에 포함되지 않은 남는 샘플을 의미한다.
이 샘플들을 활용하여 점수를 얻어볼 수 있다.

엑스트라 트리
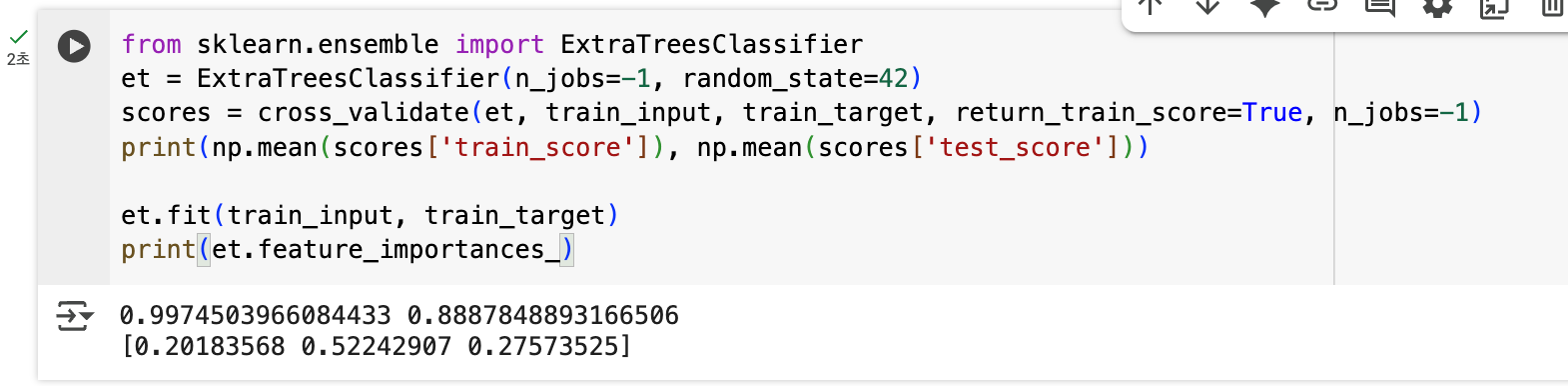
엑스트라 트리(Extra Tree)는 'Extremely Randomized Trees'의 줄임말로, 랜덤 포레스트보다 한 단계 더 무작위성을 강화한 앙상블 방법이다.
랜덤 포레스트와 엑스트라 트리의 차이점:
- 부트스트랩 샘플링: 랜덤 포레스트는 중복을 허용하여 부트스트랩 샘플을 만들지만, 엑스트라 트리는 전체 훈련 세트를 그대로 사용한다.
- 노드 분할 방식: 랜덤 포레스트는 특성을 무작위로 선택한 후, 그 중에서 최적의 임계값을 찾는다. 반면 엑스트라 트리는 특성뿐만 아니라 임계값까지도 무작위로 선택한다.
이러한 극단적인 무작위성 덕분에:
- 과대적합을 더 효과적으로 방지할 수 있다
- 계산 속도가 더 빠르다 (최적 임계값을 찾을 필요가 없으므로)
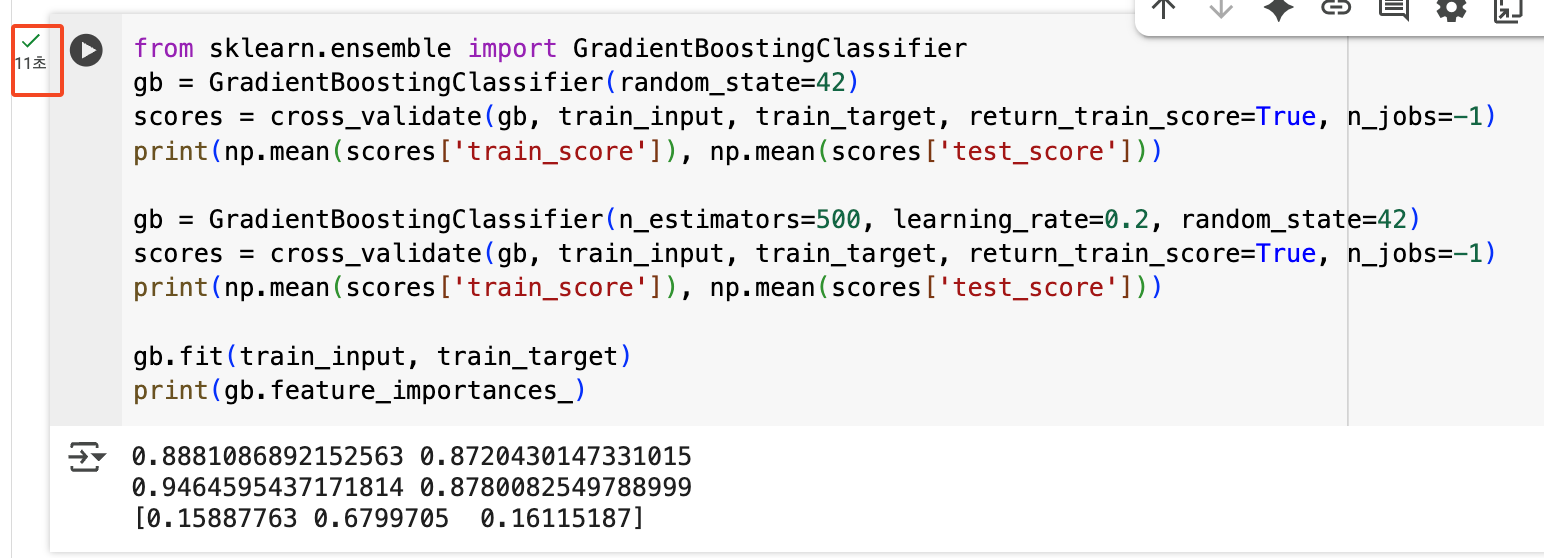
그레이디언트 부스팅
그레이디언트 부스팅(Gradient Boosting)은 랜덤 포레스트와는 완전히 다른 접근 방식의 앙상블 학습이다.
부스팅의 핵심 아이디어:
- 여러 모델을 병렬로 독립적으로 만드는 랜덤 포레스트와 달리, 부스팅은 이전 모델의 오차를 보완하는 새로운 모델을 순차적으로 추가한다.
- 즉, 앞선 모델이 틀린 부분을 다음 모델이 더 잘 맞추도록 학습한다.
여기서 '그레이디언트'라는 이름이 붙은 이유는 경사하강법에서 사용하는 그래디언트(기울기) 개념을 활용하기 때문이다. 경사하강법과 유사하게, 그레이디언트 부스팅도 손실 함수의 그래디언트 방향으로 모델을 점진적으로 개선해 나간다.
그레이디언트 부스팅의 동작 과정:
- 첫 번째 결정 트리로 훈련 세트를 훈련한다.
- 손실 함수(예: 평균제곱오차)의 그래디언트(경사)를 계산한다. 이는 각 샘플에 대해 "어느 방향으로 얼마나 개선해야 하는지"를 나타낸다.
- 이 그래디언트를 새로운 타겟으로 하여 두 번째 결정 트리를 훈련한다.
- 경사하강법처럼 손실 함수를 최소화하는 방향으로 모델을 업데이트한다.
- 이 과정을 반복하여 여러 개의 트리를 순차적으로 추가한다.
- 최종 예측은 모든 트리의 예측을 더한 값이다.
특징:
- 보통 깊이 3정도의 얕은 트리를 사용한다.
- 순차적으로 학습하므로 병렬처리가 어려워 속도가 느리다.
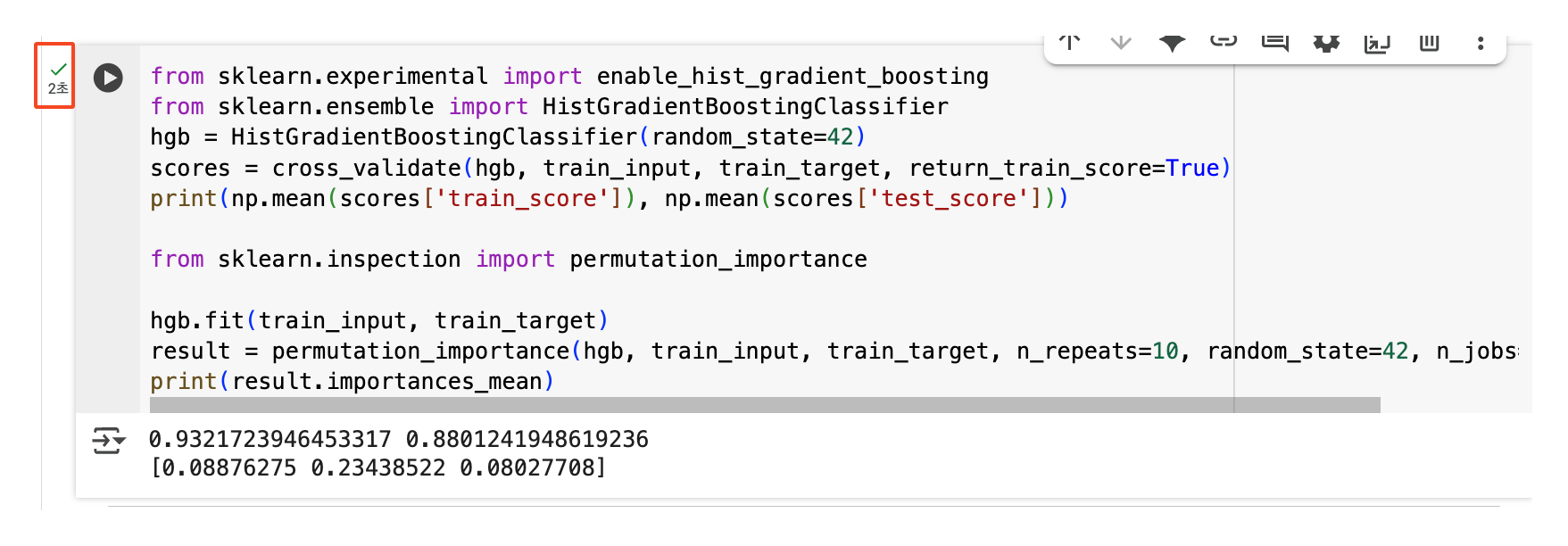
실제로 실행되는 시간을 살펴보니 아래와 같이 11초로 꽤나 걸리는 모습을 확인할 수 있었다.
히스토그램 기반 그레이디언트 부스팅
- 기존 그레이디언트 부스팅의 속도 문제를 해결한 개선된 버전이다.
아래와 같이 2초로 확실히 11초일 때보다 속도가 개선된 점을 확인할 수 있다.