📌 What is Knowledge Distilation??
최근 딥러닝 모델은 극도로 복잡하고 거대한 파라미터를 갖는 경향이 있습니다. 이러한 대규모 모델(예: 수십, 수백 개의 레이어를 갖는 DNN, 초거대 언어모델 등)은 뛰어난 성능을 보여주지만, 실제 서비스 환경에서 바로 적용하기 어렵습니다. 서비스 환경에서는 추론 속도, 메모리 사용량, 배포 비용 등의 현실적인 제약사항이 있기 때문입니다.
이런 문제를 해결하기 위한 한 가지 대표적인 기술이 바로 지식증류(Knowledge Distillation)입니다. 지식증류는 "성능은 뛰어나지만 무겁고 복잡한 모델(교사 모델)이 학습해낸 '지식'을, 더 가볍고 단순한 모델(학생 모델)이 이어받아 효율적인 형태로 구현하는 기법"이라 할 수 있습니다.
🤷 왜 지식증류가 필요한가?
대규모 모델은 높은 예측 정확도를 달성하지만, 아래와 같은 단점이 존재합니다.
1. 모델 크기와 추론 시간 부담: 수억 개 이상의 파라미터를 가진 모델은 한 번 추론에 상당한 연산 자원을 필요로 합니다. 이는 모바일 기기나 임베디드 환경에서는 비효율적이며, 서버 비용 상승으로 이어질 수 있습니다.
2. 실시간 서비스 적용의 어려움: 딥러닝 모델이 실제 프로덕션 레벨에서 사용되려면 지연 시간(Latency) 최소화가 중요합니다. 지나치게 복잡한 모델은 응답 속도가 떨어질 가능성이 큽니다. 특히 실시간으로 결과를 내놓아야 하는 환경에서는 속도를 높이는 것이 매우 중요합니다.
지식증류는 이러한 현실적 제약 속에서 대규모 모델 수준의 성능을 경량 모델로 구현하는 솔루션으로 주목받고 있습니다.
지식증류의 핵심 개념
지식증류의 핵심 아이디어는 다음과 같습니다.
-
교사 모델(Teacher Model): 미리 학습된, 크고 정확한 모델. 예를 들어, 대규모 CNN(ResNet-152 등) 또는 Transformer 기반 모델.
-
학생 모델(Student Model): 구조적으로 더 단순하고, 파라미터 수도 적은 모델(MobileNet, SqueezeNet, DistilBERT 등).
지식증류는 교사 모델이 만들어내는 출력 확률 분포(Soft Target Distribution)를 학생 모델이 학습하도록 합니다. 전통적인 지도학습에서는 원-핫(one-hot) 형태의 레이블만 사용하지만, 교사 모델의 소프트 타겟은 "정답 외의 클래스 관계"에 대한 정보를 담고 있습니다.
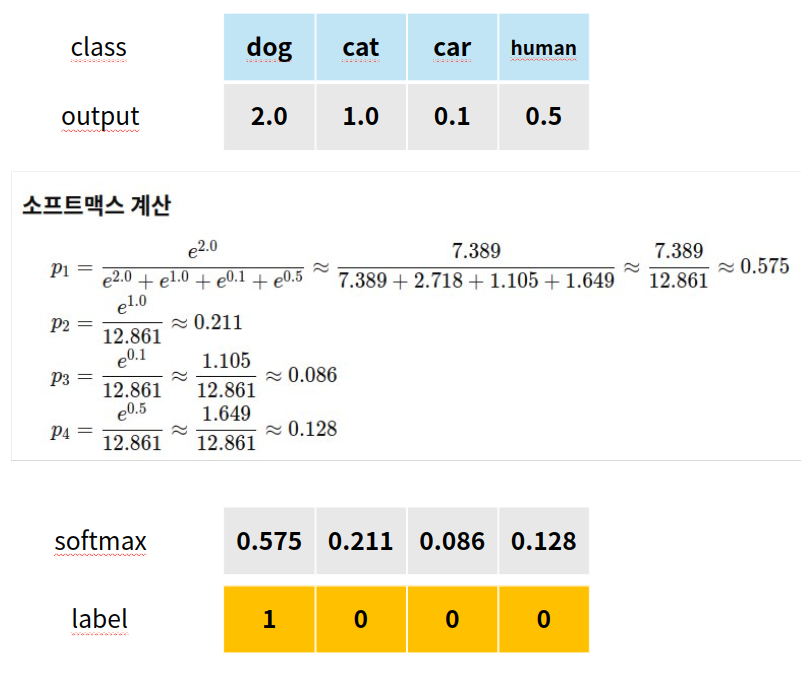
예를 들어보겠습니다. 위 사진은 모델의 출력을 softmax를 통해 확률로 변환해줍니다. 전통적인 지도학습에서는 softmax의 값이 가장 큰 dog를 정답으로 예측합니다.
이때, 교사 모델은 단순히 정답만 보는게 아닌, 정답과 다른 클래스간의 관계를 보여줍니다.
고양이(0.211), 자동차(0.086), 사람(0.128) 와 같은 분포를 통해, 정답인 dog와 고양이가 특징이 비슷하다는 걸 알 수 있습니다. 반대로 자동차는 확률이 매우 적으므로 dog와 매우 다르다는 정보를 습득할 수 있습니다. 학생 모델은 이를 학습하면서 클래스 간 상관관계나 난이도를 자연스럽게 습득하게 됩니다.
그런데, 학습이 잘 된 교사 모델의 softmax 결과는 정답이 아닌 class에 대해 매우 낮은 확률을 주게 됩니다. 따라서 학생 모델에게 정보가 잘 전달되지 않습니다.
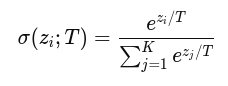
따라서 기존 softmax 수식에서 T(온도)를 추가하여 부드러운 확률 분포를 얻게 해줍니다.
지식증류의 동작 원리
-
교사 모델 학습: 대규모 모델(교사 모델)을 대용량 데이터셋으로 충분히 학습합니다.
-
교사 모델 출력 확보: 학습된 교사 모델로부터 학습 데이터(또는 추가 데이터)에 대한 예측 확률 분포를 얻습니다.
-
학생 모델 학습: 학생 모델은 정답 레이블 외에도 교사 모델의 소프트 타겟 분포를 참고하여 학습합니다. 이를 통해 학생 모델은 교사 모델에 담긴 지식을 간접적으로 전달받아 성능을 향상시킬 수 있습니다.
이 과정을 통해 학생 모델은 교사 모델의 지식을 압축해 이어받아, 상대적으로 경량화된 모델 구조로도 높은 성능을 달성하게 됩니다.
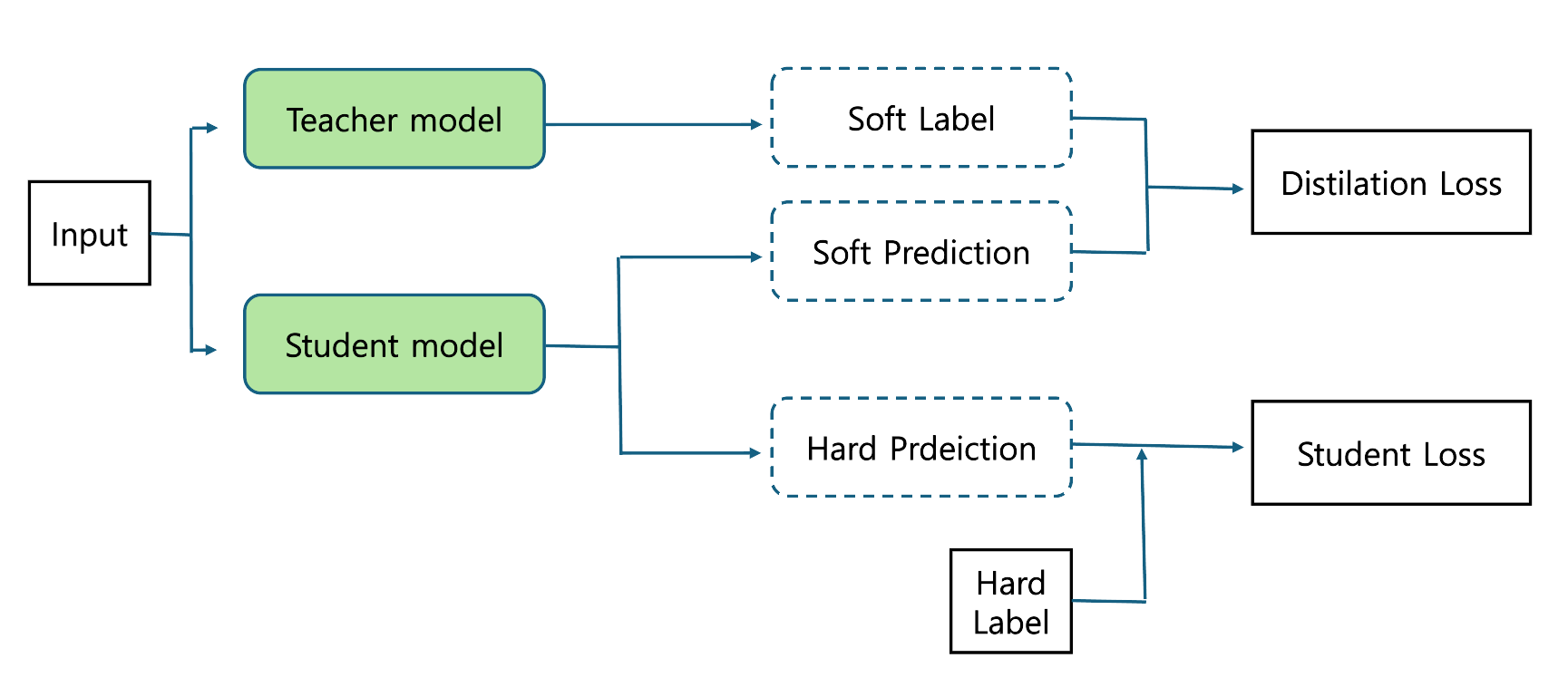
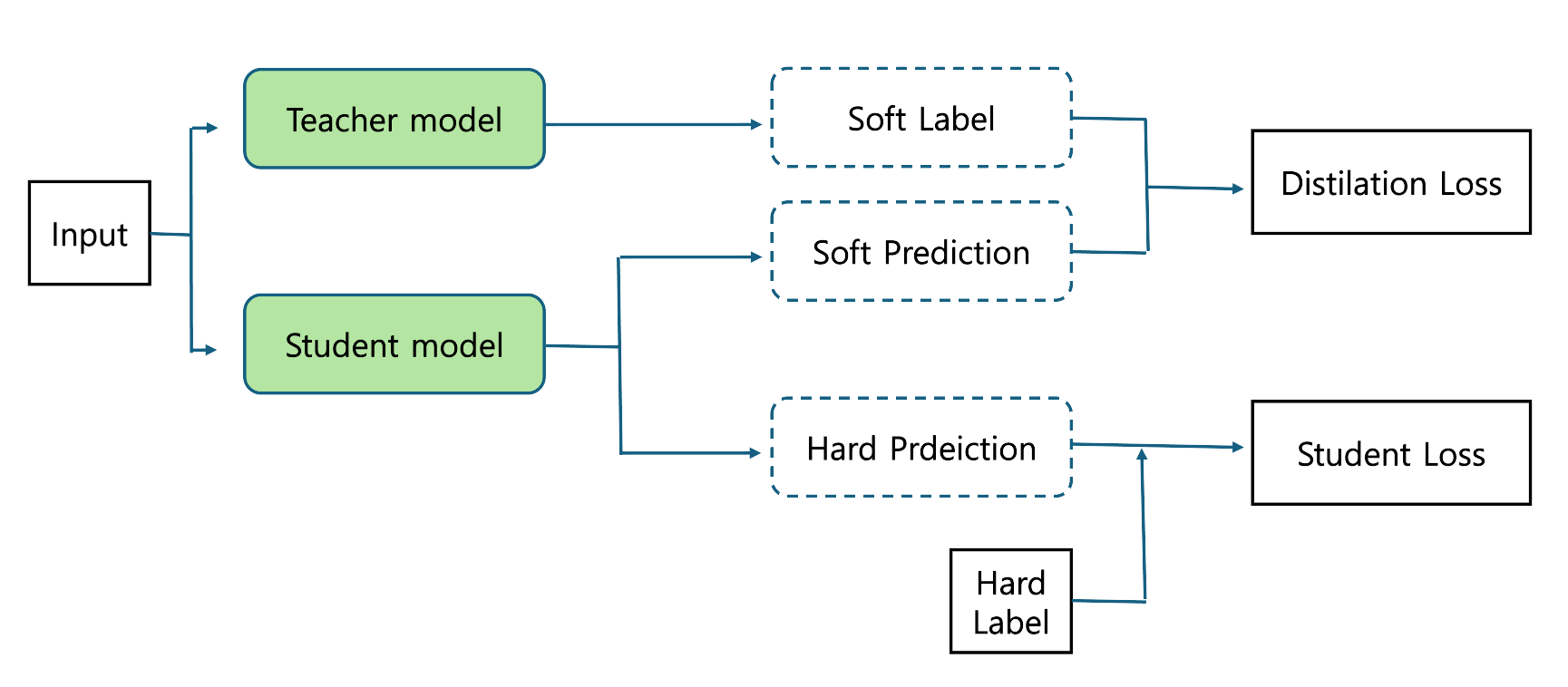
Input이 Teacher model과 Student 모델에 각각 들어갑니다. Teacher의 출력을 Label로 보고, 이를 Student가 Teacher의 Label과 비슷해지도록 학습하기 위한 Loss가 Distilation Loss 입니다.
Student의 출력을 실제 정답(Hard Label)과 비교해 전통적인 학습을 하는 것이 Student Loss 입니다.
Distilation Loss와 Student Loss에 적절한 가중치를 두어 학습을 시킵니다.
지식증류의 기대 효과
- 성능 유지 및 모델 경량화: 학생 모델은 파라미터가 훨씬 적음에도 교사 모델과 유사한 성능을 낼 수 있습니다.
- 효율적인 추론: 경량 모델은 모바일, IoT 디바이스, 에지 컴퓨팅 환경 등에 손쉽게 배포할 수 있습니다.
- 훈련 및 서빙 비용 절약: 모델이 작고 추론이 빨라 서버 비용, 대기 시간 등의 절감 효과를 기대할 수 있습니다.
1. 모바일 환경의 이미지 분류: 대형 CNN(ResNet-152)에서 학습된 분포를 활용해 MobileNet 같은 경량 모델에 지식을 증류, 모바일 앱에 탑재 가능한 모델을 구현.
2. 자연어 처리 분야: BERT나 GPT-3 같은 대형 언어모델을 교사 모델로 두고 DistilBERT와 같은 모델을 학생 모델로 학습시켜 챗봇, 실시간 번역 서비스 등에 적용.
📌 fin
지식증류(Knowledge Distillation)는 대규모 모델의 지식을 효율적으로 추출하고, 이를 작은 모델에 전달하는 강력한 기법입니다. 이를 통해 경량 모델도 대형 모델에 필적하는 성능을 낼 수 있으며, 실제 서비스 환경에서의 효율성 향상과 비용 절감 등을 기대할 수 있습니다.
딥러닝 산업 현장에서는 모델 성능과 효율성을 동시에 잡는 것이 중요한 과제로 떠오르고 있습니다. 이런 상황에서 지식증류는 모델 압축, 최적화, 경량화 영역에서 핵심적인 역할을 하고 있으며, 앞으로도 더욱 주목받을 것으로 예상됩니다.
다음에는 Distilation With No Label 이라는 주제로 포스팅을 하도록 하겠습니다.
라벨이 없는 데이터, 즉 비지도학습을 위한 Knowledge Distilation 방법입니다.
