📌 최근에 파이토치를 사용하여 논문 리뷰에서 배운 내용을 구현해보았습니다. MNIST나 CIFAR-10 등 파이토치에서 제공하는 데이터셋은 이미 훈련 데이터와 테스트 데이터로 나누어져 있어 따로 분리할 필요가 없었습니다. 그러나 대부분의 경우, 데이터셋을 직접 수집하고 라벨링한 후에 훈련 데이터와 테스트 데이터로 나누어야 합니다. 오늘은 이러한 데이터셋 분할 방법에 대해 자세히 알아보겠습니다.
🔶 데이터셋의 필요성과 분할
딥러닝 모델을 훈련시키기 위해서는 데이터가 필수적입니다. 예를 들어, 개와 고양이를 구분하는 모델을 만들고자 한다면, 개와 고양이의 이미지가 포함된 데이터셋이 필요합니다. 모델이 많은 데이터를 학습할수록 더 좋은 성능을 발휘할 가능성이 높습니다.

하지만, 수집한 데이터셋을 전부 학습에 사용하는 것은 바람직하지 않습니다. 그 이유는 모델의 성능을 평가하기 위한 테스트 데이터가 필요하기 때문입니다. 훈련 데이터와 테스트 데이터를 명확히 구분하지 않으면, 모델의 진정한 성능을 평가하기 어렵습니다.
훈련 데이터와 테스트 데이터의 구분
모델을 학습시키고 나면, 학습된 모델의 성능을 평가하기 위해 테스트 데이터가 필요합니다. 만약 모델 학습 과정에서 사용된 데이터가 테스트 데이터로 사용된다면, 모델의 성능 평가는 신뢰할 수 없게 됩니다. 이는 마치 교과서 문제와 똑같은 문제를 시험에 내는 것과 같아서, 시험의 정확성을 담보할 수 없습니다.
딥러닝에서도 동일하게, 모델은 훈련 과정에서 사용되지 않은 완전히 새로운 데이터로 평가되어야 합니다. 따라서 데이터셋을 미리 나누어 훈련 데이터와 테스트 데이터로 구분하는 것이 중요합니다.
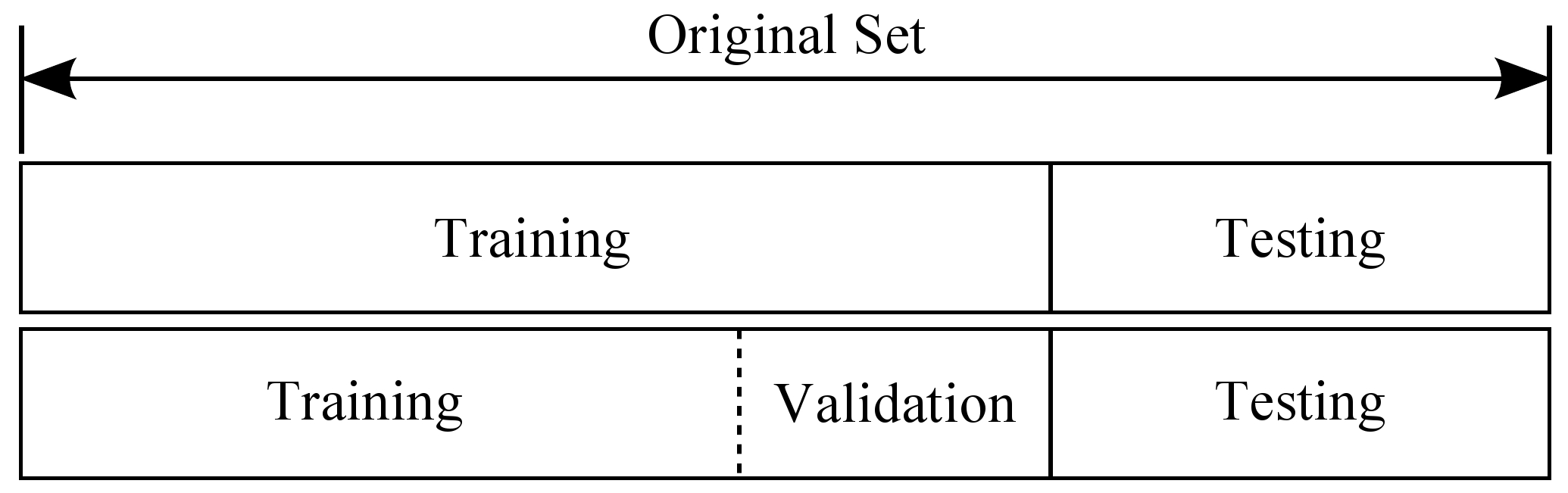
훈련 데이터는 모델의 학습 과정에 사용되며, 테스트 데이터는 모델을 학습한 후 평가하는 데에만 사용됩니다. 평가 후에는 모델을 수정해서는 안 되며, 이로 인해 테스트 데이터에 맞춘 모델이 되지 않도록 해야 합니다.
검증 데이터와 하이퍼파라미터 조정
훈련 데이터와 테스트 데이터 외에도 검증 데이터라는 개념이 있습니다. 검증 데이터는 하이퍼파라미터를 조정하는 데 사용됩니다. 하이퍼파라미터는 학습 에포크나 러닝 레이트와 같은 모델의 학습 과정에서 스스로 최적의 값을 찾지 않는 변수들입니다. 이러한 값들은 사람이 직접 조정해야 하며, 검증 데이터를 통해 성능을 평가합니다.
일반적인 데이터 분할 비율은 다음과 같습니다:
- 훈련 데이터: 60% - 80%
- 검증 데이터: 10% - 20%
- 테스트 데이터: 10% - 20%
🔶 K-Fold Cross Validation
데이터셋이 부족한 경우, 훈련, 검증, 테스트 데이터로 나누는 것이 모델 성능에 부정적인 영향을 미칠 수 있습니다. 이럴 때 사용하는 기법이 K-Fold Cross Validation입니다.

K-Fold Cross Validation은 데이터셋을 K개의 폴드(fold)로 나눈 후, 매번 다른 폴드를 검증 데이터로 사용하여 모델을 평가합니다. 예를 들어, K=5인 경우, 데이터셋을 5개의 폴드로 나눈 후, 각 폴드를 한 번씩 검증 데이터로 사용하며 나머지 4개의 폴드를 훈련 데이터로 사용합니다. 이 과정을 통해 최적의 성능을 내는 모델을 찾은 후, 마지막으로 테스트 데이터로 평가를 진행합니다.
이러한 방식은 데이터셋이 적어도 모델의 성능을 보다 안정적으로 평가할 수 있게 해줍니다.
딥러닝 모델의 성능을 정확히 평가하고 최적화하기 위해서는 데이터셋을 적절히 분할하고, 검증 데이터를 효과적으로 활용하는 것이 중요합니다. K-Fold Cross Validation 같은 기법을 통해 부족한 데이터로도 신뢰성 있는 평가를 할 수 있습니다. 데이터셋을 적절히 분할하고 사용하는 방법에 대해 이해하는 것은 모델 개발의 핵심적인 부분입니다.
